数据输入与特征工程
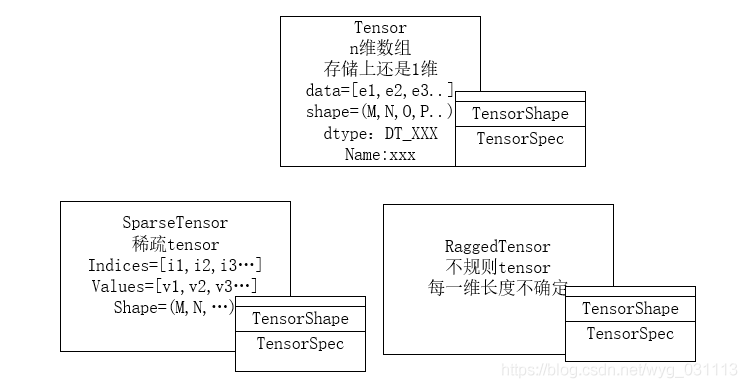
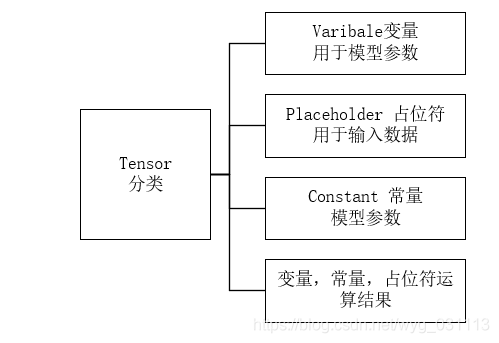
𝑦=𝑓𝑤(𝑥)之(𝑥,𝑦)y=fw(x)之(x,y):是模型的输入数据,对应了机器学习算法工程中的特征工程和模型构建中的模型输入。 w也需要初始化。无论输入如何变化,最终都要转成tensor才能被tensorflow计算。 tensorflow 在实现𝑦=𝑓𝑤(𝑥)y=fw(x)时, 把
-
x,y抽象成tensor;
-
f_w抽象成Model/estimator;
- tensor之间的复杂操作抽象成模型Model,如加减乘除指数对数导数等等。 而每个操作如加法,减法,抽象成一个operator(算子),简称OP. OP也可以自己编写,只要输入输出是tensor就行,内部逻辑 可以任意。
-
调用f,计算损失,更新参数抽象成Model.fit(x_batch)或者estimator.train(x_train_batch),其中x_train_batch是个tensor,只是第一维表示为只是第一维表示为batch_size (batch_size, M,N,...);
-
模型评估抽象为:Model.evalute(x_test_batch)或者estimator.evaluate(x_test_batch)
-
结果预测抽象为:Model.predict(x_new_batch)或者estimator.predict(x_new_batch)
所有过程都可以看作是把一个tensor变换成另一个tensor.因此tensor是唯一确定的输入和输出。因此数据输入就是把原始存储在磁盘,数据库,hdfs等等上的数据转为tensor的过程。为了让转成tensor, 以及让tensor中的数值更好的适用于模型,把原始数据做了一系列变换,这个过程叫特征工程。
keras对输入数据的要求?tf.keras.Model.fit
#Model.fit函数,x,y是输入数据。除此之外还需要参数要输入
fit(
x=None, y=None, batch_size=None, epochs=1, verbose='auto',
callbacks=None, validation_split=0.0, validation_data=None, shuffle=True,
class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None,
validation_steps=None, validation_batch_size=None, validation_freq=1,
max_queue_size=10, workers=1, use_multiprocessing=False
)- x:输入数据
- A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
- A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
- A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
- A tf.data dataset. Should return a tuple of either (inputs, targets) or (inputs, targets, sample_weights).
- A generator or keras.utils.Sequence returning (inputs, targets) or (inputs, targets, sample_weights).
- A tf.keras.utils.experimental.DatasetCreator, which wraps a callable that takes a single argument of type tf.distribute.InputContext, and returns a tf.data.Dataset. DatasetCreator should be used when users prefer to specify the per-replica batching and sharding logic for the Dataset. See tf.keras.utils.experimental.DatasetCreator doc for more information. A more detailed description of unpacking behavior for iterator types (Dataset, generator, Sequence) is given below. If using tf.distribute.experimental.ParameterServerStrategy, only DatasetCreator type is supported for x.
- y Target data. Like the input data x, it could be either Numpy array(s) or TensorFlow tensor(s). It should be consistent with x (you cannot have Numpy inputs and tensor targets, or inversely). If x is a dataset, generator, or keras.utils.Sequence instance, y should not be specified (since targets will be obtained from x).
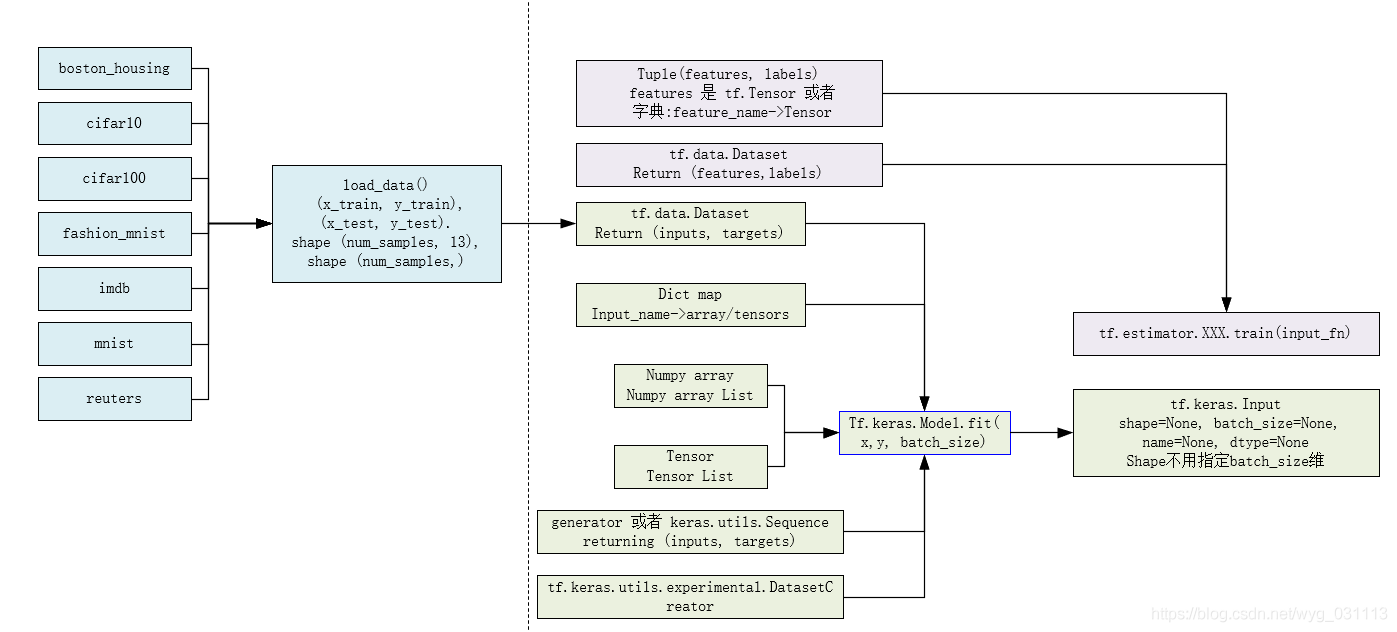
tensorflow高级API keras对特征输入的支持
- tf.keras.datasets
- tf.keras.preprocessing
- tf.keras.utils
- tf.keras.Input
- tf.keras.initializers
tf.keras.datasets
这些数据集可以直接下载使用 - boston_housing module: 波士顿房价预测。Boston housing price regression dataset.
- cifar10 module: CIFAR10 small images classification dataset.
- cifar100 module: CIFAR100 small images classification dataset.
- fashion_mnist module: Fashion-MNIST dataset.
- imdb module: IMDB sentiment classification dataset.
- mnist module: MNIST handwritten digits dataset.
- reuters module: Reuters topic classification dataset.
使用方式
from tensorflow import keras
(X_house_train, y_house_train), (X_house_test, y_house_test) = keras.datasets.boston_housing.load_data()
tf.keras.datasets.boston_housing.load_data(
path='boston_housing.npz', test_split=0.2, seed=113
)波士顿房屋数据,有房子的13个维度,和房子的价格作为label。用于房价预测
参数
- path 保存数据的目标 (relative to ~/.keras/datasets).
- test_split test set占比.
- seed 随机数种子,在分割test前会shuffle数据
返回值
两个tuple, 其中每个都是Numpy 数组: (x_train, y_train), (x_test, y_test). x_train, x_test: shape (num_samples, 13) y_train, y_test: shape (num_samples,) 都是float类型的标量. 在 10 到 50之间,单位是千美元.
tf.keras.preprocessing
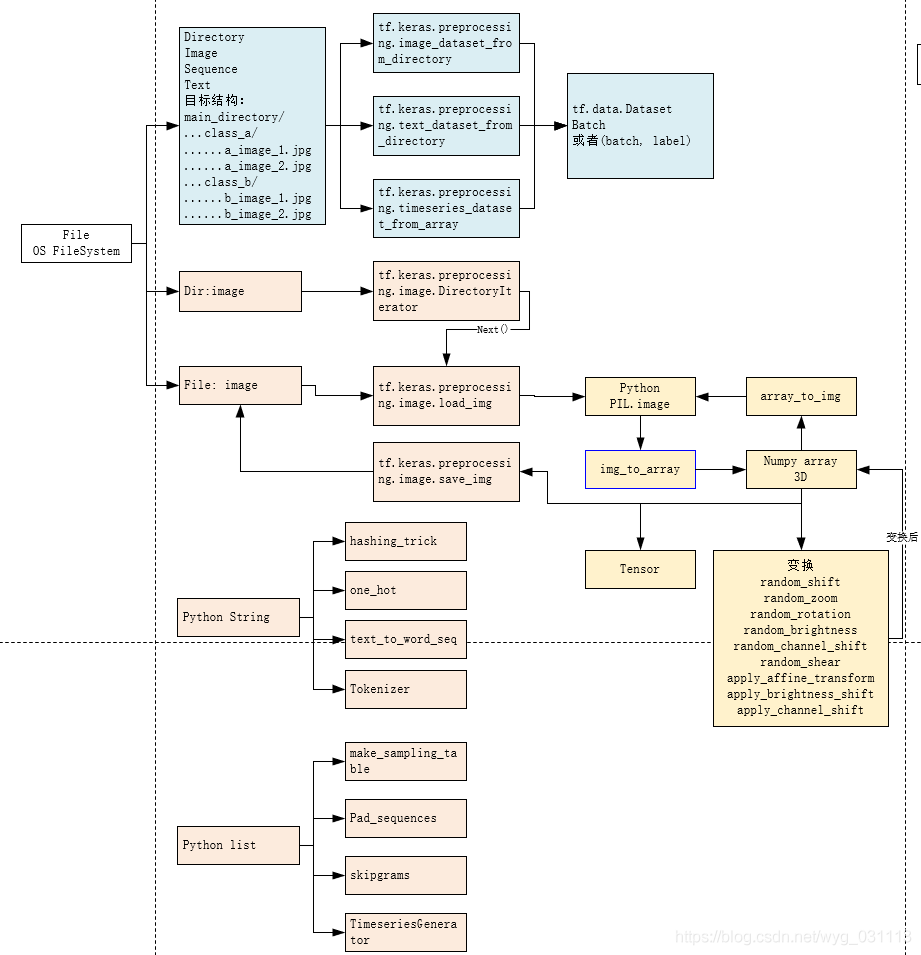 三个函数,方便加载图片,加载文本,对数组进行滑动窗口采样
三个函数,方便加载图片,加载文本,对数组进行滑动窗口采样
-
tf.keras.preprocessing.image_dataset_from_directory从目录加载图片文件
-
tf.keras.preprocessing.text_dataset_from_directory从目录加载文本文件 能根据目录结构,文件名来推断出标签。返回tf.data.Dataset.
main_directory/ ...class_a/ ......a_image_1.jpg ......a_image_2.jpg ...class_b/ ......b_image_1.jpg ......b_image_2.jpgtf_data_dataset = tf.keras.preprocessing.image_dataset_from_directory( directory, labels='inferred', label_mode='int', class_names=None, color_mode='rgb', batch_size=32, image_size=(256, 256), shuffle=True, seed=None, validation_split=None, subset=None, interpolation='bilinear', follow_links=False, smart_resize=False ) tf_data_dataset = tf.keras.preprocessing.text_dataset_from_directory( directory, labels='inferred', label_mode='int', class_names=None, batch_size=32, max_length=None, shuffle=True, seed=None, validation_split=None, subset=None, follow_links=False ) -
tf.keras.preprocessing.timeseries_dataset_from_array?对一个序列进行滑动窗口,形成样本
tf.keras.preprocessing.timeseries_dataset_from_array( data, targets, sequence_length, sequence_stride=1, sampling_rate=1, batch_size=128, shuffle=False, seed=None, start_index=None, end_index=None )Example 1: Consider indices [0, 1, ... 99]. With sequence_length=10, sampling_rate=2, sequence_stride=3, shuffle=False, the dataset will yield batches of sequences composed of the following indices:
First sequence: [0 2 4 6 8 10 12 14 16 18] sampling_rate=2,所以间隔是2. sequence_length=10,所以长度是10 Second sequence: [3 5 7 9 11 13 15 17 19 21] Third sequence: [6 8 10 12 14 16 18 20 22 24] ... Last sequence: [78 80 82 84 86 88 90 92 94 96] 0, 3, 6 。。 38. sequence_stride=3
模块 text
tf.keras.preprocessing.text 处理文本文件,提供了1个类4个函数
- class Tokenizer: Text tokenization utility class.
