目录
前言
论文地址: https://arxiv.org/pdf/2003.10027.pdf.
源码地址: https://github.com/Islanna/DynamicReLU.
贡献:提出Dynamic ReLU激活函数
Dy-ReLU特点(优点):
- 将所有输入元素 x={ x c x_c xc?} 的全局上下文编码在超参数 θ ( x ) \theta(x) θ(x) 中(运用SE模块的注意力机制),以适应激活函数 f θ ( x ) ( x ) f_{\theta(x)}(x) fθ(x)?(x)(可以根据输入数据x,动态的学习选择最佳的激活函数)。
一、背景或动机
ReLU 在深度学习的发展中地位举足轻重,它简单而且高效,极大地提高了深度网络的性能,被很多 CV 任务的经典网络使用。不过 ReLU 及其变种(无参数的 leaky ReLU 和有参数的 PReLU)都是静态的,对不同的输入以完全相同的方式执行,也就是说他们最终的参数都是固定的。那么自然会引发一个问题,能否根据输入的数据动态调整 ReLU 的参数呢?
针对这个问题,本文提出了一种动态的激活函数,Dynamic-ReLU(简称Dy-ReLU)。如下图:
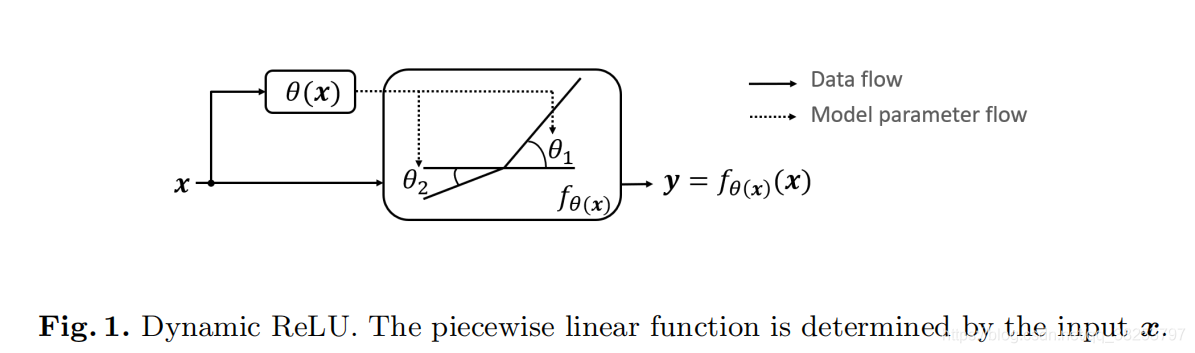
由上图可以看到,Dy-ReLU是一种动态的分段函数 f θ ( x ) ( x ) f_{\theta(x)}(x) fθ(x)?(x),其中最重要的参数 θ ( x ) \theta(x) θ(x) 由输入x绝定。最关键的思路是:将所有输入元素 x={ x c x_c xc?} 的全局上下文编码在超参数 θ ( x ) \theta(x) θ(x) 中,以适应激活函数 f θ ( x ) ( x ) f_{\theta(x)}(x) fθ(x)?(x)。
该设计能够在引入极少量的参数的情况下大大增强网络的表示能力,本文对于空间和通道上不同的共享机制设计了三种 DY-ReLU,分别是 DY-ReLU-A、DY-ReLU-B 以及 DY-ReLU-C。
二、Dynamic ReLU
Dynamic ReLU(Dy-ReLU)是一种动态的分段函数,参数依赖于输入x,不会增加网络的深度和宽度,但是可以在引入极少量的参数的情况下大大增强网络的表示能力。
