李宏毅深度学习–卷积神经网络
本文主要基于以下参考资料:
开源文档:https://datawhalechina.github.io/leeml-notes
视频地址:https://www.bilibili.com/video/BV1Ht411g7Ef
下面这张图展示了CNN的全过程:
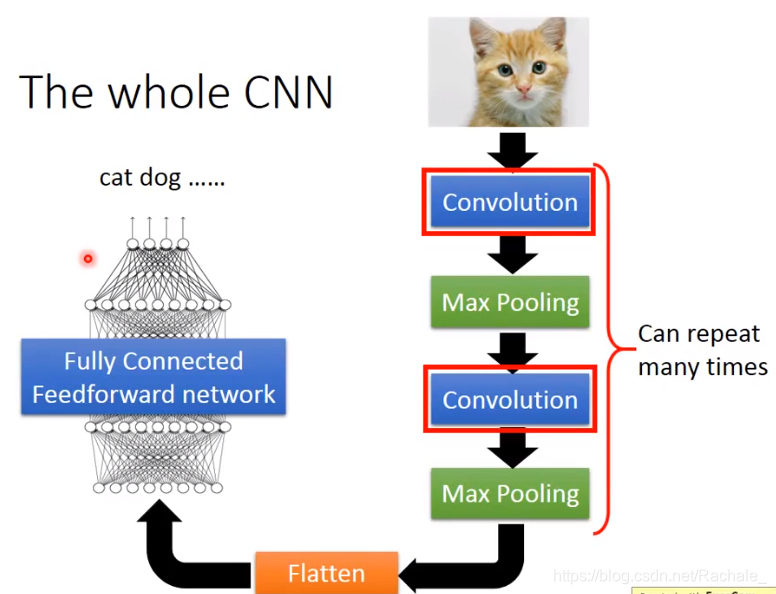
- convolution 卷积
stride表示步长,也就是每次挪动的距离,stride=1表示每次移动一格,每行移动到末端就往下移动一格继续从左开始往右挪动。每次计算image矩阵中得到的红框矩阵与filter 1的内积,最终可以得到下图右下角的4*4矩阵。这个矩阵叫feature map。
