DenseNetЕФжївЊЫМЯы
ФПЧАЕФЭјТчНсЙЙвЊУДЪЧдіМгСЫЭјТчЕФПэЖШ(GoogLeNet),вЊУДЪЧдіМгСЫЭјТчЕФЩюЖШ(Resnet)ЁЃЕЋЪЧDenseNetСэБйѕшОЖ,ЫћЪЧДгЬиеїЩЯШыЪжЁЃЭјТчНсЙЙЗЧГЃаЁЧЩ,ЕЋЪЧаЇЙћШДЗЧГЃЕФОЊШЫ!
вЛаЉгагУЕФСДНг
ТлЮФ:Densely Connected Convolutional Networks
ТлЮФСДНг:https://arxiv.org/pdf/1608.06993.pdf
ДњТыЕФgithubСДНг:https://github.com/liuzhuang13/DenseNet
MXNetАцБОДњТы(гаImageNetдЄбЕСЗФЃаЭ): https://github.com/miraclewkf/DenseNet
DenseNet ЕФКЫаФ
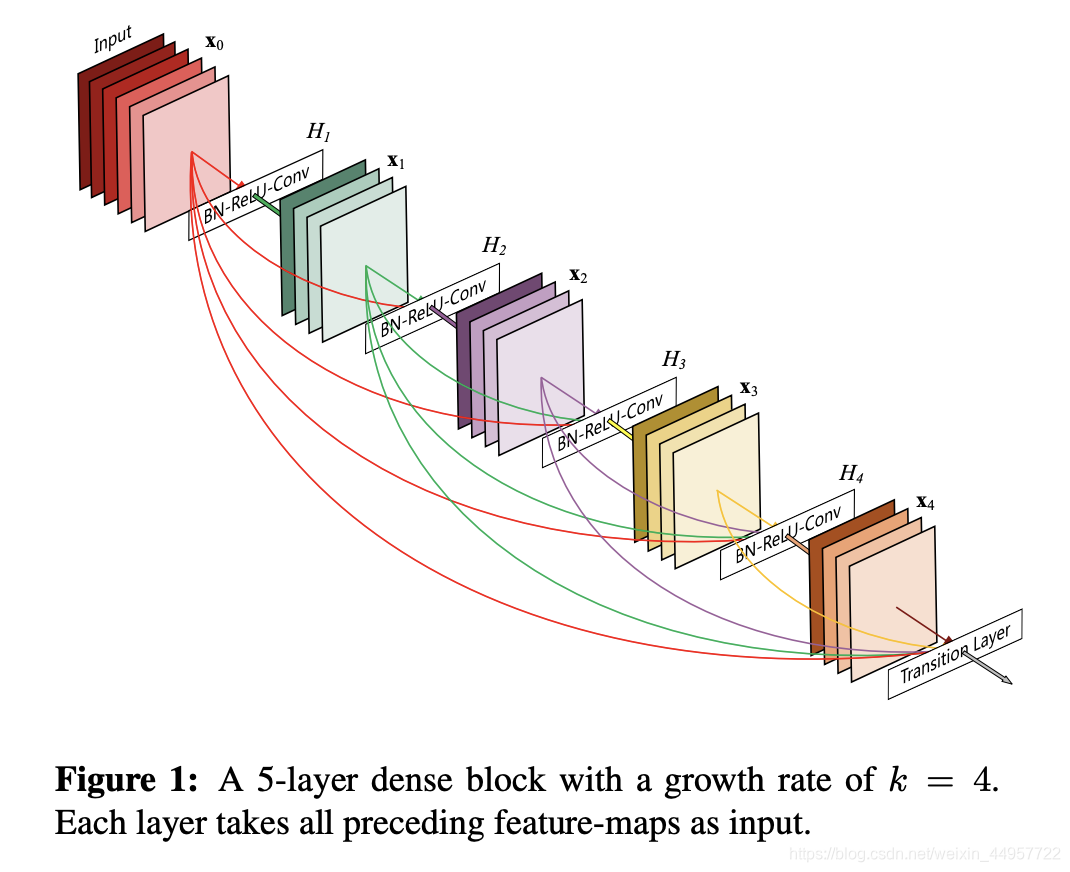
DenseNet ЕФКЫаФЪЧDense blockЁЃетИіЖЋЮїЮвгУвЛОфЛАИХРЈвЛЯТОЭЪЧУПвЛВуЕФЪфШыРДздЧАУцЫљгаВуЕФЪфГіЁЃ
дкДЋЭГЕФЩёОЭјТчжа,ШчЙћФугаNВу,ФЧУДОЭгаNИіСЌНгЁЃЕЋЪЧдкDenseNetжа,Лсга
L
?
