[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (18) �� kubeflow tf-operator
����Ŀ¼
0x00 ժҪ
Horovod ��һ����� AllReduce �ķֲ�ʽѵ����ܡ�ƾ����� TensorFlow��PyTorch ���������ѧϰ��ܵ�֧��,�Լ�ͨ���Ż����ص�,Horovod ���㷺Ӧ�������ݲ��е�ѵ���С�
ǰ��ͨ��ʮ��ƪ����,����һ��һ�������� Horovod �ķ������档������������� Horovod on K8S ������ɽ��
�����Լ���ƪ����Ŀ����:���ŷ���ѧϰ Horovod on K8S ����,����ظ�������һ��,�������Դ����ҳ����˼·�����Գ��ķ�ʽ��:����ѧϰ�˺ܶ���������,Ȼ���Լ��������롣�ش˶Ը�λ���������л��
������ horovod on k8s �IJ�ǰ���ͱر�ǰ��,������ظ����Լ�kubeflow ������ tf-operator��
��ϵ������������������:
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� Horovod �� (1) ����֪ʶ
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (2) �� ��ʹ���߽Ƕ�����
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (3) �� Horovodrun��������ʲô
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (4) �� ������� & Driver
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (5) �� �ںϿ��
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (6) �� ��̨�̼ܹ߳�
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (7) �� DistributedOptimizer
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (8) �� on spark
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (9) �� ���� on spark
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (10) �� run on spark
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (11) �� on spark �� GLOO ����
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (12) �� ����ѵ������ܹ�
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (13) �� ����ѵ��֮ Driver
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (14) �� ��η��ֽڵ����?
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (15) �� �㲥 & ֪ͨ
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (16) �� ����ѵ��֮Worker��������
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (17) �� ����ѵ��֮�ݴ�
0x01 ����֪ʶ
1.1 Kubernetes
kubernetes,���K8s,����8����8���ַ���ubernete�����ɵ���д����һ����Դ��,���ڹ�����ƽ̨�ж�������ϵ���������Ӧ��,Kubernetes��Ŀ�����ò�����������Ӧ�ü��Ҹ�Ч(powerful),Kubernetes�ṩ��Ӧ�ò���,�滮,����,ά����һ�ֻ��ơ�
Kubernetes ��һ��Խ��Խ�ܻ�ӭ�����������ѵ��ѡ��,��Ϊ���ṩ��ͨ������ʹ�ò�ͬ����ѧϰ��ܵ������,�Լ�������չ�������ԡ�
�����ٽϸ��ӵ�ģ��ѵ��������������ʱ,�����ļ���������������������Ҫ��ͨ��ʹ�ð���� AiACC ���������� horovod �ȷֲ�ʽѵ�����,�����ļ��д���,���ܽ�һ��������ѵ��������չΪ֧�ֲַ�ʽ��ѵ������
�� Kubernetes �ϳ������� kubeflow ������ tf-operator ֧�� Tensorflow PS ģʽ,���� mpi-operator ֧�� horovod �� mpi allreduce ģʽ��
1.2 ������Ϊ���ȵ�Ԫ
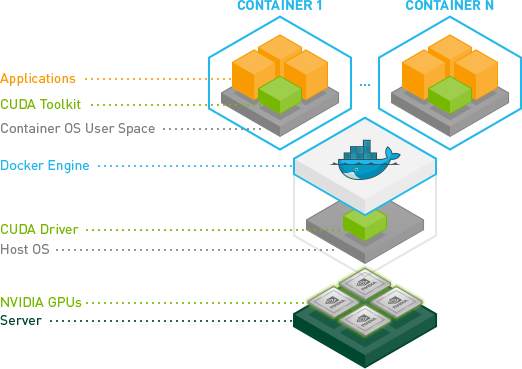
Ϊʲôϣ��ʹ����������Ϊ���ѧϰϵͳ�ĵ��ȵ�Ԫ?��Ϊ������ȡ/�������١�������ԴЧ���á���������,���Խ�������image��Ϊjob��һ���ַַ�����ִ�С���Ȼ�������������gpu,��������ܵĴ��ۡ�
���� nvidia gpu ��docker�ṩ��֧��,nvidia-docker���Դ���dockerִ��create��run��������ͼ����nvidia-docker�ܹ���
1.3 Kubeflow
Kubeflow ��һ����Դ�� Kubernetes ԭ��ƽ̨,���ڿ��������š���������п���չ�ı�Яʽ����ѧϰ�������ء�Kubeflow �������κ�Kubernetes ��Ⱥ�����С�
Kubeflow���ԺܺõĹ����������,Kubeflow�����ֱȽϼ�,ΪKubernetes + TensorFlow,��һ������ѧϰ���߰�,��������K8s֮�ϵ�һ����ջ,������ջ�����˺ܶ����,���֮��Ĺ�ϵ�Ƚ���ɢ,���ǿ������������,Ҳ���Ե��������е�һ���֡�
Kubeflow ѯ�� Kubernetes �ƻ������ļ�̨����������һ���ֲ�ʽ��ҵ�еĸ�������,���� ֪ÿ������,�����������̵� IP ��ַ�� port���Ӷ���֤һ����ҵ��������� ֮�以��֪���Է���
Ϊʲô��Ҫ�����н��̻���֪���Է���?���� TensorFlow ps-based distribution ��ʽҪ��ġ�TensorFlow 1.x ԭ���ķֲ� ʽѵ��������һ����ҵ�����н��̶�ִ�� TensorFlow 1.x runtime ������Щ ���̻���ͨ��,����Э����Ϊһ�����ֲ�ʽ runtime��,������ִ�б�ʾ���ѧϰ ������̵ļ���ͼ(graph)���ڿ�ʼ�ֲ�ʽѵ��֮��,graph �� TensorFlow runtime ����������ͼ;ÿ�����̸���ִ��һ����ͼ ���� �κ�һ������ʧ�� (�����DZ��������ȼ���ҵ��ռ),��������ͼ��ִ�о�ʧ���ˡ����� TensorFlow ԭ���ķֲ�ʽѵ�����������ݴ���(fault-tolerant)������, ���ǿ��ԴӴ���ָ�(fault-recoverable)���� TensorFlow API �ṩ checkpoint ������;���һ����ҵʧ����,����������ҵ,������� checkpoint ��ʼ����ִ�С�
1.4 Tensorflow on Kubeflow
Kubeflow ֧�����ֲ�ͬ�� Tensorflow ��ֲܷ�ʽѵ��������
- ��һ����ԭ�� Tensorflow �ܹ�,�������ڼ���ʽ������������ʵ�ֹ����߳�֮���Э����
- �ڶ����Ƿ�ɢʽ����,�����߳�ͨ�� MPI AllReduce ԭ��ֱ���ͨ��,��ʹ�ò�����������NVIDIA �� NCCL ���Ѿ���GPU ����Ч��ִ���˴� MPI ԭ��,�� Uber ��Horovod ��ʹ�� TensorFlow ִ�ж� GPU �Ͷ�ڵ�ѵ���������١���������������,�ڶ��ַ����������õ��Ż����������õ���չ��
1.5 Operator
Operator ��Kubernetes ֮�еĸ���,��Ҫ������������������û�������
Operator���Լ�����Ϊ CRD + Controller��
- CRD(Custom Resource Definition)�� Kubernetes ����չ����,����Ϊ�û��Զ�����Դ�ᡣ
- Controller �������û�����CRD��
����� Java ������,operator ���� Class,CRD ������ij�Ա����,Controller �������Ա������
1.6 TF-Operator
��ȻKubeFlow�ṩ��һ������,�����˻���ѧϰ�ķ�������,��ģ��ѵ���϶���KubeFlow����Ҫ�Ĺ��ܡ� KubeFlow��Ը��ָ����Ļ���ѧϰ����ṩ��ѵ������������ʽ�Ƕ����˸��ָ�����Operator,����Ҫ��������������ѧϰ�������ѧϰ���������,������ι���ά��һ������Ķ���ڵ�,��ι���Pod���������������,��ν����ݴ��ȵȡ�
TF-Operator���ǿ�Դ��������K8S�ṩ����չAPI,�ṩ��TensorFlow��ѵ������,������Ҳ�ܿ�����,���ʵ��������Job��һ�ַ�ʽ,���ص�����:
- �ṩTensorFlowԭ��PS-worker�ܹ� �Ķ��ѵ��
- �Ƽ���PS��workerһ������
- ͨ��service��������
- �������������ڵ�Operator
��Ϊ TF-Operator �������������ڵ�Operator,���������б�Ҫ�ȿ�����
0x02 TensorFlow �ֲ�ʽ
��Ϊ TF-Operator ��Ϊ��֧�� Tensorflow PS ģʽ,�����������Ƚ���һ�� TensorFlow �ֲ�ʽ��
2.1 Parameter server�ܹ�
��Parameter server�ܹ�(PS�ܹ�)��,��Ⱥ�еĽڵ㱻��Ϊ����:����������(parameter server)����������(worker)�����в������������ģ�͵IJ���,�������������������������ݶȡ���ÿ����������,�����������Ӳ����������л�ò���,Ȼ������ݶȷ��ظ�����������,�����������ۺϴӹ������������ص��ݶ�,Ȼ����²���,�����µIJ����㲥��������������
PS-Worker �ܹ����ݶȸ������� ͬ������ �� �첽���� ���ַ�ʽ:
��ͬ��ѵ����, ���е�Worker�豸����ͬһ��Batch�IJ�ͬС��(mini-batch)������ѵ��,�ȴ������豸�����ε��ݶȼ�����ɺ�,ģ�ͲŻ�������е��ݶȽ���һ�β�������,Ȼ��PS�����º��ģ���·��������豸��
�첽ѵ����,û���豸��Ҫȥ�ȴ������豸���ݶȼ���Ͳ�������,�����豸�����㲢�뽫�ݶȽ�����µ����Ľڵ�(PS)���첽ѵ�������ѵ���ٶȻ��ܶ�,�����첽ѵ����һ�������ص��������ݶ�ʧЧ����(stale gradients),�տ�ʼ�����豸������ͬ�IJ�����ѵ��,�����첽�����,ij���豸���һ��ѵ����,���ܷ���ģ�Ͳ����Ѿ��������豸���¹���,��ʱ����豸��������ݶȾ����ˡ�
