Datawhale���ѧϰ֮����ѧϰ����Task 6 Boosting
��ǰ���ѧϰ��,̽����һϵ�м�ʵ�õĻع�ͷ���ģ��,ͬʱҲ̽�������ʹ�ü���ѧϰ�����е�Bagging˼��ȥ�Ż����յ�ģ�͡�Bagging˼���ʵ����:ͨ��Bootstrap �ķ�ʽ��ȫ�������ݼ����г����õ������Ӽ�,�Բ�ͬ���Ӽ�ʹ��ͬһ�ֻ���ģ�ͽ������,Ȼ��ͶƱ�ó����յ�Ԥ�⡣Bagging��Ҫͨ�����ͷ���ķ�ʽ����Ԥ������ô,���½��ܵ�Boosting����Bagging��Ȼ��ͬ��˼��,Boosting������ʹ��ͬһ�����ݼ����з���ѧϰ,�õ�һϵ�м�ģ��,Ȼ�������Щģ����һ��Ԥ������ʮ��ǿ��Ļ���ѧϰģ�͡���Ȼ,Boosting˼��������յ�Ԥ��Ч����ͨ�����ϼ���ƫ�����ʽ,��Bagging���ű��ʵIJ�ͬ����Boosting��һ�������,��Ҫ�������ೣ�õ�Boosting��ʽ:Adaptive Boosting �� Gradient Boosting �Լ����ǵı���Xgboost��LightGBM�Լ�Catboost��
һ��Boosting�����Ļ���˼·
Boosting������뷢չ�벻��Valiant�� Kearns��Ŭ��,��ʷ������Valiant�� Kearns�����"ǿ��ѧϰ"��"����ѧϰ"�ĸ����ʲô��"ǿ��ѧϰ"��"����ѧϰ"��?�ڸ��ʽ�����ȷPACѧϰ�Ŀ����:
- ��ѧϰ:ʶ�������С��1/2(��ȷ�ʽ�������²��Ըߵ�ѧϰ�㷨)
- ǿѧϰ:ʶ��ȷ�ʺܸ߲����ڶ���ʽʱ������ɵ�ѧϰ�㷨
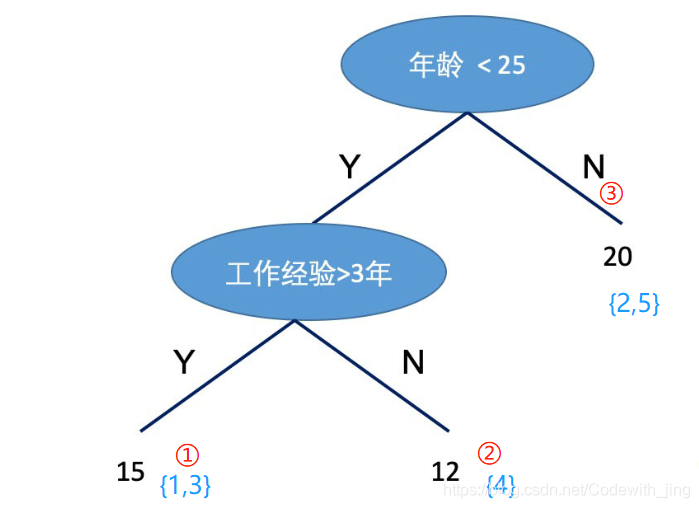
�dz���Ȥ����,��PAC ѧϰ�Ŀ����,ǿ��ѧϰ������ѧϰ�ǵȼ۵�,Ҳ����˵һ��������ǿ��ѧϰ�ij�ֱ�Ҫ�������������������ѧϰ�ġ�����һ��,�������:��ѧϰ��,����Ѿ�����������ѧϰ�㷨,�ܷ���������ǿ��ѧϰ�㷨����Ϊ,����ѧϰ�㷨��ǿ��ѧϰ�㷨���öࡣ�����������Ǵ���ѧϰ�㷨����,����ѧϰ,�õ�һϵ����������(�ֳ�Ϊ����������),Ȼ��ͨ��һ������ʽȥ�����Щ������������һ��ǿ���������������Boosting��������ͨ���ı�ѵ�����ݼ��ĸ��ʷֲ�(ѵ�����ݲ�ͬ������Ȩֵ),��Բ�ͬ���ʷֲ������ݵ����������㷨ѧϰһϵ�е�����������
����Boosting������˵,������������Ҫ������:��һ����ÿһ��ѧϰӦ����θı����ݵĸ��ʷֲ�,�ڶ�������ν������������������������������������,��ͬ��Boosting�㷨���в�ͬ�Ĵ�,���ǽ���������һ������Boosting�㷨----Adaboost,������Ҫ����Adaboost����ô���������������Լ�Ϊʲô��ô�����ġ�
����Adaboost�㷨
1��Adaboost����ԭ��
����Adaboost��˵,�����������������ķ�ʽ��:1. �����Щ��ǰһ�ַ�������������������Ȩ��,��������Щ����ȷ�����������Ȩ�ء�����һ��,��Щ����һ�ַ�������û�еõ���ȷ���������,������Ȩ�ص�������ں�һ�ֵ�ѵ���С����ܹ�ע����2. �������������������ͨ����ȡ��Ȩ���������ķ�ʽ,������˵,�Ӵ��������ʵ͵�����������Ȩ��,��Ϊ��Щ�������ܸ��õ���ɷ�������,����С��������ʽϴ������������Ȩ��,ʹ���ڱ��������С�����á�
����,�������������Adaboost�㷨:(�ο����ʦ�ġ�ͳ��ѧϰ������)
�������һ���������ѵ�����ݼ�:
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
?
?
,
(
x
N
,
y
N
)
}
T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\}
T={(x1?,y1?),(x2?,y2?),?,(xN?,yN?)},����ÿ���������������������ɡ�����
x
i
��
X
?
R
n
x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}
xi?��X?Rn,���
y
i
��
Y
=
{
?
1
,
+
1
}
y_{i} \in \mathcal{Y}=\{-1,+1\}
yi?��Y={?1,+1},
X
\mathcal{X}
X�������ռ�,
Y
\mathcal{Y}
Y�����,������շ�����
G
(
x
)
G(x)
G(x)��Adaboost�㷨����:
(1) ��ʼ��ѵ�����ݵķֲ�:
D 1 = ( w 11 , ? ? , w 1 i , ? ? , w 1 N ) , w 1 i = 1 N , i = 1 , 2 , ? ? , N D_{1}=\left(w_{11}, \cdots, w_{1 i}, \cdots, w_{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N D1?=(w11?,?,w1i?,?,w1N?),w1i?=N1?,i=1,2,?,N
(2) ����m=1,2,��,M
- ʹ�þ���Ȩֵ�ֲ� D m D_m Dm?��ѵ�����ݼ�����ѧϰ,�õ�����������: G m ( x ) : X �� { ? 1 , + 1 } G_{m}(x): \mathcal{X} \rightarrow\{-1,+1\} Gm?(x):X��{?1,+1}
- ���� G m ( x ) G_m(x) Gm?(x)��ѵ�����ϵķ�������� e m = �� i = 1 N P ( G m ( x i ) �� y i ) = �� i = 1 N w m i I ( G m ( x i ) �� y i ) e_{m}=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)=\sum_{i=1}^{N} w_{m i} I\left(G_{m}\left(x_{i}\right) \neq y_{i}\right) em?=��i=1N?P(Gm?(xi?)��?=yi?)=��i=1N?wmi?I(Gm?(xi?)��?=yi?)
- ���� G m ( x ) G_m(x) Gm?(x)��ϵ�� �� m = 1 2 log ? 1 ? e m e m \alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}} ��m?=21?logem?1?em??,�����log����Ȼ����ln
- ����ѵ�����ݼ���Ȩ�طֲ�
D m + 1 = ( w m + 1 , 1 , ? ? , w m + 1 , i , ? ? , w m + 1 , N ) w m + 1 , i = w m i Z m exp ? ( ? �� m y i G m ( x i ) ) , i = 1 , 2 , ? ? , N \begin{array}{c} D_{m+1}=\left(w_{m+1,1}, \cdots, w_{m+1, i}, \cdots, w_{m+1, N}\right) \\ w_{m+1, i}=\frac{w_{m i}}{Z_{m}} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right), \quad i=1,2, \cdots, N \end{array} Dm+1?=(wm+1,1?,?,wm+1,i?,?,wm+1,N?)wm+1,i?=Zm?wmi??exp(?��m?yi?Gm?(xi?)),i=1,2,?,N?
����� Z m Z_m Zm?�ǹ淶������,ʹ�� D m + 1 D_{m+1} Dm+1?��Ϊ���ʷֲ�, Z m = �� i = 1 N w m i exp ? ( ? �� m y i G m ( x i ) ) Z_{m}=\sum_{i=1}^{N} w_{m i} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right) Zm?=��i=1N?wmi?exp(?��m?yi?Gm?(xi?))
(3) ����������������������� f ( x ) = �� m = 1 M �� m G m ( x ) f(x)=\sum_{m=1}^{M} \alpha_{m} G_{m}(x) f(x)=��m=1M?��m?Gm?(x),�õ����յķ�����
G ( x ) = sign ? ( f ( x ) ) = sign ? ( �� m = 1 M �� m G m ( x ) ) \begin{aligned} G(x) &=\operatorname{sign}(f(x)) \\ &=\operatorname{sign}\left(\sum_{m=1}^{M} \alpha_{m} G_{m}(x)\right) \end{aligned} G(x)?=sign(f(x))=sign(m=1��M?��m?Gm?(x))?
�����Adaboost�㷨������˵��:
���ڲ���(1),����ѵ�����ݵ�Ȩֵ�ֲ��Ǿ��ȷֲ�,��Ϊ��ʹ�õ�һ��û��������Ϣ��������ÿ�������ڻ�����������ѧϰ������һ����
���ڲ���(2),ÿһ�ε��������Ļ���������
G
m
(
x
)
G_m(x)
Gm?(x)�ڼ�Ȩѵ�����ݼ��ϵķ��������
e
m
=
��
i
=
1
N
P
(
G
m
(
x
i
)
��
y
i
)
=
��
G
m
(
x
i
)
��
y
i
w
m
i
\begin{aligned}e_{m} &=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right) =\sum_{G_{m}\left(x_{i}\right) \neq y_{i}} w_{m i}\end{aligned}
em??=i=1��N?P(Gm?(xi?)��?=yi?)=Gm?(xi?)��?=yi?��?wmi??��������
G
m
(
x
)
G_m(x)
Gm?(x)�з�����������Ȩ�غ�,���ֱ��˵����Ȩ�طֲ�
D
m
D_m
Dm?��
G
m
(
x
)
G_m(x)
Gm?(x)�ķ��������
e
m
e_m
em?��ֱ�ӹ�ϵ��ͬʱ,�ڲ���(2)��,�������������
G
m
(
x
)
G_m(x)
Gm?(x)��ϵ��
��
m
\alpha_m
��m?,
��
m
=
1
2
log
?