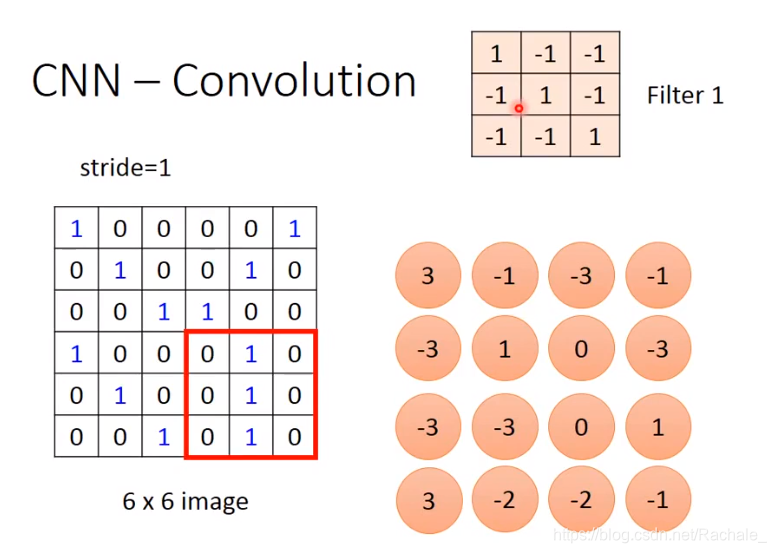
- filter的作用: 可以检测某种模式是否存在
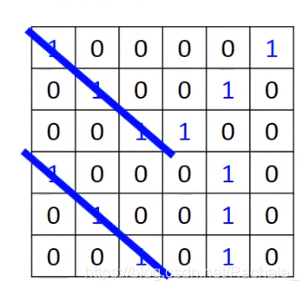
filter 1 可以检测有没有连续的1连续出现。观察上述得到的4*4的矩阵,就可以发现(1,1)与(4,1)处等于3,因此说明原矩阵中左上角和左下角的两个地方有连续的1出现,如下图蓝色斜线所示。
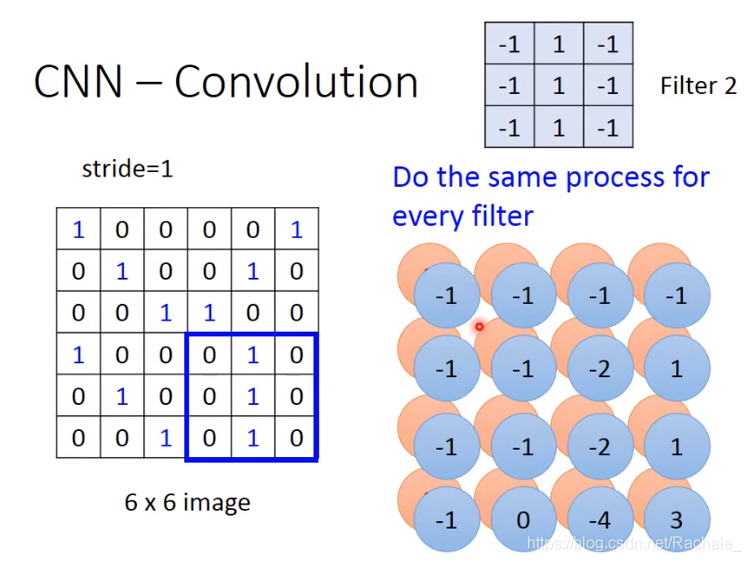
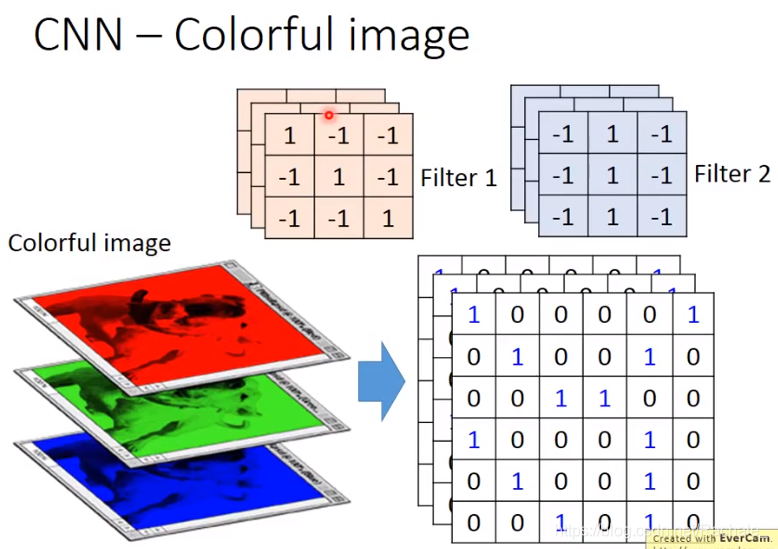