2.2 Tensorflow PS-Worker
2.2.1 �ܹ�
����ֻ�Ǵ��½���һ��,��Ҫ��Ϊ�˺� TF-Operator �Աȡ�
TF ��Job��Ҫ����ΪParameter Server��Worker(��Ϊ TF �汾��ͬ,�����в�ͬ�ε��ر���,���� master ���� chief)��
- Parameter Job:ִ��ģ����ص���ҵ,����ģ�Ͳ����洢,�ַ�,����,����;��Ϊ�ֲ�ʽѵ���ķ����,�ȵ������ն�(supervisors)�����ӡ�
- Worker Job: ��TensorFlow�Ĵ���ע���б���Ϊsupervisors,ִ��ѵ����ص���ҵ,��������������ݶȼ��㡣�������������̫��,һ̨������������,���Ҫ��Ҫ���Tasks(��̬������,�����ϵ�һ������,�Ӿ�̬�ĽǶ�����,
Task��������д�Ĵ���)�� - Chief supervisors:���ڶ������ն��б���ѡ��һ����Ϊ��Ҫ�������նˡ����ն����������ն�������������,���Ĺ����Ǻϲ������ն�������ѧϰ����,���䱣����д�롣
- Cluster �� Jobs �ļ���: Cluster(��Ⱥ) ���Ǽ�Ⱥϵͳ��
ÿ�������ɫ�����ʶ����Ψһ��,���ֲ��ڲ�ͬIP�Ļ�����(����ͬһ��������ͬ�˿ں�)��
��ʵ��������,������ɫ�����繹�����ִ��������ȫ��ͬ,Ps-worker �ܹ��ֲ�ʽģ�͵����̴�������:
-
pull : ����worker����������ͼ�����˽ṹ,��PS��ȡ���µ�ģ�Ͳ���
-
feed: ��worker��䲻ͬ��������
-
compute: ��worker������ͬ��ģ�Ͳ����Ͳ�ͬ�������ݼ����ݶ�,�ó���ͬ���ݶ�ֵ
-
push ��worker ������õ����ݶ�ֵ�ϴ���PS
-
update: PS �ռ�����worker���ݶ�ֵ,��ƽ��ֵ,����ģ�Ͳ�����
2.2.2 ����
����������:
Task��Ҫ֪����Ⱥ�϶�����Щ����,�Լ����Ƕ�����ʲô�˿ڡ�tf.train.ClusterSpec()�����������������- ���
Cluster(��Ⱥ)������Job(worker.ps),worker��������Task(��,������Taskִ��Tensorflow op����) - ��
ClusterSpec�����������뵽tf.train.Server()��,ͬʱָ����Task��Job_name��task_index�� - ��������ͬ�Ĵ��������ڲ�ͬ��������,����Ҫ����
job_name��task_index��������,��ps_hosts��worker_hosts��������������˵,����һ����,����������Ⱥ�ġ� - һ��tf.train.Server�����˱����豸(GPUs,CPUs)�ļ���,�������ӵ�������task��ip:port(�洢��cluster��), ����һ��session target����ִ�зֲ���������������Ҫ��һ�����,��������һ��������,����port�˿�,��������ݴ�����,���ͻ��ڱ���ִ��(����session target,���ñ����豸ִ������),Ȼ�������ظ������ߡ�
- Ϊ��ʹps_server�ܹ�һֱ���ڼ���״̬,������Ҫʹ��server.join()����ʱ,���̾ͻ�block������.����Ϊʲôps_server�մ�����join��,ԭ������Ϊ����Ĵ���Ὣ����ָ����ps_server����,����ps_server�����ļ����ͺ��ˡ�
# To build a cluster with two ps jobs on hosts ps0 and ps1, and 3 worker
# jobs on hosts worker0, worker1 and worker2.
cluster_spec = {
"ps": ["ps0:2222", "ps1:2222"],
"worker": ["worker0:2222", "worker1:2222", "worker2:2222"]}
# Create a cluster from the parameter server and worker hosts.
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# Create and start a server for the local task.
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
server.join()
��������Ĵ�������:
def main(_):
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
# Create a cluster from the parameter server and worker hosts.
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# Create and start a server for the local task.
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
# �ҳ�worker�����ڵ�,��task_indexΪ0�Ľڵ�
is_chief = (FLAGS.task_index == 0)
# Assigns ops to the local worker by default.
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
# Compute
��������,���Կ���,����ֻ��Ҫдһ������,�ڲ�ͬ��������,���벻ͬ�IJ���ʹ������:
# On ps0.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=ps --task_index=0
# On ps1.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=ps --task_index=1
# On worker0.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=worker --task_index=0
# On worker1.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=worker --task_index=1
0x03 TF-Operator
3.1 TF-Operator ���˼·
�˽��� TF �ֲ�ʽ�Ĵ�������,���������� TF-Operator ���˼·��
�����Ǵ� ��Design Doc TFJob K8s CRD�� �з���ġ�
Ŀ����ʹ��Kubernetes(K8s)������TensorFlowѵ��(�����Ƿֲ�ʽѵ��)������ס��ҽ���ͨ������һ��K8s�Զ�����Դ������(CRD)�����Ŀ�������ʵ����һ�㡣CRD�������������ѵ��ҵ�����K8s��Դ��
Kubernetesͨ���ṩһ������(��������VMΪ����)��������ͼ,ʹ�ù������̱�ø������ס�Kubernetes��Ϊ���ӵķֲ�ʽӦ�ó����ṩ�˻����Ĺ����顣����,K8s�ṩ��DNS��������顢��־�ռ��������ռ����洢�ȵ�����֧�֡�
��K8s��,����������ȷ��һ��Pods������״̬��Pod��K8s�еĻ���������,��������һ������Ӧ�ý��й���λ�Ľ���(��ͬ��ip)��K8s�䱸���������ÿ�����������ȷ��N��pod���ض��Ĺ淶���С���ҵ�����������������ж������ļ���
���ÿ��������������зֲ�ʽTensorFlow��ҵ��TensorFlow��һ����״̬��Ӧ�ó���;ÿ�����������������߶���Ҫ����Ψһ�Ŀ�Ѱַ��,��֧�����в�ͬ�ķֲ�ʽ��ѵģʽ��K8s��һ��statefulset�� ����,��״̬�������������е���״̬����(��Redis֮����ڴ��Ƭ�������),�������������е���ɵ���ҵ��
���,������K8s�����зֲ�ʽTF��ҵ��ζ�Ŵ�����ԭ����ƴ�ճ�һ�����������ͨ��,����ζ���ֶ����������Դ������,�û�����Ϊ��������������һ����״̬��,Ϊ�����ߴ���һ����״̬��,Ϊ������������һ����ҵ��
Ϊ�˽��������Դ������,K8s֧���Զ�����Դ(CRD)�Ϳ�������ʹ��CRD,���Ժ�����Ϊ�ض��������ش���������������Ŀ�����,ͬʱ���û�������ʵ���С�K8s�����ܿ�Ͳ���������ģʽ,�����˴�����CRD���ڸ��ֹ������ء�
����crd���ֿ�������K8s�Ŷӵ������,�����������ʹ�÷Ƿֲ�ʽ�����߳����,�������Բ������⡣
TFJob CRDΪK8s������TFJob��Դ��
TFJob��Դ�� TfReplicas �ļ��ϡ�ÿ��TfReplica��Ӧһ���ڹ����а��ݽ�ɫ��һ�� TensorFlow processes;
��������һ����ȷ�ľ���,����ͼ���ػ��滻K8s��������,ÿ��TfReplica������һ������K8s PodTemplate ��ָ��Ҫ��ÿ�����Ƹ��������еĽ���(����TF)��������������ΪK8s�Ѿ��ṩ��һ�����㷺���ú������API�����,�����µĸ���������K8s�ĸ�������������ġ�����,����PodTemplate ʹTFJob�û��������ɵ�����K8s���ԡ�����,TFJob�û�����ʹ��K8s�������ӵ���TF���̡���ʹ��TF��K8s֧�ֵ��κδ洢ϵͳ(��PDs��NFS��)���ʹ�ñ�÷dz����ס�
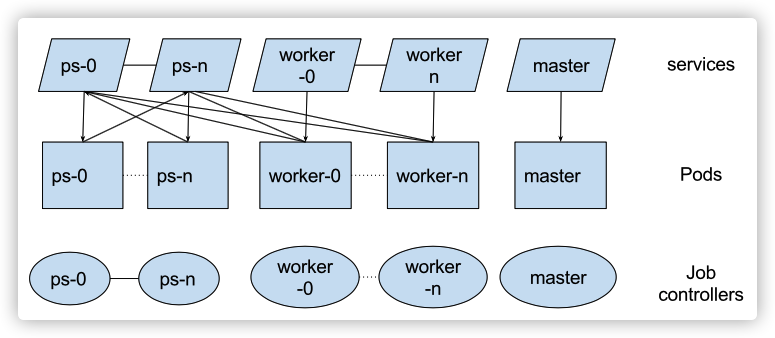
3.2 �ܹ�ͼ
����ܹ�ͼ����:
3.2.1 ʲô��Pod
���Ǵ�ͼ������,�ȿ��м�� pod ���
pod �� k8s���ȵ���С��Ԫ��pod ��������Ϊ:������,ͬʱpod�൱��������,����pod��·����һ��linux����,�������(linuxϵͳ��),�á������������кܶ�����,������ַ·����ֽ���һ��linux������Ĭ�������,ÿ���������ļ�ϵͳ������������ȫ���롣ÿ��pod�����Լ���ip��ַ��pod�ڵ�����������ͬ��ip�Ͷ˿ڿռ䡣
3.2.2 ΪʲôҪ�� service
����,ÿ��Pod���ᱻ����һ��������IP��ַ,����ÿ��Pod���ṩ��һ��������Endpoint(Pod IP + ContainerPort)�Ա��ͻ��˷���,�����ַ��ʽ����ڼ�Ⱥ�ڲ�,�ⲿû�����ʼ�Ⱥ�ڲ���IP��ַ,
���,Pod������������,���Pod����IP���п��ܻᷢ���仯���� controller ���� Pod ����������ϵ� Pod ʱ,�� Pod ����䵽�µ� IP ��ַ�������Ͳ�����һ������:���һ�� Pod �����ṩ����(���� HTTP),���ǵ� IP ���п��ܷ����仯,��ô�ͻ�������ҵ����������������?
