参考链接:https://datawhalechina.github.io/leeml-notes/#/chapter21/chapter21
文章目录
一、为什么要使用卷积神经网络(CNN)

CNN常常被用在影像处理上,比如说你想要做影像的分类,就是training一个neural network,input一张图片,然后把这张图片表示成里面的像素(pixel),也就是很长很长的矢量(vector)。output就是(假如你有1000个类别,output就是1000个dimension)dimension。
通常会遇到一些问题:
-
1.在training neural network时,我们希望在network的structure里面,每一个neural就是代表了一个最基本的classifier,事实是在文件上根据训练的结果,你有可能会得到很多这样的结论。
-
2.直接用fully connect feedforward network来做影像处理的时候,需要太多参数。
CNN能简化neural network的架构,处理影像时,某些weight用不上,我们一开始就把它滤掉。不是用fully connect feedforward network,而是用比较少的参数来做影像处理这件事。现在从下面3个方面进行阐述。
1.1 小区域(Small region )
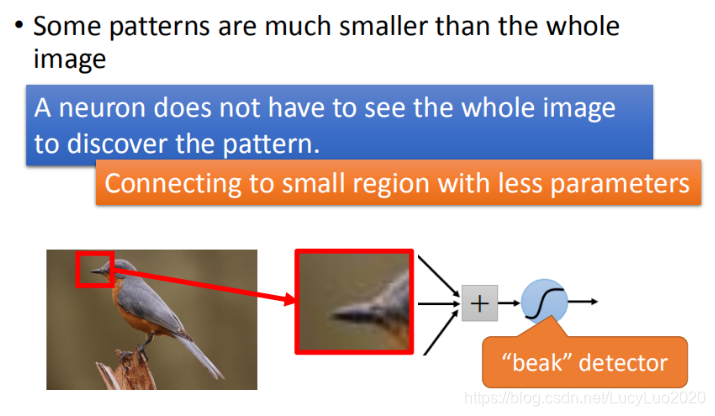
