TransReID
这篇文章是首个将视觉Transformer的ViT应用在ReID领域的研究工作,在多个ReID基准数据集上取得了超过CNN的性能。
原文:TransReID: Transformer-based Object Re-Identification
代码:https://github.com/heshuting555/TransReID
作者:阿里巴巴&浙江大学
Contributions
- 以调整适用于ReID任务的ViT作为Backbone进行特征提取,提出了名为ViT-BoT的Baseline
- 针对图像的视角、相机风格变化问题在Baseline上引入了Side Information Embedding(SIE)模块
- 在Baseline上引入了一个并列的Jigsaw分支(JPM),对全局和局部特征进行融合
Vision Transformer(ViT)学习
Transformer来源于2017 年谷歌机器翻译团队发表的《Attention is All You Need》。它完全抛弃了传统RNN和CNN等网络结构,仅仅采用Attention机制来进行机器翻译任务,取得了当时SOTA的效果。
Transformer最初提出是针对NLP领域的,ViT是将Transformer应用到CV领域,也取得了很好的效果。
原文:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
代码:https://github.com/google-research/vision_transformer
作者:谷歌
具体方法
在模型设计中,使用到了原始的Transformer Encoder,ViT对Transformer使用了最少的修改就将其用于计算机视觉,将图像分成小的patch,类似于nlp中的token,然后使用有监督的方式对训练模型以对图像分类。
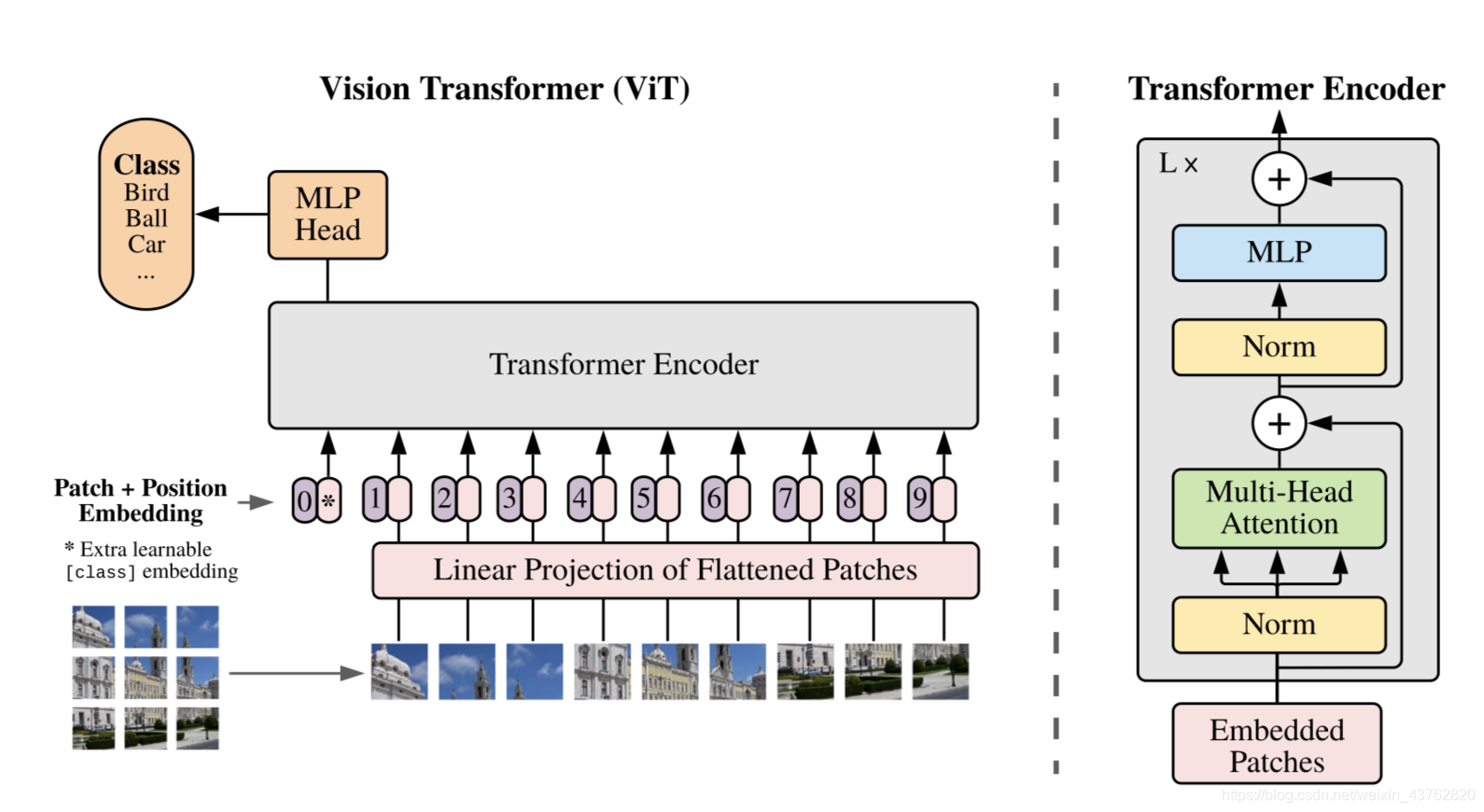
Patch Embedding
标准的Transformer以一串一维的token序列作为输入,为将图像变成对应的一维的序列patch embedding输入,将二维图像分成N个PxP大小的patch。本质就是对每一个展平后的 patch 向量做一个线性变换降维至 D 维,等同于对x进行P×P且步长为P的卷积操作
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
Position Encodings
目前Positional Encodings分为两种类型:
- Fixed Positional Encodings:即将各个位置的标志设定为固定值,一般是采用不同频率的Sin函数来表示。
- Learnable Positional Encoding:即训练开始时,初始化一个和输入token数目一致的tensor,这个tensor会在训练过程中逐步更新。
Transformer 原论文中默认采用固定的位置编码,ViT 则采用标准的可学习的1-D位置编码嵌入
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
# patch emded + pos_embed
x = x + self.pos_embed
Class Token
- 为什么输入的tokens里要加一个额外的Learnable Embedding?
因为transformer输入为一系列的patch embedding,输出也是同样长的序列patch feature,但是最后进行类别的判断时不知道用哪一个feature,需要一个代表总体的feature,简单方法可以用avg pool,把所有的patch feature都考虑算出image feature。但是作者没有用这种方式,而是引入一个class token,在输出的feature后加上一个线性分类器就可以实现分类。class token在训练时随机初始化,然后通过训练学习得到。
# 随机初始化
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# Classifier head
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
# Forward
B = x.shape[0] # Batch Size
# Patch Embeddings
x = self.patch_embed(x)
# class token
cls_tokens = self.cls_token.expand(B, -1, -1) # stole
# 按通道拼接 获取N+1维的Embeddings
x = torch.cat((cls_tokens, x), dim=1)