- hashing_trick(...): Converts a text to a sequence of indexes in a fixed-size hashing space.
- one_hot(...): One-hot encodes a text into a list of word indexes of size n.
- text_to_word_sequence(...): Converts a text to a sequence of words (or tokens).
- tokenizer_from_json(...): Parses a JSON tokenizer configuration file and returns a
tf.keras.preprocessing.text.text_to_word_sequence?字符串转单词序列
tf.keras.preprocessing.text.text_to_word_sequence(
input_text, #python字符串
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', #input_text中的这些字符就不要了
lower=True, split=' ' #分隔符
)
返回一个python list,包含了所有单词,不去重,只是生成序列tf.keras.preprocessing.text.one_hot?单词字符串拆成单词后,one hot编码
返回一个python list,都是数字
tf.keras.preprocessing.text.one_hot(
input_text, n, #n是字符大小,也就是不同的单词的个数
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True, split=' '
)tf.keras.preprocessing.text.hashing_trick?字符分成单词后,转为hash空间中。
tf.keras.preprocessing.text.hashing_trick(
text, n, hash_function=None,
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True, split=' '
)tf.keras.preprocessing.text.tokenizer_from_json?从一个配置文件来构建Tokenizer
tf.keras.preprocessing.text.Tokenizer?词法分析器解析字符串
config="" #json字符串,用来描述
tokenizer = tf.keras.preprocessing.text.tokenizer_from_json(config) #得到了 Tokenizer类的对象
tokenizer=tf.keras.preprocessing.text.Tokenizer(
num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True, split=' ', char_level=False, oov_token=None,
document_count=0, **kwargs
) #直接构造
#Tokenizer类的对象的方法
#构建字典
fit_on_sequences(sequences) #从单词列表
fit_on_texts(texts) #从文本["hello world", "what is"]
get_config() #返回python字典,就是config的python map
#seq是单词的数字序列
#mode: "binary", "count", "tfidf", "freq"
sequences_to_matrix(sequences, mode='binary') #返回numpy矩阵
#数字序列转回单词
sequences_to_texts(sequences)
sequences_to_texts_generator(sequences) #返回的是生成器
#文本直接转numpy矩阵
texts_to_matrix(texts, mode='binary')
texts_to_sequences(texts)
texts_to_sequences_generator(texts)
#返回了config的json字符串
to_json()模块 sequence
对序列数据进行处理。
tf.keras.preprocessing.sequence.pad_sequences?不同长度的序列变成一样长、
tf.keras.preprocessing.sequence.pad_sequences(
sequences, maxlen=None, dtype='int32', padding='pre',
truncating='pre', value=0.0
)seqs = [[1], [2, 3], [4, 5, 6]]
sequence.pad_sequences(seqs)
<class 'numpy.ndarray'>
[[0 0 1]
[0 2 3]
[4 5 6]]tf.keras.preprocessing.sequence.skipgrams?一个 单词左右的的单词
tf.keras.preprocessing.sequence.skipgrams(
sequence, vocabulary_size, window_size=4, negative_samples=1.0, shuffle=True,
categorical=False, sampling_table=None, seed=None
)
sentense = "The quick brown fox jumps over lazy dog"
couples, labels = tf.keras.preprocessing.sequence.skipgrams(words_seq,
vocabulary_size=8,window_size=3,shuffle=False,negative_samples=0.2)
#couples:
#[['the', 'quick'], ['the', 'brown'], ['the', 'fox'], ['quick', 'the'], ['quick', 'brown'], ['quick', 'fox'], ['quick', 'jumps'], ...]
#labels: [1,1,1,1,...0,0,0] 0是负样本- (word, word in the same window), with label 1 (positive samples).
- (word, random word from the vocabulary), with label 0 (negative samples).
tf.keras.preprocessing.sequence.make_sampling_table生成一个基于单词的概率采样表。
用来生成 skipgrams 的 sampling_table 参数。sampling_table[i] 是数据集中第 i 个最常见词的采样概率(出于平衡考虑,出现更频繁的词应该被更少地采样)。
tf.keras.preprocessing.sequence.make_sampling_table(
size, sampling_factor=1e-05
)sampling_factor是word2vec公式中的参数:?𝑝(𝑤𝑜𝑟𝑑)=(𝑚𝑖𝑛(1,𝑠𝑞𝑟𝑡(𝑤𝑜𝑟𝑑𝑓𝑟𝑒𝑞𝑢𝑒𝑛𝑐𝑦/𝑠𝑎𝑚𝑝𝑙𝑖𝑛𝑔𝑓𝑎𝑐𝑡𝑜𝑟)/(𝑤𝑜𝑟𝑑𝑓𝑟𝑒𝑞𝑢𝑒𝑛𝑐𝑦/𝑠𝑎𝑚𝑝𝑙𝑖𝑛𝑔𝑓𝑎𝑐𝑡𝑜𝑟)))p(word)=(min(1,sqrt(wordfrequency/samplingfactor)/(wordfrequency/samplingfactor)))
tf.keras.preprocessing.sequence.TimeseriesGenerator?按一定步长和滑动窗口生产序列
tf.keras.preprocessing.sequence.TimeseriesGenerator(
data, targets, length, sampling_rate=1, stride=1, start_index=0, end_index=None,
shuffle=False, reverse=False, batch_size=128
)用于生成批量时序数据的实用工具类。这个类以一系列由相等间隔以及一些时间序列参数(例如步长、历史长度等)汇集的数据点作为输入,以生成用于训练/验证的批次数据。
- data: 可索引的生成器(例如列表或 Numpy 数组),包含连续数据点(时间步)。数据应该是 2D 的,且第 0 个轴为时间维度。
- targets: 对应于 data 的时间步的目标值。它应该与 data 的长度相同。
- length: 输出序列的长度(以时间步数表示)。
- sampling_rate: 序列内连续各个时间步之间的周期。对于周期 r, 时间步 data[i], data[i-r], ... data[i - length] 被用于生成样本序列。
- stride: 连续输出序列之间的周期. 对于周期 s, 连续输出样本将为 data[i], data[i+s], data[i+2*s] 等。
- start_index: 在 start_index 之前的数据点在输出序列中将不被使用。这对保留部分数据以进行测试或验证很有用。
- end_index: 在 end_index 之后的数据点在输出序列中将不被使用。这对保留部分数据以进行测试或验证很有用。
- shuffle: 是否打乱输出样本,还是按照时间顺序绘制它们。
- reverse: 布尔值: 如果 true, 每个输出样本中的时间步将按照时间倒序排列。
- batch_size: 每个批次中的时间序列样本数(可能除最后一个外)。
模块 image
tf.keras.preprocessing.image.load_img?加载图成为python PIL.Image
tf.keras.preprocessing.image.save_img?保存PIL.Image到文件
tf.keras.preprocessing.image.load_img(
path, grayscale=False, color_mode='rgb', target_size=None,
interpolation='nearest'
)tf.keras.preprocessing.image.img_to_array?python PIL.Image转numpy 3D array
tf.keras.preprocessing.image.array_to_img?numpy 3D array转 python PIL.Image
tf.keras.preprocessing.image.img_to_array(
img, data_format=None, dtype=None
)
tf.keras.preprocessing.image.array_to_img(
x, data_format=None, scale=True, dtype=None
)tf.keras.preprocessing.image.random_zoom?缩放
tf.keras.preprocessing.image.random_zoom(
x, #numpy 3d tensor 如(1024, 768, 3)
zoom_range, # >1是缩小,<1是放大(0.5, 2)表示width放大一倍,height缩小
row_axis=1, col_axis=2, channel_axis=0, #与tensor对应。(1024, 768, 3)对就的是(0,1,2)。就是指出tensor中哪一维是宽,哪一维是高,哪一维是通道。
fill_mode='nearest', #变换后,缺失的位置怎么补{'constant', 'nearest', 'reflect', 'wrap'}
cval=0.0, #如果fill_mode是constant,这里指定补什么颜色值
interpolation_order=1 #插值方式
)tf.keras.preprocessing.image.ImageDataGenerator?变换已经有的少量图片,得到更多图片.这叫图片数据增强
在样本图片 比较小的情况下,可以对样本进行旋转,缩放,变形,变色,翻转以形成更多样本。 参数介绍看数据增强――Keras Image Data Augmentation 各参数详解
tf.keras.preprocessing.image.ImageDataGenerator(
featurewise_center=False, samplewise_center=False,
featurewise_std_normalization=False, samplewise_std_normalization=False,
zca_whitening=False, zca_epsilon=1e-06, rotation_range=0, width_shift_range=0.0,
height_shift_range=0.0, brightness_range=None, shear_range=0.0, zoom_range=0.0,
channel_shift_range=0.0, fill_mode='nearest', cval=0.0,
horizontal_flip=False, vertical_flip=False, rescale=None,
preprocessing_function=None, data_format=None, validation_split=0.0, dtype=None
)tf.keras.preprocessing.image.random_shift平移图像
tf.keras.preprocessing.image.random_shift(
x, #3d tensor
wrg, hrg, #0到1的小数
row_axis=1, col_axis=2, channel_axis=0,
fill_mode='nearest', cval=0.0, interpolation_order=1
)tf.keras.preprocessing.image.random_shear错切
tf.keras.preprocessing.image.random_shear(
x,#3d tensor
intensity, 错切度数
row_axis=1, col_axis=2, channel_axis=0,
fill_mode='nearest', cval=0.0, interpolation_order=1
)tf.keras.preprocessing.image.random_rotation?旋转
tf.keras.preprocessing.image.random_rotation(
x, #3d tensor
rg, #旋转度数
row_axis=1, col_axis=2, channel_axis=0, fill_mode='nearest',
cval=0.0, interpolation_order=1
)tf.keras.preprocessing.image.random_channel_shift通道偏移
tf.keras.preprocessing.image.random_channel_shift(
x, #3d tensor
intensity_range, #偏移
channel_axis=0
)tf.keras.preprocessing.image.random_brightness
tf.keras.preprocessing.image.random_brightness(
x, brightness_range
)tf.keras.preprocessing.image.apply_affine_transform仿射变换
tf.keras.preprocessing.image.apply_brightness_shift亮度调整
tf.keras.preprocessing.image.apply_channel_shift色彩通道
迭代目录并动态增强图片
- tf.keras.preprocessing.image.Iterator
- tf.keras.preprocessing.image.DirectoryIterator?#迭代一个目录下的所有图片,自动推断类别
- tf.keras.preprocessing.image.ImageDataGenerator?#更强大的图片增强
- apply_transform
- fit
- flow
- flow_from_dataframe
- flow_from_directory
- get_random_transform
- random_transform
- standardize
tf.keras.preprocessing.image.Iterator( n, batch_size, shuffle, seed ) tf.keras.preprocessing.image.DirectoryIterator( directory, #目录,子目录代表一个类别,字典序 image_data_generator, target_size=(256, 256), # color_mode='rgb', classes=None, class_mode='categorical', batch_size=32, shuffle=True, seed=None, data_format=None, save_to_dir=None, save_prefix='', save_format='png', follow_links=False, subset=None, interpolation='nearest', dtype=None ) tf.keras.preprocessing.image.ImageDataGenerator( featurewise_center=False, samplewise_center=False, featurewise_std_normalization=False, samplewise_std_normalization=False, zca_whitening=False, zca_epsilon=1e-06, rotation_range=0, width_shift_range=0.0, height_shift_range=0.0, brightness_range=None, shear_range=0.0, zoom_range=0.0, channel_shift_range=0.0, fill_mode='nearest', cval=0.0, horizontal_flip=False, vertical_flip=False, rescale=None, preprocessing_function=None, data_format=None, validation_split=0.0, dtype=None )
