�ؼ���
����ͬ����CNN��SyncNet
ǰ��
����Ƶ������,��������������ͬ��������,���ǵ�ʱ��ͨ���� -125ms~45ms ֮�䡣
���������ͨ�������¼���˼·:
- ��ͳ��ʽ:���ǰ� (clapperboard)
- �ִ���ʽ:ʱ���� (timecode)��ʱ��������� (time warping)
(�������ع�����δ�Թ��ڿ�ֱ�ӷ��ʵ�����Ƶ��Ϊ���ݼ�)
(һЩ���½������ء�ĸ����)
(���µ����³���Ѱ������Ƶ����֮���һ����)
����
- ������Ժ�˵��������ģ��
- ͨ���ޱ�ע���ݻ��ھ����������Ƶ�����ξ�������Ƕ��
- ��һ���˵���������ͬ������
- Ӧ�ó���:
- �������ͬ�����
- �ж϶��˳����еķ�����
- ������
ģ��
SyncNet����ṹ,����0.2s ����Ƶ����ƵƬ��(�ޱ�ǩ),����������ͨ����ͬ���ġ�
��Ƶ��
��������Ϊ MFCC ��ֵ(�����Ķ�ʱ������,�ο�)
�ɱ���Ϊ��ͼ,������ʾ��(13��20��1)
���û���VGG-M (�ο�) ��CNN����ѵ����
��Ƶ��
Ԥ�����õ��촽���ֵĻ�ɫͼƬ��
ʱ�䷽������ 25fps ������ȡ����5֡��(111��111��5)

��ʧ����
���öԱ���ʧ(������������)
E
=
1
2
N
��
i
=
1
N
(
y
n
)
d
n
2
+
(
1
?
y
n
)
max
?
(
m
a
r
g
i
n
?
d
n
,
0
)
2
E=\frac{1}{2N}\sum_{i=1}^{N}(y_n)d_n^2+(1-y_n)\max(margin-d_n, 0)^2
E=2N1?i=1��N?(yn?)dn2?+(1?yn?)max(margin?dn?,0)2
d
n
=
�O
�O
v
n
?
a
n
�O
�O
2
d_n=||v_n-a_n||_2
dn?=�O�Ovn??an?�O�O2?
ѵ��
����CNN,���ô�momentum��SGD����ѵ����
������ǿ:
- ����������Ƶ���������10%
- ���������������ȡ
- ����Ƶ����ImageNet�ı���ǿ����
���ݼ�
BBC
ʵ��
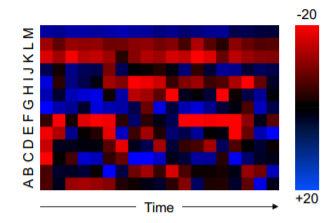
3��Ӧ�ó���
����ͬ�����
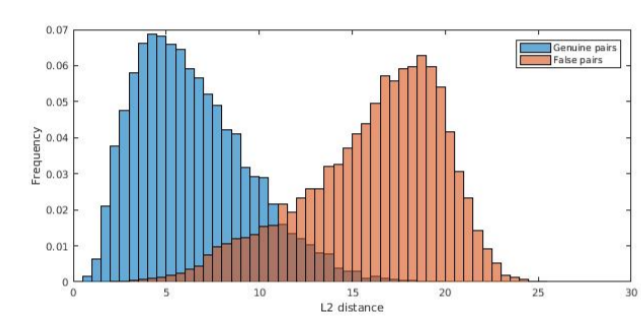

����Բ�ͬ����Ҳ���á�
�����˼��
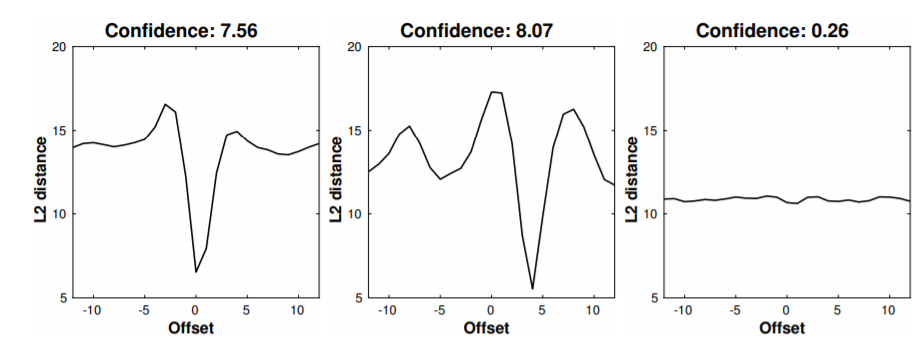
ͨ������ƥ��ȵõ���

������
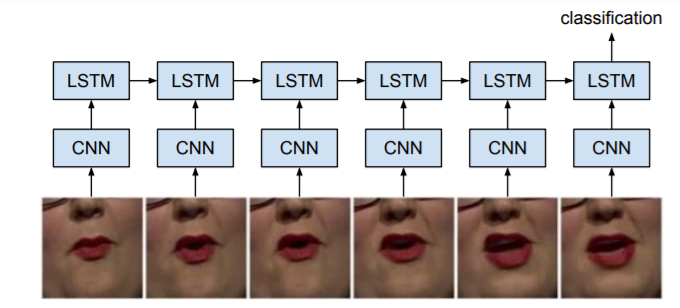
����LSTM��ͼ��֡�����б�ע��