1
?
e
m
e
m
\alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}}
��m?=21?logem?1?em??,����ʾ��
G
m
(
x
)
G_m(x)
Gm?(x)�����շ���������Ҫ�Գ̶�,
��
m
\alpha_m
��m?��ȡֵ�ɻ���������
G
m
(
x
)
G_m(x)
Gm?(x)�ķ����������ֱ�ӹ�ϵ,��
e
m
?
1
2
e_{m} \leqslant \frac{1}{2}
em??21?ʱ,
��
m
?
0
\alpha_{m} \geqslant 0
��m??0,����
��
m
\alpha_m
��m?����
e
m
e_m
em?�ļ��ٶ�����,��˷��������ԽС�Ļ��������������շ�����������Խ��!
����Ҫ��,���ڲ���(2)�е�����Ȩ�صĸ���:
w
m
+
1
,
i
=
{
w
m
i
Z
m
e
?
��
m
,
G
m
(
x
i
)
=
y
i
w
m
i
Z
m
e
��
m
,
G
m
(
x
i
)
��
y
i
w_{m+1, i}=\left\{\begin{array}{ll} \frac{w_{m i}}{Z_{m}} \mathrm{e}^{-\alpha_{m}}, & G_{m}\left(x_{i}\right)=y_{i} \\ \frac{w_{m i}}{Z_{m}} \mathrm{e}^{\alpha_{m}}, & G_{m}\left(x_{i}\right) \neq y_{i} \end{array}\right.
wm+1,i?={Zm?wmi??e?��m?,Zm?wmi??e��m?,?Gm?(xi?)=yi?Gm?(xi?)��?=yi??
���,����ʽ���Կ���:������������
G
m
(
x
)
G_m(x)
Gm?(x)��������������Ȩ������,����ȷ���������Ȩ�ؼ���,����������
e
2
��
m
=
1
?
e
m
e
m
\mathrm{e}^{2 \alpha_{m}}=\frac{1-e_{m}}{e_{m}}
e2��m?=em?1?em??����
���ڲ���(3),�������
f
(
x
)
f(x)
f(x)ʵ���˽�M�������������ļ�Ȩ����,ϵ��
��
m
\alpha_m
��m?��־�˻���������
G
m
(
x
)
G_m(x)
Gm?(x)����Ҫ��,ֵ��ע�����:���е�
��
m
\alpha_m
��m?֮�Ͳ�Ϊ1��
f
(
x
)
f(x)
f(x)�ķ��ž���������x������һ�ࡣ
����,����ʹ��һ����������ֶ�����Adaboost�㷨�Ĺ���:(������Դ:http://www.csie.edu.tw)
ѵ���������±�,�����������������ʽ��һ���ָ�
x
<
v
x<v
x<v��
x
>
v
x>v
x>v��ʾ,��ֵv�ɸû�����������ѵ�����ݼ��Ϸ��������
e
m
e_m
em?���ȷ����
?���?
1
2
3
4
5
6
7
8
9
10
x
0
1
2
3
4
5
6
7
8
9
y
1
1
1
?
1
?
1
?
1
1
1
1
?
1
\begin{array}{ccccccccccc} \hline \text { ��� } & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10 \\ \hline x & 0 & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 \\ y & 1 & 1 & 1 & -1 & -1 & -1 & 1 & 1 & 1 & -1 \\ \hline \end{array}
?���?xy?101?211?321?43?1?54?1?65?1?761?871?981?109?1??
��:
��ʼ������Ȩֵ�ֲ�
D
1
=
(
w
11
,
w
12
,
?
?
,
w
110
)
w
1
i
=
0.1
,
i
=
1
,
2
,
?
?
,
10
\begin{aligned} D_{1} &=\left(w_{11}, w_{12}, \cdots, w_{110}\right) \\ w_{1 i} &=0.1, \quad i=1,2, \cdots, 10 \end{aligned}
D1?w1i??=(w11?,w12?,?,w110?)=0.1,i=1,2,?,10?
��m=1:
- ��Ȩֵ�ֲ�
D
1
D_1
D1?��ѵ�����ݼ���,����ÿ����㲢������������
e
m
e_m
em?,��ֵȡv=2.5ʱ������������,��ô����������Ϊ:
G 1 ( x ) = { 1 , x < 2.5 ? 1 , x > 2.5 G_{1}(x)=\left\{\begin{array}{ll} 1, & x<2.5 \\ -1, & x>2.5 \end{array}\right. G1?(x)={1,?1,?x<2.5x>2.5? - G 1 ( x ) G_1(x) G1?(x)��ѵ�����ݼ��ϵ������Ϊ e 1 = P ( G 1 ( x i ) �� y i ) = 0.3 e_{1}=P\left(G_{1}\left(x_{i}\right) \neq y_{i}\right)=0.3 e1?=P(G1?(xi?)��?=yi?)=0.3��
- ���� G 1 ( x ) G_1(x) G1?(x)��ϵ��: �� 1 = 1 2 log ? 1 ? e 1 e 1 = 0.4236 \alpha_{1}=\frac{1}{2} \log \frac{1-e_{1}}{e_{1}}=0.4236 ��1?=21?loge1?1?e1??=0.4236
- ����ѵ�����ݵ�Ȩֵ�ֲ�:
D 2 = ( w 21 , ? ? , w 2 i , ? ? , w 210 ) w 2 i = w 1 i Z 1 exp ? ( ? �� 1 y i G 1 ( x i ) ) , i = 1 , 2 , ? ? , 10 D 2 = ( 0.07143 , 0.07143 , 0.07143 , 0.07143 , 0.07143 , 0.07143 , 0.16667 , 0.16667 , 0.16667 , 0.07143 ) f 1 ( x ) = 0.4236 G 1 ( x ) \begin{aligned} D_{2}=&\left(w_{21}, \cdots, w_{2 i}, \cdots, w_{210}\right) \\ w_{2 i}=& \frac{w_{1 i}}{Z_{1}} \exp \left(-\alpha_{1} y_{i} G_{1}\left(x_{i}\right)\right), \quad i=1,2, \cdots, 10 \\ D_{2}=&(0.07143,0.07143,0.07143,0.07143,0.07143,0.07143,\\ &0.16667,0.16667,0.16667,0.07143) \\ f_{1}(x) &=0.4236 G_{1}(x) \end{aligned} D2?=w2i?=D2?=f1?(x)?(w21?,?,w2i?,?,w210?)Z1?w1i??exp(?��1?yi?G1?(xi?)),i=1,2,?,10(0.07143,0.07143,0.07143,0.07143,0.07143,0.07143,0.16667,0.16667,0.16667,0.07143)=0.4236G1?(x)?
����m=2:
- ��Ȩֵ�ֲ�
D
2
D_2
D2?��ѵ�����ݼ���,����ÿ����㲢������������
e
m
e_m
em?,��ֵȡv=8.5ʱ������������,��ô����������Ϊ:
G 2 ( x ) = { 1 , x < 8.5 ? 1 , x > 8.5 G_{2}(x)=\left\{\begin{array}{ll} 1, & x<8.5 \\ -1, & x>8.5 \end{array}\right. G2?(x)={1,?1,?x<8.5x>8.5? - G 2 ( x ) G_2(x) G2?(x)��ѵ�����ݼ��ϵ������Ϊ e 2 = 0.2143 e_2 = 0.2143 e2?=0.2143
- ���� G 2 ( x ) G_2(x) G2?(x)��ϵ��: �� 2 = 0.6496 \alpha_2 = 0.6496 ��2?=0.6496
- ����ѵ�����ݵ�Ȩֵ�ֲ�:
D 3 = ( 0.0455 , 0.0455 , 0.0455 , 0.1667 , 0.1667 , 0.1667 0.1060 , 0.1060 , 0.1060 , 0.0455 ) f 2 ( x ) = 0.4236 G 1 ( x ) + 0.6496 G 2 ( x ) \begin{aligned} D_{3}=&(0.0455,0.0455,0.0455,0.1667,0.1667,0.1667\\ &0.1060,0.1060,0.1060,0.0455) \\ f_{2}(x) &=0.4236 G_{1}(x)+0.6496 G_{2}(x) \end{aligned} D3?=f2?(x)?(0.0455,0.0455,0.0455,0.1667,0.1667,0.16670.1060,0.1060,0.1060,0.0455)=0.4236G1?(x)+0.6496G2?(x)?
��m=3:
- ��Ȩֵ�ֲ�
D
3
D_3
D3?��ѵ�����ݼ���,����ÿ����㲢������������
e
m
e_m
em?,��ֵȡv=5.5ʱ������������,��ô����������Ϊ:
G 3 ( x ) = { 1 , x > 5.5 ? 1 , x < 5.5 G_{3}(x)=\left\{\begin{array}{ll} 1, & x>5.5 \\ -1, & x<5.5 \end{array}\right. G3?(x)={1,?1,?x>5.5x<5.5? - G 3 ( x ) G_3(x) G3?(x)��ѵ�����ݼ��ϵ������Ϊ e 3 = 0.1820 e_3 = 0.1820 e3?=0.1820
- ���� G 3 ( x ) G_3(x) G3?(x)��ϵ��: �� 3 = 0.7514 \alpha_3 = 0.7514 ��3?=0.7514
- ����ѵ�����ݵ�Ȩֵ�ֲ�:
D 4 = ( 0.125 , 0.125 , 0.125 , 0.102 , 0.102 , 0.102 , 0.065 , 0.065 , 0.065 , 0.125 ) D_{4}=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125) D4?=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125)
���ǵõ�:
f
3
(
x
)
=
0.4236
G
1
(
x
)
+
0.6496
G
2
(
x
)
+
0.7514
G
3
(
x
)
f_{3}(x)=0.4236 G_{1}(x)+0.6496 G_{2}(x)+0.7514 G_{3}(x)
f3?(x)=0.4236G1?(x)+0.6496G2?(x)+0.7514G3?(x),������
sign
?
