互信息最大化[视角统一]:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
摘要
视觉和语言表示学习已经广泛被应用与各种视觉语言任务。现有方法大多数基于Transformer方法的多模态编码器同时进行视觉特征学习(基于区域的图像特征)和文本特征学习。鉴于视觉特征和文本特征之间的语义空间不一致问题,因此多模态编码器在学习图像-文本交互上具有非常大的挑战性。文章通过引入对比损失,通过跨模态注意将图像和文本表示在融合前对齐(ALBEF),从而实现更扎实的视觉和文本表示学习,同时本文的方法不要对图像数据进行标注且图像分辨率要求不高。为了更好的对噪声数据进行学习,我们提出了动量蒸馏,这是一种从动量模型产生的伪目标中学习的自我训练方法。同时文章从互信息最大化的角度对文章中提出的方法进行了理论分析,表明不同的训练任务可以理解为从不同视角对图像-文本的描述建模。
ALBEF 在多个下游视觉语言任务上实现了最先进的性能。在图像文本检索方面,ALBEF优于在更大数量级数据集上预训练的方法。在 VQA 和 NLVR2上,ALBEF与最先进的技术相比,实现了 2.37% 和 3.84%的绝对改进,同时享有更快的推理速度。
代码:https://github.com/salesforce/ALBEF/
相关工作
Vision-Language Representation Learning
大多数现有的视觉语言表示学习工作分为两类。
第一类侧重于使用基Transformer方法的多模态编码器对图像和文本特征之间的交互进行建模
。此类方法在需要对图像和文本进行复杂推理的下游 V+L 任务(例如 NLVR2 、VQA)上实现了卓越的性能,但其中大多数需要高分辨率输入图像和基于检测框的特征提取器;也有学者通过去除目标检测特征提取器来提高推理速度,但会导致性能下降。
**第二个类别侧重于学习单独的图像和文本的编码器对文本和图像进行建模;**最近的CLIP 和 ALIGN使用对比损失对大量嘈杂的网络数据进行预训练,这是表示学习最有效的损失之一它们在图像-文本检索任务上取得了卓越的性能,但缺乏为其他V+L 任务对图像和文本之间更复杂的交互进行建模的能力。
本文的ALBEF方法统一了这两个类别,导致强大的单峰和多峰表示在检索和推理任务上具有卓越的性能。此外,ALBEF不需要基于检测的特征提取器,这是许多现有方法的主要计算瓶颈。
Knowledge Distillation
知识蒸馏旨在通过从教师模型中提取知识来提高学生模型的性能,通常是通过将学生的预测与教师的预测相匹配;大多数方法通过同时训练的多个教师模型并使用它们的集合作为教师从中提取知识。动量蒸馏可以解释为一种在线自我蒸馏的形式,其中使用学生模型组成的集合作为老师。类似的方法已经在半监督学习、标签噪声学习以及最近的对比学习中进行了探索应用。与现有研究不同,本文从理论上和实验上表明,动量蒸馏是一种通用的学习算法,可以提高模型在许多V+L 任务上的性能。
模型架构
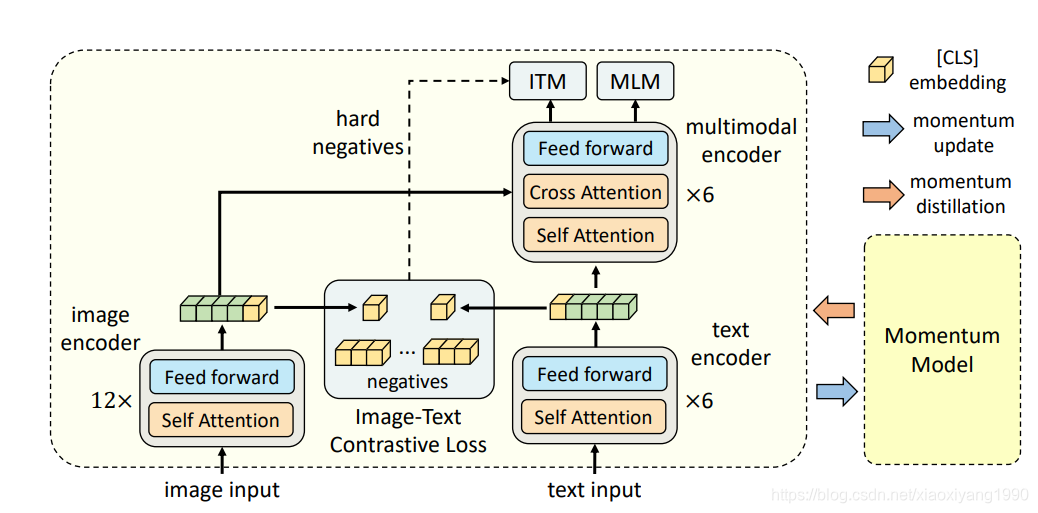
它由一个图像编码器、一个文本编码器和一个多模态编码器组成。文章提出了一种图像文本对比损失,在图像文本融合之前对图像文本进行统一表示建模。
图像文本匹配损失和掩码语言建模损失被应用于学习图像和文本之间的多模态交互。为了改进噪声数据的学习,我们使用动量模型生成伪目标来作为训练期间的额外监督。
预训练任务
作者认为,图文对比学习,掩码语言建模,图文匹配任务都是追求互信息最大话方式的一种视角,将基于三种预训练任务进行了统一建模(笔者认为这个地方是最为出彩的地方)
图文对比学习

这里笔者任务主要的思路启发来源于CLIP和MOCO这两篇文章感兴趣的小伙伴可以深入下;简单来讲,采用CLIP文章中的INfoNCE Loss追求Image和Text之间的互信息最大化;同时采用MOCO方法扩充负样本的数量。
掩码语言建模
掩码语言建模利用图像和上下文文本来预测掩码单词。
图文匹配任务

实验结果
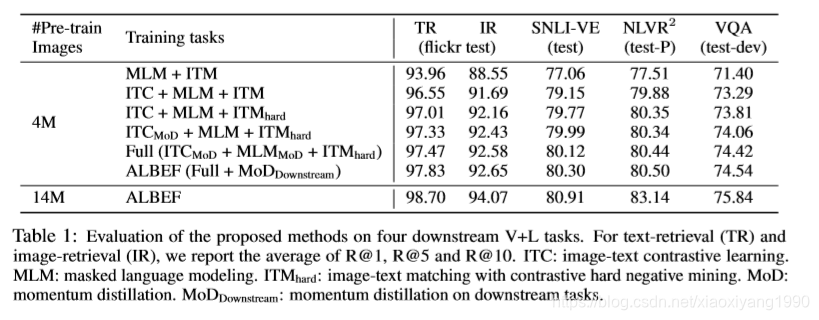
与现有方法相比,ALBEF 在多个下游 V+L任务上提供了更好的性能和更快的推理速度。同时作者建议使用部署是应该进行充分的测试,以及可能在社交媒体上面带来的潜在危害;