周志华西瓜书学习笔记(四)
CNN卷积神经网络原理
卷积网络(CNN)是一种专门用来处理具有类似网格结构的数据的神经网络,例如:时间序列数据和图像数据。
机器识图的过程:识别图像并不是一下子将一个复杂的图片完整识别出来,而是将一个完整的图片分割成许多个小部分,把每个小部分里具有的特征提取出来(也就是识别每个小部分),再将这些小部分具有的特征汇总到一起,就可以完成机器识别图像的过程了 。
卷积神经网络工作步骤

一、卷积层初步提取特征
-
卷积: s ( t ) = ∫ x ( a ) ? w ( t ? a ) d a s(t)=\int x(a)・w(t-a)da s(t)=∫x(a)?w(t?a)da这种运算称为卷积。卷积运算通常用星号表示: s ( t ) = ( x ? w ) ( t ) s(t)=(x*w)(t) s(t)=(x?w)(t)。其中第一个参数(这里为函数x)通常叫做输入(input),第二个参数(这里为函数w)叫做核函数,可以理解为一种权重。
-
卷积层作用:提取每个小部分里具有的特征
-
过程说明:假设现在图形数据是一个66的矩阵,权重(也就是核函数)为33的矩阵,这个矩阵的作用就是从图像中提取一定的特征。在图形数据矩阵里从左上角开始选出一个与权重矩阵形状一样的矩阵,权重与这个数字矩阵对应的位置全部相乘再求和,得到卷积层输出结果。然后再设定移动的步长,继续计算。过程如图:

? 图中展示的就是计算了两次的结果,只要我们把整个图像数据计算完,得到的结果就能构成一个矩阵。这个矩阵就是这一步的输出,也是下一步的输入。
说明:权重(核函数)有限制,矩阵每一行中的元素都要与上一行同一列的元素再向右平移一个位置的元素相同。比如矩阵中的第3行第2列元素,就要与上一行(第2行)同一位置(第2列)向右平移一个位置(第3列)即第2行第3列元素相同。这种矩阵称为Toeplitz矩阵。具体介绍见这。
其次,核函数需要事先给出,通过不同的卷积核计算得到的输出值,来选择最能表现该图片的特征的核。通过不断的训练学习,优化出能反映图像特征的核函数。得到的输出值越高,就说明这部分图像的特征与核匹配度越高。
卷积的优势:
- 卷积网络具有稀疏交互的特征,使得核的大小远小于输入的大小。我们可以通过只占几十个像素点的核来检测一些小的有意义的特征。
- 参数共享,一个模型的多个函数中使用相同的参数。核的每一个元素都作用在输入的每一位置上,大大减少了参数的数量。
- 等变表示,卷积由于参数共享的形式使得神经网络具有对平移平等的性质。如果一个函数满足输入改变,输出也以同样的方式改变。
二、池化层提取主要特征
池化层的形式:最大池化(max-pooling)和平均池化(mean-pooling)
顾名思义,就是对上一步骤得到的结果进行分块,在每一块中取最大值或平均值来反映图片信息。以最大池化为例:有两个核计算得到的结果,进行最大池化后结果如下:

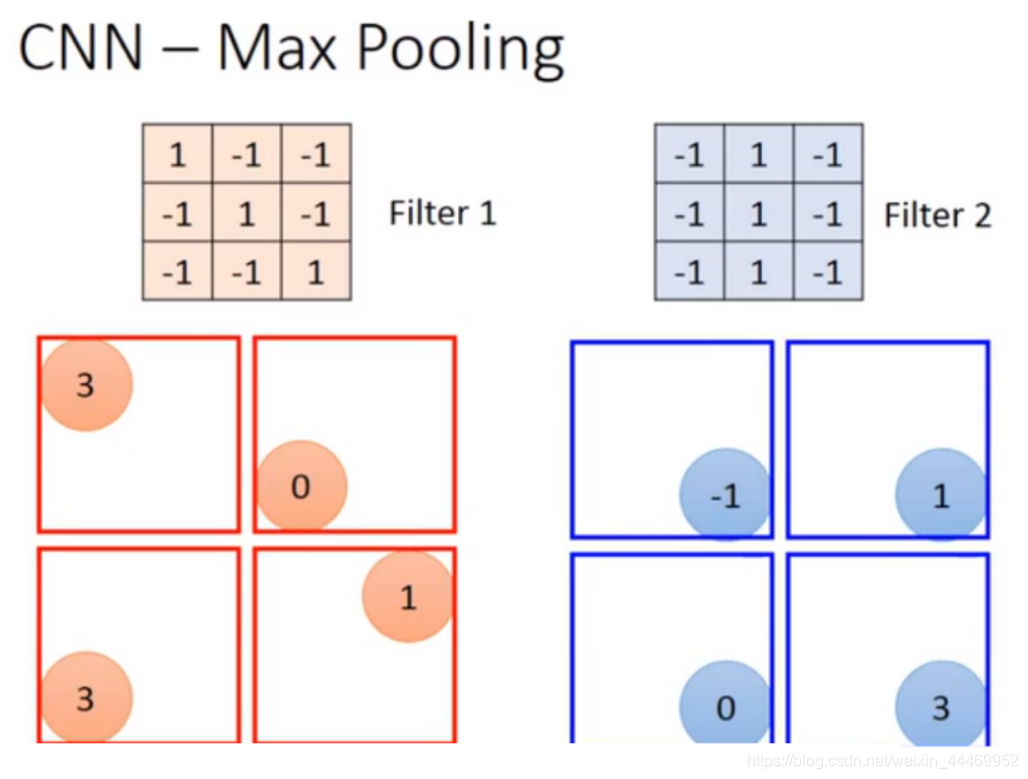
到这里为止,做完一个卷积(convolution)和一次池化(max pooling),就将原来6 * 6的image变成了一个2 *2的image。如果说此时的image像素还是很大,我们可以继续做卷积和池化,甚至可以做多次。
三、全连接层将各部分特征汇总
作用:为了生成最终的输出,使用全连接层来生成一个分类器,这个分类器的输出结果就是我们要分的类。

flatten就是feature map拉直,拉直之后就可以丢到fully connected feedforward netwwork,得到输出结果。
到此,就产生了分类器,可以进行预测识别。
本文参考链接:https://datawhalechina.github.io/leeml-notes/#/chapter21/chapter21
https://blog.csdn.net/kun1280437633/article/details/80817129?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162699941416780366564067%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=162699941416780366564067&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-2-80817129.first_rank_v2_pc_rank_v29&utm_term=%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&spm=1018.2226.3001.4187