tf.keras.utils 对输入数据的支持
tf.keras.utils.get_file下载文件
下载文件并缓存到~/.keras/dataset/,返回下载后绝对路径 fname指定缓存文件名
tf.keras.utils.get_file(
fname, origin, untar=False, md5_hash=None, file_hash=None,
cache_subdir='datasets', hash_algorithm='auto',
extract=False, archive_format='auto', cache_dir=None
)tf.keras.utils.Sequencebatch 生成器
必须能迭代,实现getitem,?len,?iter. 可以作为fit的输入
from skimage.io import imread
from skimage.transform import resize
import numpy as np
import math
# Here, `x_set` is list of path to the images
# and `y_set` are the associated classes.
class CIFAR10Sequence(Sequence):
def __init__(self, x_set, y_set, batch_size):
self.x, self.y = x_set, y_set
self.batch_size = batch_size
def __len__(self):
return math.ceil(len(self.x) / self.batch_size)
def __getitem__(self, idx):
batch_x = self.x[idx * self.batch_size:(idx + 1) *
self.batch_size]
batch_y = self.y[idx * self.batch_size:(idx + 1) *
self.batch_size]
return np.array([
resize(imread(file_name), (200, 200))
for file_name in batch_x]), np.array(batch_y)tf.keras.utils.experimental.DatasetCreator?生成dataset, 尤其在分布式环境下
model = tf.keras.Sequential([tf.keras.layers.Dense(10)])
model.compile(tf.keras.optimizers.SGD(), loss="mse")
def dataset_fn(input_context):
global_batch_size = 64
batch_size = input_context.get_per_replica_batch_size(global_batch_size)
dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat()
dataset = dataset.shard(
input_context.num_input_pipelines, input_context.input_pipeline_id)
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(2)
return dataset
model.fit(DatasetCreator(dataset_fn), epochs=10, steps_per_epoch=10)
#分布式环境下
strategy = tf.distribute.experimental.ParameterServerStrategy(
cluster_resolver)
with strategy.scope():
model = tf.keras.Sequential([tf.keras.layers.Dense(10)])
model.compile(tf.keras.optimizers.SGD(), loss="mse")
...模型输入tf.keras.Input
返回的是tensor, 实际上会有PlaceHolder.作为模型的第一层。 shape中不包含样本数量,只是样本形状。
tf.keras.Input(
shape=None, batch_size=None, name=None, dtype=None, sparse=None, tensor=None,
ragged=None, type_spec=None, **kwargs
)
input = tf.keras.Input((216,16))
print(input)
KerasTensor(type_spec=TensorSpec(shape=(None, 216, 16), dtype=tf.float32, name='input_2'), name='input_2', description="created by layer 'input_2'")
输入也可以是个字典:
inputs = {
'movieAvgRating': tf.keras.layers.Input(name='movieAvgRating', shape=(), dtype='float32'),
'movieRatingStddev': tf.keras.layers.Input(name='movieRatingStddev', shape=(), dtype='float32'),
'movieRatingCount': tf.keras.layers.Input(name='movieRatingCount', shape=(), dtype='int32'),
'userAvgRating': tf.keras.layers.Input(name='userAvgRating', shape=(), dtype='float32'),
'userRatingStddev': tf.keras.layers.Input(name='userRatingStddev', shape=(), dtype='float32'),
...
}tf.keras.initializers模型参数初始化
模型中有很多参数,这些参数需要初始值。
model.add(Dense(64,
kernel_initializer='random_uniform', #指定w初始化方式
bias_initializer='zeros')) #指定b初始化方式
from keras import initializers
model.add(Dense(64, kernel_initializer=initializers.random_normal(stddev=0.01)))
# also works; will use the default parameters.
model.add(Dense(64, kernel_initializer='random_normal'))
#自定义初始化
from tensorflow.keras import backend as K
def my_init(shape, dtype=None):
return K.random_normal(shape, dtype=dtype)
model.add(Dense(64, init=my_init))
#
import tensorflow.keras.initializers as init
#初始化值的保存与加载
cfg = init.Constant(11).get_config() #序列化成json
print(cfg)
c = init.Constant(11).from_config(cfg) #从json加载
print(c)
values = c(shape=(2, 2)) #生成真正的tensor
print(values)
#{'value': 11}
#<tensorflow.python.keras.initializers.initializers_v2.Constant object at 0x000002B7DCCA3BC8>
#tf.Tensor(
#[[11. 11.]
# [11. 11.]], shape=(2, 2), dtype=float32)当前支持的初始化方式
Classes
class Constant: Initializer that generates tensors with constant values.
class GlorotNormal: The Glorot normal initializer, also called Xavier normal initializer.
class GlorotUniform: The Glorot uniform initializer, also called Xavier uniform initializer.
class HeNormal: He normal initializer.
class HeUniform: He uniform variance scaling initializer.
class Identity: Initializer that generates the identity matrix.
class Initializer: Initializer base class: all Keras initializers inherit from this class.
class LecunNormal: Lecun normal initializer.
class LecunUniform: Lecun uniform initializer.
class Ones: Initializer that generates tensors initialized to 1.
class Orthogonal: Initializer that generates an orthogonal matrix.
class RandomNormal: Initializer that generates tensors with a normal distribution.
class RandomUniform: Initializer that generates tensors with a uniform distribution.
class TruncatedNormal: Initializer that generates a truncated normal distribution.
class VarianceScaling: Initializer capable of adapting its scale to the shape of weights tensors.
class Zeros: Initializer that generates tensors initialized to 0.
class constant: Initializer that generates tensors with constant values.
class glorot_normal: The Glorot normal initializer, also called Xavier normal initializer.
class glorot_uniform: The Glorot uniform initializer, also called Xavier uniform initializer.
class he_normal: He normal initializer.
class he_uniform: He uniform variance scaling initializer.
class identity: Initializer that generates the identity matrix.
class lecun_normal: Lecun normal initializer.
class lecun_uniform: Lecun uniform initializer.
class ones: Initializer that generates tensors initialized to 1.
class orthogonal: Initializer that generates an orthogonal matrix.
class random_normal: Initializer that generates tensors with a normal distribution.
class random_uniform: Initializer that generates tensors with a uniform distribution.
class truncated_normal: Initializer that generates a truncated normal distribution.
class variance_scaling: Initializer capable of adapting its scale to the shape of weights tensors.
class zeros: Initializer that generates tensors initialized to 0.initializer序列化与反序列化
tf.keras.initializers.serialize(
initializer
)
tf.keras.initializers.deserialize(
config, custom_objects=None
)
tf.keras.initializers.get(
identifier
)
identifier = 'Ones'
tf.keras.initializers.deserialize(identifier)
cfg = {'class_name': 'Ones', 'config': {} }
tf.keras.initializers.deserialize(cfg)
tensorflow低级API 对特征输入的支持
- tf.data
- tf.io
- tf.audio
- tf.config
- tf.image
- tf.initializer
- tf.queue
- tf.random
tf.io & tf.data
dataset是tensorflow抽像出来的数据集,每个元素表示一条数据,形状和数据类型一样。可以按batch大小拿出tensor. 同时支持数据的map reduce filter, flatmap,shuffle, window, shard等等变换,类型spark里的rdd。dataset不会加载所有数据,支持多worker分布式读取。所有模型的的输入都可以用dataset。 tf.data.experimental里还有更多的功能,如从csv文件加载,从SQL查询中加载等等。dataset可以是普通tensor,也可以是个字典,key是列名,值是tensor,字典可以看成是csv文件,json文件或者说数据库中的表。
本质上,io的作用是把存储在文件里的各种格式数据,如csv, TFRecord转成tensor。tensorflow提供了扩展ReaderOP的实现。参见:官网readerOP扩展.?国内博友翻译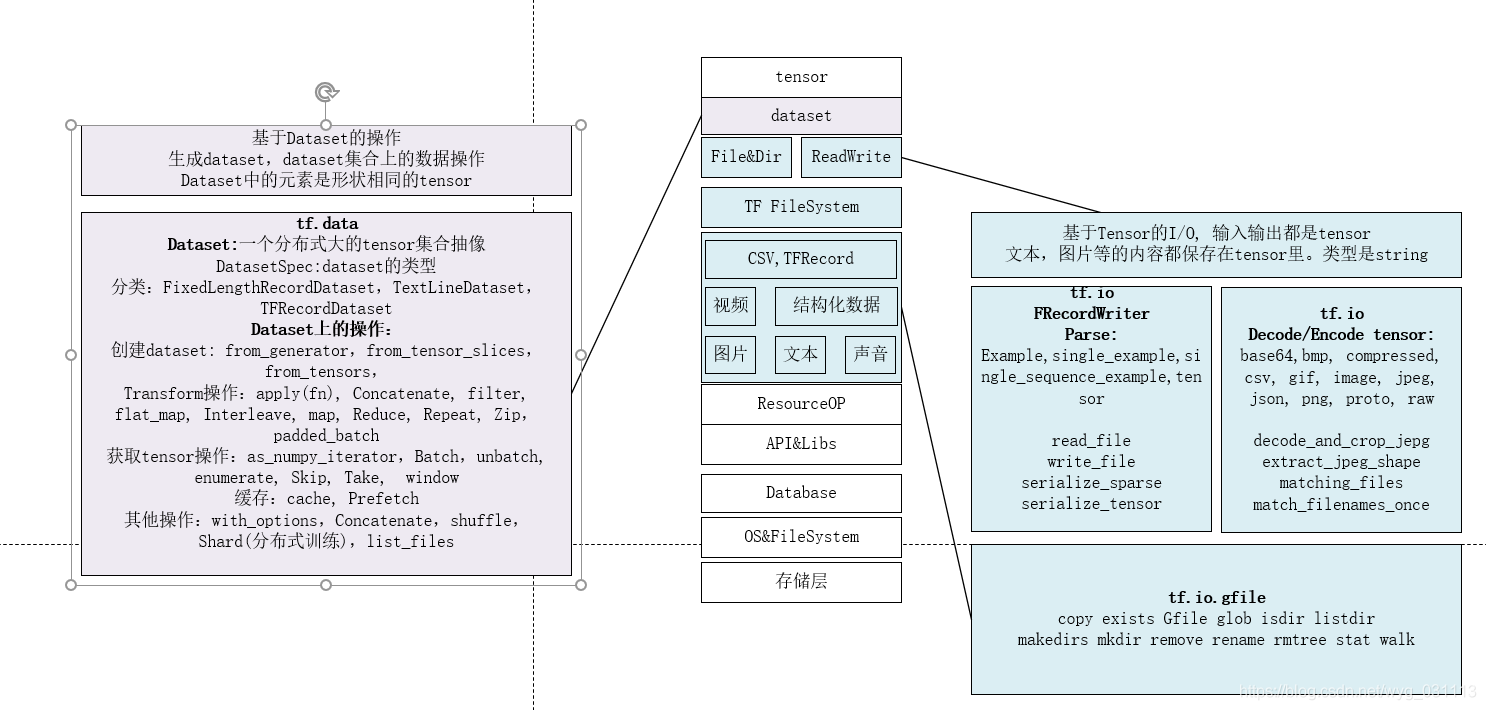
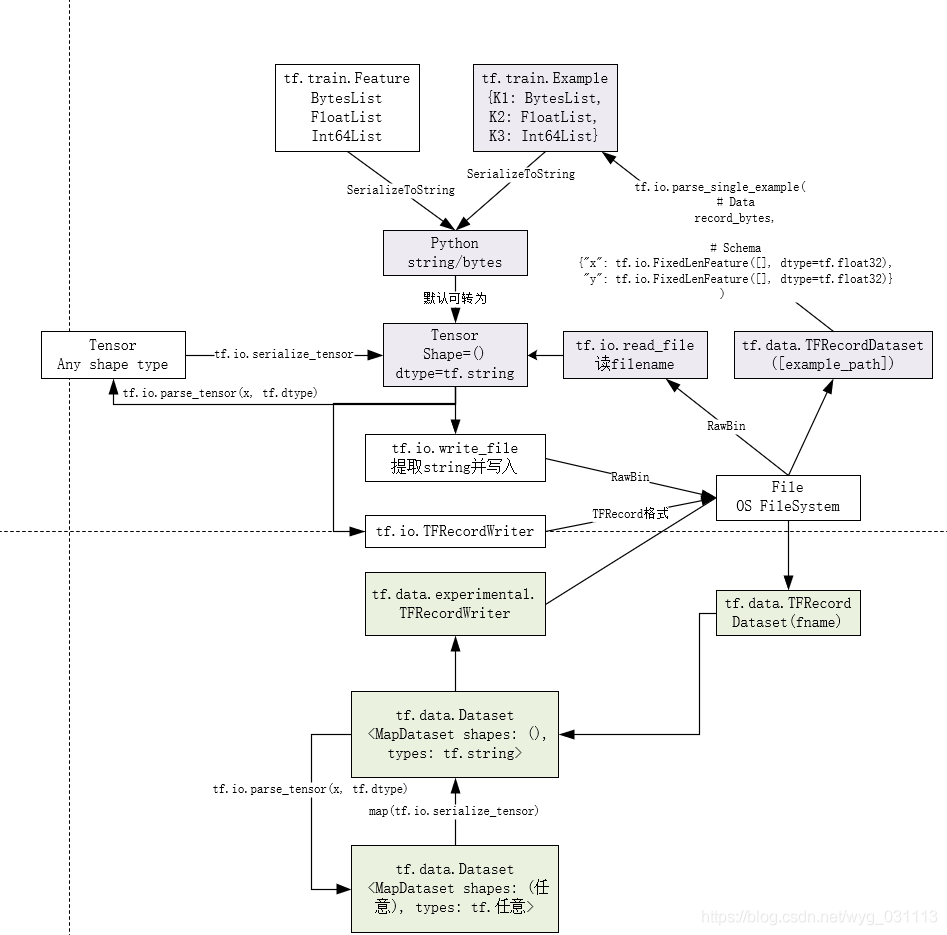
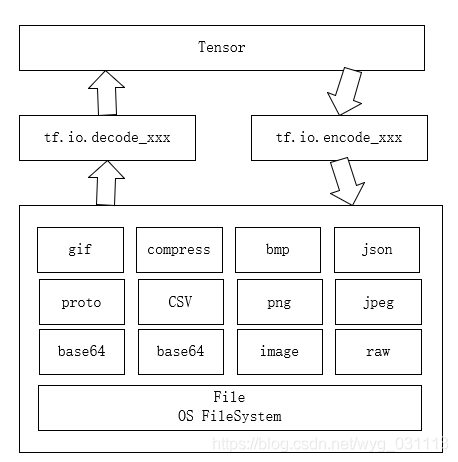
tensorflow入门教程中的数据输入
tf.train下的数据输入支持
- tf.train.Example?tf.train.Example是个字典{"string": tf.train.Feature}. 这是一种序列化字典的方式。
- tf.train.Feature?Feature是个List. 三种基本的List:
- tf.train.BytesList
- tf.train.FloatList