处理影像时,对于第一层的 hidden layer,neural的作用是侦测某一种pattern,看它是否出现?大部分的pattern其实比整张的image还要小,对一个neural来说,假设它要知道一个image里面有没有出现某一个pattern,它不需要看整张image,只要看image的一小部分。
举例:假设我们现在有一张图片,第一个hidden layer的某一种neural的工作就是要侦测有没有鸟嘴的存在(有一些neural侦测有没有爪子的存在,有一些neural侦测有没有翅膀的存在,有没有尾巴的存在,合起来就可以侦测图片中某一只鸟)。其实它并不需要看整张图,只需要给neural看一小红色方框的区域(鸟嘴),它就可以知道它是不是一个鸟嘴。对人来说也是一样,看这一小块区域这是鸟嘴,不需要去看整张图才知道这件事情。所以,每一个neural连接到每一个小块的区域就好了,不需要连接到整张完整的图。
1.2 相同的图案(Same Patterns)
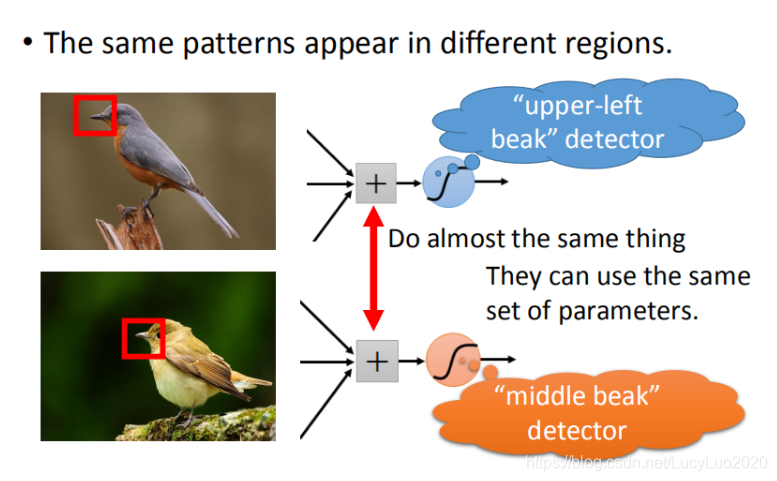
观察上图,同样的pattern在image里面,可能会出现在image不同的部分,但是代表的是同样的含义,它们有同样的形状,可以用同样的neural,同样的参数就可以把patter侦测出来。
在这张图里面,有一张在左上角的鸟嘴,有一个在中央的鸟嘴,但是你并不需要说:我们不需要去训练两个不同的探测器(detector),一个专门去侦测左上角的鸟嘴,一个去侦测中央有没有鸟嘴。如果这样做的话,这样就太冗了。我们不需要太多的冗源,这个nerual侦测左上角的鸟嘴跟侦测中央有没有鸟嘴做的事情是一样的。我们并不需要两个neural去做两组参数,我们就要求这两个neural用同一组参数,就样就可以减少需要参数的量。