[
f
3
(
x
)
]
\operatorname{sign}\left[f_{3}(x)\right]
sign[f3?(x)]��ѵ�����ݼ��ϵ�������ĸ���Ϊ0��
���ǵõ����շ�����Ϊ:
G
(
x
)
=
sign
?
[
f
3
(
x
)
]
=
sign
?
[
0.4236
G
1
(
x
)
+
0.6496
G
2
(
x
)
+
0.7514
G
3
(
x
)
]
G(x)=\operatorname{sign}\left[f_{3}(x)\right]=\operatorname{sign}\left[0.4236 G_{1}(x)+0.6496 G_{2}(x)+0.7514 G_{3}(x)\right]
G(x)=sign[f3?(x)]=sign[0.4236G1?(x)+0.6496G2?(x)+0.7514G3?(x)]
2��ʹ��sklearn��Adaboost�㷨���н�ģ
���ΰ�������ʹ��һ��UCI�Ļ���ѧϰ����Ŀ�Դ���ݼ�:���Ѿ����ݼ�,�����ݼ������� ( https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data )�ϻ�á������ݼ�������178��������13������,�Ӳ�ͬ�ĽǶȶԲ�ͬ�Ļ�ѧ���Խ�������,���ǵ������Ǹ�����Щ����Ԥ����������һ�����(������Դ��python����ѧϰ(�ڶ��桷)
��������(ʾ��):
# �������ݿ�ѧ��ع��߰�:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
%matplotlib inline
import seaborn as sns
# ����ѵ������:
wine = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data",header=None)
wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash','Magnesium', 'Total phenols','Flavanoids', 'Nonflavanoid phenols',
'Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
# ���ݲ鿴:
print("Class labels",np.unique(wine["Class label"]))
wine.head()
.��������������:
. - Class label:�����ǩ
. - Alcohol:�ƾ�
. - Malic acid:ƻ����
. - Ash:��
. - Alcalinity of ash:�ҵļ��
. - Magnesium:þ
. - Total phenols:�ܷ�
. - Flavanoids:��ͪ�����
. - Nonflavanoid phenols:�ǻ��������
. - Proanthocyanins:ԭ������
. - Color intensity:ɫ��ǿ��
. - Hue:ɫ��
. - OD280/OD315 of diluted wines:ϡ�;�OD280 OD350
. - Proline:������
# ����Ԥ����
# ��������2,3�����Ѿ�,ȥ��1��
wine = wine[wine['Class label'] != 1]
y = wine['Class label'].values
X = wine[['Alcohol','OD280/OD315 of diluted wines']].values
# �������ǩ��ɶ����Ʊ���:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
# ��8:2�ָ�ѵ�����Ͳ��Լ�
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y) # stratify���������˰���y�����ȱ�������
# ʹ�õ�һ��������ģ
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=1)
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))
Decision tree train/test accuracies 0.916/0.875
# ʹ��sklearnʵ��Adaboost(��������Ϊ������)
'''
AdaBoostClassifier��ز���:
base_estimator:����������,Ĭ��ΪDecisionTreeClassifier(max_depth=1)
n_estimators:��ֹ�����Ĵ���
learning_rate:ѧϰ��
algorithm:ѵ��������㷨,{'SAMME','SAMME.R'},Ĭ��='SAMME.R'
random_state:�������
'''
from sklearn.ensemble import AdaBoostClassifier
ada = AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1,random_state=1)
ada = ada.fit(X_train,y_train)
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pred)
ada_test = accuracy_score(y_test,y_test_pred)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))
Adaboost train/test accuracies 1.000/0.917
�������:����������ƺ���ѵ������Ƿ���,��Adaboostģ����ȷ��Ԥ����ѵ�����ݵ����з����ǩ,�����뵥����������,Adaboost�IJ�������Ҳ������ߡ�Ȼ��,Ϊʲôģ����ѵ�����Ͳ��Լ������������ô����?����ʹ��ͼ������˵�����������!
# ���������������Adaboost�ľ��߽߱�:
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,sharex='col',sharey='row',figsize=(12, 6))
for idx, clf, tt in zip([0, 1],[tree, ada],['Decision tree', 'Adaboost']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],X_train[y_train==0, 1],c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],X_train[y_train==1, 1],c='red', marker='o')
axarr[idx].set_title(tt)
axarr[0].set_ylabel('Alcohol', fontsize=12)
plt.tight_layout()
plt.text(0, -0.2,s='OD280/OD315 of diluted wines',ha='center',va='center',fontsize=12,transform=axarr[1].transAxes)
plt.show()
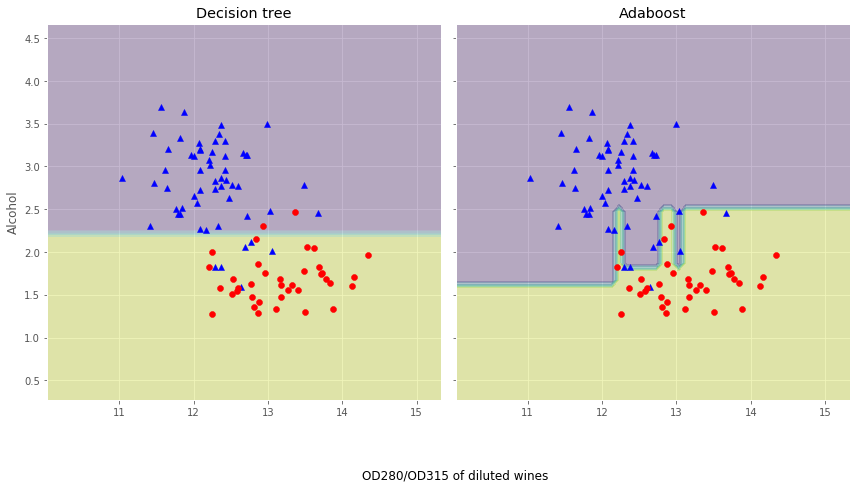
������ľ��߽߱�ͼ���Կ���:Adaboostģ�͵ľ��߽߱�ȵ���������ľ��߽߱�Ҫ���ӵĶࡣҲ����˵,Adaboost��ͼ������ģ���Ӷȶ�����ƫ��ķ�ʽȥ���������,���ǹ����������˷���,���ܳ��ֹ����,�����ѵ�����Ͳ��Լ�֮������ܴ��ڽϴ�IJ��,��ͼػش�ĸո����⡣ֵ��ע�����:�뵥�����������,Adaboost��Boostingģ�������˼���ĸ��Ӷ�,��ʵ������Ҫ��ϸ˼���Ƿ�Ը��ΪԤ�����ܵ���Ը��ƶ����Ӽ���ɱ�,����Boosting��ʽ�������������еIJ��м���ķ�ʽ����ѵ��,��Ϊÿһ��������Ҫ������һ���Ļ�����������
����ǰ��ֲ��㷨
�ؿ�Adaboost���㷨����,������Ҫͨ������M������������,ÿ���������Ĵ����ʡ�����Ȩ���Լ�ģ��Ȩ�ء����ǿ�����Ϊ:Adaboostÿ��ѧϰ��һ�������Լ���һ�������IJ���(Ȩ��)��������,���dz����Adaboost�㷨����������,��������ѧϰ��һ���dz���Ҫ�Ŀ��----ǰ��ֲ��㷨,����������,���Dz������Խ����������,Ҳ���Խ���ع����⡣
(1) �ӷ�ģ��:
��Adaboostģ����,���ǰ�ÿ�������������ϳ�һ�����ӷ������ķ�����ÿ�������������ļ�Ȩ��,��:
f
(
x
)
=
��
m
=
1
M
��
m
b
(
x
;
��
m
)
f(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right)
f(x)=��m=1M?��m?b(x;��m?),����,
b
(
x
;
��
m
)
b\left(x ; \gamma_{m}\right)
b(x;��m?)������������,
��
m
\gamma_{m}
��m?�����������IJ���,
��
m
\beta_m
��m?Ϊ������������Ȩ��,��Ȼ����ڶ�����ѧ�ļӷ�ģ�͡�Ϊʲô��ô˵��?��Ұ�
b
(
x
;
��
m
)
b(x ; \gamma_{m})
b(x;��m?)�����Ǽ��������ɡ�
�ڸ���ѵ�������Լ���ʧ����
L
(
y
,
f
(
x
)
)
L(y, f(x))
L(y,f(x))��������,ѧϰ�ӷ�ģ��
f
(
x
)
f(x)
f(x)����:
min
?
��
m
,
��
m
��
i
=
1
N
L
(
y
i
,
��
m
=
1
M
��
m
b
(
x
i
;
��
m
)
)
\min _{\beta_{m}, \gamma_{m}} \sum_{i=1}^{N} L\left(y_{i}, \sum_{m=1}^{M} \beta_{m} b\left(x_{i} ; \gamma_{m}\right)\right)
��m?,��m?min?i=1��N?L(yi?,m=1��M?��m?b(xi?;��m?))
ͨ������һ�����ӵ��Ż�����,����ͨ�����Ż������֪ʶ���н����ǰ��ֲ��㷨��������������ַ�ʽ������,���Ļ���˼·��:��Ϊѧϰ���Ǽӷ�ģ��,�����ǰ���,ÿһ��ֻ�Ż�һ������������ϵ��,�ƽ�Ŀ�꺯��,��ô�Ϳ��Խ����Ż��ĸ��Ӷȡ��������,ÿһ��ֻ��Ҫ�Ż�:
min
?
��
,
��
��
i
=
1
N
L
(
y
i
,
��
b
(
x
i
;
��
)
)
\min _{\beta, \gamma} \sum_{i=1}^{N} L\left(y_{i}, \beta b\left(x_{i} ; \gamma\right)\right)
��,��min?i=1��N?L(yi?,��b(xi?;��))
(2) ǰ��ֲ��㷨:
�������ݼ�
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
?
?