- tf.train.Int64List 一个TFRecord是ByteList,其二进制格式如下:
uint64 length uint32 masked_crc32_of_length byte data[length] uint32 masked_crc32_of_data
- 普通变量转这三种List。
# The following functions can be used to convert a value to a type compatible # with tf.train.Example. def _bytes_feature(value): """Returns a bytes_list from a string / byte.""" if isinstance(value, type(tf.constant(0))): value = value.numpy() # BytesList won't unpack a string from an EagerTensor. return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value])) def _float_feature(value): """Returns a float_list from a float / double.""" return tf.train.Feature(float_list=tf.train.FloatList(value=[value])) def _int64_feature(value): """Returns an int64_list from a bool / enum / int / uint.""" return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
tensorflow特征工程支持
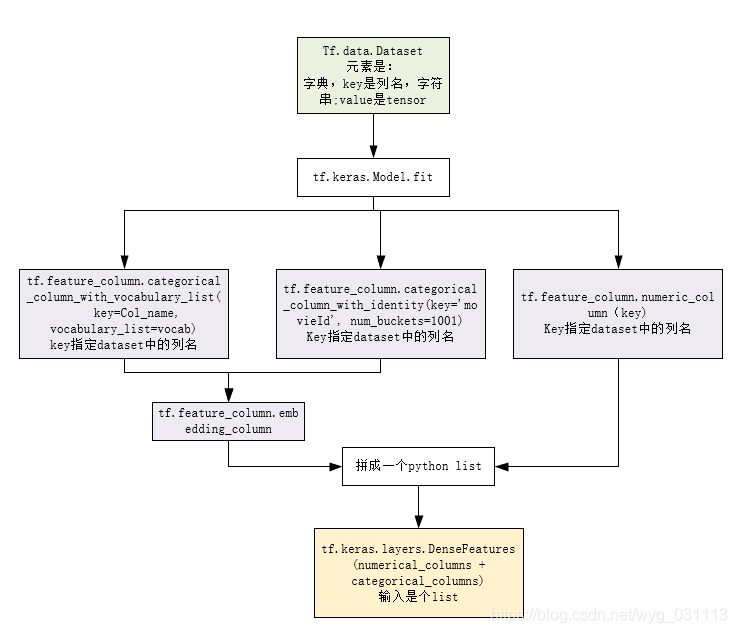
有些特征不能直接输出模型,如姓别,爱好,年龄,行为序列等等。 这些非数值特征要先进行编码,有one_hot编码,一般再进行embedding, 数值特征要可能需要规一化,标准化,正则化等等处理, 最后特征可能需要交叉连接,形成一个向量,或者张量。可以使用spark来做这些事儿,也可以使用tensorflow feature_column来做。 tensorflow的feature_column实际上是模型的一部分。 dataset的元素必须是字符映射tensor格式,如下.此时在feature_column的各输入函数中就能用列名来指定一个列数据了。?tf.feature_column
(OrderedDict([
('movieId', <tf.Tensor: shape=(12,), dtype=int32, numpy=array([292, 253, 539, 802, 79, 163, 196, 917, 480, 153, 213, 750])>),
('userId', <tf.Tensor: shape=(12,), dtype=int32, numpy=
array([26000, 19286, 16527, 5226, 23202, 22256, 21950, 27371, 21495,
6152, 2349, 17741])>),
('rating', <tf.Tensor: shape=(12,), dtype=float32, numpy=
array([3. , 3. , 3. , 4. , 4. , 3. , 4. , 5. , 4. , 1. , 0.5, 5. ],
dtype=float32)>),
('timestamp', <tf.Tensor: shape=(12,), dtype=int32, numpy=
array([ 942284088, 835618121, 941651641, 854922814, 840455142,
845462831, 833897208, 909236959, 1284984585, 976211476,
1192731033, 942317141])>),
('releaseYear', <tf.Tensor: shape=(12,), dtype=int32, numpy=
array([1995, 1994, 1993, 1996, 1996, 1995, 1995, 1939, 1993, 1995, 1994,
1964])>),
('movieGenre1', <tf.Tensor: shape=(12,), dtype=string, numpy=
array([b'Action', b'Drama', b'Comedy', b'Drama', b'Drama', b'Action',
b'Horror', b'Children', b'Action', b'Action', b'Drama', b'Comedy'],
dtype=object)>),
...
]
?
In?[37]:
#image_dataset_from_directory 的例子
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
ds = tf.keras.preprocessing.image_dataset_from_directory(
"../data/food",
labels="inferred",
label_mode="int",
class_names=None,
color_mode="rgb",
batch_size=1,
image_size=(864, 1920),
shuffle=True,
seed=None,
validation_split=None,
subset=None,
interpolation="bilinear",
follow_links=False,
)
print(type(ds))
for attr in dir(ds):
if attr.startswith("_"):
continue
print(attr)
Found 4 files belonging to 2 classes.
<class 'tensorflow.python.data.ops.dataset_ops.BatchDataset'>
apply
as_numpy_iterator
batch
cache
cardinality
class_names
concatenate
element_spec
enumerate
file_paths
filter
flat_map
from_generator
from_tensor_slices
from_tensors
interleave
list_files
map
options
padded_batch
prefetch
range
reduce
repeat
shard
shuffle
skip
take
unbatch
window
with_options
zip
In?[64]:
# 文本处理的例子
import tensorflow.keras.preprocessing.text as txt
sentense="what? tensorflow preprocessing module has an text split function. So we test text"
words = txt.text_to_word_sequence(sentense, "?.", True, ' ')
print(type(words), words)
?
print("one_hot")
one_hot = tf.keras.preprocessing.text.one_hot(
sentense, 200,
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True, split=' '
)
print(one_hot)
print("hashing_trick")
hashing_trick = tf.keras.preprocessing.text.hashing_trick(
sentense, 200, hash_function=None,
filters='?.',
lower=True, split=' '
)
print(hashing_trick)
?
tokenizer=tf.keras.preprocessing.text.Tokenizer(
num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True, split=' ', char_level=False, oov_token=None,
document_count=0
)
tokenizer.fit_on_texts([sentense])
fre = tokenizer.word_counts
?
for i in fre.items():
print(i[0], " : ", i[1])
seqs = tokenizer.texts_to_sequences([sentense])
print(seqs)
print(tokenizer.texts_to_matrix([sentense, "what text"]))
print(tokenizer.sequences_to_texts(seqs))
print(tokenizer.to_json())
<class 'list'> ['what', 'tensorflow', 'preprocessing', 'module', 'has', 'an', 'text', 'split', 'function', 'so', 'we', 'test', 'text']
one_hot
[18, 185, 93, 54, 136, 118, 27, 59, 38, 123, 194, 64, 27]
hashing_trick
[18, 185, 93, 54, 136, 118, 27, 59, 38, 123, 194, 64, 27]
what : 1
tensorflow : 1
preprocessing : 1
module : 1
has : 1
an : 1
text : 2
split : 1
function : 1
so : 1
we : 1
test : 1
[[2, 3, 4, 5, 6, 7, 1, 8, 9, 10, 11, 12, 1]]
[[0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[0. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
['what tensorflow preprocessing module has an text split function so we test text']
{"class_name": "Tokenizer", "config": {"num_words": null, "filters": "!\"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n", "lower": true, "split": " ", "char_level": false, "oov_token": null, "document_count": 1, "word_counts": "{\"what\": 1, \"tensorflow\": 1, \"preprocessing\": 1, \"module\": 1, \"has\": 1, \"an\": 1, \"text\": 2, \"split\": 1, \"function\": 1, \"so\": 1, \"we\": 1, \"test\": 1}", "word_docs": "{\"split\": 1, \"function\": 1, \"module\": 1, \"preprocessing\": 1, \"test\": 1, \"an\": 1, \"tensorflow\": 1, \"what\": 1, \"has\": 1, \"so\": 1, \"we\": 1, \"text\": 1}", "index_docs": "{\"8\": 1, \"9\": 1, \"5\": 1, \"4\": 1, \"12\": 1, \"7\": 1, \"3\": 1, \"2\": 1, \"6\": 1, \"10\": 1, \"11\": 1, \"1\": 1}", "index_word": "{\"1\": \"text\", \"2\": \"what\", \"3\": \"tensorflow\", \"4\": \"preprocessing\", \"5\": \"module\", \"6\": \"has\", \"7\": \"an\", \"8\": \"split\", \"9\": \"function\", \"10\": \"so\", \"11\": \"we\", \"12\": \"test\"}", "word_index": "{\"text\": 1, \"what\": 2, \"tensorflow\": 3, \"preprocessing\": 4, \"module\": 5, \"has\": 6, \"an\": 7, \"split\": 8, \"function\": 9, \"so\": 10, \"we\": 11, \"test\": 12}"}}
In?[78]:
from tensorflow.keras.preprocessing import sequence
import tensorflow.keras.preprocessing.text as txt
seqs = [[1], [2, 3], [4, 5, 6]]
seqs_padding = sequence.pad_sequences(seqs)
print(type(seqs_padding))
print(seqs_padding)
?
sentense = "The quick brown fox jumps over lazy dog"
words_seq = txt.text_to_word_sequence(sentense, "?.", True, ' ')
print(type(words), words)
?
?
couples, labels = tf.keras.preprocessing.sequence.skipgrams(words_seq,
vocabulary_size=8,window_size=3,shuffle=False,negative_samples=0.2)
?
print(couples)
print(labels)
tf.keras.preprocessing.sequence.make_sampling_table(
100, sampling_factor=1e-05
)
?
from tensorflow.keras.preprocessing.sequence import TimeseriesGenerator
import numpy as np
data = np.array([[i] for i in range(50)])
targets = np.array([[i] for i in range(50)])
print("data:", data)
print("targets:", targets)
data_gen = TimeseriesGenerator(data, targets,
length=10, sampling_rate=2,
batch_size=2)
print("data_gen:", [x for x in data_gen])
assert len(data_gen) == 20
batch_0 = data_gen[0]
x, y = batch_0
?
assert np.array_equal(x,
np.array([[[0], [2], [4], [6], [8]],
[[1], [3], [5], [7], [9]]]))
assert np.array_equal(y,
np.array([[10], [11]]))
?