2.1、定义Dynamic ReLU
最原始的ReLU为 y = m a x ( 0 , x ) y=max(0, x) y=max(0,x),函数图像如下:
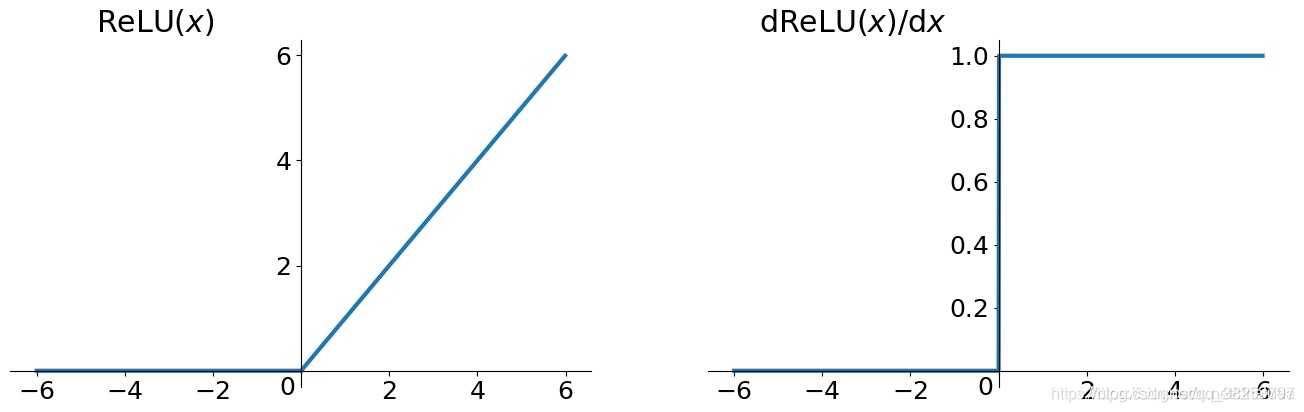
可以看到这个函数非常的简单。对于输入向量
x
x
x 的第
c
c
c 个维度channel的输入
x
c
x_c
xc?,对应的激活函数可以记为
y
c
=
m
a
x
x
c
,
0
y_c = max{x_c, 0}
yc?=maxxc?,0,进而ReLU可以统一表示为带参分段函数
y
c
=
m
a
x
k
y_c = max_k
yc?=maxk?{
a
c
k
x
c
+
b
c
k
{a^k_c x_c + b^k_c}
ack?xc?+bck?}。当x>0时,若a=1,b=0; 当x<时,若a=b=0,就是ReLU。基于此提出下式动态 ReLU 来针对
x
=
x =
x= {
x
c
{x_c}
xc?} 自适应
a
c
k
a^k_c
ack? 和
b
c
k
b^k_c
bck?。所以有:
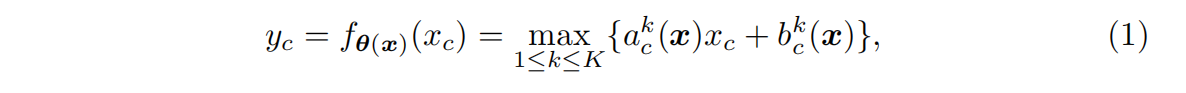
系数(
a
c
k
a^k_c
ack?,
b
c
k
b^k_c
bck?)由超函数
θ
(
x
)
\theta(x)
θ(x) 计算得到,具体如下:
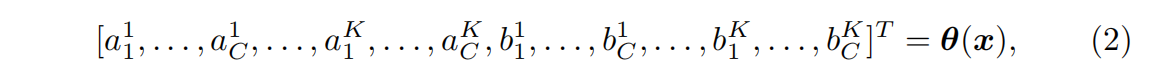
其中
K
K
K 表示函数的个数,
C
C
C为通道数。参数(
a
c
k
a^k_c
ack?,
b
c
k
b^k_c
bck?)不仅仅与
x
c
x_c
xc? 有关,还和
x
j
x_j
xj? 有关(有点注意力机制的意思,代码上也确实是用注意力模块SE完成的)。
2.2、实现超函数 θ ( x ) \theta(x) θ(x)
以DY-ReLU-A为例:
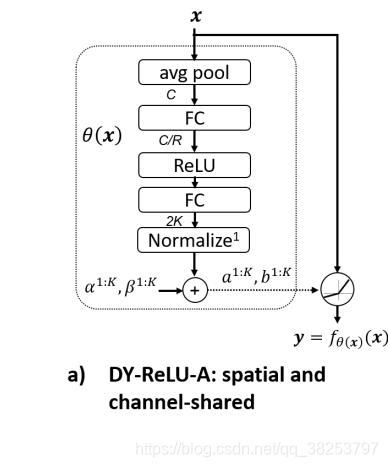
DY-ReLU 的核心超函数
θ
(
x
)
\theta(x)
