ǰ��
PSO-for-Neural-Nets
���֪��,ʹ�÷��������������ѵ���Ƿdz���Ч�ġ��������������ij�ʼֵ��ò���ʱ,��λ����Ҳ�й�ѵ��ʮ�ֻ����ľ�����
�����ṩһ�ּӿ췴�����㷨,Ŀ������ѵ��������ʱ��ʹ�÷����Լ��ݶ��½��㷨,������ʹ������Ⱥ�Ż��㷨(Particle Swarm Optimization,PSO)������������г�ʼ��,֮������ٴ�ʹ�÷��������������ʽѵ����
1 ����Ⱥ�Ż� PSO
����Ⱥ�Ż���һ��Ԫ����ʽ�㷨(meta-heuristics algorithm),�����ڻ�����Ⱥ��Ԫ����ʽ������һ�����ࡣ����ζ�Ž�������ӷ����� n ά��ռ���,���䲻���ƶ��Ի�����Ž⡣���ڲ���Ϥ����Ⱥ�Ż���ͯЬ,���������������Ͽ����˽�һ�¡�������ƪ,���������⡣
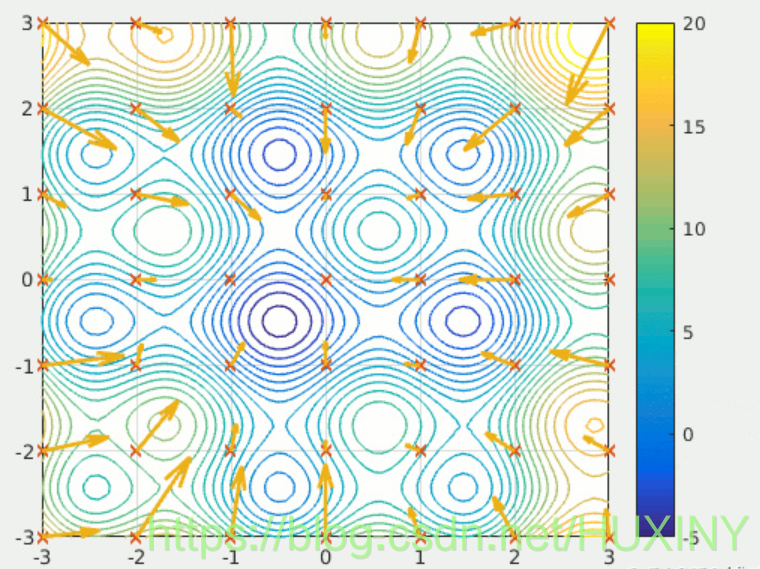
2 ������
ǰ��������: ǰ������������������(һ�����Բ���,Ȼ����һ�������Բ���)�Ķ�ջ,��Щ���������Ӧ�����ҳ�ӳ�� ��
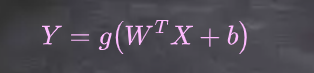

3 �����߽��

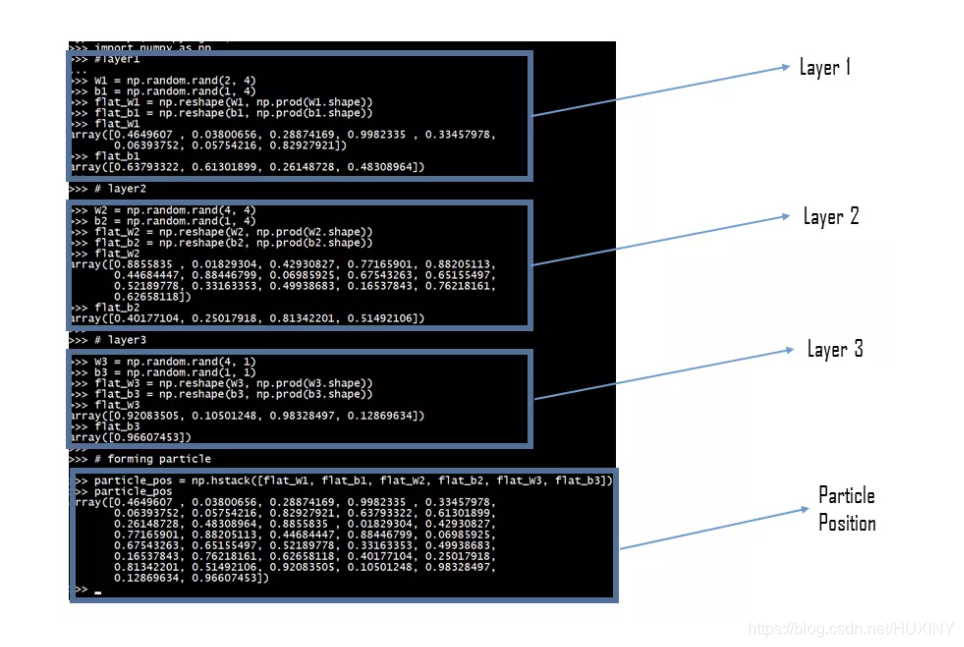
import numpy as np
from swarm_intelligence.particle import Particle
from swarm_intelligence.pso import ParticleSwarmOptimizer
from matplotlib import pyplot as plt
mean_01 = np.array([1.0, 2.0])
mean_02 = np.array([-1.0, 4.0])
cov_01 = np.array([[1.0, 0.9], [0.9, 2.0]])
cov_02 = np.array([[2.0, 0.5], [0.5, 1.0]])
ds_01 = np.random.multivariate_normal(mean_01, cov_01, 250)
ds_02 = np.random.multivariate_normal(mean_02, cov_02, 250)
all_data = np.zeros((500, 3))
all_data[:250, :2] = ds_01
all_data[250:, :2] = ds_02
all_data[250:, -1] = 1
np.random.shuffle(all_data)
split = int(0.8 * all_data.shape[0])
x_train = all_data[:split, :2]
x_test = all_data[split:, :2]
y_train = all_data[:split, -1]
y_test = all_data[split:, -1]
def sigmoid(logit):
return 1 / (1 + np.exp(-logit))
def fitness(w, X=x_train, y=y_train):
logit = w[0] <em> X[:, 0] + w[1] </em> X[:, 1] + w[2]