,
(
x
N
,
y
N
)
}
T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\}
T={(x1?,y1?),(x2?,y2?),?,(xN?,yN?)},
x
i
��
X
?
R
n
x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}
xi?��X?Rn,
y
i
��
Y
=
{
+
1
,
?
1
}
y_{i} \in \mathcal{Y}=\{+1,-1\}
yi?��Y={+1,?1}����ʧ����
L
(
y
,
f
(
x
)
)
L(y, f(x))
L(y,f(x)),����������
{
b
(
x
;
��
)
}
\{b(x ; \gamma)\}
{b(x;��)},������Ҫ����ӷ�ģ��
f
(
x
)
f(x)
f(x)��
- ��ʼ��: f 0 ( x ) = 0 f_{0}(x)=0 f0?(x)=0
- ��m = 1,2,��,M:
- (a) ��С����ʧ����:
( �� m , �� m ) = arg ? min ? �� , �� �� i = 1 N L ( y i , f m ? 1 ( x i ) + �� b ( x i ; �� ) ) \left(\beta_{m}, \gamma_{m}\right)=\arg \min _{\beta, \gamma} \sum_{i=1}^{N} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+\beta b\left(x_{i} ; \gamma\right)\right) (��m?,��m?)=arg��,��min?i=1��N?L(yi?,fm?1?(xi?)+��b(xi?;��))
�õ����� �� m \beta_{m} ��m?�� �� m \gamma_{m} ��m? - (b) ����:
f m ( x ) = f m ? 1 ( x ) + �� m b ( x ; �� m ) f_{m}(x)=f_{m-1}(x)+\beta_{m} b\left(x ; \gamma_{m}\right) fm?(x)=fm?1?(x)+��m?b(x;��m?)
- (a) ��С����ʧ����:
- �õ��ӷ�ģ��:
f ( x ) = f M ( x ) = �� m = 1 M �� m b ( x ; �� m ) f(x)=f_{M}(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right) f(x)=fM?(x)=m=1��M?��m?b(x;��m?)
����,ǰ��ֲ��㷨��ͬʱ����m=1��M�����в���
��
m
\beta_{m}
��m?,
��
m
\gamma_{m}
��m?���Ż������Ϊ���������
��
m
\beta_{m}
��m?,
��
m
\gamma_{m}
��m?�����⡣
(3) ǰ��ֲ��㷨��Adaboost�Ĺ�ϵ:
Adaboost�㷨��ǰ��ֲ��㷨������,Adaboost�㷨���ɻ�����������ɵļӷ�ģ��,��ʧ����Ϊָ����ʧ������
�ġ��ݶ�����������(GBDT)
1������ԭ��
(1) ���ڲв�ѧϰ���������㷨:
��ǰ���ѧϰ������,����һֱ���۵Ķ��Ƿ�����,����Adaboost�㷨,��û���漰�ع�����ӡ�����һС�������ᵽ��һ���ӷ�ģ��+ǰ��ֲ��㷨�Ŀ��,���ܷ�ʹ�������ܽ���ع��������?���ǿ϶��ġ�������������̽�������ʹ�üӷ�ģ��+ǰ��ֲ��㷨�Ŀ��ʵ�ֻع����⡣
��ʹ�üӷ�ģ��+ǰ��ֲ��㷨�Ŀ�ܽ������֮ǰ,������Ҫ����ȷ�������ʹ�õĻ�������ʲô,����������ʹ�þ�������������ǰ��ڶ��������Ѿ�ѧ���˻ع����Ļ���ԭ��,���㷨����Ҫ��Ѱ����ѵĻ��ֵ�,�������ô������ж���ѻ��ֵ�ʹ����Ϣ����(ID3�㷨),��Ϣ�����(C4.5�㷨),����ϵ��(CART������)�������ڻع����е�������ǩ��������ֵ,�ɻ��ֵ�������������������п�ȡ��ֵ��������ʹ����֮���ָ�겻�ٺ���,ȡ����֮����ƽ�����,���ܺܺõ�������ϳ̶ȡ�������ȷ�����Ժ�,������Ҫȷ��ÿ�������ı���ʲô������Adaboost�㷨,��Adaboost�㷨��ʹ���˷����������������Ȩ���Լ�����ÿ��������������Ȩ��,�ǻع�����û�з�������ʿ���,Ҳ��û�취������Ļع�����ʹ����,���������Ҫ�����辶��ģ�·��������,������ÿ�������IJв��ʾÿ��ʹ�û�����Ԥ��ʱû�н�����Dz������⡣���,���ǿ��Եó������㷨:
�������ݼ�
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
?
?
,
(
x
N
,
y
N
)
}
,
x
i
��
X
?
R
n
,
y
i
��
Y
?
R
T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\}, x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y_{i} \in \mathcal{Y} \subseteq \mathbf{R}
T={(x1?,y1?),(x2?,y2?),?,(xN?,yN?)},xi?��X?Rn,yi?��Y?R,������յ�������
f
M
(
x
)
f_{M}(x)
fM?(x)
- ��ʼ�� f 0 ( x ) = 0 f_0(x) = 0 f0?(x)=0
- ��m = 1,2,��,M:
- ����ÿ�������IJв�: r m i = y i ? f m ? 1 ( x i ) , i = 1 , 2 , ? ? , N r_{m i}=y_{i}-f_{m-1}\left(x_{i}\right), \quad i=1,2, \cdots, N rmi?=yi??fm?1?(xi?),i=1,2,?,N
- ��ϲв� r m i r_{mi} rmi?ѧϰһ�ûع���,�õ� T ( x ; �� m ) T\left(x ; \Theta_{m}\right) T(x;��m?)
- ���� f m ( x ) = f m ? 1 ( x ) + T ( x ; �� m ) f_{m}(x)=f_{m-1}(x)+T\left(x ; \Theta_{m}\right) fm?(x)=fm?1?(x)+T(x;��m?)
- �õ����յĻع������������: f M ( x ) = �� m = 1 M T ( x ; �� m ) f_{M}(x)=\sum_{m=1}^{M} T\left(x ; \Theta_{m}\right) fM?(x)=��m=1M?T(x;��m?)
����,�����Ѿ��ܹ������������ӷ�ģ��+ǰ��ֲ��㷨�Ŀ�ܽ���ع�������㷨,���������㷨����ô,����㷨���Ƿ��������Ŀռ���?
(2) �ݶ������������㷨(GBDT):
���������üӷ�ģ�ͺ�ǰ��ֲ��㷨ʵ��ѧϰ�Ĺ���,����ʧ����Ϊƽ����ʧ��ָ����ʧʱ,ÿһ���Ż����൱��,Ҳ��������ǰ��̽�ֵ��������㷨��Adaboost�㷨�����Ƕ���һ�����ʧ��������,����ÿһ�����Ż�������ô����,�����һ����,���ǵ÷�������ı���,Ҳ������ʲô��������һ����ʧ���������µ�ѧϰ���ѡ��Ա�������ʧ����:
?Setting?
?Loss?Function?
?
?
L
(
y
i
,
f
(
x
i
)
)
/
?
f
(
x
i
)
?Regression?
1
2
[
y
i
?
f
(
x
i
)
]
2
y
i
?
f
(
x
i
)
?Regression?
�O
y
i
?
f
(
x
i
)
�O
sign
?
[
y
i
?
f
(
x
i
)
]
?Regression?
?Huber?
y
i
?
f
(
x
i
)
?for?
�O
y
i
?
f
(
x
i
)
�O
��
��
m
��
m
sign
?
[
y
i
?
f
(
x
i
)
]
?for?
�O
y
i
?
f
(
x
i
)
�O
>
��
m
?where?
��
m
=
��
?th-quantile?
{
�O
y
i
?
f
(
x
i
)
�O
}
?Classification?
?Deviance?
k
?th?component:?
I
(
y
i
=
G
k
)
?
p
k
(
x
i
)
\begin{array}{l|l|l} \hline \text { Setting } & \text { Loss Function } & -\partial L\left(y_{i}, f\left(x_{i}\right)\right) / \partial f\left(x_{i}\right) \\ \hline \text { Regression } & \frac{1}{2}\left[y_{i}-f\left(x_{i}\right)\right]^{2} & y_{i}-f\left(x_{i}\right) \\ \hline \text { Regression } & \left|y_{i}-f\left(x_{i}\right)\right| & \operatorname{sign}\left[y_{i}-f\left(x_{i}\right)\right] \\ \hline \text { Regression } & \text { Huber } & y_{i}-f\left(x_{i}\right) \text { for }\left|y_{i}-f\left(x_{i}\right)\right| \leq \delta_{m} \\ & & \delta_{m} \operatorname{sign}\left[y_{i}-f\left(x_{i}\right)\right] \text { for }\left|y_{i}-f\left(x_{i}\right)\right|>\delta_{m} \\ & & \text { where } \delta_{m}=\alpha \text { th-quantile }\left\{\left|y_{i}-f\left(x_{i}\right)\right|\right\} \\ \hline \text { Classification } & \text { Deviance } & k \text { th component: } I\left(y_{i}=\mathcal{G}_{k}\right)-p_{k}\left(x_{i}\right) \\ \hline \end{array}
?Setting??Regression??Regression??Regression??Classification???Loss?Function?21?[yi??f(xi?)]2�Oyi??f(xi?)�O?Huber??Deviance????L(yi?,f(xi?))/?f(xi?)yi??f(xi?)sign[yi??f(xi?)]yi??f(xi?)?for?�Oyi??f(xi?)�O����m?��m?sign[yi??f(xi?)]?for?�Oyi??f(xi?)�O>��m??where?��m?=��?th-quantile?{�Oyi??f(xi?)�O}k?th?component:?I(yi?=Gk?)?pk?(xi?)??
�۲�Huber��ʧ����:
L
��
(
y
,
f
(
x
)
)
=
{
1
2
(
y
?
f
(
x
)
)
2
?for?
�O
y
?
f
(
x
)
�O
��
��
��
�O
y
?
f
(
x
)
�O
?
1
2
��
2
?otherwise?
L_{\delta}(y, f(x))=\left\{\begin{array}{ll} \frac{1}{2}(y-f(x))^{2} & \text { for }|y-f(x)| \leq \delta \\ \delta|y-f(x)|-\frac{1}{2} \delta^{2} & \text { otherwise } \end{array}\right.