<class 'numpy.ndarray'>
[[0 0 1]
[0 2 3]
[4 5 6]]
<class 'list'> ['what', 'tensorflow', 'preprocessing', 'module', 'has', 'an', 'text', 'split', 'function', 'so', 'we', 'test', 'text']
[['the', 'quick'], ['the', 'brown'], ['the', 'fox'], ['quick', 'the'], ['quick', 'brown'], ['quick', 'fox'], ['quick', 'jumps'], ['brown', 'the'], ['brown', 'quick'], ['brown', 'fox'], ['brown', 'jumps'], ['brown', 'over'], ['fox', 'the'], ['fox', 'quick'], ['fox', 'brown'], ['fox', 'jumps'], ['fox', 'over'], ['fox', 'lazy'], ['jumps', 'quick'], ['jumps', 'brown'], ['jumps', 'fox'], ['jumps', 'over'], ['jumps', 'lazy'], ['jumps', 'dog'], ['over', 'brown'], ['over', 'fox'], ['over', 'jumps'], ['over', 'lazy'], ['over', 'dog'], ['lazy', 'fox'], ['lazy', 'jumps'], ['lazy', 'over'], ['lazy', 'dog'], ['dog', 'jumps'], ['dog', 'over'], ['dog', 'lazy'], ['over', 6], ['dog', 5], ['jumps', 2], ['lazy', 7], ['brown', 5], ['fox', 3], ['the', 4]]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]
data: [[ 0]
[ 1]
[ 2]
[ 3]
[ 4]
[ 5]
[ 6]
[ 7]
[ 8]
[ 9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
[18]
[19]
[20]
[21]
[22]
[23]
[24]
[25]
[26]
[27]
[28]
[29]
[30]
[31]
[32]
[33]
[34]
[35]
[36]
[37]
[38]
[39]
[40]
[41]
[42]
[43]
[44]
[45]
[46]
[47]
[48]
[49]]
targets: [[ 0]
[ 1]
[ 2]
[ 3]
[ 4]
[ 5]
[ 6]
[ 7]
[ 8]
[ 9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
[18]
[19]
[20]
[21]
[22]
[23]
[24]
[25]
[26]
[27]
[28]
[29]
[30]
[31]
[32]
[33]
[34]
[35]
[36]
[37]
[38]
[39]
[40]
[41]
[42]
[43]
[44]
[45]
[46]
[47]
[48]
[49]]
data_gen: [(array([[[0],
[2],
[4],
[6],
[8]],
[[1],
[3],
[5],
[7],
[9]]]), array([[10],
[11]])), (array([[[ 2],
[ 4],
[ 6],
[ 8],
[10]],
[[ 3],
[ 5],
[ 7],
[ 9],
[11]]]), array([[12],
[13]])), (array([[[ 4],
[ 6],
[ 8],
[10],
[12]],
[[ 5],
[ 7],
[ 9],
[11],
[13]]]), array([[14],
[15]])), (array([[[ 6],
[ 8],
[10],
[12],
[14]],
[[ 7],
[ 9],
[11],
[13],
[15]]]), array([[16],
[17]])), (array([[[ 8],
[10],
[12],
[14],
[16]],
[[ 9],
[11],
[13],
[15],
[17]]]), array([[18],
[19]])), (array([[[10],
[12],
[14],
[16],
[18]],
[[11],
[13],
[15],
[17],
[19]]]), array([[20],
[21]])), (array([[[12],
[14],
[16],
[18],
[20]],
[[13],
[15],
[17],
[19],
[21]]]), array([[22],
[23]])), (array([[[14],
[16],
[18],
[20],
[22]],
[[15],
[17],
[19],
[21],
[23]]]), array([[24],
[25]])), (array([[[16],
[18],
[20],
[22],
[24]],
[[17],
[19],
[21],
[23],
[25]]]), array([[26],
[27]])), (array([[[18],
[20],
[22],
[24],
[26]],
[[19],
[21],
[23],
[25],
[27]]]), array([[28],
[29]])), (array([[[20],
[22],
[24],
[26],
[28]],
[[21],
[23],
[25],
[27],
[29]]]), array([[30],
[31]])), (array([[[22],
[24],
[26],
[28],
[30]],
[[23],
[25],
[27],
[29],
[31]]]), array([[32],
[33]])), (array([[[24],
[26],
[28],
[30],
[32]],
[[25],
[27],
[29],
[31],
[33]]]), array([[34],
[35]])), (array([[[26],
[28],
[30],
[32],
[34]],
[[27],
[29],
[31],
[33],
[35]]]), array([[36],
[37]])), (array([[[28],
[30],
[32],
[34],
[36]],
[[29],
[31],
[33],
[35],
[37]]]), array([[38],
[39]])), (array([[[30],
[32],
[34],
[36],
[38]],
[[31],
[33],
[35],
[37],
[39]]]), array([[40],
[41]])), (array([[[32],
[34],
[36],
[38],
[40]],
[[33],
[35],
[37],
[39],
[41]]]), array([[42],
[43]])), (array([[[34],
[36],
[38],
[40],
[42]],
[[35],
[37],
[39],
[41],
[43]]]), array([[44],
[45]])), (array([[[36],
[38],
[40],
[42],
[44]],
[[37],
[39],
[41],
[43],
[45]]]), array([[46],
[47]])), (array([[[38],
[40],
[42],
[44],
[46]],
[[39],
[41],
[43],
[45],
[47]]]), array([[48],
[49]]))]
In?[99]:
#图片处理
from tensorflow.keras.preprocessing import image
img = image.load_img("../data/imgs/water_drop.jpeg")
print(type(img))
img_array = image.img_to_array(img)
print(type(img_array), img_array.shape)
small_array = image.random_zoom(img_array,(2, 2), row_axis=0, col_axis=1, channel_axis=2, fill_mode="constant", cval=255.0) #缩小
small_array = image.random_shift(small_array, 0.2, 0.2, row_axis=0, col_axis=1, channel_axis=2, fill_mode="wrap") #平移左上
#small_array = image.random_shear(small_array, 30, row_axis=0, col_axis=1, channel_axis=2, fill_mode="reflect") # 错切30度
small_array = image.random_rotation(small_array, 30, row_axis=0, col_axis=1, channel_axis=2, fill_mode="reflect") # 旋转30度
small_array = image.random_channel_shift(small_array, 100, channel_axis=2) # 通道偏移
small_array = image.random_brightness(small_array, (0.11, 0.25)) # 亮度
small_img = image.array_to_img(small_array)
?
image.save_img("../data/imgs/small_water_drop.jpeg", small_array)
import matplotlib.pyplot as plt
name_list = glob.glob("../data/imgs/*.jpeg")
print(name_list)
fig = plt.figure()
for i in range(len(name_list)):
img = Image.open(name_list[i])
sub_img = fig.add_subplot(331+i)
sub_img.imshow(img)
print("finish")
plt.show()
<class 'PIL.JpegImagePlugin.JpegImageFile'>
<class 'numpy.ndarray'> (314, 230, 3)
['../data/imgs\\small_water_drop.jpeg', '../data/imgs\\water_drop.jpeg']
finish
In?[34]:
%matplotlib inline
import matplotlib.pyplot as plt
import os
from PIL import Image
from tensorflow.keras.preprocessing import image
import glob
?
# 设置生成器参数
datagen = image.ImageDataGenerator(fill_mode='wrap', zoom_range=[2, 2], rotation_range=30)
gen_data = datagen.flow_from_directory("../data/food",
batch_size=1,
shuffle=False,
save_to_dir="../data/imgs/gen",
save_prefix='gen',
target_size=(230, 314))
?
# 生成9张图
for i in range(9):
print(gen_data.next())
?
# 找到本地生成图,把9张图打印到同一张figure上
name_list = glob.glob("../data/imgs/gen/*")
print(name_list)
fig = plt.figure()
for i in range(len(name_list)):
img = Image.open(name_list[i])
sub_img = fig.add_subplot(331+i)
sub_img.imshow(img)
print("finish")
plt.show()
Found 4 images belonging to 2 classes.
(array([[[[197.49608 , 195.59686 , 206.29451 ],
[196.8464 , 195.8464 , 201.78923 ],
[196.11282 , 195.11282 , 200.89769 ],
...,
[167.34569 , 169.34569 , 181.34569 ],
[163.60367 , 165.60367 , 177.60367 ],
[161.84317 , 163.84317 , 175.84317 ]],
[[182.42973 , 183.16086 , 160.98347 ],
[189.86267 , 173.75064 , 156.85756 ],
[192.25763 , 179.13568 , 162.17818 ],
...,
[168.76956 , 171.73764 , 180.83344 ],
[166.10483 , 168.91493 , 178.48462 ],
[166.57103 , 169.22318 , 179.26675 ]],
[[169.27336 , 151.65533 , 108.567055],
[184.31009 , 160.2404 , 122.72813 ],
[184.10081 , 159.87317 , 123.46663 ],
...,
[168.14565 , 171.14565 , 180.14565 ],
[167.16219 , 170.16219 , 179.16219 ],
[172.4397 , 175.4397 , 184.4397 ]],
...,
[[201.3465 , 193.49046 , 203.73596 ],
[200.70587 , 195.65358 , 202.89189 ],
[200.74875 , 198.35962 , 204.13786 ],
...,
[167.24629 , 155.50586 , 107.5135 ],
[176.5436 , 169.63449 , 123.96084 ],
[186.13063 , 172.74063 , 136.74669 ]],
[[202.74513 , 191.74513 , 207.23541 ],
[201.49722 , 193.99446 , 206.24861 ],
[200.48473 , 197.7271 , 204.24237 ],
...,
[160.093 , 152.86102 , 109.23169 ],
[170.15862 , 168.6926 , 130.1766 ],
[182.747 , 176.3869 , 146.12642 ]],
[[199.26651 , 190.27661 , 202.654 ],
[202.61478 , 195.5236 , 205.15993 ],
[201.86298 , 198.05923 , 203.47977 ],
...,
[148.46976 , 143.34447 , 102.82678 ],
[152.41342 , 147.79903 , 113.48543 ],
[162.11528 , 157.34293 , 123.9771 ]]]], dtype=float32), array([[1., 0.]], dtype=float32))
(array([[[[ 14.748968 , 12.748968 , 13.748968 ],
[ 14.316918 , 8.316918 , 12.316918 ],
[ 14.82766 , 8.82766 , 12.82766 ],
...,
[176.32729 , 149.68933 , 111.62909 ],
[177.62643 , 150.16823 , 110.71968 ],
[176.13506 , 146.45345 , 110.2314 ]],
[[ 11.170319 , 9.170319 , 10.170319 ],
[ 14.294234 , 9.397848 , 12.570138 ],
[ 13.199247 , 9.243782 , 11.7103815],
...,
[183.46611 , 160.73991 , 138.85306 ],
[194.49974 , 168.50064 , 145.40466 ],
[199.14297 , 176.14934 , 148.48479 ]],
[[ 13.250704 , 11.250704 , 12.250704 ],
[ 13. , 11. , 12. ],
[ 13. , 11. , 12. ],
...,
[ 23.987291 , 23.167837 , 20.639719 ],
[126.061134 , 112.86194 , 97.769615 ],
[165.69382 , 148.69382 , 120.693825 ]],
...,
[[185.71043 , 163.80698 , 113.51735 ],
[179.3196 , 158.95804 , 109.91341 ],
[174.26529 , 158.34352 , 116.63423 ],
...,
[ 37.927494 , 31.927494 , 31.927494 ],
[ 36.88584 , 30.885841 , 30.885841 ],
[ 37.697884 , 31.697882 , 31.697882 ]],
[[204.1778 , 181.1778 , 137.1778 ],
[204.51524 , 181.75072 , 137.33228 ],
[198.23494 , 175.14499 , 130.30292 ],
...,
[ 38.95383 , 37.95383 , 35.95383 ],
[ 38.7186 , 37.7186 , 35.7186 ],
[ 38.48337 , 37.48337 , 35.48337 ]],
[[186.36334 , 160.73625 , 103.60084 ],
[183.63062 , 157.85246 , 97.63229 ],
[155.32684 , 130.01917 , 65.26384 ],
...,
[ 37.967712 , 36.967712 , 34.967712 ],
[ 37.732483 , 36.732483 , 34.732483 ],
[ 37.497253 , 36.497253 , 34.497253 ]]]], dtype=float32), array([[1., 0.]], dtype=float32))
(array([[[[122.37699 , 80.37699 , 56.37699 ],
[124.36578 , 82.36578 , 58.365784],
[141.03284 , 104.03284 , 78.03284 ],
...,
[146.75232 , 104.49137 , 66.23043 ],
[163.53795 , 148.67024 , 132.13841 ],
[178.41075 , 182.80609 , 185.50914 ]],
[[122.27127 , 80.27127 , 56.27127 ],
[127.430664, 85.430664, 61.430668],
[126.0182 , 84.895454, 60.544556],
...,
[189.62161 , 198.36423 , 203.05276 ],
[189.0411 , 198.0411 , 205.0411 ],
[181.49832 , 190.49832 , 197.49832 ]],
[[119.44023 , 77.44023 , 53.440235],
[ 14. , 10. , 11. ],
[ 14. , 10. , 11. ],
...,
[178.19873 , 187.11513 , 194.61679 ],
[175.77531 , 184.77531 , 191.77531 ],
[175. , 184. , 191. ]],
...,
[[ 69.394684, 42.394684, 31.394686],
[ 67.82814 , 40.828136, 29.828136],
[ 70.10823 , 43.10823 , 32.10823 ],
...,
[ 61.003674, 41.807247, 24.590923],
[ 37.43643 , 23.106794, 18.49962 ],
[ 21.911402, 15.247913, 11.572069]],
[[ 67.24442 , 40.244423, 29.244421],
[ 67.56132 , 40.561317, 29.561317],
[ 71.90522 , 44.905216, 33.905216],