preds = sigmoid(logit)
return binary_cross_entropy(y, preds)
def binary_cross_entropy(y, y_hat):
left = y * np.log(y_hat + 1e-7)
right = (1 - y) * np.log((1 - y_hat) + 1e-7)
return -np.mean(left + right)
pso = ParticleSwarmOptimizer(Particle, 0.1, 0.3, 30, fitness,
lambda x, y: x<y, n_iter=100,
dims=3, random=True,
position_range=(0, 1), velocity_range=(0, 1))
pso.optimize()
print(pso.gbest, fitness(pso.gbest, x_test, y_test))
26%|������ | 26/100 [00:00<00:00, 125.34it/s]
1.1801928375606305
1.4209814927365876
1.6079804335787051
1.4045063665887232
1.6061883358646398
1.216230952537311
1.092492742843725
1.425740352398705
1.2316560685535152
0.9883386170699404
0.7872754467763685
1.2949776923674654
1.5335307808402896
1.4402299491203296
1.707301581201865
1.3663291698028996
0.810679674134304
0.902645267001228
...
0.6887999501032107
0.6888687686160592
0.688937050625055
0.6890767713425439
0.6892273324647994
0.6890875560305971
0.689124619992127
0.6898172338259064
0.6887098887333781
0.6887212601101861
0.688826316853767
0.6892384007287018
0.6844381943050638
0.689115638510458
0.6891453159612045
0.6901587770829556
0.6895998527186173
0.6890967086445332
0.689073485303836
0.6883588252450673
[0.00451265 0.21376644 0.22467216] 0.6875450245414241
����Ⱥ�Ż��㷨����Ԫ�����㷨��һ��,Ѱ��������Ҫ����ļ���ʱ�䡣����,Ԫ�����㷨�������ά���������,���㸴�ӶȻ���������ά���Ĺ�ģ���Ӻܿ�,������������������縴�ӵ�Ѱ�š�
���ǶԱ��ݶ��½�����,Ԫ����Ҳ�кܶ�����,�����ݶ��½�Ҳ��һЩ����,����Գ�ʼ��������,�����ʼ��������������,��ʼ�������ÿ��ܾͲ����������Զ��ڲ���ʮ�ָ��ӵ�����ܹ�,����Ԫ�����㷨���Եõ�һ���Ƚϲ����ij�ʼ����