基于规则的海事自由文本信息抽取方法研究
目录
一.前言
海事事故数据作为评估现有安全水平和降低风险措施有效性的基础,在进行风险分析时必不可少。目前我国各海事部门大都存在各自船舶数据库,但在各部门数据库相对独立,不同部门的数据库甚至同一部门的不同数据库都存在着数据不互通的问题 ,并且各海事部门数据库大都未对外开放,无法直接得到结构化的事故数据,只能在Web网页中获取得到事故相关的文本信息。
二.自由文本信息抽取方法
2.1 基本组成结构
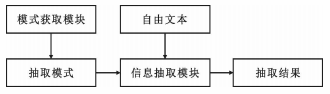
自由文本信息抽取系统主要由模式获取模块和信息抽取模块两部分组成。
自由文本信息抽取各组成部分功能解释如下:
1 ) 词法分析:指对文本的预处理,主要包括分句、分词和词性标注。
2 ) 命名实体识别:识别文本中各种不同类型的专业名词,主要包括人名、地名、机构名、时间、日期等。
3 ) 句法分析:识别文本中的名词群组、动词群组和介词群组等句法成分。
4 ) 指代解析:同一实体在文本中可能有多种不同的表达方式,将它们与所指代对象关联到一起。
5 ) 推理:通过特定规则从已抽取信息中推理出隐含的相关信息。
6 ) 事件融合:将抽取合并得到的多个单个信息按输出格式的要求结合成完整的事件抽取模板。
2.2 评价标准
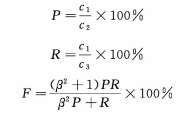
一般以准确率、召回率和
F
F
F值作为自由文本信息抽取方法的评价指标[1]。式中:
P
P
P 为准确率,
R
R
R 为召回率,
C
1
C_1
C1?为返回结果中正确的个数,
C
2
C_2
C2?为所有返回结果的个数,
C
3
C_3
C3?为应该返回结果的个数,
β
\beta
β 为权重系数,决定在评价抽取结果时是侧重准确率还是侧重召回率,通常设定为1,2 或
1
2
\frac{1}{2}
21? ,0 。取值为1时,准确率和召回率一样重要。
三.基于规则的海事信息抽取方法
3.1 海事信息的数据来源
主要包括事故发生时间、事故船舶名称及类型、事故发生地点、事故类型、伤亡情况、是否碍航等描述海事事故的重要信息。
3.2 海事信息抽取流程
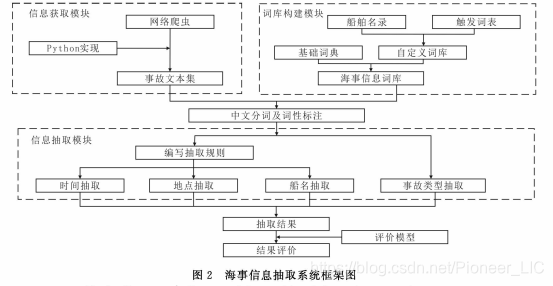
1 ) 信息获取模块。利用网络爬虫对长江海事局官网上的海事事故信息的网页进行解析并下载[2],得到事故文本集。
2 ) 海事词库构建模块。包括抽取任务本身及其触发词等海事专业词汇。
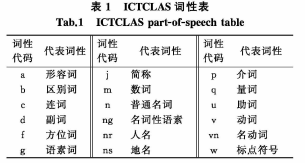
3 ) 海事文本的分词及词性标注。基于中科院的ICTCLAS中文分词算法,将通用词典与自定义海事词库进行去重合并后,对自由文本进行中文分词以及词性标注,ICTCLAS常见词性标注见表 1。
(ICTCLAS中文分词算法):

4 ) 信息抽取模块。通过对大量事故语料的阅读归纳,对抽取任务中的时间、地点、船名信息编制抽取规则进行抽取,事故类型信息则可利用自定义词库直接进行抽取。
5 ) 信息抽取结果评价。对抽取结果进行评价,系统的框架结构见图2。
3.3 自定义海事词库的创建
海事文本中存在大量船名、地名、航段、事故类型等海事专业词汇,因此,需要建立一个自定义的海事词库,对海事专业词汇进行总结、分类,以及词性标注。
定义待抽取的信息类型,描述水上交通事故的关键信息有时间、地点、船名和事故类型, 将这4项确定为抽取任务,待抽取的数据项定义及常见表达方式如下:
时间:水上交通事故发生的日期,通常包括年、月、日、时,例如,“3 月 1 7 日”‘‘2 月 2 日 23:32 时”等。
地点:水上交通事故发生的地点,常用表达方式为长江上\中\下游里程数,例如,“长江中游里程 114 km”“长江下游 436 km”等。
船名:事故船舶的名称,例如,“宁高鹏 2969” “炜 轮 1 0号”“万 港 65-9趸”“武汉中宁壹号”等。
事故类型:水上交通事故的类型,由中华人民共和国海事局定义的海事事故类型有碰撞,搁浅,触礁,触损,浪损,火灾、爆炸,风灾,自沉,其他。
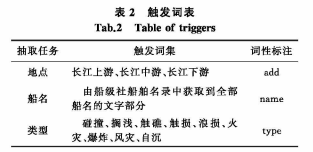
抽取任务触发词组成的触发词集见表2。
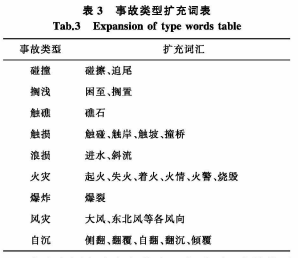
自定义海事词库需要在触发词集的基础上进行扩展,即通过词典找出触发词表中各数据项触发词的同义词以其各种不同形态,从中选择某些常用词汇,与触发词表合并构成自定义海事词库。通过对海事文本的分析,仅事故类型触发词需要进行扩展,事故类型扩充词表见表3。
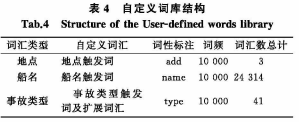
自定义词库包括自定义词汇、词性标注以及词频,见表4。
3.4 信息抽取规则的设计
文基于中科院的ICTCLAS中文分词算法[3],将通用词典与自定义海事词库进行去重合并后,对自由文本进行中文分词以及词性标注,各抽取任务触发词的词性均由自定义海事词库进行定义,能准确定位与识别得到。