...,
[ 18.42208 , 13.224929, 11.18265 ],
[ 12.687892, 8.687892, 5.687892],
[ 11. , 7. , 4. ]],
[[ 65.9801 , 38.980106, 27.980106],
[ 66.31295 , 39.31295 , 28.31295 ],
[ 70. , 43. , 32. ],
...,
[ 10.616635, 6.616635, 3.616635],
[ 11. , 7. , 4. ],
[ 30. , 49. , 56. ]]]], dtype=float32), array([[0., 1.]], dtype=float32))
(array([[[[158.24402 , 103.24402 , 64.24402 ],
[157.20236 , 102.202354, 63.202354],
[156.78732 , 101.78732 , 62.787323],
...,
[ 96.1901 , 100.9298 , 103.86472 ],
[ 72.48573 , 72.61003 , 71.430855],
[ 49.76083 , 44.09836 , 37.959095]],
[[156.5991 , 102.284744, 62.94193 ],
[156.62766 , 103.13998 , 63.38382 ],
[155.73866 , 102.73867 , 62.738667],
...,
[ 47.624058, 28.814857, 21.598349],
[ 46.108677, 26.108677, 19.108677],
[ 46.281574, 26.281574, 19.281574]],
[[170.92667 , 130.38278 , 100.44178 ],
[181.50974 , 156.53946 , 139.35481 ],
[179.11768 , 163.39145 , 155.44077 ],
...,
[ 46. , 26. , 19. ],
[ 46.261906, 26.261908, 19.261908],
[ 46.675247, 26.675247, 19.675247]],
...,
[[172.52693 , 123.52693 , 82.52693 ],
[163.84302 , 114.84302 , 73.84302 ],
[163.41344 , 114.413445, 73.413445],
...,
[110.12289 , 67.86462 , 7.738824],
[103.23379 , 67.69311 , 17.149872],
[ 86.7062 , 58.312447, 18.57109 ]],
[[164.74854 , 115.748535, 74.748535],
[168.39337 , 119.39337 , 78.39337 ],
[173.11687 , 124.11686 , 83.11686 ],
...,
[212.00558 , 183.92592 , 152.83708 ],
[104.71801 , 70.70083 , 36.05694 ],
[ 75.30618 , 46.514687, 27.713285]],
[[172.68434 , 123.68435 , 82.68435 ],
[175.79506 , 126.79506 , 85.79506 ],
[174.07611 , 125.07611 , 84.07611 ],
...,
[126.90422 , 94.2723 , 52.406868],
[108.18196 , 74.95671 , 25.591282],
[101.82707 , 72.24066 , 15.553958]]]], dtype=float32), array([[0., 1.]], dtype=float32))
(array([[[[162.54607 , 140.43701 , 92.94162 ],
[167.32477 , 144.20888 , 94.26344 ],
[168.5936 , 145.5936 , 95.5936 ],
...,
[214.32645 , 205.83179 , 197.45615 ],
[211.68092 , 202.78543 , 195.36742 ],
[199.0902 , 190.46338 , 181.97066 ]],
[[157.35152 , 136.35152 , 79.351524],
[159.75658 , 138.8573 , 82.26014 ],
[168.00694 , 148.00694 , 95.00695 ],
...,
[203.79298 , 195.52617 , 182.10452 ],
[186.12558 , 179.12558 , 161.12558 ],
[175.73907 , 168.73907 , 150.73907 ]],
[[182.06876 , 172.55077 , 125.960846],
[186.9542 , 177.97356 , 134.0704 ],
[184.57115 , 180.46297 , 147.68985 ],
...,
[206.70607 , 197.00311 , 185.8154 ],
[203.95103 , 194.95103 , 179.95103 ],
[199.43927 , 190.43927 , 175.43927 ]],
...,
[[129.1102 , 136.1102 , 146.1102 ],
[132.69481 , 139.69481 , 149.69481 ],
[138.95865 , 145.95865 , 155.95865 ],
...,
[155.09018 , 124.09018 , 77.09018 ],
[153.06468 , 122.06468 , 75.06468 ],
[154.8387 , 124.683716, 81.501335]],
[[144.06181 , 151.06181 , 161.06181 ],
[151.47647 , 158.47647 , 168.47647 ],
[155.78406 , 162.78406 , 172.78406 ],
...,
[136.03076 , 111.292564, 59.351418],
[153.6451 , 131.89677 , 89.437836],
[159.86247 , 144.66911 , 110.71799 ]],
[[160.48535 , 162.48535 , 174.48535 ],
[161.5776 , 163.5776 , 175.5776 ],
[162.23312 , 164.23312 , 176.23312 ],
...,
[147.33875 , 129.58485 , 99.12993 ],
[153.40198 , 137.28969 , 110.96042 ],
[157.87761 , 150.76941 , 129.21269 ]]]], dtype=float32), array([[1., 0.]], dtype=float32))
(array([[[[ 11. , 13. , 12. ],
[ 14.610134 , 16.125296 , 15.367716 ],
[ 16.778244 , 17.060007 , 16.919125 ],
...,
[ 28.258049 , 24.58065 , 26. ],
[ 27. , 25. , 26. ],
[ 27. , 25. , 26. ]],
[[ 22.191101 , 22.191101 , 22.191101 ],
[ 12.5086355, 12.600882 , 12.139654 ],
[ 15.64824 , 15.64824 , 15.64824 ],
...,
[ 28.712418 , 24.643791 , 26.643791 ],
[ 27. , 25. , 26. ],
[ 27. , 25. , 26. ]],
[[ 13.067023 , 14.067023 , 9.067023 ],
[ 13.546663 , 14.546663 , 9.546663 ],
[ 19.122389 , 19.122389 , 19.122389 ],
...,
[ 26. , 26. , 28. ],
[ 26.438786 , 25.561214 , 27.122429 ],
[ 26.709421 , 24.709421 , 25.709421 ]],
...,
[[ 47. , 46. , 52. ],
[ 47. , 46. , 52. ],
[ 46.26293 , 45.26293 , 51.26293 ],
...,
[216.97125 , 215.97125 , 213.97125 ],
[217.56793 , 213.84259 , 211.16124 ],
[217.42444 , 212.42444 , 209.42444 ]],
[[ 47. , 46. , 52. ],
[ 47. , 46. , 52. ],
[ 44.522297 , 45.522297 , 50.522297 ],
...,
[213.46265 , 212.46265 , 210.06296 ],
[214.69519 , 213.64775 , 210.10837 ],
[209.045 , 208.03078 , 206.07343 ]],
[[ 46.073723 , 45.073723 , 51.073723 ],
[ 45.374783 , 44.374783 , 50.374783 ],
[ 56.226227 , 56.543564 , 61.884895 ],
...,
[220.41754 , 219.41754 , 215.41754 ],
[203.74152 , 202.74152 , 198.74152 ],
[209.21077 , 207.77936 , 207.07361 ]]]], dtype=float32), array([[1., 0.]], dtype=float32))
(array([[[[ 51.126705 , 55.126705 , 58.126705 ],
[ 82.5096 , 86.5096 , 89.5096 ],
[ 70.76067 , 76.06839 , 81.33894 ],
...,
[ 23.268814 , 45.19461 , 47.485203 ],
[ 11.7311535, 16.496706 , 19.589855 ],
[ 10.274679 , 10.363222 , 15.870874 ]],
[[ 27.762114 , 31.762114 , 34.762115 ],
[ 31.214249 , 35.21425 , 38.21425 ],
[ 9.704897 , 13.704897 , 16.704897 ],
...,
[ 16.44812 , 23.779846 , 30.49343 ],
[ 8.839941 , 9.125933 , 17.011536 ],
[ 9.9491415, 7.3734875, 16.161314 ]],
[[ 11.263567 , 15.263567 , 18.263567 ],
[ 16.682335 , 21.097448 , 23.993671 ],
[ 23.691298 , 34.117264 , 34.90428 ],
...,
[ 15.143221 , 22.14322 , 28.14322 ],
[ 6.452234 , 10.597892 , 16.939629 ],
[ 9.385681 , 8.232622 , 15.620258 ]],
...,
[[170.87587 , 152.87587 , 148.87587 ],
[186.88281 , 168.88281 , 164.88281 ],
[193.41031 , 175.41031 , 171.41031 ],
...,
[228.25313 , 224.25313 , 221.25313 ],
[218.60822 , 214.60822 , 211.60822 ],
[232.48206 , 228.48206 , 225.48206 ]],
[[189.77908 , 171.77908 , 167.77908 ],
[182.77571 , 165.80685 , 162.58023 ],
[180.49771 , 166.49771 , 165.49771 ],
...,
[244.67561 , 240.67561 , 237.67561 ],
[242.2991 , 238.2991 , 235.2991 ],
[236.84029 , 232.84029 , 229.84029 ]],
[[194.20255 , 183.02634 , 182.02634 ],
[161.34476 , 147.34476 , 146.34476 ],
[195.95435 , 181.95435 , 180.95435 ],
...,
[230.88043 , 226.88043 , 223.88043 ],
[247.7854 , 243.7854 , 240.7854 ],
[238.17511 , 234.17511 , 231.17511 ]]]], dtype=float32), array([[0., 1.]], dtype=float32))
(array([[[[194.00693 , 182.00693 , 182.00693 ],
[212.79828 , 199.05524 , 200.3755 ],
[177.41058 , 165.09329 , 170.0126 ],
...,
[ 93.524704, 95.524704, 110.524704],
[107.2284 , 109.2284 , 124.2284 ],
[131.8256 , 133.8256 , 148.8256 ]],
[[189.6426 , 177.6426 , 179.6426 ],
[182.4 , 168.45258 , 169.9861 ],
[170.82819 , 151.82819 , 153.82819 ],
...,
[109.36671 , 111.36671 , 123.36671 ],
[135.67038 , 137.67038 , 149.67038 ],
[137.7637 , 139.7637 , 153.8362 ]],
[[187.00688 , 175.00688 , 175.00688 ],
[189.58304 , 177.58304 , 178.73537 ],
[184.88995 , 172.88995 , 173.8003 ],
...,
[176.4813 , 142.23364 , 120.541695],
[152.61957 , 139.08484 , 144.49713 ],
[131.39795 , 131.14864 , 142.54976 ]],
...,
[[ 45.894497, 27.793894, 13.827429],
[ 60.301247, 38.4896 , 25.760149],
[ 58.20142 , 37.745205, 24.327692],
...,
[101.89489 , 99.89489 , 102.150406],
[ 69.85508 , 67.85508 , 68.87358 ],
[111.00058 , 109.00058 , 112.00058 ]],
[[ 54.5624 , 35.5624 , 21.5624 ],
[ 56.425148, 37.425148, 23.425148],
[ 52.71005 , 32.71005 , 21.710049],
...,
[119.30326 , 117.30326 , 120.30326 ],
[120.017395, 118.017395, 121.017395],
[121.94499 , 119.94499 , 122.94499 ]],
[[ 50.638546, 31.638546, 17.638546],
[ 52.355766, 33.355766, 19.355766],
[ 49.520306, 30.070442, 17.420027],
...,
[ 98.01438 , 96.87774 , 99.44606 ],
[110.88403 , 108.88403 , 111.88403 ],
[100.52511 , 98.52511 , 101.52511 ]]]], dtype=float32), array([[0., 1.]], dtype=float32))
(array([[[[ 22.033401, 27.033401, 46.0334 ],
[ 31.00981 , 34.273544, 50.958523],
[ 99. , 102. , 109. ],
...,
[150. , 148. , 149. ],
[151.4593 , 149.4593 , 150.4593 ],
[153. , 151. , 152. ]],
[[ 96. , 103. , 109. ],
[ 95.60615 , 102.60615 , 109.39385 ],
[ 94.72869 , 101.72869 , 109.72869 ],
...,
[153.15485 , 151.15485 , 152.15485 ],
[153. , 151.56734 , 151.71632 ],
[153.16113 , 153.32227 , 150.35548 ]],
[[ 95. , 102. , 110. ],
[ 94.61782 , 101.61782 , 109.61782 ],
[ 91.75785 , 98.75785 , 106.75785 ],
...,
[156.79655 , 155.20345 , 155.9655 ],
[154.16182 , 154.75728 , 146.67636 ],
[155.91673 , 152.1249 , 143.16652 ]],
...,
[[159.49153 , 119.85117 , 67.33835 ],
[157.37437 , 119.959984, 64.21596 ],
[154.2703 , 118.296234, 58.72054 ],
...,
[ 84.627884, 87.627884, 94.02584 ],
[ 86. , 89. , 96. ],
[ 85.70813 , 88.70813 , 95.70813 ]],
[[180.93237 , 168.99658 , 143.43422 ],
[184.91132 , 169.67854 , 133.67024 ],
[182.96992 , 167.5503 , 139.83311 ],
...,
[ 84.75859 , 87.75859 , 93.51717 ],
[ 86. , 89. , 96. ],
[ 86.40263 , 89.40263 , 96.40263 ]],
[[172.39845 , 166.34996 , 166.0485 ],
[173. , 168. , 165. ],
[172.91673 , 167.8751 , 165.08327 ],
...,
[ 85.961945, 88.961945, 95.961945],
[ 88.21736 , 91.21736 , 98.21736 ],
[ 89.93145 , 92.93145 , 99.93145 ]]]], dtype=float32), array([[1., 0.]], dtype=float32))
['../data/imgs/gen\\gen_0_3369535.png', '../data/imgs/gen\\gen_0_3836511.png', '../data/imgs/gen\\gen_0_4140914.png', '../data/imgs/gen\\gen_0_4638047.png', '../data/imgs/gen\\gen_1_2563035.png', '../data/imgs/gen\\gen_1_3028108.png', '../data/imgs/gen\\gen_2_1012726.png', '../data/imgs/gen\\gen_2_6892319.png', '../data/imgs/gen\\gen_3_3940752.png', '../data/imgs/gen\\gen_3_4620824.png']
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-34-a7d7c4173d9f> in <module>
25 for i in range(len(name_list)):
26 img = Image.open(name_list[i])
---> 27 sub_img = fig.add_subplot(331+i)
28 sub_img.imshow(img)
29 print("finish")
C:\ProgramData\Anaconda3\envs\tf2\lib\site-packages\matplotlib\figure.py in add_subplot(self, *args, **kwargs)
1400 # more similar to add_axes.