θ(x) 的实现采用 SE 模块(SENet 提出的 Squeeze-and-Excitation)来实现。对于输入tesnsor的维度是 C x H x W,首先通过一个全局池化层压缩空间信息,然后经过两个中间夹着一个 ReLU 的全连接层(降维 + 升维),这里输出 2K个元素,再接一个归一化层(normalization layer)将输出限定在 (-1, 1)之间(采用【2 * Sigmoid - 1】函数就可以做到)。最后再经过一个初始值和残差的加权和得到最终输出:
θ
(
x
)
=
\theta(x) =
θ(x)=(
a
c
k
a^k_c
ack?,
b
c
k
b^k_c
bck?)
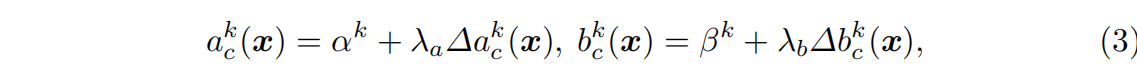
其中 α c k ( x ) \alpha^k_c(x) αck?(x) 和 β c k ( x ) \beta^k_c(x) βck?(x)分别为 a c k a^k_c ack?和 b c k b^k_c bck?的初始值, λ a \lambda_a λa? 和 λ b \lambda_b λb? 分别为残差范围控制标量,也就是加的权。 α c k ( x ) \alpha^k_c(x) αck?(x) 、 β c k ( x ) \beta^k_c(x) βck?(x)、 λ a \lambda_a λa? 和 λ b \lambda_b λb?都是超参数。
2.3、Dynamic ReLU的三个版本
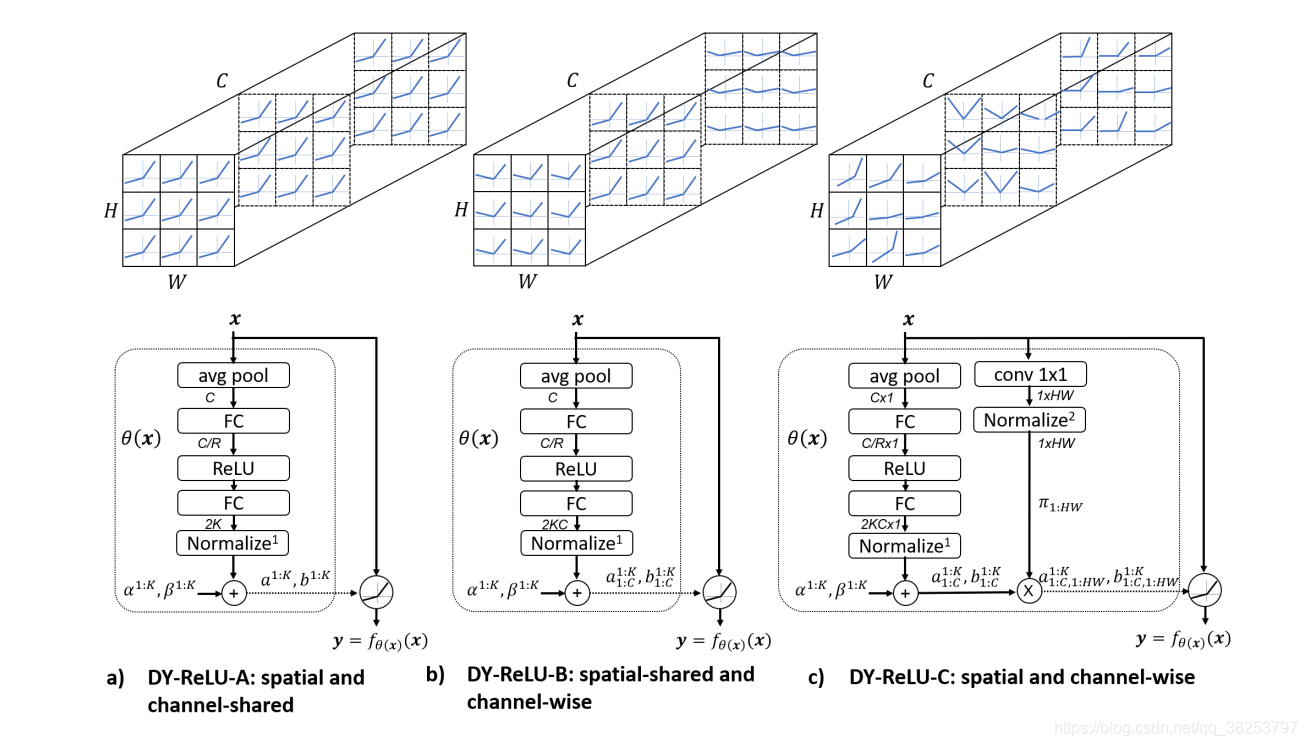
- DY-ReLU-A(空间和通道都共享):所有空间位置和通道共享相同的分段线性激活函数。其超函数的网络结构(如图a)与DY-ReLU B相似,只是输出的数目减少到2K。与DY-ReLU-B相比,DY-ReLU-a的计算量较小,但表示能力较弱。
- DY-ReLU-B(空间共享通道不共享):其网络结构如图2-(B)所示。激活函数需要由超函数计算2KC参数(每个通道2K)。
- DY-ReLU-C (空间通道都不共享)。虽然效果最好,但是参数太大了,不太可能用这个,这里就不讲了,感兴趣的可以看原文。