Kubernetes �����Ľ�������� Service��
Serviceֻ��һ���������,Kubernetes Service �����ϴ�����һ�� Pod,��������Щ Pod ������ label ����ѡ��Service �����Ͻ�һ��pod(������ͬ)���������һ��ͳһ��ڡ����Խ���������Ϊ����һ������ĸ��ؾ��⡣
Service ���Լ� IP,������� IP �Dz���ġ��ͻ���ֻ��Ҫ���� Service �� IP,Kubernetes ��������ά�� Service �� Pod ��ӳ���ϵ�����ۺ�� Pod ��α仯,�Կͻ��˲������κ�Ӱ��,��Ϊ Service û�б䡣����һ���ͨ��service������pod��core-dns���service����һ���ڲ�������ip,����ڲ��������ͨ�����ip������serviceName�����ʵ�pod�ķ���
���Ǹ���һ��Դ���е�service ���ӡ�
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/path: /metrics
prometheus.io/scrape: "true"
prometheus.io/port: "8443"
labels:
app: tf-job-operator
name: tf-job-operator
spec:
ports:
- name: monitoring-port
port: 8443
targetPort: 8443
selector:
name: tf-job-operator
type: ClusterIP
�������ǿ����Ѿ���������Ϊtf-job-operator��Service,�����һ��Cluster IP,��Service��������ļ���selector����� Pod,�����ЩPod��Ϣ���µ�һ����Ϊ tf-job-operator ��Endpoints������ȥ,����������������������˵��Pod�����ˡ�
3.2.3 ʲô�� controller
��Ϊ Kubernetes ���е���Դ�������������ǵ�����,�����Ҫͨ�� Custom Resource Definition �Ļ��ƽ�����չ��
K8S��һ�ж���resource,����Deployment,Service�ȵȡ�
���ǿ��Ի���CRD(CustomResourceDefinitions)��������resource,���������Զ���һ��Deployment��Դ,�ṩ��ͬ�IJ�����ԡ�
����֪��resource����ͨ��k8s��RESTFUL API����CURD����,����CRD������resourceҲ��һ���ġ�
CRD�����Ƕ���һ��resource,���ǻ���Ҫʵ��controller,������deployment controller�ȵ�,������Ӧ��Դ��CURD�¼�,������Ӧ�Ĵ���,���粿��POD��
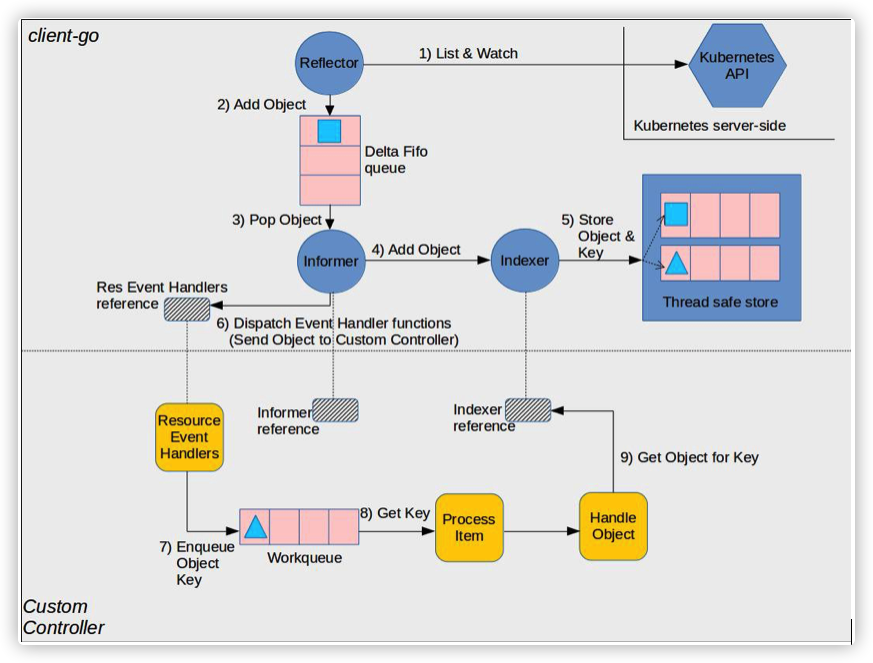
��ʵ,TF-Operator ��Ҫ����һ�� Controller ��ʵ��,��������Ҳ��Ҫ���ǽ������ controller��
3.3 Spec
�������ȸ���һ�� Job Spec,������ҿ����ں����ʹ����ж�Ӧ����������,ӵ��һ�� master,2�� workers,һ�� PS��
apiVersion: "kubeflow.org/v1alpha1" # ָ��api�汾,��ֵ������kubectl api-versions��
kind: "TFJob" # ָ��������Դ�Ľ�ɫ/����
metadata: # ��Դ��Ԫ����/����
name: "example-job"
spec: # ��Դ�淶�ֶ�
replicaSpecs: # ����������Ŀ
- replicas: 1
tfReplicaType: MASTER
template: # ģ��
spec:
containers:
- image: gcr.io/tf-on-k8s-dogfood/tf_sample:dc944ff # ����ʹ�õľ����ַ
name: tensorflow
args:
- --log_dir=gs://my-job/log-dir
restartPolicy: OnFailure
- replicas: 2
tfReplicaType: WORKER
template:
spec:
containers:
- image: gcr.io/tf-on-k8s-dogfood/tf_sample:dc944ff
name: tensorflow
args:
- --log_dir=gs://my-job/log-dir
restartPolicy: OnFailure
- replicas: 1
tfReplicaType: PS
�������ǿ�ʼ����������硣
3.4 TFJob
�������ǿ��� TFJob �Ķ���,���¿��Ժ������ Spec ���ҵ���Ӧ��ϵ,��Ϊ����Ŀ�����˽������,�������Ǿ�ֻ������Щ���ɡ�
// TFJob represents a TFJob resource.
type TFJob struct {
// Standard Kubernetes type metadata.
metav1.TypeMeta `json:",inline"`
// Standard Kubernetes object's metadata.
// +optional
metav1.ObjectMeta `json:"metadata,omitempty"`
// Specification of the desired state of the TFJob.
// +optional
Spec TFJobSpec `json:"spec,omitempty"`
// Most recently observed status of the TFJob.
// Populated by the system.
// Read-only.
// +optional
Status commonv1.JobStatus `json:"status,omitempty"`
}
// TFJobSpec is a desired state description of the TFJob.
type TFJobSpec struct {
// RunPolicy encapsulates various runtime policies of the distributed training
// job, for example how to clean up resources and how long the job can stay
// active.
RunPolicy commonv1.RunPolicy `json:"runPolicy,inline"`
// SuccessPolicy defines the policy to mark the TFJob as succeeded.
// Default to "", using the default rules.
// +optional
SuccessPolicy *SuccessPolicy `json:"successPolicy,omitempty"`
// A map of TFReplicaType (type) to ReplicaSpec (value). Specifies the TF cluster configuration.