1401 self._axstack.remove(ax)
-> 1402 ax = subplot_class_factory(projection_class)(self, *args, **kwargs)
1403
1404 return self._add_axes_internal(key, ax)
C:\ProgramData\Anaconda3\envs\tf2\lib\site-packages\matplotlib\axes\_subplots.py in __init__(self, fig, *args, **kwargs)
37
38 self.figure = fig
---> 39 self._subplotspec = SubplotSpec._from_subplot_args(fig, args)
40 self.update_params()
41 # _axes_class is set in the subplot_class_factory
C:\ProgramData\Anaconda3\envs\tf2\lib\site-packages\matplotlib\gridspec.py in _from_subplot_args(figure, args)
688 if num < 1 or num > rows*cols:
689 raise ValueError(
--> 690 f"num must be 1 <= num <= {rows*cols}, not {num}")
691 return gs[num - 1] # -1 due to MATLAB indexing.
692 else:
ValueError: num must be 1 <= num <= 12, not 0
In?[101]:
#tf.keras.utils
#下载文件
from tensorflow.keras import utils
print(dir(utils))
data_path = utils.get_file("tensorflow", "https://codeload.github.com/tensorflow/tensorflow/zip/refs/heads/master", cache_dir="source_code")
print(data_path)
['CustomObjectScope', 'GeneratorEnqueuer', 'OrderedEnqueuer', 'Progbar', 'Sequence', 'SequenceEnqueuer', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '_sys', 'custom_object_scope', 'deserialize_keras_object', 'get_custom_objects', 'get_file', 'get_registered_name', 'get_registered_object', 'get_source_inputs', 'model_to_dot', 'normalize', 'pack_x_y_sample_weight', 'plot_model', 'register_keras_serializable', 'serialize_keras_object', 'to_categorical', 'unpack_x_y_sample_weight']
Downloading data from https://codeload.github.com/tensorflow/tensorflow/zip/refs/heads/master
71098368/Unknown - 166s 2us/step/tmp\.keras\datasets\tensorflow
In?[103]:
import tensorflow as tf
input = tf.keras.Input((216,16))
print(input)
KerasTensor(type_spec=TensorSpec(shape=(None, 216, 16), dtype=tf.float32, name='input_2'), name='input_2', description="created by layer 'input_2'")
In?[107]:
import tensorflow.keras.initializers as init
#初始化值的保存与加载
cfg = init.Constant(11).get_config()
print(cfg)
c = init.Constant(11).from_config(cfg)
print(c)
values = c(shape=(2, 2))
print(values)
{'value': 11}
<tensorflow.python.keras.initializers.initializers_v2.Constant object at 0x000002B7DCCA3BC8>
tf.Tensor(
[[11. 11.]
[11. 11.]], shape=(2, 2), dtype=float32)
?In?[225]:
from tensorflow.data import Dataset
import tensorflow as tf
def gen():
for i in range(10):
yield i
?
ds = Dataset.from_tensor_slices(
{"a": tf.ones([4]),"b": tf.zeros([4, 100], dtype=tf.int32)})
for d in ds.batch(3):
print(type(d), d)
filename = '../data/tfrecords/test.tfrecord'
ds = Dataset.from_tensor_slices([1, 2])
ds = ds.map(tf.io.serialize_tensor) #元素必须是 tf.String 才能写入文件,TFRecord: <TFRecordDatasetV2 shapes: (), types: tf.string>
print("before write:", ds)
writer = tf.data.experimental.TFRecordWriter(filename)
writer.write(ds)
ds = tf.data.TFRecordDataset(filename)
print("read back TFRecord:", ds)
ds = ds.map(lambda x : tf.io.parse_tensor(x, tf.int32)) #反序列化回来
for x in ds:
print(x)
<class 'dict'> {'a': <tf.Tensor: shape=(3,), dtype=float32, numpy=array([1., 1., 1.], dtype=float32)>, 'b': <tf.Tensor: shape=(3, 100), dtype=int32, numpy=
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])>}
<class 'dict'> {'a': <tf.Tensor: shape=(1,), dtype=float32, numpy=array([1.], dtype=float32)>, 'b': <tf.Tensor: shape=(1, 100), dtype=int32, numpy=
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])>}
before write: <MapDataset shapes: (), types: tf.string>
read back TFRecord: <TFRecordDatasetV2 shapes: (), types: tf.string>
tf.Tensor(1, shape=(), dtype=int32)
tf.Tensor(2, shape=(), dtype=int32)
In?[224]:
import tensorflow as tf
import tensorflow.io as tio
import tensorflow.io.gfile as gf
print("====================文件读写与操作=====================")
#读取文件成为tensor shape=() dtype=string, tensorflow的string可以保存任意二进制数据
samples = tio.read_file("../data/txt/ender_games.txt")
#把tensor shape=() dtype=string写入到文件
tio.write_file("../data/txt/ender_games_copy.txt", samples)
tio.write_file(tf.cast("../data/txt/ender_games_coopy.txt", tf.string), samples)
tio.write_file("../data/txt/ender_games_coopy.bytes", b'bytes is me')
#文件存在
assert gf.exists("../data/txt/ender_games_coopy.txt")
#直接copy文件
gf.copy("../data/txt/ender_games.txt", "../data/txt/ender_games_copy.txt", overwrite=True)
#删除文件
gf.remove("../data/txt/ender_games_coopy.txt")
assert not gf.exists("../data/txt/ender_games_coopy.txt")
#列出文件名
print(gf.glob("../data/**/*.txt"))
#创建目录和子目录
gf.makedirs("../data/path/to/all/children")
#遍历目录
for x in gf.walk("../data"):
if gf.isdir(x[0]):
print("directory:", x[0], "children:", x[1])
else:
print("file:", x[0])
print("====================tensor 序列化 & 反序列化=====================")
#序列化一个tensor
vec_ex1 = tf.constant([[1,2,4], [4,5,6]])
print("vec_ex1", vec_ex1)
vec_ex_binary_string = tio.serialize_tensor(vec_ex)
#反序列化回来
vec_tensor = tio.parse_tensor(vec_ex_binary_string, out_type=tf.int32)
print("back tensor:", vec_tensor)
#支持sparse序列化
vec_sparse = tf.sparse.from_dense(vec_ex1)
vec_sparse_seri = tio.serialize_sparse(vec_sparse)
print("vec_sparse", vec_sparse, vec_sparse_seri)
?
print("====================tf.train.Feature的序列化与反序列化=====================")
byte_feature = tf.train.Feature(bytes_list=tf.train.BytesList(value=[b"abcdefg", b"12312312"]))
float_feature = tf.train.Feature(float_list=tf.train.FloatList(value=[1.1, 2.2, 3.4]))
int_feature = tf.train.Feature(int64_list=tf.train.Int64List(value=[11,22,33,44]))
print("BytesList2Feature", type(byte_feature), byte_feature)
print("BytesList2Feature", type(float_feature), float_feature)
print("BytesList2Feature", type(int_feature), int_feature)
print(byte_feature.SerializeToString(), float_feature.SerializePartialToString(), int_feature.SerializePartialToString())
print("====================tf.train.Example的序列化与反序列化=====================")
# The following functions can be used to convert a value to a type compatible
# with tf.train.Example.
#帮助函数,把python中的类型转成三种List类型
def _bytes_feature(value):
"""Returns a bytes_list from a string / byte."""
if isinstance(value, type(tf.constant(0))):
value = value.numpy() # BytesList won't unpack a string from an EagerTensor.
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
?
def _float_feature(value):
"""Returns a float_list from a float / double."""
return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))
?
def _int64_feature(value):
"""Returns an int64_list from a bool / enum / int / uint."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
?
#
# The number of observations in the dataset.
n_observations = int(1e4)
?
# Boolean feature, encoded as False or True.
feature0 = np.random.choice([False, True], n_observations)
?
# Integer feature, random from 0 to 4.
feature1 = np.random.randint(0, 5, n_observations)
?
# String feature.
strings = np.array([b'cat', b'dog', b'chicken', b'horse', b'goat'])
feature2 = strings[feature1]
?
# Float feature, from a standard normal distribution.
feature3 = np.random.randn(n_observations)
?
#字典映射三种list
def serialize_example(feature0, feature1, feature2, feature3):
"""
Creates a tf.train.Example message ready to be written to a file.
"""
# Create a dictionary mapping the feature name to the tf.train.Example-compatible
# data type.
feature = {
'feature0': _int64_feature(feature0),
'feature1': _int64_feature(feature1),
'feature2': _bytes_feature(feature2),
'feature3': _float_feature(feature3),
}
?
# Create a Features message using tf.train.Example.
#创建Feature和Example并序列化
fea = tf.train.Features(feature=feature)
example_proto = tf.train.Example(features=fea)
print("tf.Example", type(example_proto), "tf.Feature:", type(fea))
return example_proto.SerializeToString()
?
#序列化
serialized_example = serialize_example(False, 4, b'goat', 0.9876)
print("serizlized_example:", serialized_example)
#反序列化
example_proto = tf.train.Example.FromString(serialized_example)
print("example_proto:", example_proto)
?
?
?
#TFRecord的读写
# Write the records to a file.
import numpy as np
example_path = "../data/tfrecords/example.txt"
with tf.io.TFRecordWriter(example_path) as file_writer:
file_writer.write("abcdefg")
?
example_path = "../data/tfrecords/example.dat"
with tf.io.TFRecordWriter(example_path) as file_writer:
for _ in range(4):
x, y = np.random.random(), np.random.random()
?
record_bytes = tf.train.Example(features=tf.train.Features(feature={
"x": tf.train.Feature(float_list=tf.train.FloatList(value=[x])),
"y": tf.train.Feature(float_list=tf.train.FloatList(value=[y])),
})).SerializeToString()
#print("record_bytes", type(record_bytes)) #python bytes
file_writer.write(record_bytes)
# Read the data back out.
def decode_fn(record_bytes):
return tf.io.parse_single_example(
# Data
record_bytes,
?
