知识蒸馏的局限
学生网络仅关注教师网络的预测结果,而没有充分利用到教师网络中的参数,相对而言粗糙且宽泛。
权重蒸馏有多厉害
与2015年的知识蒸馏相比,在相同的数据集上,效果提升0.51-1.82个BLEU,速度提升1.11-1.39倍。
(这里速度不一定可信,因知识蒸馏那篇文章里提到了贪婪搜索提速,而本文并没有对其进行贪婪搜索)
权重蒸馏是什么
简单来说:利用教师网络中的一部分参数作为学生网络参数的初始值
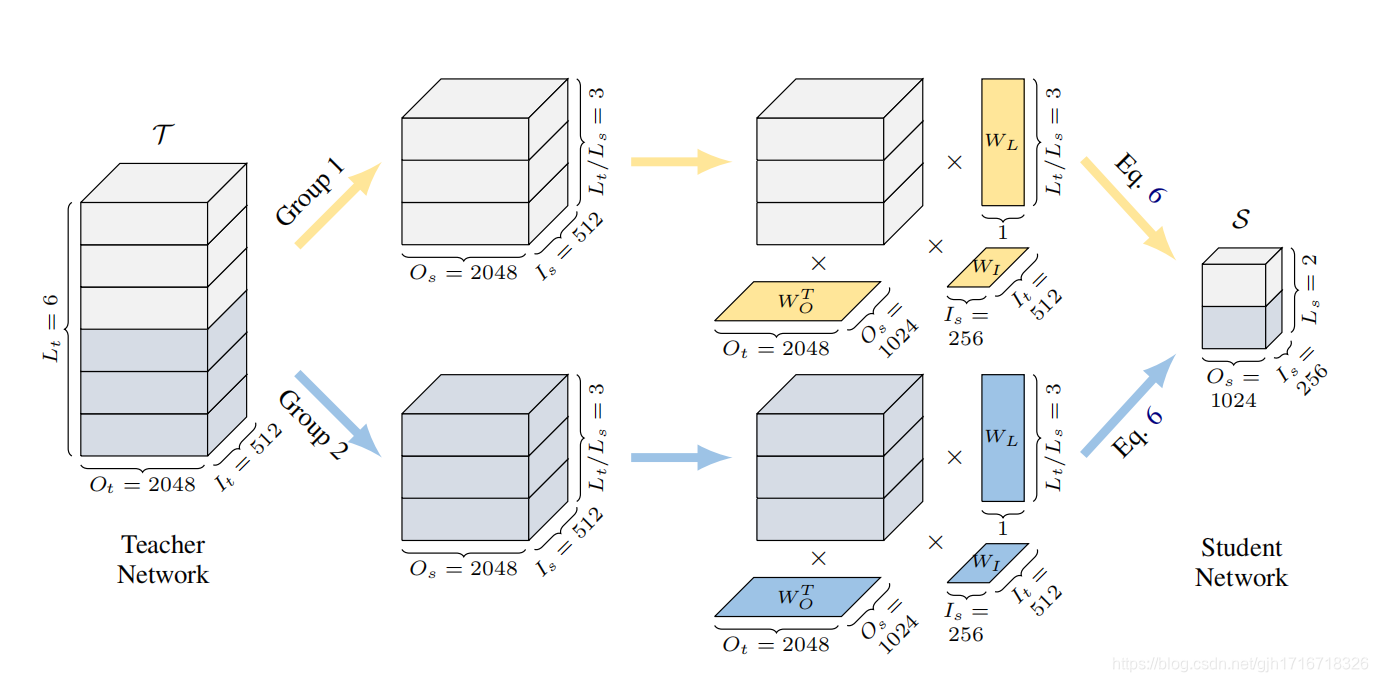
具体做法:因为教师网络和学生网络的结构不同,矩阵形状不同,因此不能直接迁移参数,而是通过参数生成器(Parameter Generator)对教师参数进行处理。然后再转移到学生网络中。
参数生成器(Parameter Generator)
通过教师参数对学生参数进行预测是有可能的,但实现上会有很多问题。
权重分组(Weight Grouping)
比如参数过多,如果一次性把几十亿的参数全部放进内存的话效率会非常低,因此需要对参数进行分组,逐一操作。
文章在权重的基础上定义了类(Class)和实例(Instance)的概念。
- 实例的最小单位是层,文中举例的是全连接层(Feed-Forward-Network)
- 各类权重在整个网络中有不同的功能,同类权重功能相似
- 类是由实例聚类(cluster)而来的(different weight classes clusters all their instantiations to form their own groups.)