// For example,
// {
// "PS": ReplicaSpec,
// "Worker": ReplicaSpec,
// }
TFReplicaSpecs map[commonv1.ReplicaType]*commonv1.ReplicaSpec `json:"tfReplicaSpecs"`
// // A switch to enable dynamic worker
EnableDynamicWorker bool `json:"enableDynamicWorker,omitempty"`
}
3.5 ��ɫ
������ǿ��� TF-Operator ֮��,�� TF ��ɫ�Ķ�Ӧʵ�֡�
3.5.1 ����
�����ǽ�ɫ���塣����Ľ�ɫ������Ӧ�� Tensorflow �ĸ�����ɫ,�����ܶ�Ϊ�˼��ݶ������Ľ�ɫ��
// setTypeNamesToCamelCase sets the name of all replica types from any case to correct case.
func setTypeNamesToCamelCase(tfJob *TFJob) {
setTypeNameToCamelCase(tfJob, TFReplicaTypePS)
setTypeNameToCamelCase(tfJob, TFReplicaTypeWorker)
setTypeNameToCamelCase(tfJob, TFReplicaTypeChief)
setTypeNameToCamelCase(tfJob, TFReplicaTypeMaster)
setTypeNameToCamelCase(tfJob, TFReplicaTypeEval)
}
const (
// TFReplicaTypePS is the type for parameter servers of distributed TensorFlow.
TFReplicaTypePS commonv1.ReplicaType = "PS"
// TFReplicaTypeWorker is the type for workers of distributed TensorFlow.
// This is also used for non-distributed TensorFlow.
TFReplicaTypeWorker commonv1.ReplicaType = "Worker"
// TFReplicaTypeChief is the type for chief worker of distributed TensorFlow.
// If there is "chief" replica type, it's the "chief worker".
// Else, worker:0 is the chief worker.
TFReplicaTypeChief commonv1.ReplicaType = "Chief"
// TFReplicaTypeMaster is the type for master worker of distributed TensorFlow.
// This is similar to chief, and kept just for backwards compatibility.
TFReplicaTypeMaster commonv1.ReplicaType = "Master"
// TFReplicaTypeEval is the type for evaluation replica in TensorFlow.
TFReplicaTypeEval commonv1.ReplicaType = "Evaluator"
)
3.5.2 ������ɫ
NewTFJobV2 ���������������õIJ�ͬ,��������ͬ�Ľ�ɫ��
������Կ���,���� job ʱ��,�������ǰ��� spec �Ķ�Ӧ�ֶ���������
apiVersion: "kubeflow.org/v1alpha1"
kind: "TFJob"
metadata:
name: "example-job"
spec:
replicaSpecs:
�����Ǻ������塣
func NewTFJobV2(worker, ps, master, cheif, evaluator int) *tfv1.TFJob {
tfJob := &tfv1.TFJob{
TypeMeta: metav1.TypeMeta{
Kind: tfv1.Kind,
},
ObjectMeta: metav1.ObjectMeta{
Name: TestTFJobName,
Namespace: metav1.NamespaceDefault,
},
Spec: tfv1.TFJobSpec{
TFReplicaSpecs: make(map[commonv1.ReplicaType]*commonv1.ReplicaSpec),
},
}
tfv1.SetObjectDefaults_TFJob(tfJob)
if worker > 0 {
worker := int32(worker)
workerReplicaSpec := &commonv1.ReplicaSpec{
Replicas: &worker,
Template: NewTFReplicaSpecTemplate(),
}
tfJob.Spec.TFReplicaSpecs[tfv1.TFReplicaTypeWorker] = workerReplicaSpec
}
if ps > 0 {
ps := int32(ps)
psReplicaSpec := &commonv1.ReplicaSpec{
Replicas: &ps,
Template: NewTFReplicaSpecTemplate(),
}
tfJob.Spec.TFReplicaSpecs[tfv1.TFReplicaTypePS] = psReplicaSpec
}
if master > 0 {
master := int32(master)
masterReplicaSpec := &commonv1.ReplicaSpec{
Replicas: &master,
Template: NewTFReplicaSpecTemplate(),
}
tfJob.Spec.TFReplicaSpecs[tfv1.TFReplicaTypeMaster] = masterReplicaSpec
}
if cheif > 0 {
cheif := int32(cheif)
cheifReplicaSpec := &commonv1.ReplicaSpec{
Replicas: &cheif,
Template: NewTFReplicaSpecTemplate(),
}
tfJob.Spec.TFReplicaSpecs[tfv1.TFReplicaTypeChief] = cheifReplicaSpec
}
if evaluator > 0 {
evaluator := int32(evaluator)
evaluatorReplicaSpec := &commonv1.ReplicaSpec{
Replicas: &evaluator,
Template: NewTFReplicaSpecTemplate(),
}
tfJob.Spec.TFReplicaSpecs[tfv1.TFReplicaTypeChief] = evaluatorReplicaSpec
}
return tfJob
}
3.5.3 ������� master
�����·������� master��
func (tc *TFController) IsMasterRole(replicas map[commonv1.ReplicaType]*commonv1.ReplicaSpec, rtype commonv1.ReplicaType, index int) bool {
if ContainChieforMasterSpec(replicas) {
return rtype == tfv1.TFReplicaTypeChief || rtype == tfv1.TFReplicaTypeMaster
}
// else check if it is worker with index 0
return rtype == tfv1.TFReplicaTypeWorker && index == 0
}
0x04 Contoller
����ͽ�������,���� Controller ���ʵ�֡�
4.1 K8S CRD�ؼ�����
����������Ҫ���� K8S CRD ��һЩ�ؼ����
-
informer:����apiserver���ض���Դ�仯,Ȼ���洢��һ���̰߳�ȫ��local cache��,���ص������Լ�ʵ�ֵ�event handler��
-
local cache:informerʵʱͬ��apiserver(Ҳ����etcd)�е����ݵ��ڴ��д洢,������Ч����apiserver�IJ�ѯѹ��,��ȱ�����ʵʱ�Բ���,���ػ��Զ�̵��������һ��㵫��������etcdһ��,������Ҫ������������������Local cache����apiserverʵʱ��ȡ���ݡ�
-
Lister:�ṩ��CURD��������local cache��
-
controller:һ��������,����ָ����ij����Դ��ʵ�ֶ���,��Ҫ�����Լ�������Controller����������Ҫ����:
-
- ʵ��event handler������Դ��CURD����
- ��event handler,����ʹ��workqueue���ʵ����ͬ��Դ���������event��ȥ��,�Լ�event�����쳣���ʧ������,ͨ���ǽ���ʹ�õġ�
-
Workqueue:һ�����������,�ǿ�ѡʹ�õ�,��ͨ������ʹ��,ԭ������˵�ˡ�������Ҫ��ʵ��event handler��ʱ��ѷ����仯����Դ��ʶ����workqueue,�������processor���ѡ�
-
Clientset:Ĭ��clientsetֻ��CRUD k8s�ṩ����Դ����,����deployments,daemonset��;���ɵĴ���Ϊ�����Զ������Դ(CRD)�����˵�����clientset,�Ӷ�������ʹ�ýṹ���Ĵ���CURD�Զ�����Դ��Ҳ����˵,������ڽ���Դ����k8s�Դ���clientset,�����CRD�������ɴ������clientset��
-
Processor:����ʵ�ֵ�goЭ��,����workqueue�е��¼�,workqueue�ṩ�˰���Դ��ʶ��ȥ�ء�
4.2 ����
TFController �Ķ�������,���Կ�����������Ա������������,�ͷֱ��õ��������IJ��������
// TFController is the type for TFJob Controller, which manages
// the lifecycle of TFJobs.
type TFController struct {
common.JobController
// tfJobClientSet is a clientset for CRD TFJob.
tfJobClientSet tfjobclientset.Interface
// To allow injection of sync functions for testing.
syncHandler func(string) (bool, error)
// tfJobInformer is a temporary field for unstructured informer support.
tfJobInformer cache.SharedIndexInformer
// Listers for TFJob, Pod and Service
// tfJobLister can list/get tfjobs from the shared informer's store.
tfJobLister tfjoblisters.TFJobLister
// tfJobInformerSynced returns true if the tfjob store has been synced at least once.
tfJobInformerSynced cache.InformerSynced
}
4.3 ���
TF-Operator ������������ runWorker,��ʵ����ѭ������ processNextWorkItem��
func (tc *TFController) runWorker() {
for tc.processNextWorkItem() {
}
}
processNextWorkItem����WorkQueue�ж�ȡ����������,������ͨ������syncHandler����������
// processNextWorkItem will read a single work item off the workqueue and
// attempt to process it, by calling the syncHandler.
func (tc *TFController) processNextWorkItem() bool {
obj, quit := tc.WorkQueue.Get()
if key, ok = obj.(string); !ok {
tc.WorkQueue.Forget(obj)
return true
}
tfJob, err := tc.getTFJobFromKey(key)
// ͬ��TFJob�Խ�ʵ��״̬ƥ�䵽�����״̬��
// Sync TFJob to match the actual state to this desired state.
forget, err := tc.syncHandler(key)
}
4.4 syncHandler
syncHandler ������������ key ��ͬ�� Job,���Ǵ� WorkQueue ֮��Ū����һ�� job,���ش�����
֮ǰ������ tc.syncHandler = tc.syncTFJob,��������ʵ�������� syncTFJob��
- ���
tfjob������ֵ�Ѿ�ʵ��,��ôsyncTFJob�ͻ��ø�����key��ͬ��tfjob,����ζ������ϣ�������
pod/service��������ɾ��: - EnableDynamicWorker �������ݲ�ͬ�������á�
- Ȼ������ ReconcileJobs �Ծ��� job ���д�����
// syncTFJob syncs the tfjob with the given key if it has had its expectations fulfilled, meaning
// it did not expect to see any more of its pods/services created or deleted.