1.3 二次抽样(Subsampling)

一个image,你可以做subsampling,把一个image的奇数行,偶数列的pixel拿掉,变成原来十分之一的大小,它其实不会影响人对这张image的理解。我们会觉得这两张image看起来可能没有太大的差别。所以我们就可以用这样的概念把image变小,这样就可以减少需要的参数。
二、CNN架构
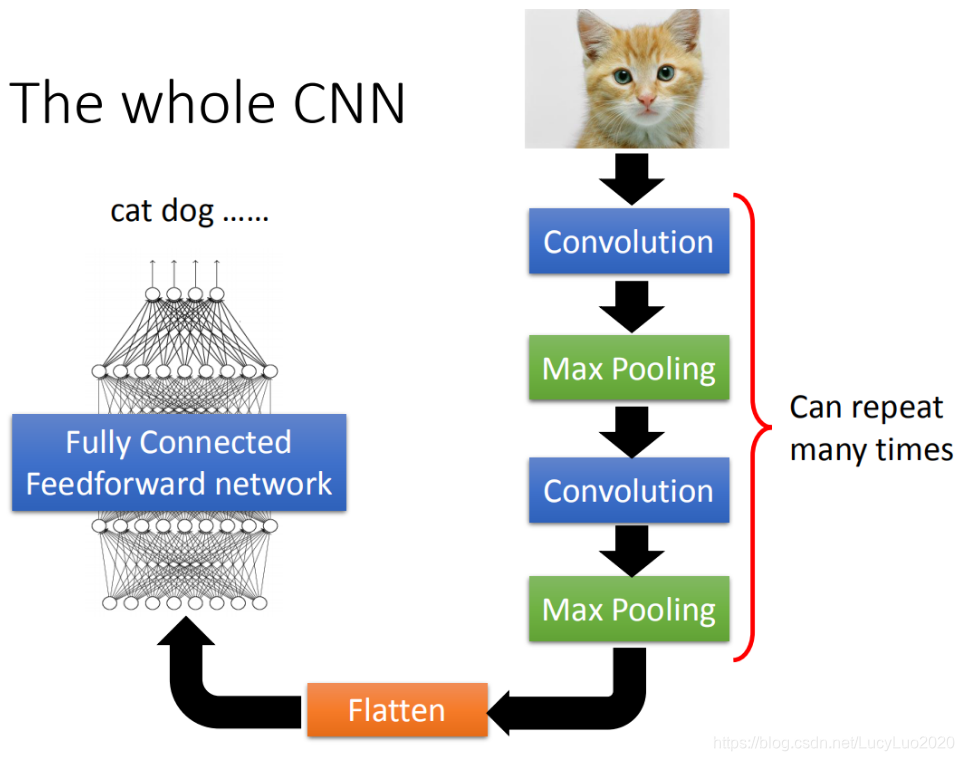
CNN的架构如下:
- 1.输入一张图片后通过卷积层(convolution layer);
- 2.然后做max pooling;
- 3.再做卷积(convolution);
- 4.2-3步重复多次;(反复多少次是事先决定的,即network的架构)
- 5.压平(flatten);
- 6.最后把flatten的output丢到一般全连接前馈网络(fully connected feedforward network),就可以得到影像辨识的结果。
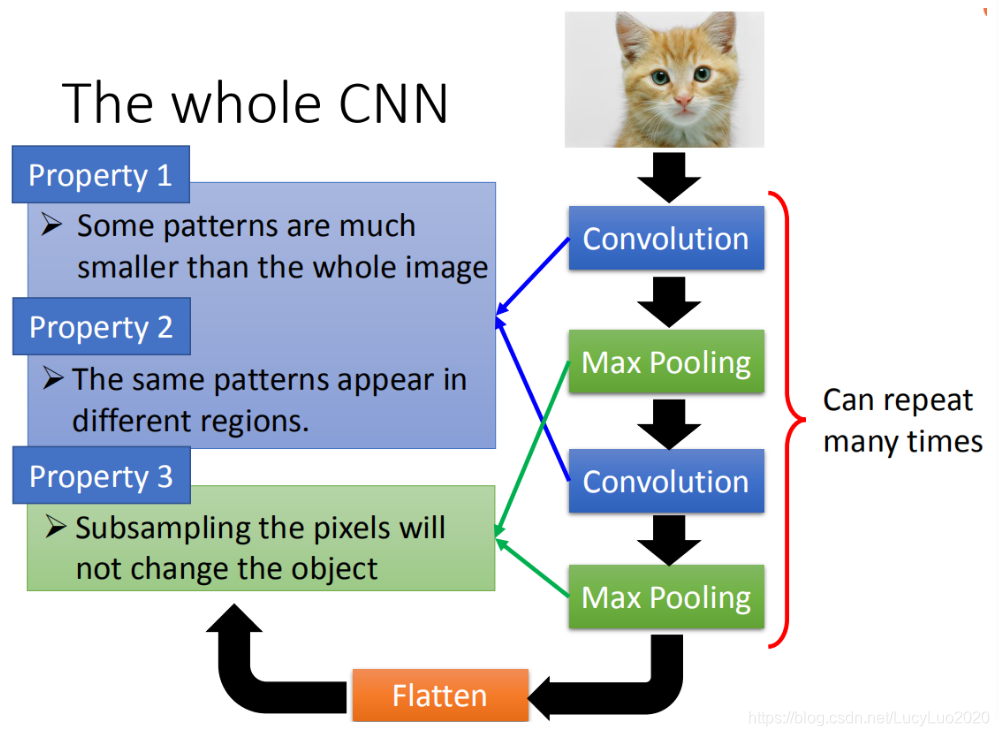
基于前面三个影像处理的观察,得出:
- 第一,要生成一个pattern,不要看整张的image,只需要看image的一小部分。
- 第二,通用的pattern会出现在一张图片的不同的区域。
