Ŀ¼
ǰ��

һ��ͶƱ��
1.ͶƱ����˼·
ͶƱ���Ǽ���ѧϰ�г��õļ���,�������������ģ�͵ķ�������,����ģ�͵Ĵ����ʡ�һ�������,�������Ƿ����ھֲ�,����ں϶�������ǽ�������һ���÷���,�����ͶƱ���Ļ���˼·��
���ڻع�ģ����˵,ͶƱ�����յ�Ԥ�����Ƕ�������ع�ģ��Ԥ������ƽ��ֵ��
���ڷ���ģ��,ӲͶƱ����Ԥ�����Ƕ��ģ��Ԥ�����г��ִ����������,��ͶƱ�Ը���Ԥ�����ĸ��ʽ������,����ѡȡ����֮���������ǩ��
2.ͶƱ����ԭ��
ͶƱ����һ����ѭ�������Ӷ����ļ���ѧϰ,ͨ�����ģ�͵ļ��ɽ��ͷ���,�Ӷ����ģ�͵�³���ԡ������������,ͶƱ����Ԥ��Ч��Ӧ�������κ�һ����ģ�͵�Ԥ��Ч����
ͶƱ���ڻع�ģ�������ģ���Ͼ���ʹ��:
- �ع�ͶƱ��:Ԥ����������ģ��Ԥ������ƽ��ֵ��
- ����ͶƱ��:Ԥ����������ģ���ֳ�������Ԥ����
����ͶƱ���ֿ��Ա�����ΪӲͶƱ����ͶƱ:
- ӲͶƱ:Ԥ����������ͶƱ��������ֵ��ࡣ
- ��ͶƱ:Ԥ����������ͶƱ����и��ʼӺ������ࡣ
���Dz�ͬ�Ļ�ģ�Ϳ��ܲ�����Ӱ��,������,��ģ�Ϳ������κ��ѱ�ѵ���õ�ģ�͡�����ʵ��Ӧ����,��ҪͶƱ�������ϺõĽ��,��Ҫ������������:
- ��ģ��֮���Ч�����ܲ�����ij����ģ�������������ģ��Ч������ʱ,��ģ�ͺܿ��ܳ�Ϊ������
- ��ģ��֮��Ӧ���н�С��ͬ���ԡ������ڻ�ģ��Ԥ��Ч�����Ƶ������,������ģ��������ģ�͵�ͶƱ,��������������ģ�ͻ���������ģ�͡�?
��ͶƱ�ϼ���ʹ�õ�ģ����Ԥ�������������ǩʱ,�ʺ�ʹ��ӲͶƱ����ͶƱ������ʹ�õ�ģ����Ԥ�����ĸ���ʱ,�ʺ�ʹ����ͶƱ��
��ͶƱͬ������������Щ��������Ԥ�����Ա���ʵ�ģ��,ֻҪ���ǿ�����������ڸ��ʵ�Ԥ�����ֵ(����֧����������k-����ں;�����)��
������:��������ģ�͵Ĵ�����һ����,����ζ������ģ�Ͷ�Ԥ��Ĺ�����һ���ġ����һЩģ����ijЩ����ºܺ�,������������ºܲ�,����ʹ��ͶƱ��ʱ��Ҫ���ǵ���һ�����⡣
3.ͶƱ���İ�������(����sklearn,����pipe�ܵ���ʹ���Լ�voting��ʹ��)
Sklearn���ṩ�� VotingRegressor �� VotingClassifier ����ͶƱ������ ?������ģ�͵IJ�����ʽ��ͬ,��������ͬ�IJ�����ʹ��ģ����Ҫ�ṩһ��ģ���б�,�б���ÿ��ģ�Ͳ���Tuple�Ľṹ��ʾ,��һ��Ԫ�ش�������,�ڶ���Ԫ�ش���ģ��,��Ҫ��֤ÿ��ģ�ͱ���ӵ��Ψһ�����ơ�
����ģ��:
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models)
Ԥ����:
models = [('lr',LogisticRegression()),('svm',make_pipeline(StandardScaler(),SVC()))]
ensemble = VotingClassifier(estimators=models)
ģ�ͻ��ṩ��voting����������ѡ����ͶƱ����ӲͶƱ:
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models, voting='soft')
����:
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2)
# summarize the dataset
return X,y
# get a voting ensemble of models
def get_voting():
# define the base models
models = list()
models.append(('knn1', KNeighborsClassifier(n_neighbors=1)))
models.append(('knn3', KNeighborsClassifier(n_neighbors=3)))
models.append(('knn5', KNeighborsClassifier(n_neighbors=5)))
models.append(('knn7', KNeighborsClassifier(n_neighbors=7)))
models.append(('knn9', KNeighborsClassifier(n_neighbors=9)))
# define the voting ensemble
ensemble = VotingClassifier(estimators=models, voting='hard')