// This function is not meant to be invoked concurrently with the same key.
// �������������ͬһ��keyͬʱ����
func (tc *TFController) syncTFJob(key string) (bool, error) {
namespace, name, err := cache.SplitMetaNamespaceKey(key)
sharedTFJob, err := tc.getTFJobFromName(namespace, name)
tfjob := sharedTFJob.DeepCopy()
// Sync tfjob every time if EnableDynamicWorker is true
tfjobNeedsSync := tfjob.Spec.EnableDynamicWorker || tc.satisfiedExpectations(tfjob)
// Ϊ��tfjob����Ĭ��ֵ��
// Set default for the new tfjob.
scheme.Scheme.Default(tfjob)
if tfjobNeedsSync && tfjob.DeletionTimestamp == nil {
// ����reconcileTFJobs������TFJobs
reconcileTFJobsErr = tc.ReconcileJobs(tfjob, tfjob.Spec.TFReplicaSpecs, tfjob.Status, &tfjob.Spec.RunPolicy)
}
return true, err
}
4.5 ReconcileJobs
reconcileTFJobs��鲢����ÿ������TFReplicaSpec��replicas,��������Ӧ����,������Ϊ��������������
- ��� job ����,������Ӧ����,delete����pod��service��
- ���TFJob������backofflimit����active deadline,ɾ������pod��service,Ȼ��״̬����Ϊfailed��
- ���� ���������ļ���TFReplicaSpecs����,
- �ֱ�Ϊ��ͬ���͵Ľڵ�������Ӧ��Pod��
- ������Pod֮��,��ҪΪ������һ��Service��
// ����ڴ���/ɾ�� pods/servicesʱ��������,��������tfjob��
// ReconcileJobs checks and updates replicas for each given ReplicaSpec.
// It will requeue the job in case of an error while creating/deleting pods/services.
func (jc *JobController) ReconcileJobs(
job interface{},
replicas map[apiv1.ReplicaType]*apiv1.ReplicaSpec,
jobStatus apiv1.JobStatus,
runPolicy *apiv1.RunPolicy) error {
metaObject, ok := job.(metav1.Object)
jobName := metaObject.GetName()
runtimeObject, ok := job.(runtime.Object)
jobKey, err := KeyFunc(job)
pods, err := jc.Controller.GetPodsForJob(job)
services, err := jc.Controller.GetServicesForJob(job)
oldStatus := jobStatus.DeepCopy()
// ���TFJob terminated,��delete����pod��service��
if commonutil.IsSucceeded(jobStatus) || commonutil.IsFailed(jobStatus) {
// If the Job is succeed or failed, delete all pods and services.
jc.DeletePodsAndServices(runPolicy, job, pods)
jc.CleanupJob(runPolicy, jobStatus, job)
return nil
}
// ������ǰ�����Դ���
// retrieve the previous number of retry
previousRetry := jc.WorkQueue.NumRequeues(jobKey)
activePods := k8sutil.FilterActivePods(pods)
jc.recordAbnormalPods(activePods, runtimeObject)
active := int32(len(activePods))
failed := k8sutil.FilterPodCount(pods, v1.PodFailed)
totalReplicas := k8sutil.GetTotalReplicas(replicas)
prevReplicasFailedNum := k8sutil.GetTotalFailedReplicas(jobStatus.ReplicaStatuses)
if jobExceedsLimit {
// If the Job exceeds backoff limit or is past active deadline
// delete all pods and services, then set the status to failed
jc.DeletePodsAndServices(runPolicy, job, pods); err != nil {
jc.CleanupJob(runPolicy, jobStatus, job); err != nil {
jc.Recorder.Event(runtimeObject, v1.EventTypeNormal, commonutil.JobFailedReason, failureMessage)
commonutil.UpdateJobConditions(&jobStatus, apiv1.JobFailed, commonutil.JobFailedReason, failureMessage)
return jc.Controller.UpdateJobStatusInApiServer(job, &jobStatus)
} else {
// General cases which need to reconcile
if jc.Config.EnableGangScheduling {
minAvailableReplicas := totalReplicas
_, err := jc.SyncPodGroup(metaObject, minAvailableReplicas)
}
// ���������ļ���TFReplicaSpecs����,�ֱ�Ϊ��ͬ���͵Ľڵ�������Ӧ��Pod��
// ������Pod֮��,��ҪΪ������һ��Service��
// Diff current active pods/services with replicas.
for rtype, spec := range replicas {
err := jc.Controller.ReconcilePods(metaObject, &jobStatus, pods, rtype, spec, replicas)
err = jc.Controller.ReconcileServices(metaObject, services, rtype, spec)
}
}
err = jc.Controller.UpdateJobStatus(job, replicas, &jobStatus)
// No need to update the job status if the status hasn't changed since last time.
if !reflect.DeepEqual(*oldStatus, jobStatus) {
return jc.Controller.UpdateJobStatusInApiServer(job, &jobStatus)
}
return nil
}
Ŀǰ������:
+------------+
| runWorker |
+-----+------+
|
|
v
+--------+------------+
| processNextWorkItem |
+--------+------------+
|
|
v
+----+------+
| syncTFJob |
+----+------+
|
|
v
+-------+--------+
| ReconcileJobs |
+-------+--------+
|
|
v
+--------+---------+
| |
| |
v v
+---------+---------+ +-----+--------+
| | | |
| ReconcileServices | |ReconcilePods |
| | | |
+-------------------+ +--------------+
�������Ƿֱ���ܴ��� Pod �� ���� Service��
4.6 ���� Pod
4.6.1 ReconcilePods
reconcilePodsΪÿ��������TFReplicaSpec������pod��
�������:
- ��ʼ�� replica ��״̬;
- ���master pod����,ѡ��master pod,���û��master,��һ��worker pod��ѡΪmaster;
- createNewPod �������µ� pod;
- ����ɾ�� pod;
// reconcilePods checks and updates pods for each given TFReplicaSpec.
// It will requeue the tfjob in case of an error while creating/deleting pods.
func (tc *TFController) ReconcilePods(
job interface{},
jobStatus *commonv1.JobStatus,
pods []*v1.Pod,
rtype commonv1.ReplicaType,
spec *commonv1.ReplicaSpec,
replicas map[commonv1.ReplicaType]*commonv1.ReplicaSpec,
) error {
tfJob, ok := job.(*tfv1.TFJob)
// Convert ReplicaType to lower string.
rt := strings.ToLower(string(rtype))
// ��ȡrtype���͵�����pod��
pods, err := tc.FilterPodsForReplicaType(pods, rt)
numReplicas := int(*spec.Replicas)
masterRole := false
initializeReplicaStatuses(jobStatus, rtype)
// GetPodSlices will return enough information here to make decision to add/remove/update resources.
// For example, let's assume we have pods with replica-index 0, 1, 2
// If replica is 4, return a slice with size 4. [[0],[1],[2],[]], a pod with replica-index 3 will be created.
// If replica is 1, return a slice with size 3. [[0],[1],[2]], pod with replica-index 1 and 2 are out of range and will be deleted.
podSlices := tc.GetPodSlices(pods, numReplicas, logger)
for index, podSlice := range podSlices {
if len(podSlice) > 1 {
logger.Warningf("We have too many pods for %s %d", rt, index)
} else if len(podSlice) == 0 {
// ���master pod����,ѡ��master pod
// ���û��master,��һ��worker pod��ѡΪmaster��
// check if this replica is the master role
masterRole = tc.IsMasterRole(replicas, rtype, index)
// TODO: [should change to CreateNewPod]
err = tc.createNewPod(tfJob, rt, strconv.Itoa(index), spec, masterRole, replicas)
} else {
// Check the status of the current pod.
pod := podSlice[0]
// Ŀǰֻ��������workers
// check if the index is in the valid range, if not, we should kill the pod
if index < 0 || index >= numReplicas {
err = tc.PodControl.DeletePod(pod.Namespace, pod.Name, tfJob)
}
// Check if the pod is retryable.
if spec.RestartPolicy == commonv1.RestartPolicyExitCode {
if pod.Status.Phase == v1.PodFailed && train_util.IsRetryableExitCode(exitCode) {
tc.Recorder.Event(tfJob, corev1.EventTypeWarning, tfJobRestartingReason, msg)
err := commonutil.UpdateJobConditions(jobStatus, commonv1.JobRestarting, tfJobRestartingReason, msg)
tfJobsRestartCount.Inc()
}
}
updateJobReplicaStatuses(jobStatus, rtype, pod)
}
}
return nil
}
4.6.2 createNewPod
createNewPodΪ������index��type����һ���µ�pod:
// createNewPod creates a new pod for the given index and type.
func (tc *TFController) createNewPod(tfjob *tfv1.TFJob, rt, index string, spec *commonv1.ReplicaSpec, masterRole bool,
replicas map[commonv1.ReplicaType]*commonv1.ReplicaSpec) error {
tfjobKey, err := KeyFunc(tfjob)
expectationPodsKey := expectation.GenExpectationPodsKey(tfjobKey, rt)
// Create OwnerReference.
controllerRef := tc.GenOwnerReference(tfjob)
// Set type and index for the worker.
labels := tc.GenLabels(tfjob.Name)
labels[tfReplicaTypeLabel] = rt
labels[tfReplicaIndexLabel] = index
podTemplate := spec.Template.DeepCopy()
// Set name for the template.
podTemplate.Name = common.GenGeneralName(tfjob.Name, rt, index)
if podTemplate.Labels == nil {
podTemplate.Labels = make(map[string]string)
}
for key, value := range labels {
podTemplate.Labels[key] = value
}
// ���ɼ�Ⱥ��������Ϣ,������ؼ�,��һ��ʵ��
if err := tc.SetClusterSpec(tfjob, podTemplate, rt, index); err != nil {
return err
}
// if gang-scheduling is enabled:
// 1. if user has specified other scheduler, we report a warning without overriding any fields.
