我们将属性称为"特征" (feature) ,对当前学习任务有 用的属性称为"相关特征" (relevant feature) 、没什么用的属性称为"无关特 征" (irrelevant feature). 从给远的特征集合中选择出相关特征于集的过程,称 为"特征选择" (feature selection).特征选择是一个重要的"数据预处理" (data preprocessing) 过程?在现实 机器学习任务中 获得数据之后通常先进行特征选择,此后再训练学习器。
有两个很重要的原因:首先,我们在现实任务中经常会遇到维数灾难问题, 这是由于属性过多而造成的?若能从中选择出重要的特征,使得后续学习过程 仅需在-部分特征上构建模型?则维数灾难问题会大为减轻.去除不相关特征往往会降低学习任务的难度?这 就像侦探破案一样,若将纷繁复杂的因素抽丝剥茧,只留下关键因素,则真相往 往更易看清.
特征选择过程必须确保不丢失重要特征,否则后续学习过程 会因为重要信息的缺失而无法获得好的性能.,特征选择中所谓的"无关特征"是指与当前辈习 任务无关
两个关键环节:如何根据评价结果获取下一个候 选特征子集?如何评价候选特征子集的好坏?
将特征子集搜索机制与子集评价机制相结合,即可得到特征选择方法.例 如将前向搜索与信息娟相结合,这显然与决策树算法非常相似.事实上,决策树 可用于特征选择,树结点的划分属性所组成的集合就是选择出的特征子集.其 他的特征选择方法未必像决策树特征选择这么明显,但它们在本质上都是显式 或隐式地结合了某种(或多种)子集搜索机制和子集评价机制. 常见的特征选择方法大致可分为三类:过滤式(且lter) 、包裹式(wrapper)和. 嵌入式(embedding).
过滤式方法先对数据集进行特征选择,然后再训练学习器,特征选择过程 与后续学习器无关.这相当于先用特征选择过程对初始特征进行"过滤",再 用过滤后的特征来训练模型.Relief (Relevant Features) [Kira and Rendell, 1992] 是一种著名的过滤式 特征选择方法,该方法设计了一个"相关统计量"来度量特征的重要性.Relief 的关键是如何确定相关统计量,,相关统计量对应于属性 分量为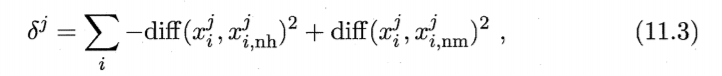
实际上 Relief 只需在数据集的 采样上而不必在整个数据集上估计相关统计量 [Kira and Rendell, 1992]. 显然, Relief 的时间开销随采样次数以及原始特征数线性增长,因此是一个运行效率 很高的过滤式特征选择算法.Relief 是为二分类问题设计的 其扩展变体 RelieιF [Kononenko , 1994] 处理多分类问题?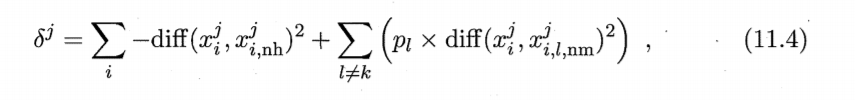
与过滤式特征选择不考虑后续学习器不间?包裹式特征选择直接把最终将 要使用的学习器的性能作为特征于集的评价准则.换言之?包裹式特征选择的 目的就是为给定学习器选择最有利于其性能、 "量身走做"的特征子集.
LVW (Las Vegas Wrapper) [Liu and Setiono, 1996] 是一个典型的包裹式 特征选择方法.它在拉斯维加斯方法(Las Vegas method) 框架下使用随机策略 来进行子集搜索,并以最终分类器的误差为特征子集评价准则,若有运行时间限制?则有可能给不出解.?
在过滤式和包裹式特征选择方法中,特征选择过程与学习器训练过程有明 显的分别;与此不同,嵌入式特征选择是将特征选择过程与学习器训练过程融 为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行了 特征选择.
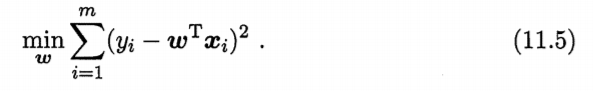
当样本特征很多,而样本数相对较少时,式(1 1. 5) 很容易陷入过拟合.为了 缓解过拟合问题,可对式(11.5) 引入正则化项.若使用 L2 范数正则化,则有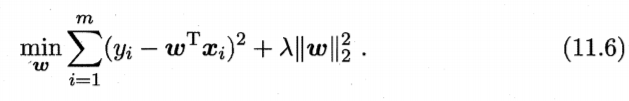 ?