# Schema
{"x": tf.io.FixedLenFeature([], dtype=tf.float32),
"y": tf.io.FixedLenFeature([], dtype=tf.float32)}
)
for batch in tf.data.TFRecordDataset([example_path]).map(decode_fn):
print("x = {x:.4f}, y = {y:.4f}".format(**batch))
?
?
?
?
print(type(samples), samples.shape, samples.dtype, len(str_samples), str_samples[0:1024])
print(dir(tio))
print(dir(tf))
====================文件读写与操作=====================
['..\\data\\tfrecords\\example.txt', '..\\data\\txt\\ender_games.txt', '..\\data\\txt\\ender_games_copy.txt']
directory: ../data children: ['food', 'imgs', 'path', 'sparrow', 'tfrecords', 'txt']
directory: ../data\food children: ['class_a', 'class_b']
directory: ../data\food\class_a children: []
directory: ../data\food\class_b children: []
directory: ../data\imgs children: ['gen']
directory: ../data\imgs\gen children: []
directory: ../data\path children: ['to']
directory: ../data\path\to children: ['all']
directory: ../data\path\to\all children: ['children']
directory: ../data\path\to\all\children children: []
directory: ../data\sparrow children: []
directory: ../data\tfrecords children: []
directory: ../data\txt children: []
====================tensor 序列化 & 反序列化=====================
vec_ex1 tf.Tensor(
[[1 2 4]
[4 5 6]], shape=(2, 3), dtype=int32)
back tensor: tf.Tensor(
[[1 2 4]
[4 5 6]], shape=(2, 3), dtype=int32)
vec_sparse SparseTensor(indices=tf.Tensor(
[[0 0]
[0 1]
[0 2]
[1 0]
[1 1]
[1 2]], shape=(6, 2), dtype=int64), values=tf.Tensor([1 2 4 4 5 6], shape=(6,), dtype=int32), dense_shape=tf.Tensor([2 3], shape=(2,), dtype=int64)) tf.Tensor(
[b'\x08\t\x12\x08\x12\x02\x08\x06\x12\x02\x08\x02"`\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x00'
b'\x08\x03\x12\x04\x12\x02\x08\x06"\x18\x01\x00\x00\x00\x02\x00\x00\x00\x04\x00\x00\x00\x04\x00\x00\x00\x05\x00\x00\x00\x06\x00\x00\x00'
b'\x08\t\x12\x04\x12\x02\x08\x02"\x10\x02\x00\x00\x00\x00\x00\x00\x00\x03\x00\x00\x00\x00\x00\x00\x00'], shape=(3,), dtype=string)
====================tf.train.Feature的序列化与反序列化=====================
BytesList2Feature <class 'tensorflow.core.example.feature_pb2.Feature'> bytes_list {
value: "abcdefg"
value: "12312312"
}
BytesList2Feature <class 'tensorflow.core.example.feature_pb2.Feature'> float_list {
value: 1.100000023841858
value: 2.200000047683716
value: 3.4000000953674316
}
BytesList2Feature <class 'tensorflow.core.example.feature_pb2.Feature'> int64_list {
value: 11
value: 22
value: 33
value: 44
}
b'\n\x13\n\x07abcdefg\n\x0812312312' b'\x12\x0e\n\x0c\xcd\xcc\x8c?\xcd\xcc\x0c@\x9a\x99Y@' b'\x1a\x06\n\x04\x0b\x16!,'
====================tf.train.Example的序列化与反序列化=====================
tf.Example <class 'tensorflow.core.example.example_pb2.Example'> tf.Feature: <class 'tensorflow.core.example.feature_pb2.Features'>
serizlized_example: b'\nR\n\x14\n\x08feature2\x12\x08\n\x06\n\x04goat\n\x11\n\x08feature1\x12\x05\x1a\x03\n\x01\x04\n\x11\n\x08feature0\x12\x05\x1a\x03\n\x01\x00\n\x14\n\x08feature3\x12\x08\x12\x06\n\x04[\xd3|?'
example_proto: features {
feature {
key: "feature0"
value {
int64_list {
value: 0
}
}
}
feature {
key: "feature1"
value {
int64_list {
value: 4
}
}
}
feature {
key: "feature2"
value {
bytes_list {
value: "goat"
}
}
}
feature {
key: "feature3"
value {
float_list {
value: 0.9876000285148621
}
}
}
}
x = 0.3993, y = 0.2057
x = 0.0059, y = 0.2728
x = 0.9259, y = 0.5181
x = 0.8927, y = 0.0866
<class 'tensorflow.python.framework.ops.EagerTensor'> () <dtype: 'string'> 580818 tf.Tensor(b' ENDER\'S GAME\n by Orson Scott Card\n \n \n Chapter 1 -- Third\n \n "I\'ve watched through his eyes, I\'ve listened through his ears, and tell you he\'s the one. Or at least as close as we\'re going to get."\n \n "That\'s what you said about the brother."\n \n "The brother tested out impossible. For other reasons. Nothing to do with his ability."\n \n "Same with the sister. And there are doubts about him. He\'s too malleable. Too willing to submerge himself in someone else\'s will."\n \n "Not if the other person is his enemy."\n \n "So what do we do? Surround him with enemies all the time?"\n \n "If we have to."\n \n "I thought you said you liked this kid."\n \n "If the buggers get him, they\'ll make me look like his favorite uncle."\n \n "All right. We\'re saving the world, after all. Take him."\n \n ***\n \n The monitor lady smiled very nicely and tousled his hair and said, "Andrew, I suppose by now you\'re just absolutely sick of having that horrid monitor. Well, I
['FixedLenFeature', 'FixedLenSequenceFeature', 'RaggedFeature', 'SparseFeature', 'TFRecordOptions', 'TFRecordWriter', 'VarLenFeature', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '_sys', 'decode_and_crop_jpeg', 'decode_base64', 'decode_bmp', 'decode_compressed', 'decode_csv', 'decode_gif', 'decode_image', 'decode_jpeg', 'decode_json_example', 'decode_png', 'decode_proto', 'decode_raw', 'deserialize_many_sparse', 'encode_base64', 'encode_jpeg', 'encode_png', 'encode_proto', 'extract_jpeg_shape', 'gfile', 'is_jpeg', 'match_filenames_once', 'matching_files', 'parse_example', 'parse_sequence_example', 'parse_single_example', 'parse_single_sequence_example', 'parse_tensor', 'read_file', 'serialize_many_sparse', 'serialize_sparse', 'serialize_tensor', 'write_file', 'write_graph']
['AggregationMethod', 'Assert', 'CriticalSection', 'DType', 'DeviceSpec', 'GradientTape', 'Graph', 'IndexedSlices', 'IndexedSlicesSpec', 'Module', 'Operation', 'OptionalSpec', 'RaggedTensor', 'RaggedTensorSpec', 'RegisterGradient', 'SparseTensor', 'SparseTensorSpec', 'Tensor', 'TensorArray', 'TensorArraySpec', 'TensorShape', 'TensorSpec', 'TypeSpec', 'UnconnectedGradients', 'Variable', 'VariableAggregation', 'VariableSynchronization', '_API_MODULE', '_LazyLoader', '__all__', '__builtins__', '__cached__', '__compiler_version__', '__cxx11_abi_flag__', '__doc__', '__file__', '__git_version__', '__internal__', '__loader__', '__monolithic_build__', '__name__', '__operators__', '__package__', '__path__', '__spec__', '__version__', '_absolute_import', '_api', '_compat', '_current_file_location', '_current_module', '_distutils', '_division', '_estimator_module', '_fi', '_inspect', '_ll', '_logging', '_main_dir', '_major_api_version', '_module_dir', '_module_util', '_names_with_underscore', '_os', '_plugin_dir', '_print_function', '_running_from_pip_package', '_s', '_site', '_site_packages_dirs', '_six', '_sys', '_tf2', '_tf_api_dir', '_typing', 'abs', 'acos', 'acosh', 'add', 'add_n', 'argmax', 'argmin', 'argsort', 'as_dtype', 'as_string', 'asin', 'asinh', 'assert_equal', 'assert_greater', 'assert_less', 'assert_rank', 'atan', 'atan2', 'atanh', 'audio', 'autodiff', 'autograph', 'batch_to_space', 'bfloat16', 'bitcast', 'bitwise', 'bool', 'boolean_mask', 'broadcast_dynamic_shape', 'broadcast_static_shape', 'broadcast_to', 'case', 'cast', 'clip_by_global_norm', 'clip_by_norm', 'clip_by_value', 'compat', 'complex', 'complex128', 'complex64', 'concat', 'cond', 'config', 'constant', 'constant_initializer', 'control_dependencies', 'convert_to_tensor', 'cos', 'cosh', 'cumsum', 'custom_gradient', 'data', 'debugging', 'device', 'distribute', 'divide', 'double', 'dtypes', 'dynamic_partition', 'dynamic_stitch', 'edit_distance', 'eig', 'eigvals', 'einsum', 'ensure_shape', 'equal', 'errors', 'estimator', 'executing_eagerly', 'exp', 'expand_dims', 'experimental', 'extract_volume_patches', 'eye', 'feature_column', 'fill', 'fingerprint', 'float16', 'float32', 'float64', 'floor', 'foldl', 'foldr', 'function', 'gather', 'gather_nd', 'get_logger', 'get_static_value', 'grad_pass_through', 'gradients', 'graph_util', 'greater', 'greater_equal', 'group', 'guarantee_const', 'half', 'hessians', 'histogram_fixed_width', 'histogram_fixed_width_bins', 'identity', 'identity_n', 'image', 'import_graph_def', 'init_scope', 'initializers', 'inside_function', 'int16', 'int32', 'int64', 'int8', 'io', 'is_tensor', 'keras', 'less', 'less_equal', 'linalg', 'linspace', 'lite', 'load_library', 'load_op_library', 'logical_and', 'logical_not', 'logical_or', 'lookup', 'losses', 'make_ndarray', 'make_tensor_proto', 'map_fn', 'math', 'matmul', 'matrix_square_root', 'maximum', 'meshgrid', 'metrics', 'minimum', 'mixed_precision', 'mlir', 'multiply', 'name_scope', 'negative', 'nest', 'newaxis', 'nn', 'no_gradient', 'no_op', 'nondifferentiable_batch_function', 'norm', 'not_equal', 'numpy_function', 'one_hot', 'ones', 'ones_initializer', 'ones_like', 'optimizers', 'pad', 'parallel_stack', 'pow', 'print', 'profiler', 'py_function', 'qint16', 'qint32', 'qint8', 'quantization', 'quantize_and_dequantize_v4', 'queue', 'quint16', 'quint8', 'ragged', 'random', 'random_normal_initializer', 'random_uniform_initializer', 'range', 'rank', 'raw_ops', 'realdiv', 'recompute_grad', 'reduce_all', 'reduce_any', 'reduce_logsumexp', 'reduce_max', 'reduce_mean', 'reduce_min', 'reduce_prod', 'reduce_sum', 'register_tensor_conversion_function', 'repeat', 'required_space_to_batch_paddings', 'reshape', 'resource', 'reverse', 'reverse_sequence', 'roll', 'round', 'saturate_cast', 'saved_model', 'scalar_mul', 'scan', 'scatter_nd', 'searchsorted', 'sequence_mask', 'sets', 'shape', 'shape_n', 'sigmoid', 'sign', 'signal', 'sin', 'sinh', 'size', 'slice', 'sort', 'space_to_batch', 'space_to_batch_nd', 'sparse', 'split', 'sqrt', 'square', 'squeeze', 'stack', 'stop_gradient', 'strided_slice', 'string', 'strings', 'subtract', 'summary', 'switch_case', 'sysconfig', 'tan', 'tanh', 'tensor_scatter_nd_add', 'tensor_scatter_nd_max', 'tensor_scatter_nd_min', 'tensor_scatter_nd_sub', 'tensor_scatter_nd_update', 'tensordot', 'test', 'tile', 'timestamp', 'tools', 'tpu', 'train', 'transpose', 'truediv', 'truncatediv', 'truncatemod', 'tuple', 'type_spec_from_value', 'types', 'uint16', 'uint32', 'uint64', 'uint8', 'unique', 'unique_with_counts', 'unravel_index', 'unstack', 'variable_creator_scope', 'variant', 'vectorized_map', 'version', 'where', 'while_loop', 'xla', 'zeros', 'zeros_initializer', 'zeros_like']