// 2. if no SchedulerName is set for pods, then we set the SchedulerName to "kube-batch".
if tc.Config.EnableGangScheduling {
if isNonGangSchedulerSet(replicas) {
tc.Recorder.Event(tfjob, v1.EventTypeWarning, podTemplateSchedulerNameReason, errMsg)
} else {
podTemplate.Spec.SchedulerName = gangSchedulerName
}
if podTemplate.Annotations == nil {
podTemplate.Annotations = map[string]string{}
}
podTemplate.Annotations[gangSchedulingPodGroupAnnotation] = tfjob.GetName()
podTemplate.Annotations[volcanoTaskSpecKey] = rt
}
// ʹ�������������Ϣ,��������Pod�Ĵ���
err = tc.PodControl.CreatePodsWithControllerRef(tfjob.Namespace, podTemplate, tfjob, controllerRef)
return nil
}
4.6.3 ����������Ϣ
4.6.3.1 SetClusterSpec
���溯���е�����������Ϣ�Ƚ���Ҫ,�������ǵ���ժ����˵һ�¡�
setClusterSpecΪ������podTemplateSpec���ɲ�����TF_CONFIG:
// SetClusterSpec generates and sets TF_CONFIG for the given podTemplateSpec.
func (tc *TFController) SetClusterSpec(job interface{}, podTemplate *v1.PodTemplateSpec, rtype, index string) error {
tfjob, ok := job.(*tfv1.TFJob)
// Generate TF_CONFIG JSON string.
tfConfigStr, err := genTFConfigJSONStr(tfjob, rtype, index)
// Add TF_CONFIG environment variable to tensorflow container in the pod.
for i := range podTemplate.Spec.Containers {
if podTemplate.Spec.Containers[i].Name == tfv1.DefaultContainerName {
if len(podTemplate.Spec.Containers[i].Env) == 0 {
podTemplate.Spec.Containers[i].Env = make([]v1.EnvVar, 0)
}
podTemplate.Spec.Containers[i].Env = append(podTemplate.Spec.Containers[i].Env, v1.EnvVar{
Name: tfConfig,
Value: tfConfigStr,
})
break
}
}
return nil
}
4.6.3.2 genTFConfigJSONStr
genTFConfigJSONStr ������ json ���ݡ�
// genTFConfig will generate the environment variable TF_CONFIG
// {
// "cluster": {
// "ps": ["ps1:2222", "ps2:2222"],
// "worker": ["worker1:2222", "worker2:2222", "worker3:2222"]
// },
// "task": {
// "type": "ps",
// "index": 1
// },
// }
// }
func genTFConfigJSONStr(tfjob *tfv1.TFJob, rtype, index string) (string, error) {
// Configure the TFCONFIG environment variable.
i, err := strconv.ParseInt(index, 0, 32)
if err != nil {
return "", err
}
cluster, err := genClusterSpec(tfjob)
if err != nil {
return "", err
}
var tfConfigJSONByteSlice []byte
if tfjob.Spec.EnableDynamicWorker {
sparseCluster := convertClusterSpecToSparseClusterSpec(cluster, strings.ToLower(rtype), int32(i))
sparseTFConfig := SparseTFConfig{
Cluster: sparseCluster,
Task: TaskSpec{
Type: strings.ToLower(rtype),
Index: int(i),
},
}
tfConfigJSONByteSlice, err = json.Marshal(sparseTFConfig)
} else {
tfConfig := TFConfig{
Cluster: cluster,
Task: TaskSpec{
Type: strings.ToLower(rtype),
Index: int(i),
},
// We need to set environment to cloud otherwise it will default to local which isn't what we want.
// Environment is used by tensorflow.contrib.learn.python.learn in versions <= 1.3
// TODO(jlewi): I don't think it is used in versions TF >- 1.4. So we can eventually get rid of it.
// ������Ҫ���û���Ϊcloud,��������Ĭ��Ϊlocal,�ⲻ��������Ҫ�ġ�
Environment: "cloud",
}
tfConfigJSONByteSlice, err = json.Marshal(tfConfig)
}
if err != nil {
return "", err
}
return string(tfConfigJSONByteSlice), nil
}
4.6.3.3 genClusterSpec
������ǴӼ�Ⱥ��Ϣ�л�� cluster ��Ϣ��
// genClusterSpec will generate ClusterSpec.
func genClusterSpec(tfjob *tfv1.TFJob) (ClusterSpec, error) {
clusterSpec := make(ClusterSpec)
for rtype, spec := range tfjob.Spec.TFReplicaSpecs {
rt := strings.ToLower(string(rtype))
replicaNames := make([]string, 0, *spec.Replicas)
port, err := GetPortFromTFJob(tfjob, rtype)
// ����ѭ��������TF_CONFIG�����Cluster��Ϣ��ע�⿴ע��,ʹ��DNS���Service,����Ļ��Ǹ����ڵ�IP���̶�������
for i := int32(0); i < *spec.Replicas; i++ {
// As described here: https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/#a-records.
// Headless service assigned a DNS A record for a name of the form "my-svc.my-namespace.svc.cluster.local".
// And the last part "svc.cluster.local" is called cluster domain
// which maybe different between kubernetes clusters.
// ��������:https://kubernetes.io/docs/concepts/services-networking/dns-pos-service/#a-records��
// Headless serviceΪ"my-svc.my-namespace.svc.cluster.local"�����Ʒ���һ��DNS��¼��
// ���һ������"svc.cluster.local"����Ϊcluster domain,�ڲ�ͬ��kubernetes��Ⱥ֮����ܴ��ڲ��졣
hostName := common.GenGeneralName(tfjob.Name, rt, fmt.Sprintf("%d", i))
svcName := hostName + "." + tfjob.Namespace + "." + "svc"
clusterDomain := os.Getenv(EnvCustomClusterDomain)
if len(clusterDomain) > 0 {
svcName += "." + clusterDomain
}
endpoint := fmt.Sprintf("%s:%d", svcName, port)
replicaNames = append(replicaNames, endpoint)
}
clusterSpec[rt] = replicaNames
}
return clusterSpec, nil
}
4.6.4 CreatePodsWithControllerRef
�õ��˼�Ⱥ������Ϣ֮��,��ʹ�ü�Ⱥ��������Ϣ,������������Pod�Ĵ���:
func (r RealPodControl) CreatePods(namespace string, template *v1.PodTemplateSpec, object runtime.Object) error {
return r.createPods("", namespace, template, object, nil)
}
func (r RealPodControl) CreatePodsWithControllerRef(namespace string, template *v1.PodTemplateSpec, controllerObject runtime.Object, controllerRef *metav1.OwnerReference) error {
if err := ValidateControllerRef(controllerRef); err != nil {
return err
}
return r.createPods("", namespace, template, controllerObject, controllerRef)
}
4.6.5 createPods
�������������K8S�ӿڴ���pod
func (r RealPodControl) createPods(nodeName, namespace string, template *v1.PodTemplateSpec, object runtime.Object, controllerRef *metav1.OwnerReference) error {
pod, err := GetPodFromTemplate(template, object, controllerRef)
if len(nodeName) != 0 {