L��?(y,f(x))={21?(y?f(x))2���Oy?f(x)�O?21?��2??for?�Oy?f(x)�O����?otherwise??
������������,Freidman������ݶ������㷨(gradient boosting),�������������½����Ľ��Ʒ���,������ʧ�����ĸ��ݶ��ڵ�ǰģ�͵�ֵ
?
[
?
L
(
y
,
f
(
x
i
)
)
?
f
(
x
i
)
]
f
(
x
)
=
f
m
?
1
(
x
)
-\left[\frac{\partial L\left(y, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]_{f(x)=f_{m-1}(x)}
?[?f(xi?)?L(y,f(xi?))?]f(x)=fm?1?(x)?��Ϊ�ع������������㷨�еIJв�Ľ���ֵ,��ϻع���������˵���ݶ���Ϊ�в�Ľ���ֵ,����˵�в��Ǹ��ݶȵ�һ��������
���¿�ʼ��������ݶ������㷨:
����ѵ�����ݼ�
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
?
?
,
(
x
N
,
y
N
)
}
,
x
i
��
X
?
R
n
,
y
i
��
Y
?
R
T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\}, x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y_{i} \in \mathcal{Y} \subseteq \mathbf{R}
T={(x1?,y1?),(x2?,y2?),?,(xN?,yN?)},xi?��X?Rn,yi?��Y?R����ʧ����
L
(
y
,
f
(
x
)
)
L(y, f(x))
L(y,f(x)),����ع���
f
^
(
x
)
\hat{f}(x)
f^?(x)
- ��ʼ�� f 0 ( x ) = arg ? min ? c �� i = 1 N L ( y i , c ) f_{0}(x)=\arg \min _{c} \sum_{i=1}^{N} L\left(y_{i}, c\right) f0?(x)=argminc?��i=1N?L(yi?,c)
- ����m=1,2,��,M:
- ��i = 1,2,��,N����: r m i = ? [ ? L ( y i , f ( x i ) ) ? f ( x i ) ] f ( x ) = f m ? 1 ( x ) r_{m i}=-\left[\frac{\partial L\left(y_{i}, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]_{f(x)=f_{m-1}(x)} rmi?=?[?f(xi?)?L(yi?,f(xi?))?]f(x)=fm?1?(x)?
- �� r m i r_{mi} rmi?���һ���ع���,�õ���m������Ҷ������� R m j , j = 1 , 2 , ? ? , J R_{m j}, j=1,2, \cdots, J Rmj?,j=1,2,?,J
- ��j=1,2,��J,����: c m j = arg ? min ? c �� x i �� R m j L ( y i , f m ? 1 ( x i ) + c ) c_{m j}=\arg \min _{c} \sum_{x_{i} \in R_{m j}} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+c\right) cmj?=argminc?��xi?��Rmj??L(yi?,fm?1?(xi?)+c)
- ���� f m ( x ) = f m ? 1 ( x ) + �� j = 1 J c m j I ( x �� R m j ) f_{m}(x)=f_{m-1}(x)+\sum_{j=1}^{J} c_{m j} I\left(x \in R_{m j}\right) fm?(x)=fm?1?(x)+��j=1J?cmj?I(x��Rmj?)
- �õ��ع���: f ^ ( x ) = f M ( x ) = �� m = 1 M �� j = 1 J c m j I ( x �� R m j ) \hat{f}(x)=f_{M}(x)=\sum_{m=1}^{M} \sum_{j=1}^{J} c_{m j} I\left(x \in R_{m j}\right) f^?(x)=fM?(x)=��m=1M?��j=1J?cmj?I(x��Rmj?)
2��ʹ��sklearn��ʹ��GBDT
����������ʹ��sklearn��ʹ��GBDT:
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html#sklearn.ensemble.GradientBoostingRegressor
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html?highlight=gra#sklearn.ensemble.GradientBoostingClassifier
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
'''
GradientBoostingRegressor��������:
loss:{��ls��, ��lad��, ��huber��, ��quantile��}, default=��ls��:��ls�� ָ��С���˻ع�. ��lad�� (��С����ƫ��) �ǽ��������������˳����Ϣ�ĸ߶�³������ʧ������. ��huber�� �����ߵĽ��. ��quantile��������λ���ع�(����alphaָ����λ��)
learning_rate:ѧϰ����С��ÿ�����Ĺ���learning_rate����learning_rate��n_estimators֮����ҪȨ�⡣
n_estimators:Ҫִ�е���������������ٺ�ƫ�����ӡ�subsample < 1.0
subsample:������ϸ�������ѧϰ�ߵ��������������С��1.0,��������ݶ���ǿ��subsample�����n_estimators��ѡ��ᵼ�·�
criterion:{'friedman_mse','mse','mae'},Ĭ��='friedman_mse':�� mse���Ǿ������,�� mae����ƽ��������Ĭ��ֵ�� friedman_mse��ͨ������õ�,��Ϊ��ijЩ������������ṩ���õĽ���ֵ��
min_samples_split:����ڲ��ڵ����������������
min_samples_leaf:��Ҷ�ڵ㴦��Ҫ����С��������
min_weight_fraction_leaf:������Ҷ�ڵ㴦(������������)��Ȩ���ܺ��е���С��Ȩ���������δ�ṩsample_weight,��������Ȩ����ȡ�
max_depth:�����ع�ģ�͵������ȡ����������������нڵ�������������˲����Ի���������;���ֵȡ�����������������á�
min_impurity_decrease:����ڵ���ѻᵼ�����ʵļ��ٴ��ڻ���ڸ�ֵ,��ýڵ㽫�����ѡ�
min_impurity_split:��ǰֹͣ��ľ��������ֵ������ڵ�����ʸ�����ֵ,��ýڵ㽫����
max_features{��auto��, ��sqrt��, ��log2��},int��float:Ѱ����ѷָ�ʱҪ���ǵĹ�������:
���Ϊint,��max_features��ÿ���ָ����������
���Ϊfloat,max_features��ΪС��,�� ��ÿ�β��ʱ����Ҫ�ء�int(max_features * n_features)
�����auto��,��max_features=n_features��
����ǡ� sqrt��,��max_features=sqrt(n_features)��
���Ϊ�� log2��,��Ϊmax_features=log2(n_features)��
���û��,��max_features=n_features��
'''
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
est = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,
max_depth=1, random_state=0, loss='ls').fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))
5.009154859960321
from sklearn.datasets import make_regression
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
X, y = make_regression(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=0)
reg = GradientBoostingRegressor(random_state=0)
reg.fit(X_train, y_train)
reg.score(X_test, y_test)
0.43848663277068134
�塢XGBoost�㷨
1������ԭ��
XGBoost�dz�������˿�����һ����Դ����ѧϰ��Ŀ,��Ч��ʵ����GBDT�㷨���������㷨�����ϵ�����Ľ�,���㷺Ӧ����Kaggle�����������������ѧϰ�����в�ȡ���˲����ijɼ���XGBoost�����ϻ���һ��GBDT,�����������ٶȺ�Ч�ʷ��ӵ�����,���Խ�X (Extreme) GBoosted,����ǰ��˵��,���߶���boosting������XGBoost��һ���Ż��ķֲ�ʽ�ݶ���ǿ��,ּ��ʵ�ָ�Ч,���ͱ�Я�� ����Gradient Boosting�����ʵ�ֻ���ѧϰ�㷨�� XGBoost�ṩ�˲���������(Ҳ��ΪGBDT,GBM),���Կ���ȷ�ؽ���������ݿ�ѧ���⡣ ��ͬ�Ĵ�������Ҫ�ķֲ�ʽ����(Hadoop,SGE,MPI)������,���ҿ��Խ��������ʮ�ڸ����������⡣XGBoost�����˺�����㲢���ܹ�ʹ���ݿ�ѧ����һ�������ϴ������ڵ��������ݡ�����,����Щ�������н������һ���˵��˵�ϵͳ�����ٵļ�Ⱥϵͳ����չ����������ݼ��ϡ�Xgboost��CART������Ϊ��ģ��,ͨ��Gradient Tree Boostingʵ�ֶ��CART���ļ���ѧϰ,�õ�����ģ�͡���������������XGBoost������ģ����:
���ó����������,���ǵ�����Ϊ:
D
=
{
(
x
i
,
y
i
)
}
(
�O
D
�O
=
n
,
x
i
��
R
m
,
y
i
��
R
)
\mathcal{D}=\left\{\left(\mathbf{x}_{i}, y_{i}\right)\right\}\left(|\mathcal{D}|=n, \mathbf{x}_{i} \in \mathbb{R}^{m}, y_{i} \in \mathbb{R}\right)
D={(xi?,yi?)}(�OD�O=n,xi?��Rm,yi?��R)
**(1) ����Ŀ�꺯��: **
������K����,���i�����������Ϊ
y
^
i
=
?
(
x
i
)
=
��
k
=
1
K
f
k
(
x
i
)
,
f
k
��
F
\hat{y}_{i}=\phi\left(\mathrm{x}_{i}\right)=\sum_{k=1}^{K} f_{k}\left(\mathrm{x}_{i}\right), \quad f_{k} \in \mathcal{F}
y^?i?=?(xi?)=��k=1K?fk?(xi?),fk?��F,����,
F
=
{
f
(
x
)
=
w
q
(
x
)
}
(
q
:
R
m
��
T
,
w
��
R
T
)
\mathcal{F}=\left\{f(\mathbf{x})=w_{q(\mathbf{x})}\right\}\left(q: \mathbb{R}^{m} \rightarrow T, w \in \mathbb{R}^{T}\right)
F={f(x)=wq(x)?}(q:Rm��T,w��RT)
���,Ŀ�꺯���Ĺ���Ϊ:
L
(
?
)
=
��
i
l
(
y
^
i
,
y
i
)
+
��
k
��
(
f
k
)
\mathcal{L}(\phi)=\sum_{i} l\left(\hat{y}_{i}, y_{i}\right)+\sum_{k} \Omega\left(f_{k}\right)
L(?)=i��?l(y^?i?,yi?)+k��?��(fk?)