3.4.1 船名信息的抽取
Yname:{ name } { m } *
其中,name是自定义海事词典中标注的船名信息词性,m 表示数词;{a } * 表示词性为a 的词出现小于等于 1 次。抽取步骤[4]如下:
1 ) 读取 1 条事故文本并对其进行中文分词及词性标注。
2 ) 查找词性为“name”词汇并定位。
3 ) 向后查找,判断词性是否为“m”,若是,抽取“name”和“m”词汇。
4 ) 若否,直接抽取“name”词汇。
5 ) 定位下1 个“name”词性,重 复 3 )? 4) 。
6 ) 遍历完所有“name”词性,去除抽取得到的相同词汇并保存。
7 ) 读取下 1 条文本,重 复 1)?7)。
3.4.2 事件信息的抽取
Ytime:{ m } + { d }* { m } { ng }
其中,m 表示数词;d 表示副词;ng 表示名词性语素 ^ &} +表示词性为 a 的词出现至少 2 次 ;{a } * 表示词性为a 的词出现小于等于1 次。抽取步骤如下:
1 ) 读 取 1 条事故文本并对其进行中文分词及词性标注。
2 ) 查找连续 2 个词性为“m”词汇。
3 ) 向后查找判断词性是否为“m”,若是,向后查找判断词性是否为“ng”,若是,抽取,若否,结束。
4 ) 若“name”后词汇词性不是“m”,则判断该词汇词性是否为“d”,若是,重复步骤 3),若否,结束。
5 ) 保存抽取得到的结果
3.4.3 地点信息的抽取
Yadd : { add } { n } * { m }
其中,m 表示数词,n 表示名词,add是自定义海事词典中标注的地点信息触发词词性;U } + 表示词性为a 的词出现至少2 次 ;{a} * 表示词性为 a 的词出现小于等于1 次。抽取步骤如下:
1 ) 读取一条事故文本并对其进行中文分词及词性标注。
2 ) 查找词性为“add”词汇并定位。
3 ) 向后查找判断词汇词性是否为“m”,若是 ,抽取“add”和“m”词汇。
4 ) 若否,判断该词汇词性是否为“n”,若是,重复步骤 3);若否,结束。
5 ) 保存抽取得到的结果。
3.4.4 事故类信息的抽取
在自定义海事词库中,事故类型数据由海事局定义的事故类型以及各类型拓展词汇合并组成 ,词性标注为“type”,这类信息可以依靠词性从文本中直接识别并抽取得到。
四.结束语
通过构建自定义海事词库和编制抽取规则,提出一种基于规则的海事自由文本信息抽取方法。定义了需要抽取的数据项,确定了抽取数据类型为时间、地点、船名和事故类型4 个描述事故的关键信息,再创建自定义的海事词库,其中包括待抽取数据项常见触发词及拓展词汇,与通用词典合并作为海事自由文本的分词词典,通过分词后的词性构建抽取规则,对抽取任务进行抽取。
五.参考文献
[ 1 ] 孙星、严新平 、初秀民等.基于船标岸一体化技术的内河信息服务关键技术研究[J ].交通信息与安全,2012(4): 126-130.SUN Xing, YAN Xinping, CHU Xiumin, et al. Key technologies of information service system for inland waterway based on ship-mark-shore integration technology[J]. Journal of Transport Information and Safety 2012(4) : 126-130. (in Chinese)
[ 2 ] AHMADI-ABKENARI F , SELAMAT A. An architecture for a focused trend parallel Web crawler
with the application of clickstream analysis[J]. Information Sciences, 2012(1) : 266-281.
[ 3 ]ZHU K. Analysis of Chinese word segmentation technology[J]. Applied Mechanics & Materials 2014, 687-691:1540-1543.
[ 4 ] 陆 敏 ,张东华,陈 伟 ,等 .内河数字化航标系统设计及应用 [ J ] . 交 通 信 息 与 安 全 2012(1):152 -154.129.LU Min, ZHANG Donghua, CHEN Wei, et al. System design of digitalized aids to navigation in inland river and its application [ J ]. Journal of Transport Information and Safety, 2012 (1 ) : 152-154.129. (in Chinese)