1.K-Means++算法介绍
K-Means++主要解决初始化种子点的问题,其选择初始种子的基本思想是:初始聚类中心之间相互距离要在K-Means算法基础上引入了更智能的初始化步骤,该步骤倾向于选择彼此相距较远的中心点,这一改进使得K-means算法收敛到次优解的可能性很小。K-Means++算法表明,更智能的初始化步骤所需计算量是值得的,因为他可以大大减少寻找最优解所需运行算法的次数。
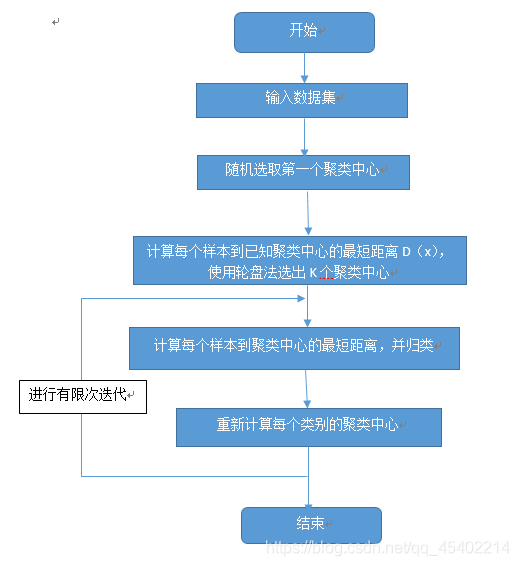
2.K-Means算法实现步骤
1.取一个中心点C1,从数据集中随机选择一个中心点。
2.计算每个样本与当前已有聚类中心之间的最短距离,用D(x)表示。然后计算每个样本被选为下一个聚类中心的概率,公式如下图所示,最后按轮盘法选出下一个聚类中心:
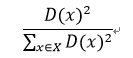
3.重复上一步,直到选择了所有K个中心点。
4.初始化聚类中心到此为止,接下来继续通过K-Means算法进行求解。
3.实现实例
数据集请在k-means聚类算法实现下载
# coding: utf-8
import math
import random
from sklearn import datasets
import numpy as np
import pandas as pd
def euler_distance(point1: list, point2: list) -> float:
"""
计算两点之间的欧拉距离,支持多维
"""
distance = 0.0
for a, b in zip(point1, point2):
distance += math.pow(a - b, 2)
return math.sqrt(distance)
def get_closest_dist(point, centroids):
min_dist = math.inf # 初始设为无穷大
for i, centroid in enumerate(centroids):
dist = euler_distance(centroid, point)
if dist < min_dist:
min_dist = dist
return min_dist
def kpp_centers(data_set: list, k: int) -> list:
"""
从数据集中返回 k 个对象可作为质心
"""
cluster_centers = []
cluster_centers.append(random.choice(data_set))#随机返回一个数据记录
d = [0 for _ in range(len(data_set))] # 初始化d为0,长度为数据集的长度
for _ in range(1, k):
total = 0.0
for i, point in enumerate(data_set):
d[i] = get_closest_dist(point, cluster_centers) # 与最近一个聚类中心的距离
total += d[i]
total *= random.random()
for i, di in enumerate(d): # 轮盘法选出下一个聚类中心;
total -= di
if total > 0:
continue
cluster_centers.append(data_set[i])
break
return cluster_centers
def kmeans(data, k, cent):
'''
kmeans算法求解聚类中心
:param data: 训练数据
:param k: 聚类中心的个数
:param cent: 随机初始化的聚类中心
:return: 返回训练完成的聚类中心和每个样本所属的类别
'''
m, n = np.shape(data) # m:样本的个数;n:特征的维度
subCenter = np.array(np.zeros((m))) # 初始化每个样本所属的类别
change = True # 判断是否需要重新计算聚类中心
while change == True:
change = False # 重置
for i in range(m):
minDist = np.inf # 设置样本与聚类中心的最小距离,初始值为正无穷
minIndex = 0 # 所属的类别
for j in range(k):
# 计算i和每个聚类中心的距离
dist = euler_distance(list(data[i]), list(cent[j]))
if dist < minDist:
minDist = dist
minIndex = j
# 判断是否需要改变
if subCenter[i] != minIndex: # 需要改变
change = True
subCenter[i] = minIndex
# 重新计算聚类中心
for j in range(k):
sum_all = np.mat(np.zeros((1, n)))#n是特征的维度
r = 0 # 每个类别中样本的个数
for i in range(m):
if subCenter[i] == j: # 计算第j个类别
sum_all += data[i]
r += 1
print(str(r)+":"+str(j))
for z in range(n):
try:
cent[j][z] = sum_all[0, z] / r
except:
print("ZeroDivisionError: division by zero")
return subCenter, cent
if __name__ == "__main__":
inputfile = 'data/consumption_data.xls' # 销量及其他属性数据
data = pd.read_excel(inputfile, index_col='Id') # 读取数据
data_zs = 1.0 * (data - data.mean()) / data.std() # 数据标准化
cluster_centers = kpp_centers(data_zs.values.tolist(), 4)
subCenter, cent = kmeans(data_zs.values.tolist(),4,cluster_centers)
for i in range(500):
subCenter, cent = kmeans(data_zs.values.tolist(), 4, cent)
print(subCenter)
subCenter = pd.Series(subCenter,index = data.index)
r = pd.concat([data, subCenter], axis=1) # 横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(data.columns) + ['类别'] # 重命名表头
print(r)
from sklearn.manifold import TSNE
tsne = TSNE(random_state=105)
tsne.fit_transform(data_zs) # 进行数据降维
print(tsne.embedding_)
tsne = pd.DataFrame(tsne.embedding_, index=data_zs.index) # 转换数据格式
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 不同类别用不同颜色和样式绘图
print(r['类别'] == 0)
d = tsne[r['类别'] == 0]
plt.plot(d[0], d[1], 'r.')
d = tsne[r['类别'] == 1]
plt.plot(d[0], d[1], 'go')
d = tsne[r['类别'] == 2]
plt.plot(d[0], d[1], 'b*')
d = tsne[r['类别'] == 3]
plt.plot(d[0], d[1], 'y*')
plt.show()