����,
��
i
l
(
y
^
i
,
y
i
)
\sum_{i} l\left(\hat{y}_{i}, y_{i}\right)
��i?l(y^?i?,yi?)Ϊloss function,
��
k
��
(
f
k
)
\sum_{k} \Omega\left(f_{k}\right)
��k?��(fk?)�����
(2) ����ʽ��ѵ��(Additive Training):
��������
x
i
x_i
xi?,
y
^
i
(
0
)
=
0
\hat{y}_i^{(0)} = 0
y^?i(0)?=0(��ʼԤ��),
y
^
i
(
1
)
=
y
^
i
(
0
)
+
f
1
(
x
i
)
\hat{y}_i^{(1)} = \hat{y}_i^{(0)} + f_1(x_i)
y^?i(1)?=y^?i(0)?+f1?(xi?),
y
^
i
(
2
)
=
y
^
i
(
0
)
+
f
1
(
x
i
)
+
f
2
(
x
i
)
=
y
^
i
(
1
)
+
f
2
(
x
i
)
\hat{y}_i^{(2)} = \hat{y}_i^{(0)} + f_1(x_i) + f_2(x_i) = \hat{y}_i^{(1)} + f_2(x_i)
y^?i(2)?=y^?i(0)?+f1?(xi?)+f2?(xi?)=y^?i(1)?+f2?(xi?)���Դ�����,���Եõ�:$ \hat{y}_i^{(K)} = \hat{y}_i^{(K-1)} + f_K(x_i)$ ,����,$ \hat{y}_i^{(K-1)} $ ΪǰK-1������Ԥ����,$ f_K(x_i)$ Ϊ��K������Ԥ������
���,Ŀ�꺯�����Էֽ�Ϊ:
L
(
K
)
=
��
i
=
1
n
l
(
y
i
,
y
^
i
(
K
?
1
)
+
f
K
(
x
i
)
)
+
��
k
��
(
f
k
)
\mathcal{L}^{(K)}=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}_{i}^{(K-1)}+f_{K}\left(\mathrm{x}_{i}\right)\right)+\sum_{k} \Omega\left(f_{k}\right)
L(K)=i=1��n?l(yi?,y^?i(K?1)?+fK?(xi?))+k��?��(fk?)
����������Ҳ���Էֽ�ΪǰK-1�����ĸ��Ӷȼӵ�K�����ĸ��Ӷ�,���:
L
(
K
)
=
��
i
=
1
n
l
(
y
i
,
y
^
i
(
K
?
1
)
+
f
K
(
x
i
)
)
+
��
k
=
1
K
?
1
��
(
f
k
)
+
��
(
f
K
)
\mathcal{L}^{(K)}=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}_{i}^{(K-1)}+f_{K}\left(\mathrm{x}_{i}\right)\right)+\sum_{k=1} ^{K-1}\Omega\left(f_{k}\right)+\Omega\left(f_{K}\right)
L(K)=��i=1n?l(yi?,y^?i(K?1)?+fK?(xi?))+��k=1K?1?��(fk?)+��(fK?),����
��
k
=
1
K
?
1
��
(
f
k
)
\sum_{k=1} ^{K-1}\Omega\left(f_{k}\right)
��k=1K?1?��(fk?)��ģ��������K������ʱ���Ѿ��̶�,���ı�,�����һ����֪�ij���,���������Ż���ʱ��ʡȥ,��:
L
(
K
)
=
��
i
=
1
n
l
(
y
i
,
y
^
i
(
K
?
1
)
+
f
K
(
x
i
)
)
+
��
(
f
K
)
\mathcal{L}^{(K)}=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}_{i}^{(K-1)}+f_{K}\left(\mathrm{x}_{i}\right)\right)+\Omega\left(f_{K}\right)
L(K)=i=1��n?l(yi?,y^?i(K?1)?+fK?(xi?))+��(fK?)
(3) ʹ��̩�ռ�������Ŀ�꺯��:
L
(
K
)
?
��
i
=
1
n
[
l
(
y
i
,
y
^
(
K
?
1
)
)
+
g
i
f
K
(
x
i
)
+
1
2
h
i
f
K
2
(
x
i
)
]
+
��
(
f
K
)
\mathcal{L}^{(K)} \simeq \sum_{i=1}^{n}\left[l\left(y_{i}, \hat{y}^{(K-1)}\right)+g_{i} f_{K}\left(\mathrm{x}_{i}\right)+\frac{1}{2} h_{i} f_{K}^{2}\left(\mathrm{x}_{i}\right)\right]+\Omega\left(f_{K}\right)
L(K)?i=1��n?[l(yi?,y^?(K?1))+gi?fK?(xi?)+21?hi?fK2?(xi?)]+��(fK?)
����,
g
i
=
?
y
^
(
t
?
1
)
l
(
y
i
,
y
^
(
t
?
1
)
)
g_{i}=\partial_{\hat{y}(t-1)} l\left(y_{i}, \hat{y}^{(t-1)}\right)
gi?=?y^?(t?1)?l(yi?,y^?(t?1))��
h
i
=
?
y
^
(
t
?
1
)
2
l
(
y
i
,
y
^
(
t
?
1
)
)
h_{i}=\partial_{\hat{y}^{(t-1)}}^{2} l\left(y_{i}, \hat{y}^{(t-1)}\right)
hi?=?y^?(t?1)2?l(yi?,y^?(t?1))
������,���Dz�����̩�ռ��������֪ʶ:
����ѧ��,̩�ռ���(Ӣ��:Taylor series)������������ʽ������������ʾһ������,��Щ��ӵ����ɺ�����ijһ��ĵ�����á��������ʽ����:
f
(
x
)
=
f
(
x
0
)
0
!
+
f
��
(
x
0
)
1
!
(
x
?
x
0
)
+
f
��
��
(
x
0
)
2
!
(
x
?
x
0
)
2
+
��
+
f
(
n
)
(
x
0
)
n
!
(
x
?
x
0
)
n
+
.
.
.
.
.
.
f(x)=\frac{f\left(x_{0}\right)}{0 !}+\frac{f^{\prime}\left(x_{0}\right)}{1 !}\left(x-x_{0}\right)+\frac{f^{\prime \prime}\left(x_{0}\right)}{2 !}\left(x-x_{0}\right)^{2}+\ldots+\frac{f^{(n)}\left(x_{0}\right)}{n !}\left(x-x_{0}\right)^{n}+......
f(x)=0!f(x0?)?+1!f��(x0?)?(x?x0?)+2!f����(x0?)?(x?x0?)2+��+n!f(n)(x0?)?(x?x0?)n+......
����
��
i
=
1
n
l
(
y
i
,
y
^
(
K
?
1
)
)
\sum_{i=1}^{n}l\left(y_{i}, \hat{y}^{(K-1)}\right)
��i=1n?l(yi?,y^?(K?1))��ģ��������K������ʱ���Ѿ��̶�,���ı�,�����һ����֪�ij���,���������Ż���ʱ��ʡȥ,��:
L
~
(
K
)
=
��
i
=
1
n
[
g
i
f
K
(
x
i
)
+
1
2
h
i
f
K
2
(
x
i
)
]
+
��
(
f
K
)
\tilde{\mathcal{L}}^{(K)}=\sum_{i=1}^{n}\left[g_{i} f_{K}\left(\mathbf{x}_{i}\right)+\frac{1}{2} h_{i} f_{K}^{2}\left(\mathbf{x}_{i}\right)\right]+\Omega\left(f_{K}\right)
L~(K)=i=1��n?[gi?fK?(xi?)+21?hi?fK2?(xi?)]+��(fK?)
(4) ��ζ���һ����:
Ϊ��˵����ζ���һ����������,������Ҫ���弸������:��һ���������������ڵĽڵ�λ��
q
(
x
)
q(x)
q(x),�ڶ�������������Щ�������ڽڵ�j��
I
j
=
{
i
�O
q
(
x
i
)
=
j
}
I_{j}=\left\{i \mid q\left(\mathbf{x}_{i}\right)=j\right\}
Ij?={i�Oq(xi?)=j},������������ÿ������Ԥ��ֵ
w
q
(
x
)
w_{q(x)}
wq(x)?,���ĸ�������ģ���Ӷ�
��
(
f
K
)
\Omega\left(f_{K}\right)
��(fK?),��������Ҷ�ӽڵ�ĸ����Լ��ڵ㺯��ֵ������,��:
��
(
f
K
)
=
��
T
+
1
2
��
��
j
=
1
T
w
j
2
\Omega\left(f_{K}\right) = \gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2}
��(fK?)=��T+21?����j=1T?wj2?������ͼ������:
q
(
x
1
)
=
1
,
q
(
x
2
)
=
3
,
q
(
x
3
)
=
1
,
q
(
x
4
)
=
2
,
q
(
x
5
)
=
3
q(x_1) = 1,q(x_2) = 3,q(x_3) = 1,q(x_4) = 2,q(x_5) = 3
q(x1?)=1,q(x2?)=3,q(x3?)=1,q(x4?)=2,q(x5?)=3,
I
1
=
{
1
,
3
}
,
I
2
=
{
4
}
,
I
3
=
{
2
,
5
}
I_1 = \{1,3\},I_2 = \{4\},I_3 = \{2,5\}
I1?={1,3},I2?={4},I3?={2,5},
w
=
(
15
,
12
,
20
)
w = (15,12,20)
w=(15,12,20)
���,Ŀ�꺯�������Ϸ��������:
L
~
(
K
)
=
��
i
=
1
n
[
g
i
f
K
(
x
i
)
+
1
2
h
i
f
K
2
(
x
i
)
]
+
��
T
+
1
2
��
��
j
=
1
T
w
j
2
=
��
j
=
1
T
[
(
��
i
��
I
j
g
i
)
w
j
+
1
2
(
��
i
��
I
j
h
i
+
��
)
w
j
2
]
+
��
T
\begin{aligned} \tilde{\mathcal{L}}^{(K)} &=\sum_{i=1}^{n}\left[g_{i} f_{K}\left(\mathrm{x}_{i}\right)+\frac{1}{2} h_{i} f_{K}^{2}\left(\mathrm{x}_{i}\right)\right]+\gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2} \\ &=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T \end{aligned}
L~(K)?=i=1��n?[gi?fK?(xi?)+21?hi?fK2?(xi?)]+��T+21?��j=1��T?wj2?=j=1��T???????i��Ij?��?gi????wj?+21????i��Ij?��?hi?+��???wj2????+��T?