然后文章又定义了类的等价概念群(Groups),以及细分概念子集(Subset)
- 相邻的层会被划分到一个子集中,因为相邻层更相似
权重转换(Weight Transformation)
举例:将 L t / L s L_t/L_s Lt?/Ls?层的 I t I_t It? x O t O_t Ot?的参数,转换为1层 I s I_s Is? x O s O_s Os?
- 将 L t / L s L_t/L_s Lt?/Ls?层的 I t I_t It? x O t O_t Ot?的参数视作 I t I_t It? x O t O_t Ot? x L t / L s L_t/L_s Lt?/Ls?的矩阵
- 定义可学习的线性变换矩阵 W I ∈ R I t ? I s W_I \isin \reals^{I_t * I_s} WI?∈RIt??Is?,与当前矩阵( I t I_t It? x O t O_t Ot? x L t / L s L_t/L_s Lt?/Ls?)相乘,分别进行输入维度变换得到 T ∈ R I s ? O t ? L t / L s T \isin \reals^{I_s*O_t*L_t/L_s} T∈RIs??Ot??Lt?/Ls?
- 定义可学习的线性变换矩阵 W O ∈ R O t ? O s W_O \isin \reals^{O_t * O_s} WO?∈ROt??Os?,与当前矩阵( I s I_s Is? x O t O_t Ot? x L t / L s L_t/L_s Lt?/Ls?)相乘,分别进行输入维度变换得到 T ∈ R I s ? O s ? L t / L s T \isin \reals^{I_s*O_s*L_t/L_s} T∈RIs??Os??Lt?/Ls?
