适用于 TensorFlow 2.3 及 keras 2.4.3 ,Python版本为3.8
如果你使用新版本的第三方库,请考虑降级为本文适用的版本,或者自行查阅第三方库的升级文档修改代码。
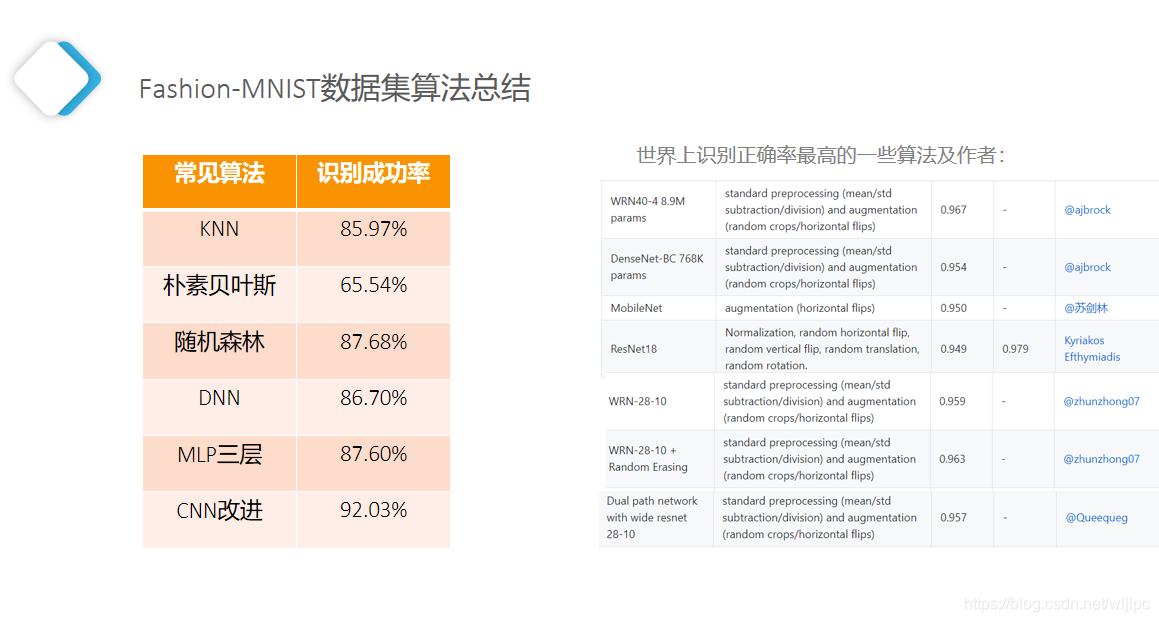
图像分类数据集中最常用的是手写数字识别数据集MNIST 。但大部分模型在MNIST上的分类精度都超过了95%。为了更直观地观察算法之间的差异,我们将使用一个图像内容更加复杂的数据集Fashion-MNIST?
FashionMNIST 是图像数据集,它是由 Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。FashionMNIST 的大小、格式和训练集/测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28x28 的灰度图片。方便我们进行测试各种神经网络算法。 该数据集识别难度远大于原有的MNIST数据集。

数据库导入
所有代码都用keras.datasets接口来加载fashion_mnist数据,从网络上直接下载fashion_mnist数据,无需从本地导入,十分方便。
这意味着你可以将代码中的
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
修改为(X_train, y_train), (X_test, y_test) = mnist.load_data()
就可以直接对原始的MNIST数据集进行训练和识别。
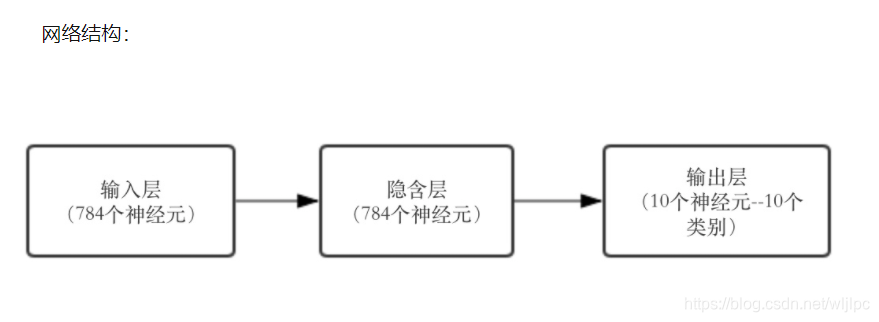
1.Baseline版本代码(MLP实现,识别成功率为87.6%)
BaseLine版本用的是MultiLayer Percepton(多层感知机)。这个网络结构比较简单,输入--->隐含--->输出。隐含层采用的rectifier linear unit,输出直接选取的softmax进行多分类。
import numpy
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.utils import np_utils
from keras.datasets import fashion_mnist
seed = 7
numpy.random.seed(seed)
#加载数据
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
num_pixels = X_train.shape[1] * X_train.shape[2]
X_train = X_train.reshape(X_train.shape[0], num_pixels).astype('float32')
X_test = X_test.reshape(X_test.shape[0], num_pixels).astype('float32')
X_train = X_train / 255
X_test = X_test / 255
# 对输出进行one hot编码
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
# MLP模型
def baseline_model():
model = Sequential()
model.add(Dense(num_pixels, input_dim=num_pixels, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# 建立模型
model = baseline_model()
# Fit
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2)
#Evaluation
scores = model.evaluate(X_test, y_test, verbose=0)
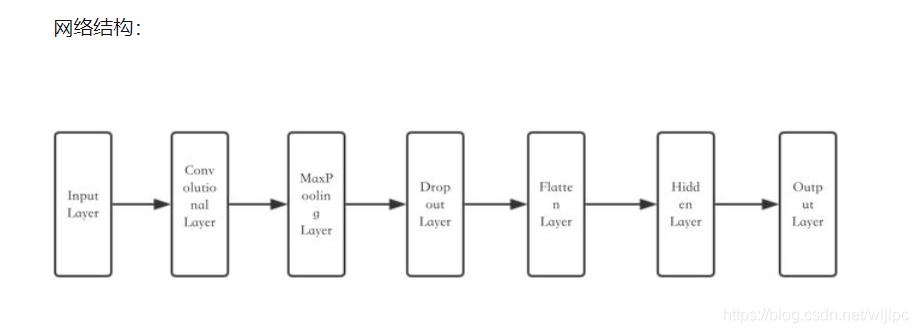
print("使用MLP并迭代十次的正确率为:" ,'%.2f' %(scores[1]*100) , "%")?2.CNN卷积神经网络(迭代20次,识别成功率92%)?
import numpy
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Convolution2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
from keras.datasets import fashion_mnist
seed = 7
numpy.random.seed(seed)
#加载数据
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
# reshape to be [samples][channels][width][height]
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32')
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32')
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
# define a simple CNN model
def baseline_model():
# create model
model = Sequential()
model.add(Convolution2D(32,( 5, 5), padding='valid', input_shape=( 28, 28, 1), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.1))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# build the model
model = baseline_model()
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=20, batch_size=128, verbose=2)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("使用CNN网络的正确率为:" ,'%.2f' %(scores[1]*100) , "%")附录