如上图所示,DY-ReLU可以根据输入x的变化,自动变化几个关键参数,自适应的更换更高效的激活函数,所以我们才称其为动态神经网络。
三、论文实验结果
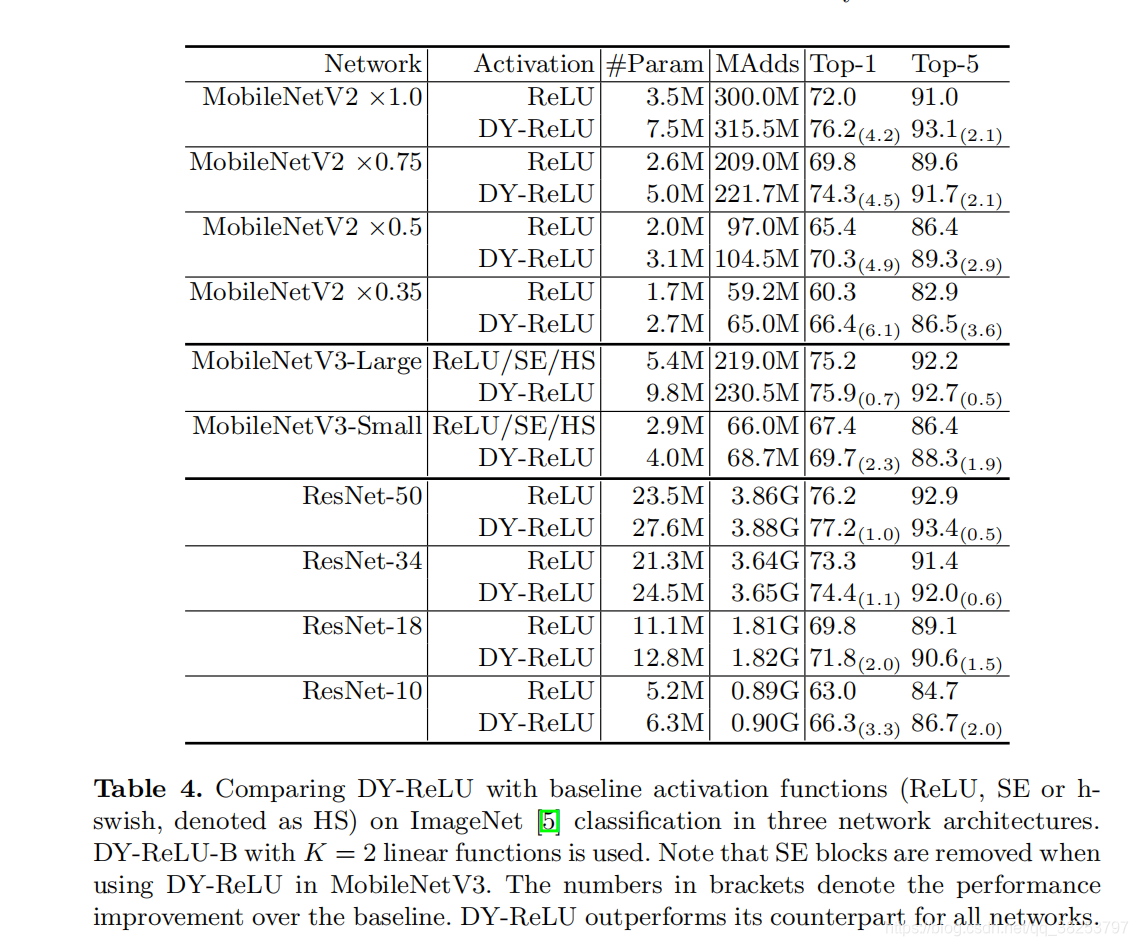
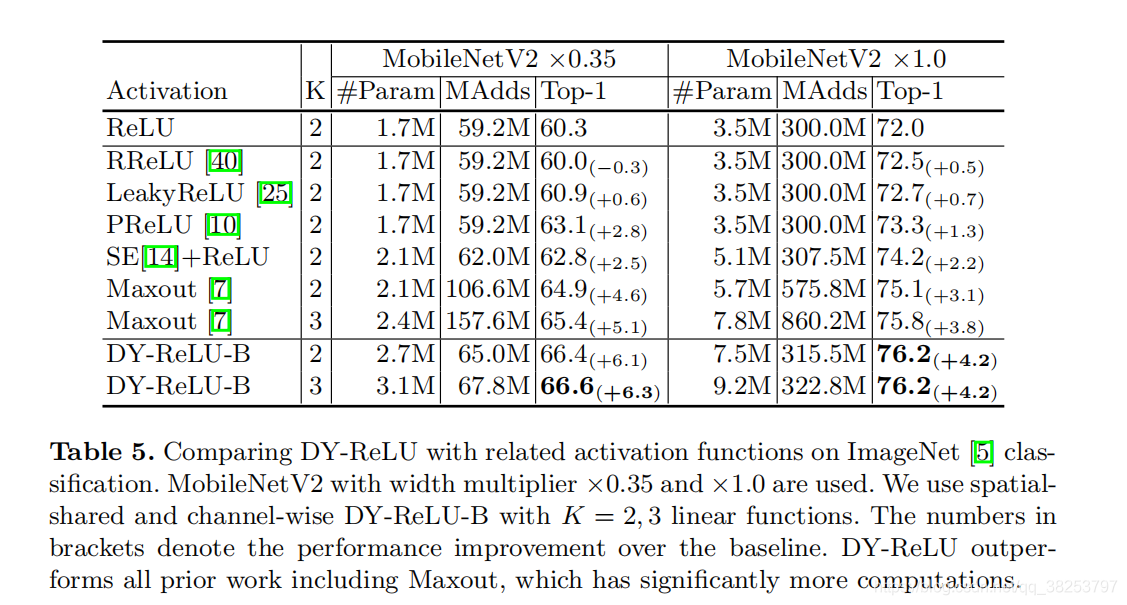
作者通过实验得出以下几点发现:
-
DyReLUB与DyReLUC更适合于图像分类任务;
-
DyReLUB与DyReLUC更适合于关键点检测的骨干网络,而DyReLUC更适合于关键点检测的head网络;
-
在图像分类方面,DyReLU在MobileNetV2的嵌入应用可以得到4.2% 的性能提升;
-
在关键点检测方面,DyReLU的应用可以得到3.5AP的性能提升。
因为DyReLUC的运算量太大,DyReLUA的性能又没那么好,所以我们一般是用DyReLUB。
四、PyTorch实现
这里只实现了前两个版本,第三个版本的参数太大了,一般我们不用。
class DyReLU(nn.Module):
def __init__(self, channels, reduction=4, k=2, conv_type='2d'):
super(DyReLU, self).__init__()
self.channels = channels
self.k = k
self.conv_type = conv_type
assert self.conv_type in ['1d', '2d']
self.fc1 = nn.Linear(channels, channels // reduction)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(channels // reduction, 2*k)
self.sigmoid = nn.Sigmoid()
self.register_buffer('lambdas', torch.Tensor([1.]*k + [0.5]*k).float())
self.register_buffer('init_v', torch.Tensor([1.] + [0.]*(2*k - 1)).float())
