Learn note06ЈCConvolutional Neural Network
1. Why CNN for Image
Aneuron does not have to see the whole image to discover the pattern.
The same patterns appear in different regions.
- ЁЎupper-left breakЁЏ detector
- ЁЎmiddle beakЁЏ detector
Subsampling the pixels will not change the object.
The whole CNN
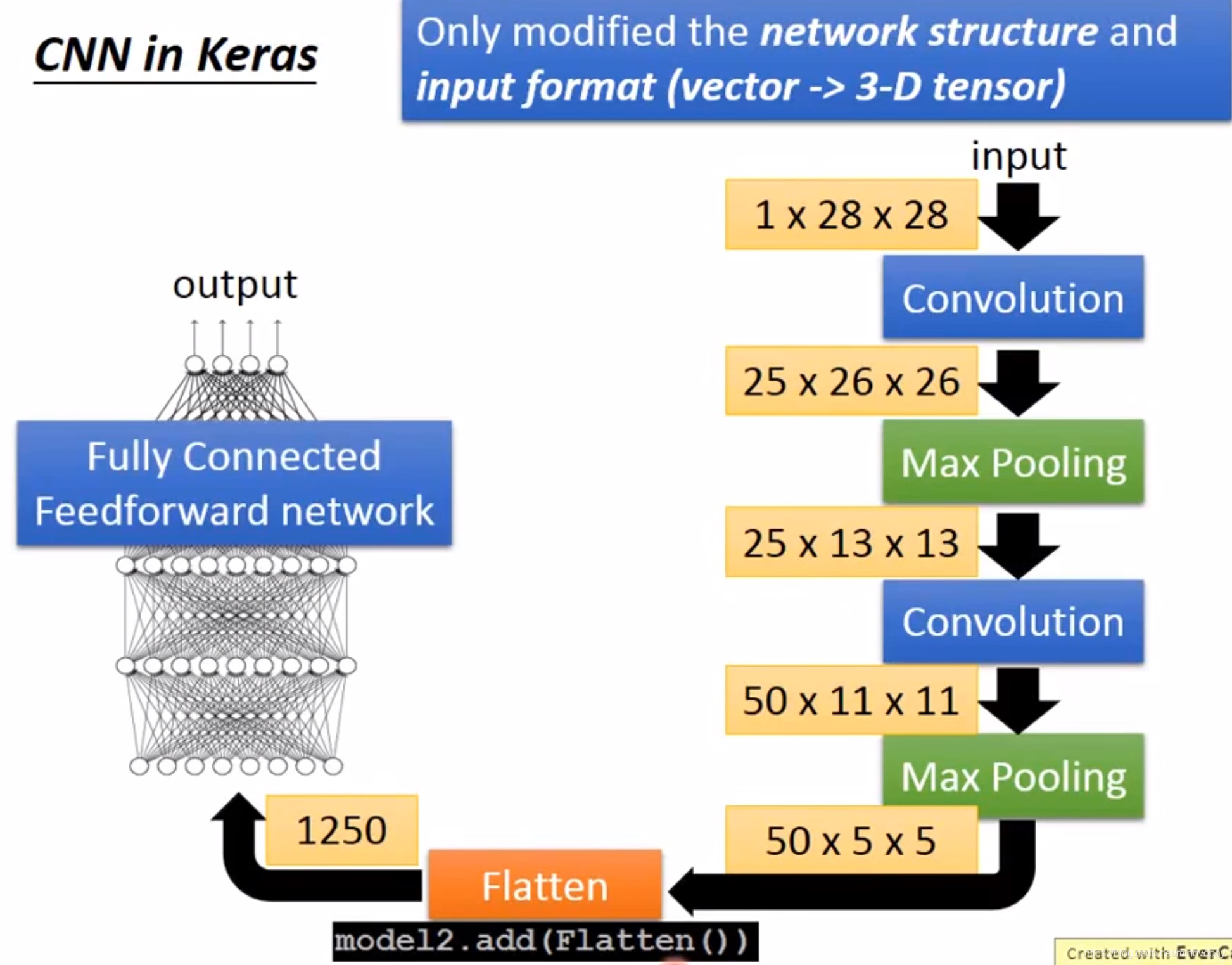
input,Convolution, Max Pooling, Convolution, Max Pooling, Flatten(can repeat many times), Fully connected Feedforward network. A new image.
Small than the original image
The number of the channel is the number of filters.