- 定义可学习的线性变换矩阵 W L ∈ R L t / L s ? 1 W_L \isin \reals^{L_t/L_s * 1} WL?∈RLt?/Ls??1,与当前矩阵( I s I_s Is? x O s O_s Os? x L t / L s L_t/L_s Lt?/Ls?)相乘,分别进行输入维度变换得到 T ∈ R I s ? O s ? 1 T \isin \reals^{I_s*O_s*1} T∈RIs??Os??1
- 定义可学习的矩阵W(形状与T相同)和偏置B, S = t a n h ( T ) ? T + B S=tanh(T)\bigotimes T+B S=tanh(T)?T+B
- 同类权重共享相同的线性变换矩阵
训练过程
- 首先需要训练参数生成器,即训练定义的可学习矩阵
- 其次对学生网络进行微调
训练参数生成器
优化目标:通过权重转换获得的学生网络与教师网络尽可能接近
更新参数:参数生成器
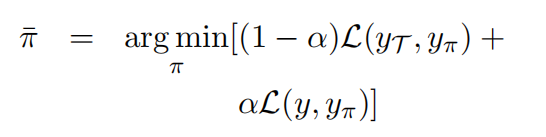
学生网络微调
优化目标:通过权重转换获得的学生网络与教师网络尽可能接近
更新参数:学生网络
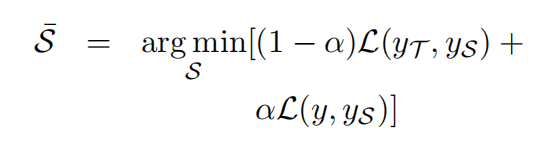
实验部分
数据集
- English-Roman:WMT16,包含610K个平行句对
- Chinese-English:NIST12 OpenMT,包含1800K个平行句对
- English-German:WMT14,包含4500K个平行句对
模型设置
- Transformer-base:6-enc 6-dec 512(Embedding)+2048(FNN)
- Transformer-deep:48-enc 6-dec 512(Embedding)+2048(FNN)
- Transformer-big:6-enc 6-dec 1024(Embedding)+4096(FNN)
- TINY:6-enc 1-dec 解码器宽度减半
- SMALL:6-enc 2-dec 解码器宽度不变
结果对比
English-Roman
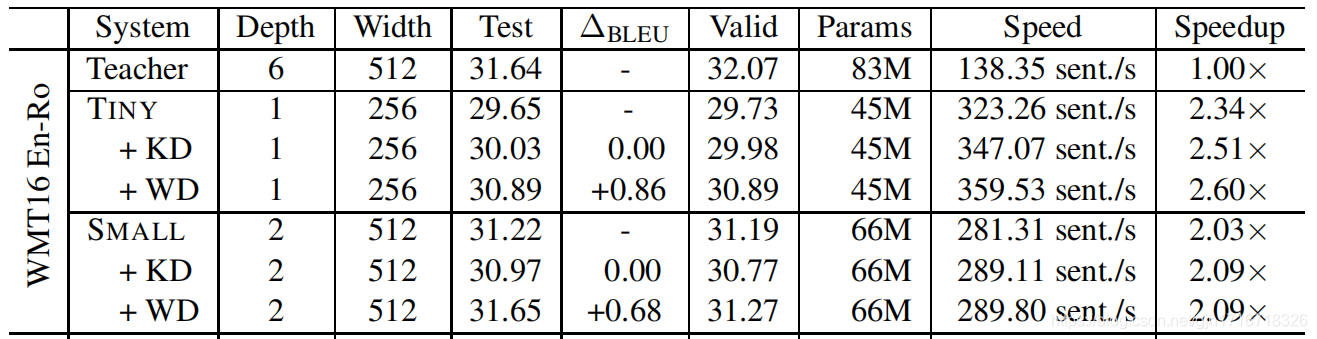