- 第三,可以subsampling。
前面的两个property可以用convolution来处理掉,最后的property可以用Max Pooling这件事来处理。
三、卷积(Convolution)
3.1 属性1(Property1)
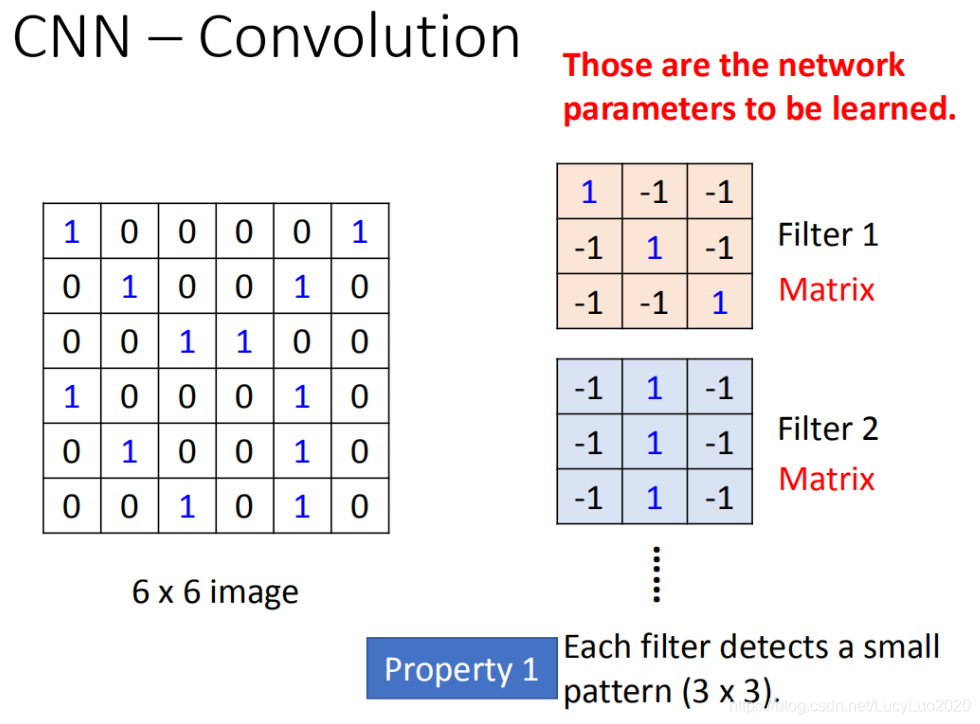
假设现在network的输入是一张6*6的Image,如果是黑白的,一个pixel就只需要用一个value去描述它,1就代表有涂墨水,0就代表没有涂到墨水。那在convolution layer里面,它由一组过滤(filter),(其中每一个filter其实就等同于是fully connect layer里面的一个neuron),每一个filter其实就是一个矩阵――matrix(3 *3),这每个filter里面的参数(matrix里面每一个element值)就是network的参数(parameter,这些parameter是要学习出来,不需要人去设计)
每个filter如果是3* 3的检测(detects)意味着它就是再侦测一个3 *3的pattern(看3 *3的一个范围)。在侦测pattern的时候不看整张image,只看一个3 *3的范围内就可以决定有没有某一个pattern的出现。这个就是我们考虑的第一个属性(Property)。
3.2 属性2(Propetry2)
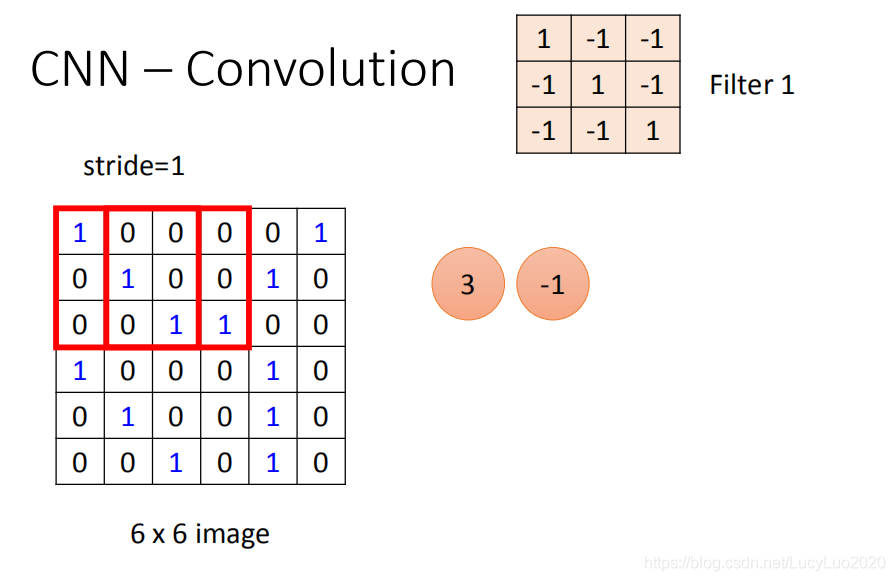
filter跟image怎么运作?