CNN- Max Pooling
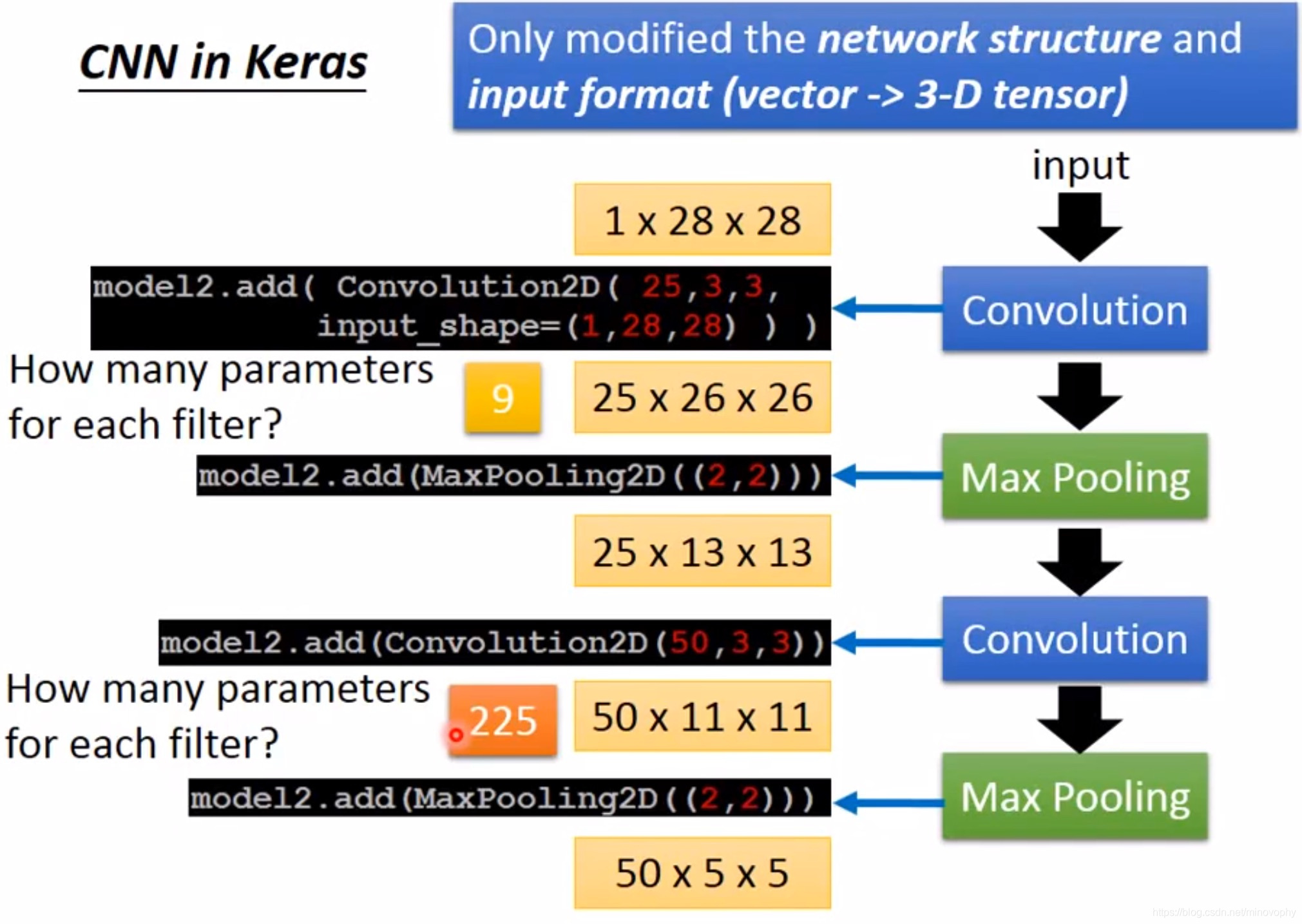
CNN in Keras
Only modified the network structure and input format(vector 3-D tensor)
input, Convolution, Max Pooling, Convolution, Max Pooling
input 12828, Convolution2D(25, 3, 3), output(252626), (26= 28-3+1),
input(output(252626)), MaxPooling2D((2,2))), output(251313),
input(output(251313)), Convolution2D(50, 3, 3)), output(501111)(11 = 13-3+1)
input(output(501111), MaxPlooling2D((2,2))), output(5055)
2. More Application: Playing Go
Fully-connected feedforward network can be used.
But CNN performs much better.
Some patterns are much smaller than the whole image.
The same patterns appear in different regions.
Subsampling the pixels will not change the object.
3. More Application: Speech/Text
embedding dimension
sentence matrix, convolutional feature map, pooled representation,softmax.