�������ǵ�Ŀ�������С��Ŀ�꺯��,���ڵ�Ŀ�꺯������Ϊһ������w�Ķ��κ���:
L
~
(
K
)
=
��
j
=
1
T
[
(
��
i
��
I
j
g
i
)
w
j
+
1
2
(
��
i
��
I
j
h
i
+
��
)
w
j
2
]
+
��
T
\tilde{\mathcal{L}}^{(K)}=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T
L~(K)=��j=1T?[(��i��Ij??gi?)wj?+21?(��i��Ij??hi?+��)wj2?]+��T,���ݶ��κ�����ֵ�Ĺ�ʽ:
y
=
a
x
2
b
x
c
y=ax^2 bx c
y=ax2bxc��ֵ,�Գ�����
x
=
?
b
2
a
x=-\frac{b}{2 a}
x=?2ab?,��ֵΪ
y
=
4
a
c
?
b
2
4
a
y=\frac{4 a c-b^{2}}{4 a}
y=4a4ac?b2?,���:
w
j
?
=
?
��
i
��
I
j
g
i
��
i
��
I
j
h
i
+
��
w_{j}^{*}=-\frac{\sum_{i \in I_{j}} g_{i}}{\sum_{i \in I_{j}} h_{i}+\lambda}
wj??=?��i��Ij??hi?+����i��Ij??gi??
�Լ�
L
~
(
K
)
(
q
)
=
?
1
2
��
j
=
1
T
(
��
i
��
I
j
g
i
)
2
��
i
��
I
j
h
i
+
��
+
��
T
\tilde{\mathcal{L}}^{(K)}(q)=-\frac{1}{2} \sum_{j=1}^{T} \frac{\left(\sum_{i \in I_{j}} g_{i}\right)^{2}}{\sum_{i \in I_{j}} h_{i}+\lambda}+\gamma T
L~(K)(q)=?21?j=1��T?��i��Ij??hi?+��(��i��Ij??gi?)2?+��T
(5) ���Ѱ��������״:
���ѷ���,�ոյ����۶��ǻ���������״�Ѿ�ȷ���˼���
w
w
w��
L
L
L,����ʵ����������Ҫ��ѧϰ������һ���ҵ�������״�����,���ǽ���������ѧϰ�ķ�ʽ,ʹ��Ŀ�꺯���ı仯����Ϊ���ѽڵ�ı�������ʹ��һ��������˵��:
��������8������,���ѷ�ʽ����,���:
L
~
(
o
l
d
)
=
?
1
2
[
(
g
7
+
g
8
)
2
H
7
+
H
8
+
��
+
(
g
1
+
.
.
.
+
g
6
)
2
H
1
+
.
.
.
+
H
6
+
��
]
+
2
��
L
~
(
n
e
w
)
=
?
1
2
[
(
g
7
+
g
8
)
2
H
7
+
H
8
+
��
+
(
g
1
+
.
.
.
+
g
3
)
2
H
1
+
.
.
.
+
H
3
+
��
+
(
g
4
+
.
.
.
+
g
6
)
2
H
4
+
.
.
.
+
H
6
+
��
]
+
3
��
L
~
(
o
l
d
)
?
L
~
(
n
e
w
)
=
1
2
[
(
g
1
+
.
.
.
+
g
3
)
2
H
1
+
.
.
.
+
H
3
+
��
+
(
g
4
+
.
.
.
+
g
6
)
2
H
4
+
.
.
.
+
H
6
+
��
?
(
g
1
+
.
.
.
+
g
6
)
2
h
1
+
.
.
.
+
h
6
+
��
]
?
��
\tilde{\mathcal{L}}^{(old)} = -\frac{1}{2}[\frac{(g_7 + g_8)^2}{H_7+H_8 + \lambda} + \frac{(g_1 +...+ g_6)^2}{H_1+...+H_6 + \lambda}] + 2\gamma \\ \tilde{\mathcal{L}}^{(new)} = -\frac{1}{2}[\frac{(g_7 + g_8)^2}{H_7+H_8 + \lambda} + \frac{(g_1 +...+ g_3)^2}{H_1+...+H_3 + \lambda} + \frac{(g_4 +...+ g_6)^2}{H_4+...+H_6 + \lambda}] + 3\gamma\\ \tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} = \frac{1}{2}[ \frac{(g_1 +...+ g_3)^2}{H_1+...+H_3 + \lambda} + \frac{(g_4 +...+ g_6)^2}{H_4+...+H_6 + \lambda} - \frac{(g_1+...+g_6)^2}{h_1+...+h_6+\lambda}] - \gamma
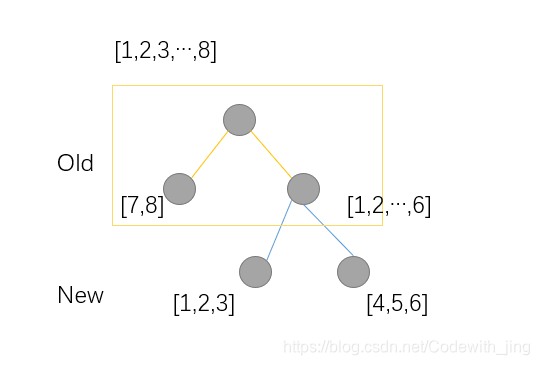
L~(old)=?21?[H7?+H8?+��(g7?+g8?)2?+H1?+...+H6?+��(g1?+...+g6?)2?]+2��L~(new)=?21?[H7?+H8?+��(g7?+g8?)2?+H1?+...+H3?+��(g1?+...+g3?)2?+H4?+...+H6?+��(g4?+...+g6?)2?]+3��L~(old)?L~(new)=21?[H1?+...+H3?+��(g1?+...+g3?)2?+H4?+...+H6?+��(g4?+...+g6?)2??h1?+...+h6?+��(g1?+...+g6?)2?]?��
���,����������ӿ���:�ָ�ڵ�ı�Ϊ
m
a
x
{
L
~
(
o
l
d
)
?
L
~
(
n
e
w
)
}
max\{\tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} \}
max{L~(old)?L~(new)},��:
L
split?
=
1
2
[
(
��
i
��
I
L
g
i
)
2
��
i
��
I
L
h
i
+
��
+
(
��
i
��
I
R
g
i
)
2
��
i
��
I
R
h
i
+
��
?
(
��
i
��
I
g
i
)
2
��
i
��
I
h
i
+
��
]
?
��
\mathcal{L}_{\text {split }}=\frac{1}{2}\left[\frac{\left(\sum_{i \in I_{L}} g_{i}\right)^{2}}{\sum_{i \in I_{L}} h_{i}+\lambda}+\frac{\left(\sum_{i \in I_{R}} g_{i}\right)^{2}}{\sum_{i \in I_{R}} h_{i}+\lambda}-\frac{\left(\sum_{i \in I} g_{i}\right)^{2}}{\sum_{i \in I} h_{i}+\lambda}\right]-\gamma
Lsplit??=21?[��i��IL??hi?+��(��i��IL??gi?)2?+��i��IR??hi?+��(��i��IR??gi?)2??��i��I?hi?+��(��i��I?gi?)2?]?��
(6.1) ��ȷ̰�ķ����㷨:
XGBoost�����������Ĺ�����,������IJ����ǽڵ���ѡ��ڵ���������� Ҫ�Ļ������ҵ����������������зֵ�, Ȼ��Ҷ�ӽڵ㰴������������������ �ֵ���з��ѡ�ѡȡ���������������зֵ��һ��˼·����:�����ҵ����еĺ� ѡ���������еĺ�ѡ�зֵ�, һһ�����
L
split?
\mathcal{L}_{\text {split }}
Lsplit??, Ȼ��ѡ��
L
s
p
l
i
t
\mathcal{L}_{\mathrm{split}}
Lsplit? ���������� ��Ӧ�зֵ���Ϊ���������������зֵ㡣���dzƴ��ַ���Ϊ��ȷ̰���㷨�����㷨��һ������ʽ�㷨, ��Ϊ�ڽڵ����ʱֻѡ��ǰ���ŵķ��Ѳ���, ����ȫ�����ŵķ��Ѳ��ԡ���ȷ̰���㷨�ļ������������ʾ:

(6.2) ����ֱ��ͼ�Ľ����㷨:
��ȷ̰���㷨��ѡ�����������������зֵ�ʱ��һ��ʮ����Ч�ķ����������������������������зֵ������, ������ѡ�������ŵ�, �Ӷ���֤ģ���ܱȽϺõ������ѵ�����ݡ����ǵ����ݲ�����ȫ���ص��ڴ�ʱ,��ȷ̰���㷨���� �dz���Ч,�㷨�ڼ����������Ҫ�������ڴ������֮��������ݽ���,���Ǹ��dz���ʱ�Ĺ���, �����ڷֲ�ʽ����������ͬ�������⡣Ϊ���ܹ�����Ч��ѡ �������������зֵ�, XGBoost���һ�ֽ����㷨����������⡣ ����ֱ��ͼ�Ľ����㷨����Ҫ˼����:��ijһ����Ѱ�������зֵ�ʱ,���ȶԸ������������зֵ㰴��λ�� (��ٷ�λ) ��Ͱ, �õ�һ����ѡ�зֵ㼯��������ÿһ���зֵ㶼���Էֵ���Ӧ�ķ�Ͱ; Ȼ��,��ÿ��Ͱ��������ͳ��G��H�õ�ֱ��ͼ, GΪ��Ͱ����������һ������ͳ��g֮��, HΪ��Ͱ������������������ͳ��h֮��; ���,ѡ�����к�ѡ��������ѡ�зֵ��ж�ӦͰ������ͳ������������Ϊ���������������зֵ㡣����ֱ��ͼ�Ľ����㷨�ļ������������ʾ:
- ����ÿ������ k = 1 , 2 , ? ? , m , k=1,2, \cdots, m, k=1,2,?,m, ����λ�������� k k k ��Ͱ �� , \Theta, ��, �ɵú�ѡ�зֵ�, S k = { S k 1 , S k 2 , ? ? , S k l } 1 S_{k}=\left\{S_{k 1}, S_{k 2}, \cdots, S_{k l}\right\}^{1} Sk?={Sk1?,Sk2?,?,Skl?}1
- ����ÿ������
k
=
1
,
2
,
?
?