首先第一个filter是一个3* 3的matrix,把这个filter放在image的左上角,把filter的9个值和image的9个值做内积,两边都是1,1,1(斜对角),内积的结果就得到3。(移动多少是事先决定的),移动的距离叫做步长(stride――stride等于多少,自己设计)。
四、卷积和全连接之间的关系
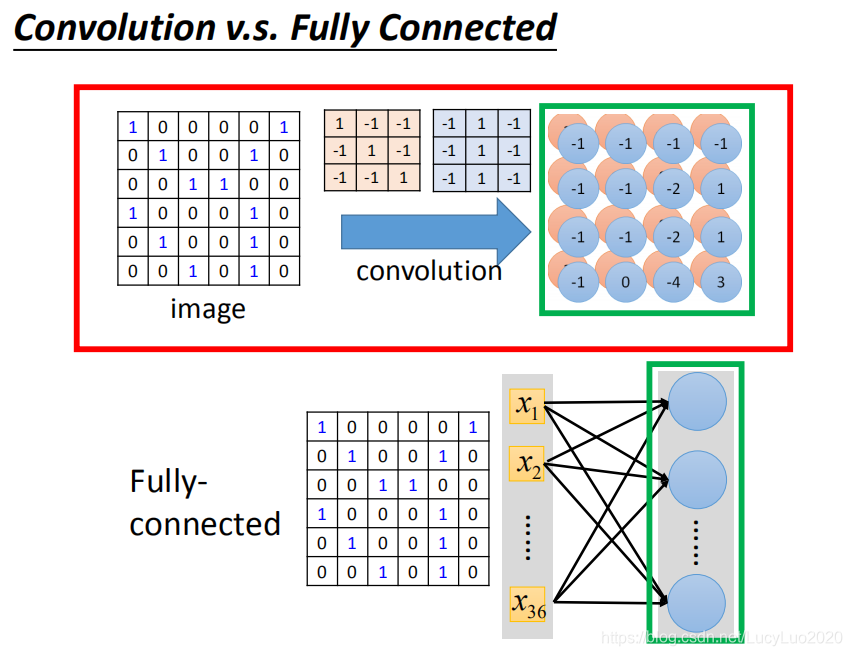
convolution就是fully connected layer把一些weight拿掉了。经过convolution的output其实就是一个hidden layer的neural的output。如果把这两个link在一起的话,convolution就是fully connected拿掉一些weight的结果。
五、Max pooling
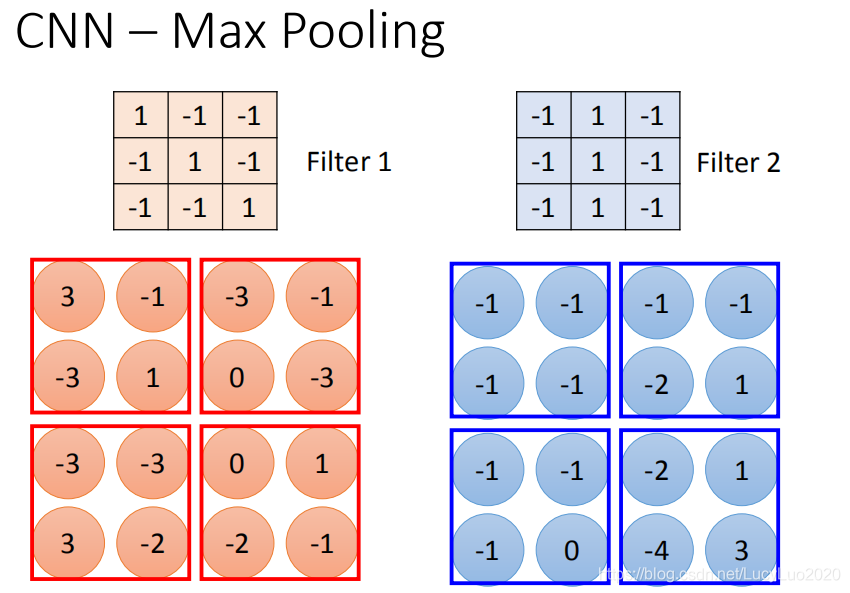
如上图,根据filter 1得到4*4的maxtrix,根据filter2得到另一个4 *4的matrix,输出,4个一组。每一组里面可以选择它们的平均或者选最大的,把四个value合成一个value,让image缩小。