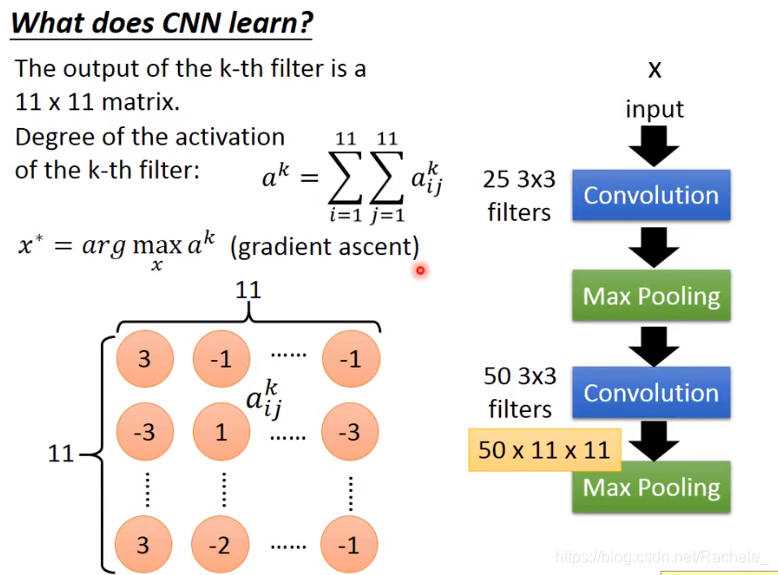
不同的filter用于检测不同的模式,在每一层神经网络中,可以包含多个filter(滤波器),每个filter可以得到一个feature map。
filter 2检测是否存在竖直的连续出现的3个1,最终检测到右下角出现模式二。
- filter 的维度由输入层的维度决定,每一维的大小取决于要检测的模式
如果是彩色图片,那么图片的像素矩阵应该是3维的,因此每一个filter也应该是3维(层)的。
- CNN VS 完全连接神经网络
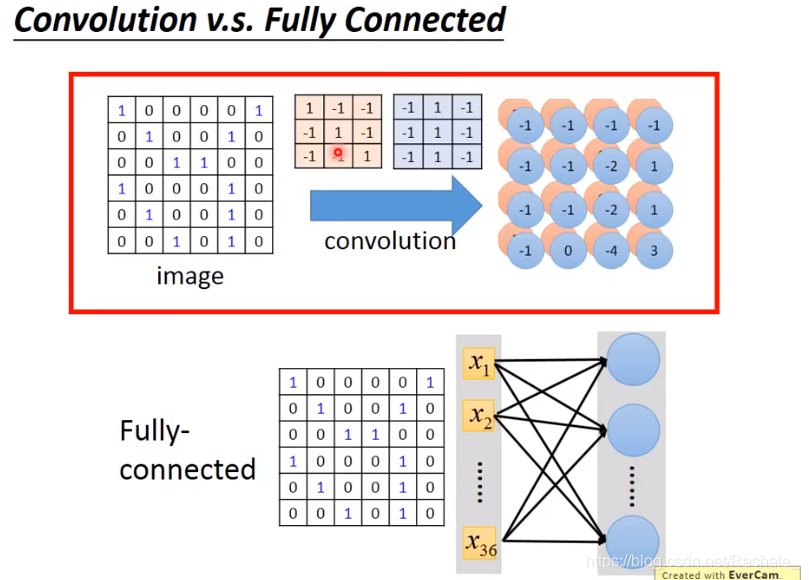