pod.Spec.NodeName = nodeName
}
if labels.Set(pod.Labels).AsSelectorPreValidated().Empty() {
return fmt.Errorf("unable to create pods, no labels")
}
if newPod, err := r.KubeClient.CoreV1().Pods(namespace).Create(pod); err != nil {
return err
} else {
accessor, err := meta.Accessor(object)
}
return nil
}
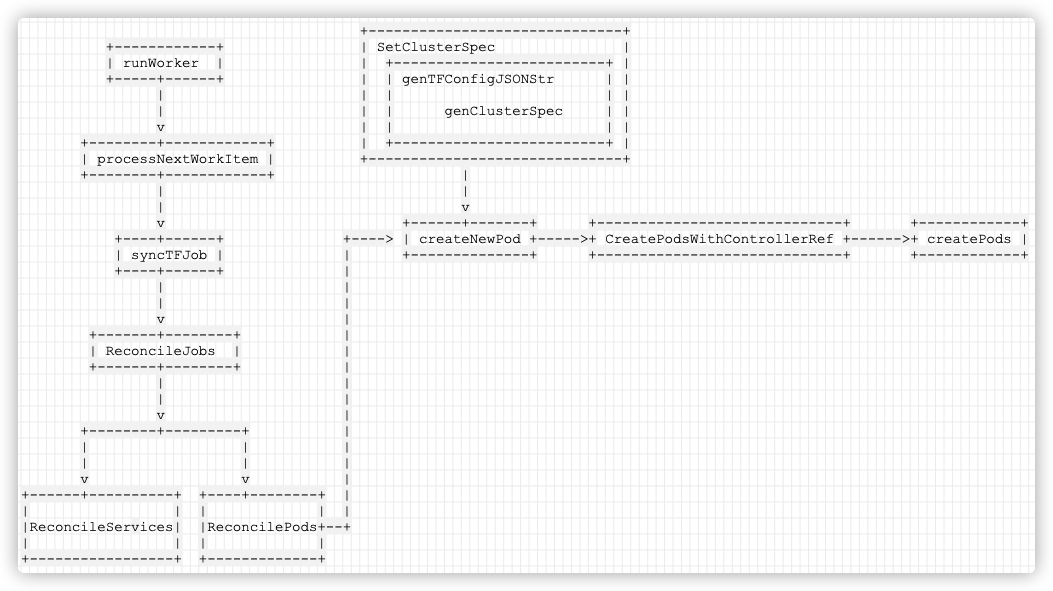
��ʱ������:
+------------------------------+
+------------+ | SetClusterSpec |
| runWorker | | +-------------------------+ |
+-----+------+ | | genTFConfigJSONStr | |
| | | | |
| | | genClusterSpec | |
v | | | |
+--------+------------+ | +-------------------------+ |
| processNextWorkItem | +------------------------------+
+--------+------------+ |
| |
| v
v +------+-------+ +-----------------------------+ +------------+
+----+------+ +----> | createNewPod +----->+ CreatePodsWithControllerRef +------>+ createPods |
| syncTFJob | | +--------------+ +-----------------------------+ +------------+
+----+------+ |
| |
| |
v |
+-------+--------+ |
| ReconcileJobs | |
+-------+--------+ |
| |
| |
v |
+--------+---------+ |
| | |
| | |
v v |
+------+----------+ +----+--------+ |
| | | | |
|ReconcileServices| |ReconcilePods+--+
| | | |
+-----------------+ +-------------+
�ֻ�����:
4.7 ��������
4.7.1 ReconcileServices
ReconcileServices Ϊÿ��������TFReplicaSpec������service,��������:
- ���ڴ���/ɾ������ʱ��������ʱ����tfjob��
- ��ȡrt���͵�����service��
- ���߽����·���;
- ����ɾ���ɷ���,Ŀǰֻ������Сworker��service��Χ;
// reconcileServices checks and updates services for each given ReplicaSpec.
// It will requeue the job in case of an error while creating/deleting services.
func (jc *JobController) ReconcileServices(
job metav1.Object,
services []*v1.Service,
rtype apiv1.ReplicaType,
spec *apiv1.ReplicaSpec) error {
// Convert ReplicaType to lower string.
rt := strings.ToLower(string(rtype))
replicas := int(*spec.Replicas)
// Get all services for the type rt.
services, err := jc.FilterServicesForReplicaType(services, rt)
// GetServiceSlices will return enough information here to make decision to add/remove/update resources.
//
// For example, let's assume we have services with replica-index 0, 1, 2
// If replica is 4, return a slice with size 4. [[0],[1],[2],[]], a svc with replica-index 3 will be created.
//
// If replica is 1, return a slice with size 3. [[0],[1],[2]], svc with replica-index 1 and 2 are out of range and will be deleted.
serviceSlices := jc.GetServiceSlices(services, replicas, commonutil.LoggerForReplica(job, rt))
for index, serviceSlice := range serviceSlices {
if len(serviceSlice) > 1 {
} else if len(serviceSlice) == 0 {
err = jc.CreateNewService(job, rtype, spec, strconv.Itoa(index))
} else {
// Check the status of the current svc.
svc := serviceSlice[0]
// check if the index is in the valid range, if not, we should kill the svc
if index < 0 || index >= replicas {
err = jc.ServiceControl.DeleteService(svc.Namespace, svc.Name, job.(runtime.Object))
}
}
}
return nil
}
4.7.2 CreateNewService
Ϊ������index��type����һ����service:
// createNewService creates a new service for the given index and type.
func (jc *JobController) CreateNewService(job metav1.Object, rtype apiv1.ReplicaType,
spec *apiv1.ReplicaSpec, index string) error {
jobKey, err := KeyFunc(job)
// Convert ReplicaType to lower string.
rt := strings.ToLower(string(rtype))
expectationServicesKey := expectation.GenExpectationServicesKey(jobKey, rt)
err = jc.Expectations.ExpectCreations(expectationServicesKey, 1)
if err != nil {
return err
}
// Append ReplicaTypeLabel and ReplicaIndexLabel labels.
labels := jc.GenLabels(job.GetName())
labels[apiv1.ReplicaTypeLabel] = rt
labels[apiv1.ReplicaIndexLabel] = index
port, err := jc.GetPortFromJob(spec)
if err != nil {
return err
}
service := &v1.Service{
Spec: v1.ServiceSpec{
ClusterIP: "None",
Selector: labels,
Ports: []v1.ServicePort{},
},
}
// Add service port to headless service only if port is set from controller implementation
if port != nil {
svcPort := v1.ServicePort{Name: jc.Controller.GetDefaultContainerPortName(), Port: *port}
service.Spec.Ports = append(service.Spec.Ports, svcPort)
}
service.Name = GenGeneralName(job.GetName(), rt, index)
service.Labels = labels
// Create OwnerReference.
controllerRef := jc.GenOwnerReference(job)
err = jc.ServiceControl.CreateServicesWithControllerRef(job.GetNamespace(), service, job.(runtime.Object), controllerRef)
if err != nil && errors.IsTimeout(err) {
succeededServiceCreationCount.Inc()
return nil
} else if err != nil {
failedServiceCreationCount.Inc()
return err
}
succeededServiceCreationCount.Inc()
return nil
}
4.7.3 CreateServicesWithControllerRef
ʹ�ü�Ⱥ��������Ϣ,��������Service�Ĵ���:
func (r RealServiceControl) CreateServicesWithControllerRef(namespace string, service *v1.Service, controllerObject runtime.Object, controllerRef *metav1.OwnerReference) error {
if err := ValidateControllerRef(controllerRef); err != nil {
return err
}
return r.createServices(namespace, service, controllerObject, controllerRef)
}
4.7.4 createServices
��ʱ����������K8S�ӿڴ���service:
func (r RealServiceControl) createServices(namespace string, service *v1.Service, object runtime.Object, controllerRef *metav1.OwnerReference) error {
if labels.Set(service.Labels).AsSelectorPreValidated().Empty() {
return fmt.Errorf("unable to create Services, no labels")
}
serviceWithOwner, err := GetServiceFromTemplate(service, object, controllerRef)
newService, err := r.KubeClient.CoreV1().Services(namespace).Create(serviceWithOwner)
accessor, err := meta.Accessor(object)