return ensemble
# get a list of models to evaluate
def get_models():
models = dict()
models['knn1'] = KNeighborsClassifier(n_neighbors=1)
models['knn3'] = KNeighborsClassifier(n_neighbors=3)
models['knn5'] = KNeighborsClassifier(n_neighbors=5)
models['knn7'] = KNeighborsClassifier(n_neighbors=7)
models['knn9'] = KNeighborsClassifier(n_neighbors=9)
models['hard_voting'] = get_voting()
return models
#�����evaluate_model()��������һ��ģ��ʵ��,���Էֲ�10��������֤�����ظ��ķ����б�����ʽ���ء�
# evaluate a give model using cross-validation
from sklearn.model_selection import cross_val_score #Added by ljq
def evaluate_model(model, X, y):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores
from sklearn.neighbors import KNeighborsClassifier
from matplotlib import pyplot
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model, X, y)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
���ǵõ��Ľ������:
knn1 0.873 (0.030)
knn3 0.889 (0.038)
knn5 0.895 (0.031)
knn7 0.899 (0.035)
knn9 0.900 (0.033)
hard_voting 0.902 (0.034)
��ȻͶƱ��Ч���Դ����κ�һ����ģ�͡�
����bagging
1. bagging��˼·
��ͶƱ����ͬ����,Bagging����������ģ������Ԥ����,ͬʱ����һ��������Ӱ���ģ��ѵ��,��֤��ģ�Ϳ��Է���һ���ļ��衣����һ���������ᵽ,ϣ������ģ��֮����нϴ�IJ�����,����ʵ�ʲ����е�ģ��ȴ������ͬ�ʵ�,���һ����˼·��ͨ����ͬ�IJ�������ģ�͵IJ����ԡ�
ʲô��Baggings?
ʲô����������(bootstrap)?
bootstrap��bagging�Ĺ�ϵ
2.bagging��ԭ������
��������(bootstrap),���зŻصĴ����ݼ��н��в���,Ҳ����˵,ͬ����һ���������ܱ���ν��в�����
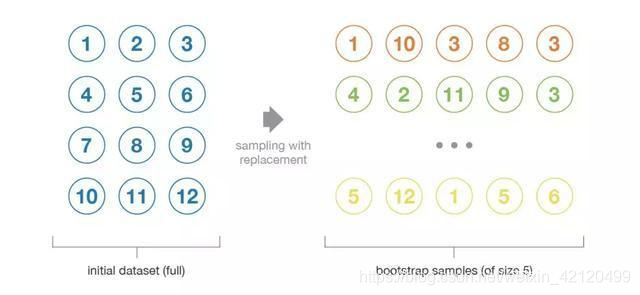
�����������ȡ��һ�������������������,�ٰ���������Żس�ʼ���ݼ�,�ظ�K�β���,�������ǿ��Ի��һ����СΪK���������ϡ�ͬ���ķ���, ���ǿ��Բ�����T����K�������IJ�������,Ȼ�����ÿ����������ѵ����һ����ѧϰ��,�ٽ���Щ��ѧϰ�����н��,�����Bagging�Ļ������̡�
??�ع�����:ͨ��Ԥ��ȡƽ��ֵ�����еġ�
??��������:ͨ����Ԥ��ȡ����ƱԤ�������еġ�
??Bagging����֮������Ч,����Ϊÿ��ģ�Ͷ���������ͬ��ѵ�����ݼ��������ɵ�,����ʹ��ÿ����ģ��֮��������IJ���,ʹÿ����ģ��ӵ������ͬ��ѵ��������
??Baggingͬ����һ�����ͷ����ļ���,������ڲ���֦������������������������Ŷ���ѧϰ����Ч���������ԡ���ʵ�ʵ�ʹ����,�����в�����Bagging�����Ը�άС���������������Ч�����C>������biasΪ���۽��ͷ���
3. bagging�İ�������(����sklearn,�������ɭ�ֵ���������Լ�ʵ��)
SklearnΪ�����ṩ�� BaggingRegressor �� BaggingClassifier ����Bagging������API��
���ھ�����������bagging����,�ԱȻع�ģ�͡�
Bagging��һ������Ӧ�������ɭ�֡�����˼��,��ɭ�֡��������ࡰ����bagging��ɵġ��ھ���ʵ����,����ÿ��������ѵ����������������������������ͨ����������õ���,���ɭ�ֵ�Ԥ�����Ƕ����������������(ͶƱ)��