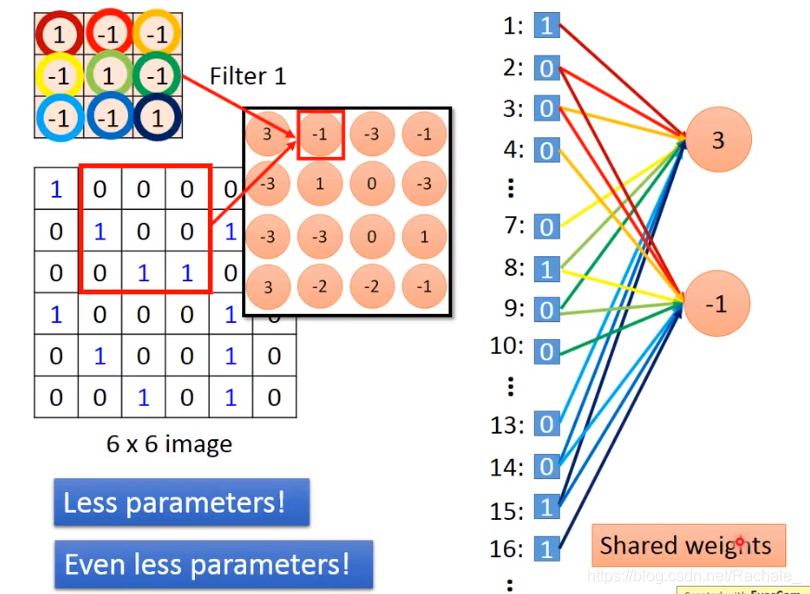
其实相当于是输入层中某些值的权重为0,完全连接神经网络是输入层的每个值都有非0的权重,因此CNN是Not fully connected。此外,由于共用同一个filter,因此同一层神经网络中的每个神经元给输入值的权重分布是一样的。
- MAX Pooling
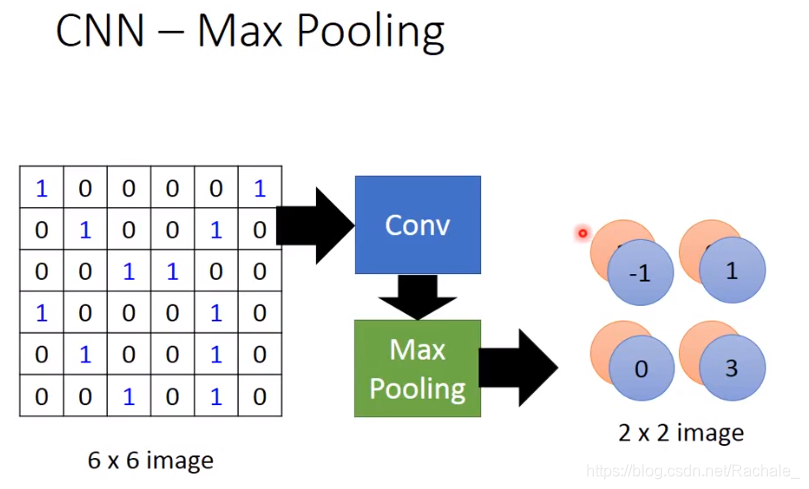
对于每一张图片,即使从像素矩阵中抽取一部分信息,也不改变图片原始形状,这是max pooling得以应用的原因。
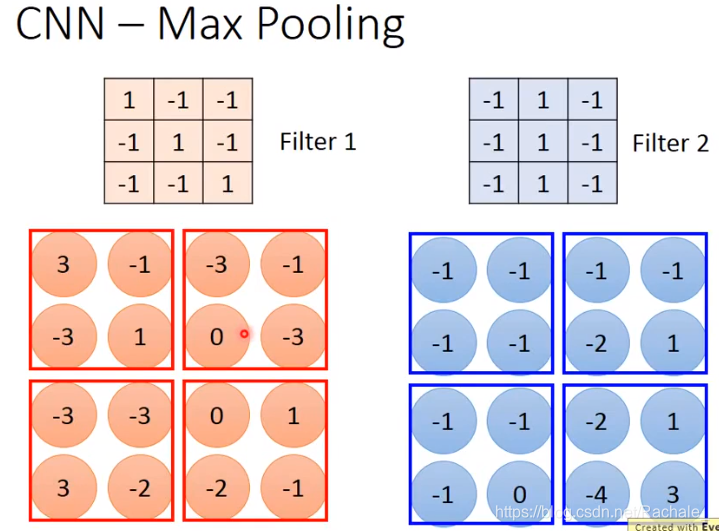