- TINY:模型压缩比率0.54,速度提升2.6倍
- TINY:BLEU-比老师低0.75,比同学高0.86
- SMALL:模型压缩比率0.79,速度提升2.09倍
- SMALL:BLEU-比老师高0.01,比同学高0.68
Chinese-English
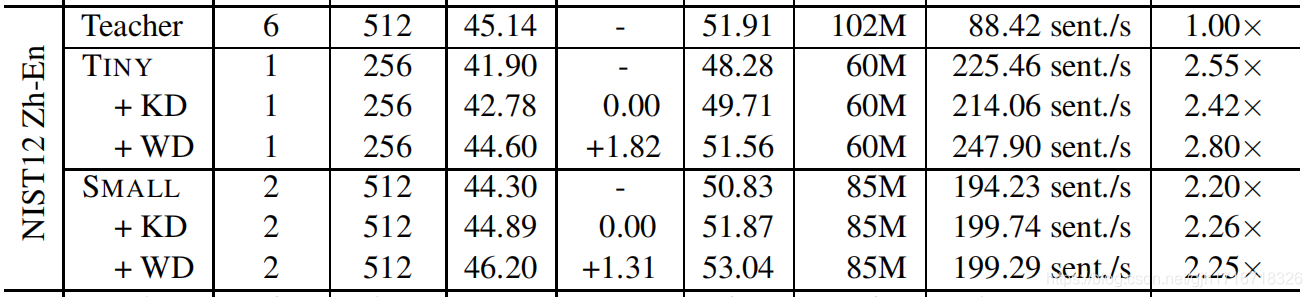
- TINY:模型压缩比率0.58,速度提升2.8倍
- TINY:BLEU-比老师低0.54,比同学高1.82
- SMALL:模型压缩比率0.83,速度提升2.25倍
- SMALL:BLEU-比老师高1.06,比同学高1.31
English-German (base)
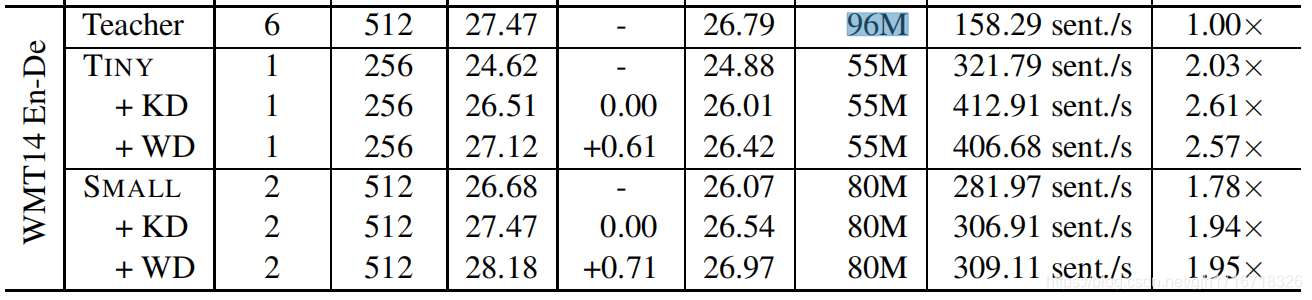
- TINY:模型压缩比率0.57,速度提升2.57倍
- TINY:BLEU-比老师低0.35,比同学高0.61
- SMALL:模型压缩比率0.83,速度提升1.95倍
- SMALL:BLEU-比老师高1.5(数据越多,这条越好),比同学高0.71
English-German (big)
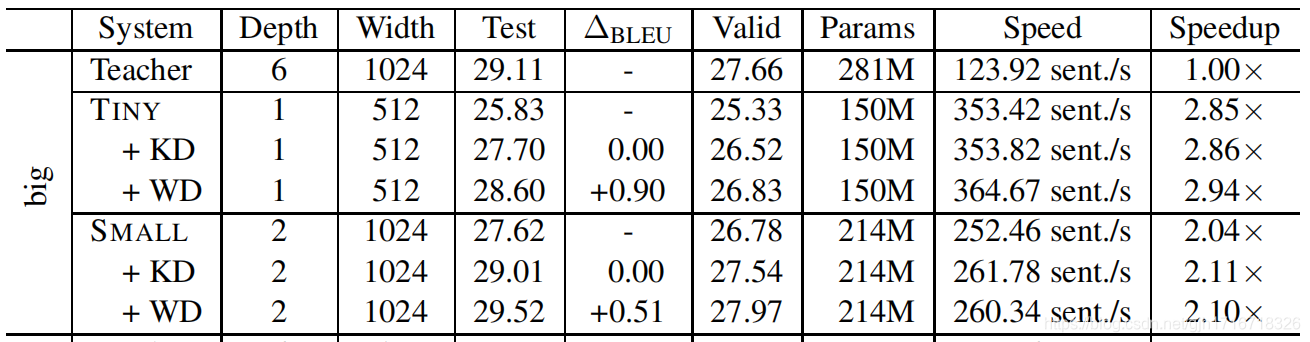
- TINY:模型压缩比率0.53,速度提升2.94倍
- TINY:BLEU-比老师低0.51,比同学高0.9
- SMALL:模型压缩比率0.76,速度提升2.1倍
- SMALL:BLEU-比老师高0.41,比同学高0.51
English-German (deep)
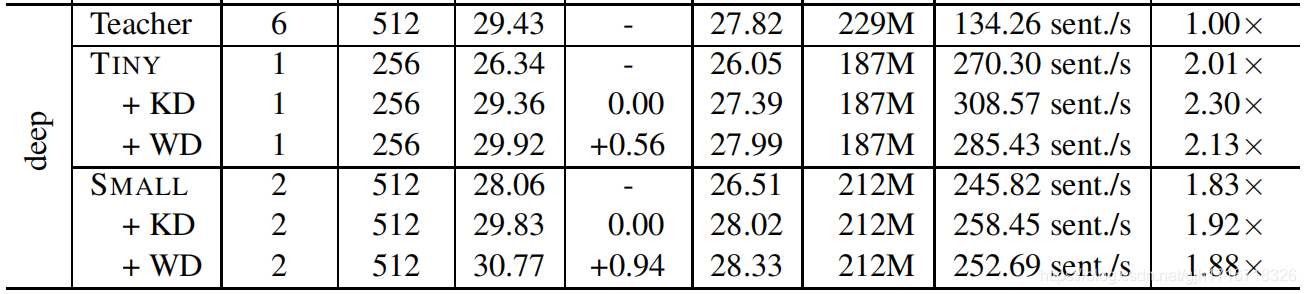
- TINY:模型压缩比率0.81,速度提升2.13倍
- TINY:BLEU-比老师低0.49,比同学高0.56
- SMALL:模型压缩比率0.92,速度提升1.88倍
- SMALL:BLEU-比老师高1.34,比同学高0.94