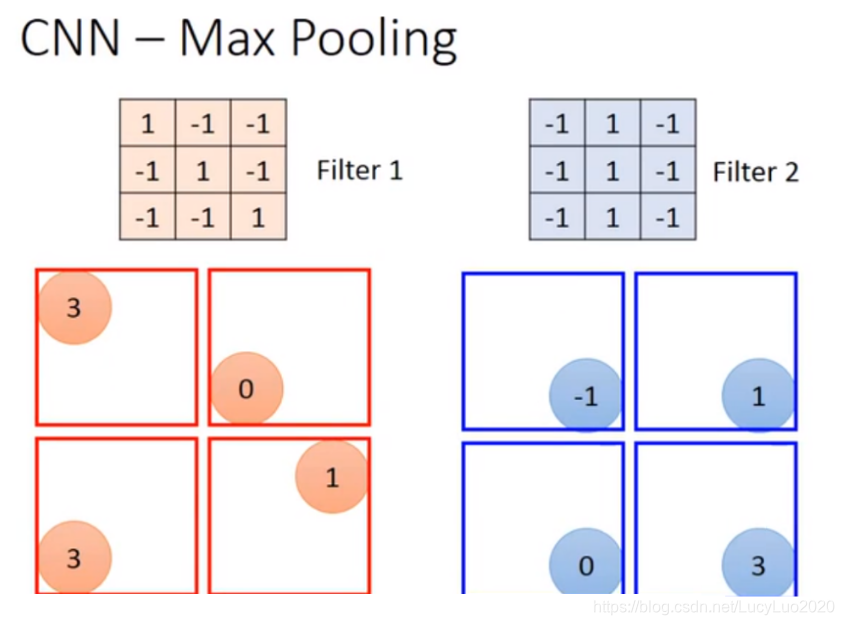
如果选择四个里面的max vlaue都保留下来,这样可能会有个问题,把这个放到neuron里面,这样就不能够微分了,但是可以用微分的办法来处理。
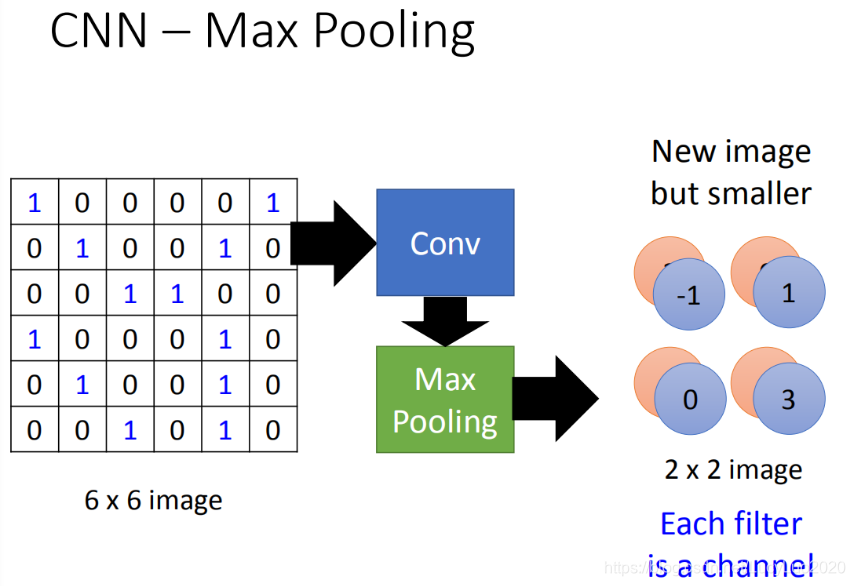
做完一个convolution和一次max pooling,就将原来6 * 6的image变成了一个2 *2的image。这个2 *2的pixel的深度depend你有几个filter,得到的结果就是一个new image but smaller,一个filter就代表了一个channel。
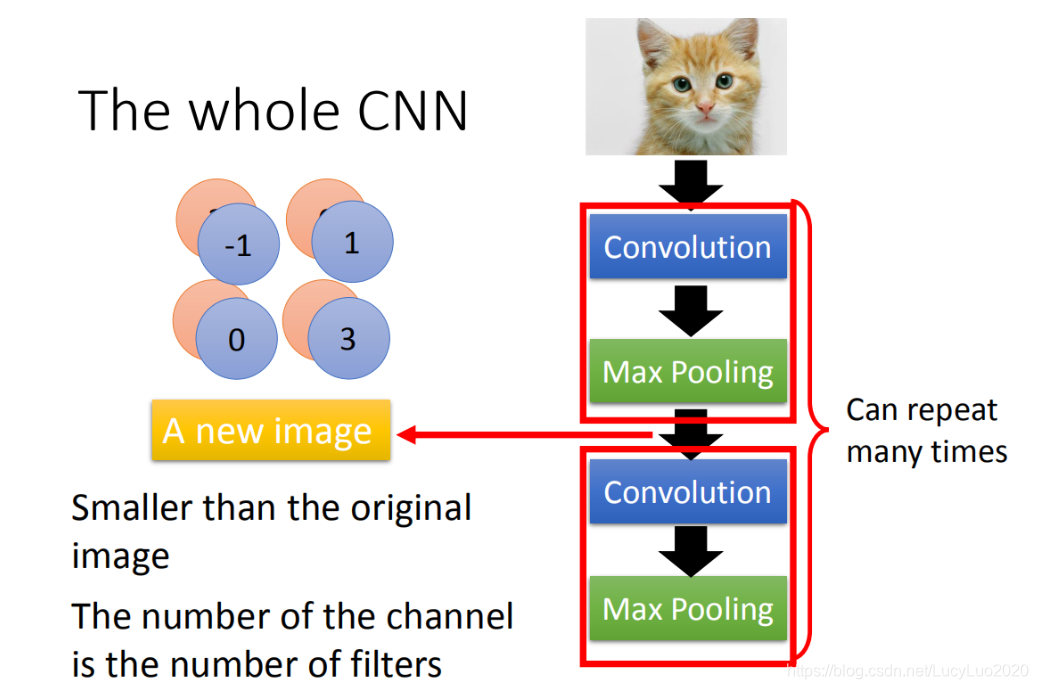
这件事可以重复多次,通过一个convolution + max pooling就得到新的 image。它是一个比较小的image,可以把这个小的image,做同样的事情,再次通过convolution + max pooling,将得到一个更小的image。