选择框框中每4个值中最大的那一个,具体框框的大小可以视具体情况决定。
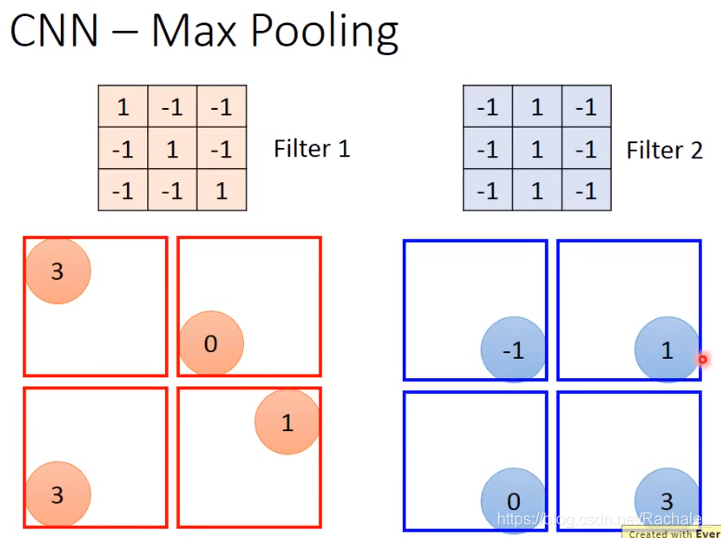
最终得到下面的值。有多少个filter,得到新的image矩阵就有多少维。
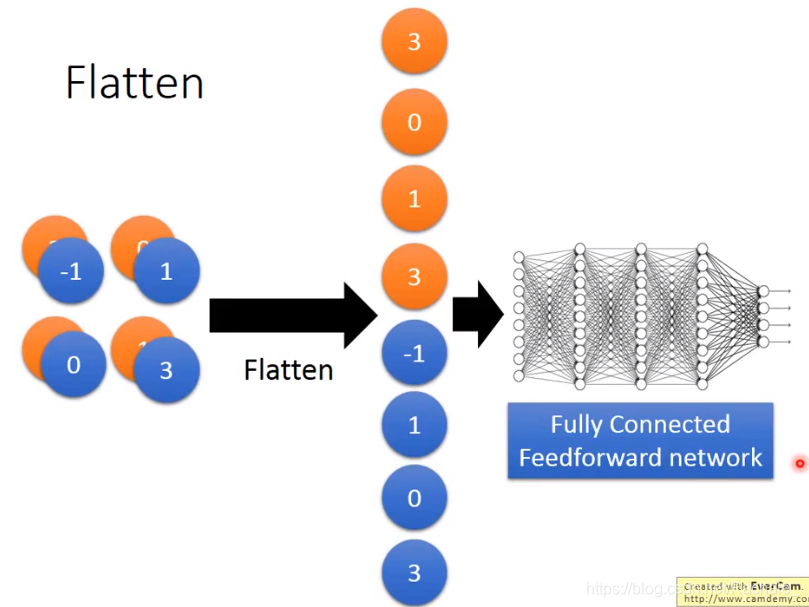
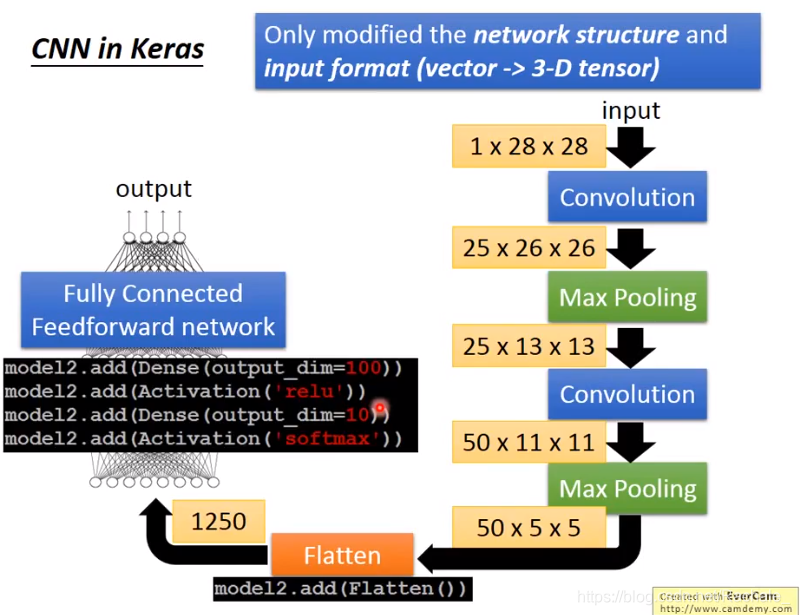
- Flatten
flatten其实就是把filter输出的多维矩阵拉成一个数组的过程,最终传递给全连接前馈神经网络,后面就是之前学的DNN的部分。
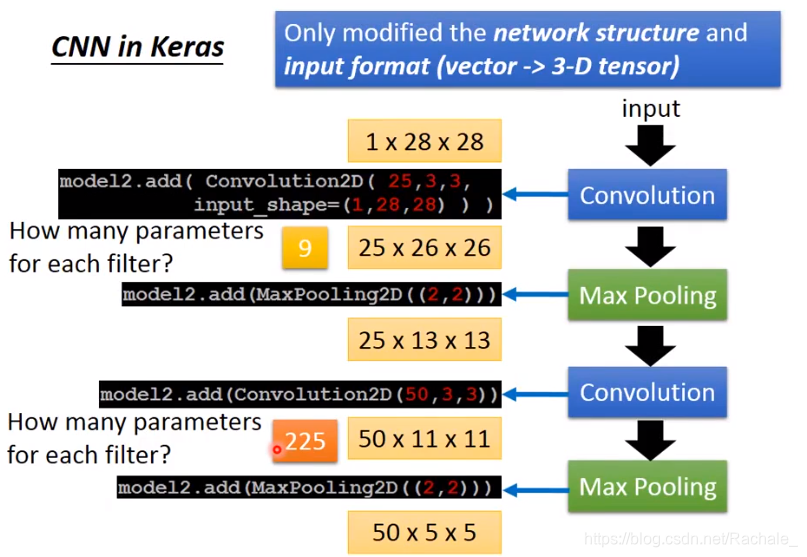
- CNN in Keras