def get_relu_coefs(self, x):
theta = torch.mean(x, dim=-1)
if self.conv_type == '2d':
theta = torch.mean(theta, dim=-1)
theta = self.fc1(theta)
theta = self.relu(theta)
theta = self.fc2(theta)
theta = 2 * self.sigmoid(theta) - 1
return theta
def forward(self, x):
raise NotImplementedError
class DyReLUA(DyReLU):
def __init__(self, channels, reduction=4, k=2, conv_type='2d'):
super(DyReLUA, self).__init__(channels, reduction, k, conv_type)
self.fc2 = nn.Linear(channels // reduction, 2*k)
def forward(self, x):
assert x.shape[1] == self.channels
theta = self.get_relu_coefs(x) # 这里是执行到normalize
relu_coefs = theta.view(-1, 2*self.k) * self.lambdas + self.init_v # 这里是执行完 theta(x)
# BxCxL -> LxCxBx1
x_perm = x.transpose(0, -1).unsqueeze(-1)
# a^k_c=relu_coefs[:, :self.k] b^k_c=relu_coefs[:, self.k:]
# a^k_c(x) * x_c + b^k_c(x)
output = x_perm * relu_coefs[:, :self.k] + relu_coefs[:, self.k:]
# LxCxBx2 -> BxCxL
# y_c = max{a^k_c(x) * x_c + b^k_c(x)}
result = torch.max(output, dim=-1)[0].transpose(0, -1)