?
其中正则化参数 λ>0 (11.6) 称为 "ili令回归" (ridge regression) [Tikhonov and Arsenin, 1977] ,通过引入 范数正则化?确能显著降低过拟合的风险,
L1范数和 L2 范数正则化都有助于降低过拟合风险,但前者还会带来一个 额外的好处:它比后者更易于获得"稀疏" (sparse) 解,即它求得的 会有更 少的非零分量.?
?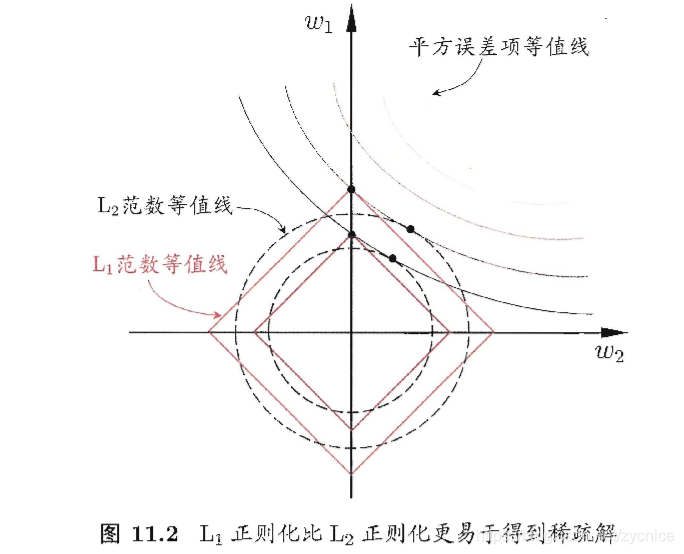
?注意到 取得稀疏解意味着初始的 个特征中仅有对应着 的非零分量 的特征才会出现在最终模型中 于是,求 范数正则化的结果是得到了仅采 用一部分初始特征的模型;换言之,基于 则化的学习 方法就是一种嵌入式 特征选择方法?其特征选择过程与学习器训练过程融为一体, 同时完成.
L1正则化问题的求 可使用近端梯度下降
不妨把数据集 D考虑、成一个矩阵,其每行对应于・个样本,每列对应于_.. 个特征.特征选择所考虑的问题是特征具有"稀疏性"?即矩阵中的许多列与 当前学习任务无关,通过特征选择去除这些列,则学习器训练过程仅需在较小的矩阵上进行,学习任务的难度可能有所降低?涉及的计算和存储开销会减少, 学得模型的可解释性也会提高.
当样本具有这样的稀疏表达形式时,对学习任务来说会有不少好处,例如 线性支持向量机之所以能在文本数据上有很好的性能,恰是由于文本数据在使 用上述的字频表示后具有高度的稀疏性,使大多数问题变得线性可分.
为普通稠密表达的样本找到合适的 字典,将样本转化为合适的稀疏表示形式,从而使学习任务得以简化,模型 复杂度得以降低,通常称为"字典学习" (dictionary learning) ,亦称"稀疏编 码" (sparse coding). 这两个称谓稍有差别,"字典学习"更侧重于学得字典的 过程?而"稀疏编码"则更侧重于对样本进行稀疏表达的过程由于两者通常 是在同一个优化求解过程中完成的,因此下面我们不做进一步区分,笼统地称 为字典学习.
给定数据集 {Xl X2 ?? 字典学习最简单的形式为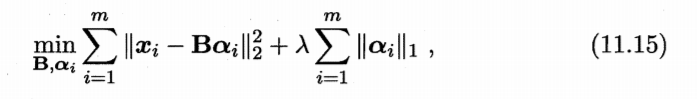
奈奎斯特采样定理提供 了信号恢复的充分条件而 非必要条件
事实上,在很多应用中均可获得具有稀疏性的 例如图像或声音的数字信 号通常在时域上不具有稀疏性?但经过傅里叶变换、余弦变换、小波变换等处 理后却会转化为频域上的稀疏信号.
基于部分信息来恢复全部信息的技术在许多现实任务中有重要应用.能通过压缩感知技术恢复欠采样信号的前提条件之一是信号 有稀疏表示