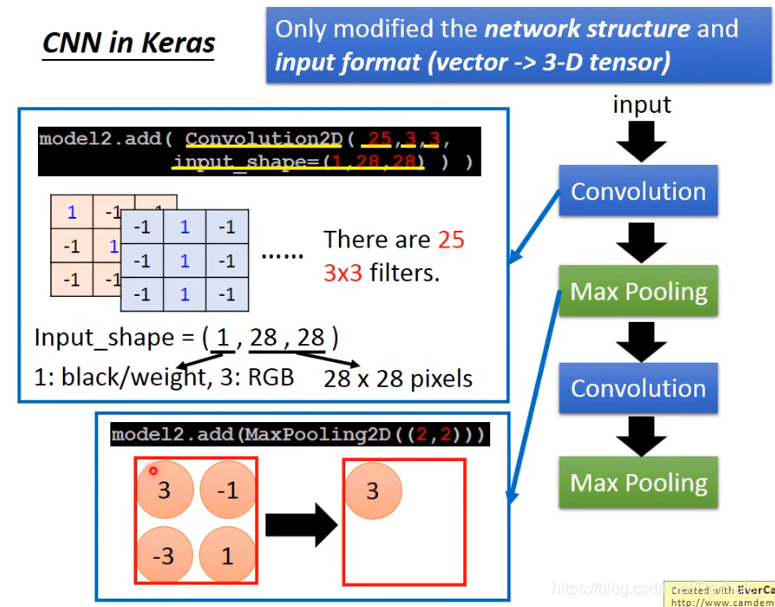
第二次卷积的filter的参数个数=2533=225个,上一轮max pooling得到的是251313的pixel矩阵,因此filter也应该是25维的。
- CNN的完整架构
在DNN的基础上,最开始进行一次图片压缩。图片压缩由多次convoluntion和max pooling组成。
- what does CNN learn
部分学习资料

下图左边部分人眼根本无法分辨是数字,但却是CNN学习到的内容。对CNN加以限制,如下图右边所示公式(其中加号应该为减号),约束像素的值要尽量小,最终得到下图右方的图片。

- deep dream