return result
class DyReLUB(DyReLU):
def __init__(self, channels, reduction=4, k=2, conv_type='2d'):
super(DyReLUB, self).__init__(channels, reduction, k, conv_type)
self.fc2 = nn.Linear(channels // reduction, 2*k*channels)
def forward(self, x):
assert x.shape[1] == self.channels
theta = self.get_relu_coefs(x)
relu_coefs = theta.view(-1, self.channels, 2*self.k) * self.lambdas + self.init_v
if self.conv_type == '1d':
# BxCxL -> LxBxCx1
x_perm = x.permute(2, 0, 1).unsqueeze(-1)
output = x_perm * relu_coefs[:, :, :self.k] + relu_coefs[:, :, self.k:]
# LxBxCx2 -> BxCxL
result = torch.max(output, dim=-1)[0].permute(1, 2, 0)
elif self.conv_type == '2d':
# BxCxHxW -> HxWxBxCx1
x_perm = x.permute(2, 3, 0, 1).unsqueeze(-1)
output = x_perm * relu_coefs[:, :, :self.k] + relu_coefs[:, :, self.k:]
# HxWxBxCx2 -> BxCxHxW
result = torch.max(output, dim=-1)[0].permute(2, 3, 0, 1)
return result
Reference
链接: 博客1.