(
L
+
1
)
/
2
L*(L+1)/2
L?(L+1)/2ИіСЌНгЁЃЯТУцПДвЛЯТDense blockЕФЭМЪО:
ЮФеТжаЭЌбљвВгУЙЋЪНЫЕУїСЫDenseNetКЭResNetЕФЧјБ№:
ЪзЯШПДвЛЯТResNetЕФЙЋЪН:
X
l
=
H
l
(
X
l
?
1
)
+
X
l
?
1
X_l = H_l(X_{l-1})+X_{l-1}
Xl?=Hl?(Xl?1?)+Xl?1?
етРяЕФ
l
l
lБэЪОВу,
X
l
X_l
Xl?БэЪО
l
l
lВуЕФЪфГі,
H
l
H_l
Hl?БэЪОвЛИіЗЧЯпадБфЛЛЁЃЫљвдЖдгкResNetЖјбд,
l
l
lВуЕФЪфГіЪЧ
l
?
1
l-1
l?1ВуЕФЪфГіМгЩЯЖд
l
?
1
l-1
l?1ВуЪфГіЕФЗЧЯпадБфЛЛЁЃ
дйРДПДвЛЯТЮвУЧЕФDenseNetЕФЙЋЪН:
X
l
=
H
l
(
[
X
0
,
X
1
,
X
2
,
.
.
.
,
X
l
?
1
]
)
X_l = H_l([X_0, X_1,X_2, ... , X_{l-1}])
Xl?=Hl?([X0?,X1?,X2?,...,Xl?1?])
[
X
0
,
X
1
,
X
2
,
.
.
.
,
X
l
?
1
]
[X_0, X_1,X_2, ... , X_{l-1}]
[X0?,X1?,X2?,...,Xl?1?]БэЪОНЋ
0
0
0ЕН
l
?
1
l-1
l?1ВуЕФЪфГіfeature mapзіconcatenationЁЃconcatenationЪЧзіЭЈЕРЕФКЯВЂ,ОЭЯёInceptionФЧбљЁЃЖјЧАУцresnetЪЧзіжЕЕФЯрМг,ЭЈЕРЪ§ЪЧВЛБфЕФЁЃ
H
l
H_l
Hl?АќРЈBN,ReLUКЭ
3
ЁС
3
3\times3
3ЁС3ЕФОэЛ§ЁЃ
DenseNetЕФгХЕу
етРяУцжївЊЫЕЦфжаЕФЫФЕу:
1ЁЃ МѕЧсСЫЬнЖШЯћЪЇЕФЮЪЬт
2ЁЃ МгЧПСЫЬиеїЕФДЋВЅ
3ЁЃ гааЇЕФРћгУСЫЬиеї
4ЁЃМѕЩйСЫВЮЪ§ЕФЪ§СП
DenseNetЕФНсЙЙ
ЯТУцЕФБэЪОЕФЪЧвЛИіDenseNetЕФНсЙЙЭМ,дкетИіНсЙЙЭМжаАќКЌСЫ3Иіdense blockЁЃзїепНЋDenseNetЗжГЩЖрИіdense block,двђЪЧЯЃЭћИїИіdense blockФкЕФfeature mapЕФsizeЭГвЛ,етбљдкзіconcatenationОЭВЛЛсгаsizeЕФЮЪЬтЁЃ