这边有一个问题:第一次有25个filter,得到25个feature map,第二个也是由25个filter,那将其做完是不是要得到 2 5 2 25^2 252的feature map。其实不是这样的!
假设第一层filter有2个,第二层的filter在考虑这个imput时是会考虑深度的,并不是每个channel分开考虑,而是一次考虑所有的channel。所以convolution有多少个filter,output就有多少个filter(convolution有25个filter,output就有25个filter。只不过,这25个filter都是一个立方体)
六、压平(Flatten)
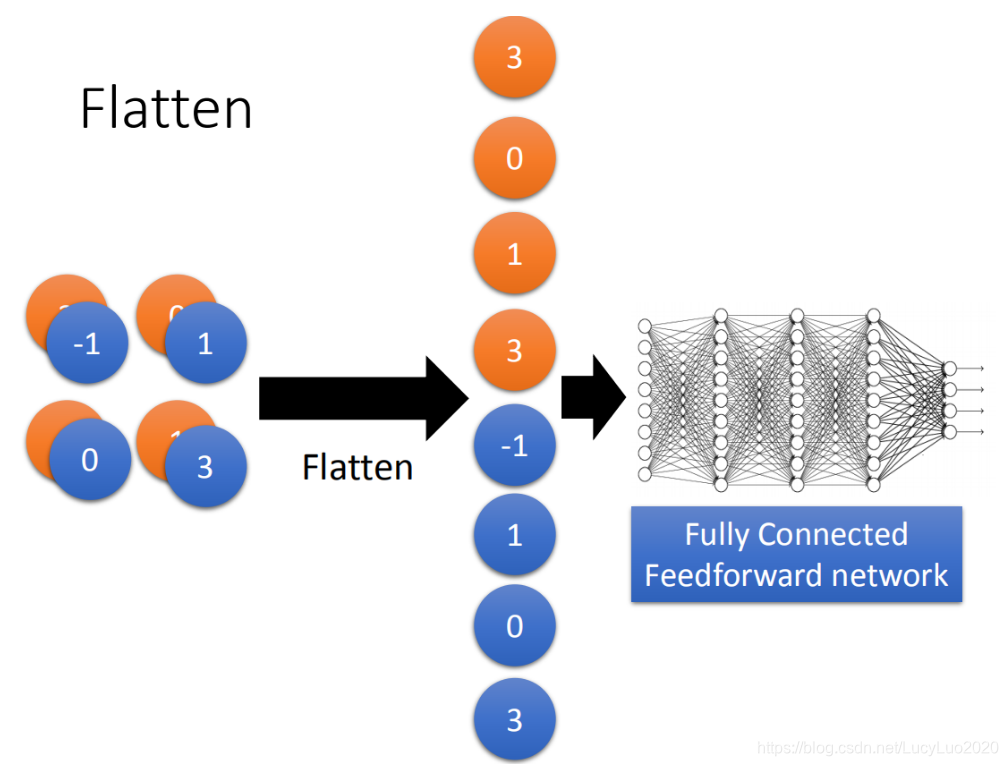
flatten就是特征图(feature map)拉直,拉直之后就可以丢到fully connected feedforward netwwork,然后就结束了。