}
��ʱ����չ����:
+------------------------------+
+------------+ | SetClusterSpec |
| runWorker | | +-------------------------+ |
+-----+------+ | | genTFConfigJSONStr | |
| | | | |
| | | genClusterSpec | |
v | | | |
+--------+------------+ | +-------------------------+ |
| processNextWorkItem | +------------------------------+
+--------+------------+ |
| |
| v
v +------+-------+ +-----------------------------+ +------------+
+----+------+ +----> | createNewPod +----->+ CreatePodsWithControllerRef +------>+ createPods |
| syncTFJob | | +--------------+ +-----------------------------+ +------------+
+----+------+ |
| |
| |
v | +------------------+ +---------------------------------+ +----------------+
+-------+--------+ | +----> | CreateNewService +---->+ CreateServicesWithControllerRef +--->+ createServices |
| ReconcileJobs | | | +------------------+ +---------------------------------+ +----------------+
+-------+--------+ | |
| | |
| | |
v | |
+--------+---------+ | |
| | | |
| | | |
v v | |
+------+----------+ +----+--------+ | |
| | | | | |
|ReconcileServices| |ReconcilePods+--+ |
| | | | |
+------+----------+ +-------------+ |
| |
+---------------------------------->+
�ֻ�����:
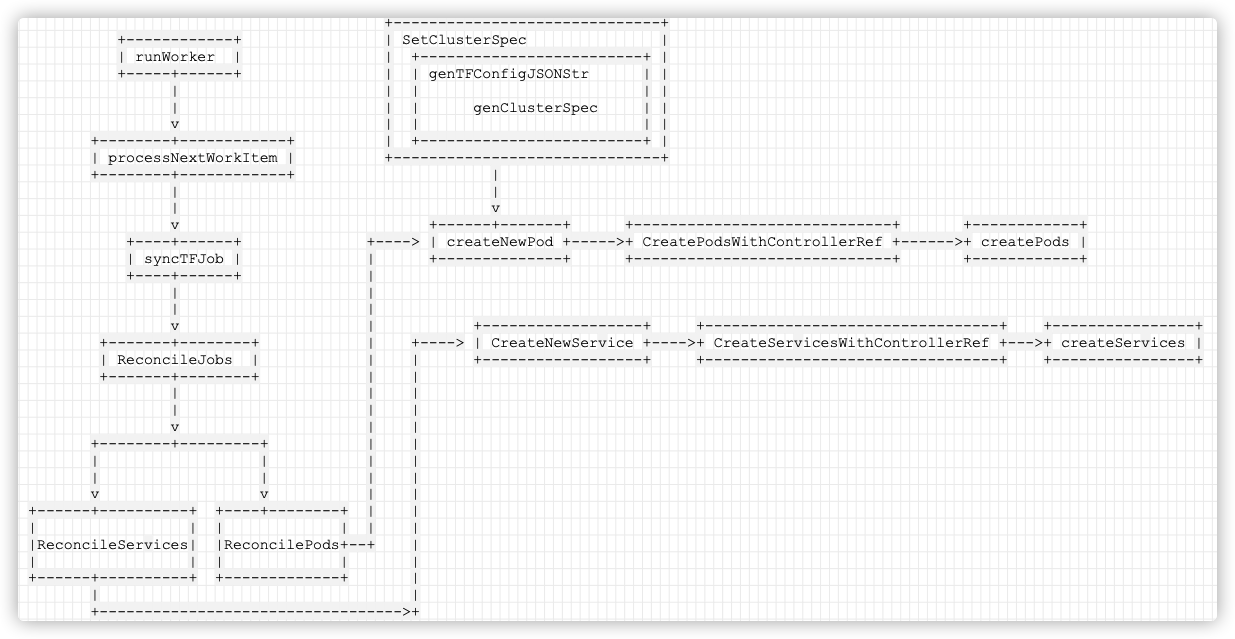
�������Ǵ��¿�֪,TF-Operator �����Ͼ���:
- ͨ�� TF-Operator �������Զ�����Դ�����������ֲ�ʽ����ѧϰ��ѵ������;
- ͬʱʵ���� TFJob �� Controller ���������������ϲ���,���û������ö������֮��Ĺ�ϵ;
0x05 ����ͨ����Ƚ�
����������,��ҿ���Ҳ�е��ɻ�,���� TF on K8s �� ��ͨ������ɶ����,���ƺδ���?��������;�������¡�
5.1 ����
�������ȿ�Դ���е�Dockerfile����
FROM tensorflow/tensorflow:1.5.0
ADD . /var/tf_dist_mnist
ENTRYPOINT ["python", "/var/tf_dist_mnist/dist_mnist.py"]
Ȼ����Ӧ�� spec,�ֱ���2�� PS,4�� Worker��
apiVersion: "kubeflow.org/v1"
kind: "TFJob"
metadata:
name: "dist-mnist-for-e2e-test"
spec:
tfReplicaSpecs:
PS:
replicas: 2
restartPolicy: Never
template:
spec:
containers:
- name: tensorflow
image: kubeflow/tf-dist-mnist-test:1.0
Worker:
replicas: 4
restartPolicy: Never
template:
spec:
containers:
- name: tensorflow
image: kubeflow/tf-dist-mnist-test:1.0
Ȼ���ٰ�װexample,��һ���ֲ�ʽ�� mnist ѵ������
cd ./examples/v1/dist-mnist
docker build -f Dockerfile -t kubeflow/tf-dist-mnist-test:1.0 .
kubectl create -f ./tf_job_mnist.yaml
5.2 �Ƚ�
���Ǿͼ�ѵ�����뿴����
5.2.1 ��ͨ TF
����host ��������ͨ���ű����������õ�,������Ƕ�ȡ����������������
# ��ȡ����
ps_spec = FLAGS.ps_hosts.split(',')
worker_spec = FLAGS.worker_hosts.split(',')
# ������Ⱥ
num_worker = len(worker_spec)
cluster = tf.train.ClusterSpec({'ps': ps_spec, 'worker': worker_spec})
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
5.2.2 TF-Operator
����,dist_mnist.py�������·�ʽ��ȡ cluster ��Ϣ��
# If not explicitly specified in the constructor and the TF_CONFIG
# environment variable is present, load cluster_spec from TF_CONFIG.
tf_config = json.loads(os.environ.get('TF_CONFIG') or '{}')
���,�� TF-Operator ֮��������,˵�� cluster ��Ϣ�Ǵ���������:
tfConfig = "TF_CONFIG"
Ȼ��,�� SetClusterSpec ��������,���ǵ��� K8S �ӿڶ�̬��ȡ����:
// SetClusterSpec generates and sets TF_CONFIG for the given podTemplateSpec.
func (tc *TFController) SetClusterSpec(job interface{}, podTemplate *v1.PodTemplateSpec, rtype, index string) error {
tfjob, ok := job.(*tfv1.TFJob)
// Do not set TF_CONFIG for local training jobs.
if !isDistributed(tfjob) {
return nil
}
// Generate TF_CONFIG JSON string.
tfConfigStr, err := genTFConfigJSONStr(tfjob, rtype, index)
// Add TF_CONFIG environment variable to tensorflow container in the pod.
for i := range podTemplate.Spec.Containers {
if podTemplate.Spec.Containers[i].Name == tfv1.DefaultContainerName {
if len(podTemplate.Spec.Containers[i].Env) == 0 {
podTemplate.Spec.Containers[i].Env = make([]v1.EnvVar, 0)
}
podTemplate.Spec.Containers[i].Env = append(podTemplate.Spec.Containers[i].Env, v1.EnvVar{
Name: tfConfig,
Value: tfConfigStr,
})
break
}
}
return nil
}
��˿���֪��,���û��Ƕȿ�,������һ����뼴�ɡ����ڲ�������,������ K8S �ӹ��ˡ�
�û�ֻҪ�� spec ֮���趨��Ҫ���� worker,ps �ͳɡ������û��Ϳ��Ѿ���������ģ��֮�ϡ���devops ���չ����Ϊ��㶨һ�С�
0x06 �ܽ�
�ۺ�֮ǰ�����ǿ��Եó� TF-Operator ��������:
- ͨ�� TF-Operator �������Զ�����Դ�����������ֲ�ʽ����ѧϰ��ѵ������;
- ͬʱʵ���� TFJob �� Controller ���������������ϲ���,���û������ö������֮��Ĺ�ϵ;
- �����û�,ֻҪ����һ�� TFJob ���Զ�����Դ����,�� Template ���ú������Ϣ,���൱��������һ���ֲ�ʽѵ�������ִ�й����ˡ�
- �û����Ѿ���������ģ��֮�ϡ���devops ���չ����Ϊ��㶨һ��;
kubeflow/tf-operator ��Ȼ��������,������Ȼ�кܶ�ȱ�ݡ�
- Kubeflow ������ Kubernetes ���������� TensorFlow ԭ���ķֲ�ʽ������������ҵ������ ��Ϊ���߲������ݴ�,���� Kubeflow �������������С������ݴ�,Ҳ��ζ�Ų� �ܵ��Ե��ȡ�
- ʹ�� kubeflow/tf-operator ִ�зֲ�ʽ TensorFlow ��ҵ,ģ�͵�������ȴ�����Ľ���ȫ����������ܿ�ʼ�������Ⱥ��Դ�������������н���,��ǰ��ҵֻ�ܵȴ�������ҵ�ͷ���Դ��Ϊ��������Դ�ȴ�ʱ��,���Ը���ҵ����ר����Դ�ء�
- ������Դ������,��Ⱥ��Դ�����ʻ�ܵ͡����� kubeflow/tf-operator ����ͬʱ����з�Ч�ʺͼ�Ⱥ�����ʡ�
����,����Ҫ����:û�к� horovod ��ϵ����,û�а�װ MPI ������,�����������ǿ��� MPI-Operator��
0xEE ������Ϣ
��������������ͼ�����˼���������
�Ź����˺�:������˼��
������뼰ʱ�õ�����д���µ���Ϣ����,�����뿴�������Ƽ��ļ�������,�����ע��

0xFF �ο�
tensorflowѧϰ�ʼ�(ʮ��):�ֲ�ʽTensorflow
�� Kubernetes �ϵ������ѧϰѵ������-Elastic Training Operator
��Googleһ����������ѧϰϵͳ3 - ����MPIJob����ResNet101
����|һ̽��Ѷ����Kubeflow�����Ķ��⻧ѵ��ƽ̨����ļ����ܹ�
https://blog.csdn.net/weixin_43970890/article/details/113863716
�� Amazon EKS ���Ż��ֲ�ʽ���ѧϰ���ܵ����ʵ��
��ԭ���ĵ��� AI ѵ��ϵ��֮һ:���� AllReduce �ĵ��Էֲ�ʽѵ��ʵ��
ͨ��shellִ��kubectl exec���ڶ�Ӧpod������ִ��shell����
k8sϵ�� �C CRD�Զ�����Դ��Controllerʵ��(���ƪ)
TensorFlow�ֲ�ʽȫ��(ԭ��,����,ʵ��)