夸大现在看到的东西

取得的效果

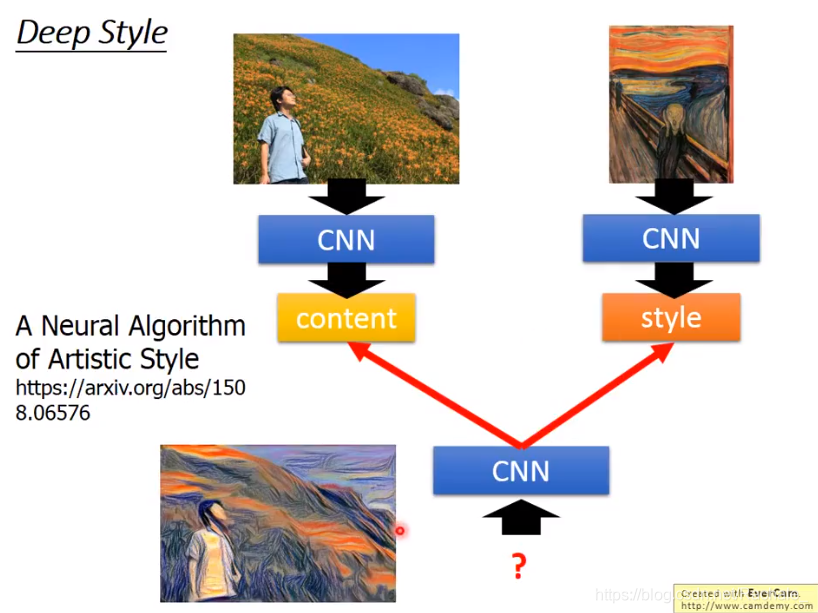
- deep style
filter 之间的关系决定图片的风格,filter的模式决定图片内容形状。deep style从原图片中学习filter的模式,从想要转化的风格图片中获取filter之间的关系,最终找到一个同时满足上面两个要求的filter。
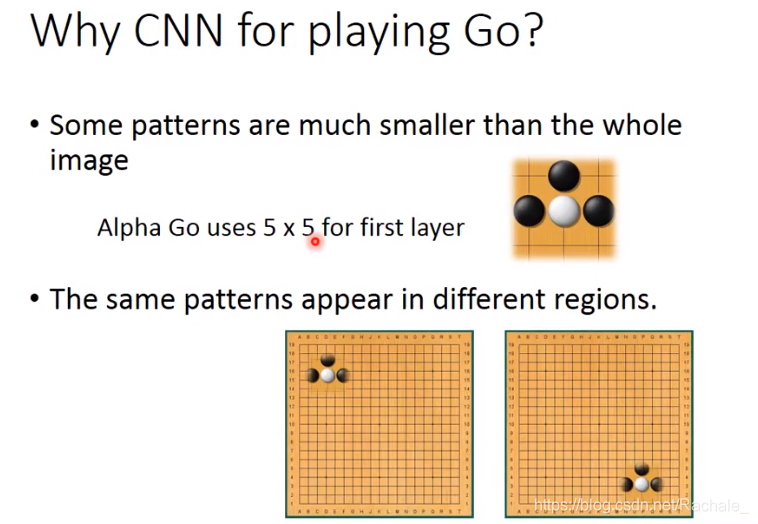
- CNN应用在下围棋上
当图片的某些特性存在时,才可以使用CNN

但实际上在playing go上没有使用max pooling。 - 后续的学习资料