,
m
,
k=1,2, \cdots, m,
k=1,2,?,m, ��:
G k v �� = �� j �� { j �O s k , v �� x j k > s k , v ? 1 ?? } g j H k v �� = �� j �� { j �O s k , v �� x j k > s k , v ? 1 ?? } h j \begin{array}{l} G_{k v} \leftarrow=\sum_{j \in\left\{j \mid s_{k, v} \geq \mathbf{x}_{j k}>s_{k, v-1\;}\right\}} g_{j} \\ H_{k v} \leftarrow=\sum_{j \in\left\{j \mid s_{k, v} \geq \mathbf{x}_{j k}>s_{k, v-1\;}\right\}} h_{j} \end{array} Gkv?��=��j��{j�Osk,v?��xjk?>sk,v?1?}?gj?Hkv?��=��j��{j�Osk,v?��xjk?>sk,v?1?}?hj?? - ���ƾ�ȷ̰���㷨,�����ݶ�ͳ���ҵ��������ĺ�ѡ�зֵ㡣
������һ������˵������ֱ��ͼ�Ľ����㷨:������һ����������,��������ȡֵΪ18��19��21��31��36��37��55��57,������Ҫʹ�ý����㷨�ҵ����������������ѷ��ѵ�:
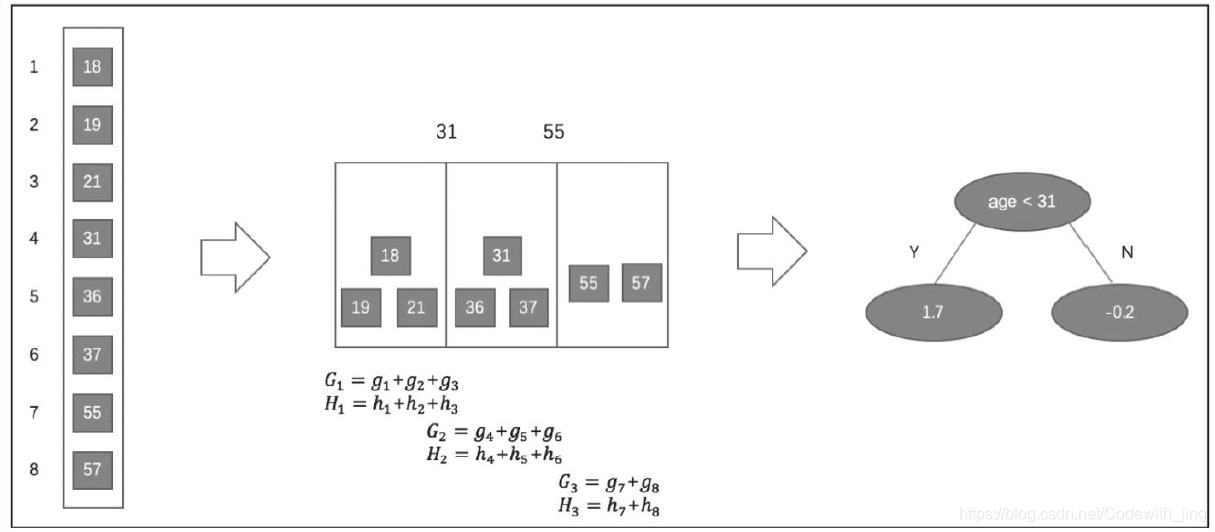
�����㷨ʵ�������ֺ�ѡ�зֵ�Ĺ�������:ȫ�ֲ��Ժͱ��ز��ԡ�ȫ�ֲ��������������ij�ʼ�ζ�ÿһ������ȷ��һ����ѡ�зֵ�ļ���, ���ڸ���ÿһ��Ľڵ�����о����ô˼��ϼ�������, �������̺�ѡ�зֵ㼯�ϲ��ı䡣���ز���������ÿһ�νڵ����ʱ������ȷ����ѡ�зֵ㡣ȫ�ֲ�����Ҫ��ϸ�ķ�Ͱ���ܴﵽ���ز��Եľ�ȷ��, ��ȫ�ֲ�����ѡȡ��ѡ�зֵ㼯��ʱ�ȱ��ز��Ը�����XGBoostϵͳ��, �û����Ը�����������ѡ��ʹ�þ�ȷ̰���㷨�������㷨ȫ�ֲ��ԡ������㷨���ز���, �㷨����ͨ�������������á�
2��XGBoostϵͳ����
������XGBoost�����۲���,�������Ƕ�XGBoostϵͳ������ϸ�Ľ���:
�ٷ��ĵ�:https://xgboost.readthedocs.io/en/latest/python/python_intro.html
�����Լ����ܽ�:https://zhuanlan.zhihu.com/p/143009353
��������(ʾ��):
# XGBoostԭ�����߿������:
import xgboost as xgb # ���빤�߿�
# read in data
dtrain = xgb.DMatrix('demo/data/agaricus.txt.train') # XGBoost��ר�����ݸ�ʽ,����Ҳ������dataframe����ndarray
dtest = xgb.DMatrix('demo/data/agaricus.txt.test') # # XGBoost��ר�����ݸ�ʽ,����Ҳ������dataframe����ndarray
# specify parameters via map
param = {'max_depth':2, 'eta':1, 'objective':'binary:logistic' } # ����XGB�IJ���,ʹ���ֵ���ʽ����
num_round = 2 # ʹ���߳���
bst = xgb.train(param, dtrain, num_round) # ѵ��
# make prediction
preds = bst.predict(dtest) # Ԥ��
XGBoost�IJ�������(�����ڵ�����Ϊsklearn�ӿڶ�Ӧ�IJ�������):
�Ƽ�����:https://link.zhihu.com/?target=https%3A//blog.csdn.net/luanpeng825485697/article/details/79907149
�Ƽ��ٷ��ĵ�:https://link.zhihu.com/?target=https%3A//xgboost.readthedocs.io/en/latest/parameter.html
XGBoost�IJ���������:
-
ͨ�ò���:(�������͵�booster,��Ϊtree�����ܱ����Իع�õö�,������Ǻ��������Իع顣)
- booster:ʹ���ĸ���ѧϰ��ѵ��,Ĭ��gbtree,��ѡgbtree,gblinear ��dart
- nthread:��������XGBoost�IJ����߳���,Ĭ��Ϊ�������߳���
- verbosity:��ӡ��Ϣ����ϸ�̶ȡ���ЧֵΪ0(��Ĭ),1(����),2(��Ϣ),3(����)��
- Tree Booster�IJ���:
- eta(learning_rate):learning_rate,�ڸ�����ʹ�ò��������Է�ֹ�������,Ĭ��= 0.3,��Χ:[0,1];����ֵһ������Ϊ:0.01-0.2
- gamma(min_split_loss):Ĭ��= 0,���ѽڵ�ʱ,��ʧ������Сֵֻ�д��ڵ���gamma�ڵ�ŷ���,gammaֵԽ��,�㷨Խ����,Խ���������,�����ܾͲ�һ���ܱ�֤,��Ҫƽ�⡣��Χ:[0,��]
- max_depth:Ĭ��= 6,һ�����������ȡ����Ӵ�ֵ��ʹģ������,���Ҹ����ܹ�����ϡ���Χ:[0,��]
- min_child_weight:Ĭ��ֵ= 1,����·��ѵĽڵ������Ȩ�غ�С��min_child_weight��ֹͣ���� ����������������ٹ����,����Ҳ����̫��,�ᵼ��Ƿ��ϡ���Χ:[0,��]
- max_delta_step:Ĭ��= 0,����ÿ��Ҷ���������������������������ֵ����Ϊ0,���ʾû��Լ���������������Ϊ��ֵ,�������ʹ���²�����ӱ��ء�ͨ������Ҫ�˲���,���ǵ��༫�Ȳ�ƽ��ʱ,���������������ع顣��������Ϊ1-10��ֵ���������ڿ��Ƹ��¡���Χ:[0,��]
- subsample:Ĭ��ֵ= 1,����ÿ�����������IJ�����,������ó�0.5,XGBoost�����ѡ��һ���������Ϊѵ��������Χ:(0,1]
- sampling_method:Ĭ��= uniform,���ڶ�ѵ��ʵ�����в����ķ�����
- uniform:ÿ��ѵ��ʵ����ѡ����ʾ��ȡ�ͨ����subsample> = 0.5 ���� Ϊ���õ�Ч����
- gradient_based:ÿ��ѵ��ʵ����ѡ�����������ݶȾ���ֵ������,������˵���� g 2 + �� h 2 \sqrt{g^2+\lambda h^2} g2+��h2?,subsample��������Ϊ����0.1,��������ʧģ�;��ȡ�
- colsample_bytree:Ĭ��= 1,�в�����,Ҳ�������������ʡ���ΧΪ(0,1]
- lambda(reg_lambda):Ĭ��=1,L2����Ȩ������Ӵ�ֵ��ʹģ���ӱ��ء�
- alpha(reg_alpha):Ĭ��= 0,Ȩ�ص�L1��������Ӵ�ֵ��ʹģ���ӱ��ء�
- tree_method:Ĭ��=auto,XGBoost��ʹ�õ��������㷨��
- auto:ʹ������ʽѡ�����ķ�����
- ����С�����ݼ�,exact��ʹ�þ�ȷ̰��()��
- ���ڽϴ�����ݼ�,approx��ѡ������㷨()�������鳢��hist,gpu_hist,�ô��������ݿ��ܸ��ߵ����ܡ�(gpu_hist)֧�֡�external memory�ⲿ�洢����
- exact:��ȷ��̰���㷨��ö�����в�ֵĺ�ѡ�㡣
- approx:ʹ�÷�λ�����ݶ�ֱ��ͼ�Ľ���̰���㷨��
- hist:�����ֱ��ͼ�Ż��Ľ���̰���㷨��(LightGBMҲ��ʹ��ֱ��ͼ�㷨)
- gpu_hist:GPU hist�㷨��ʵ�֡�
- auto:ʹ������ʽѡ�����ķ�����
- scale_pos_weight:��������Ȩ�ص�ƽ��,����ڲ�ƽ����������á�Kaggle����һ������sum(negative instances) / sum(positive instances),�����߶Ȳ�ƽ��������,���������ô���0,���Լӿ�������
- num_parallel_tree:Ĭ��=1,ÿ�ε����ڼ乹��IJ���������������ѡ������֧����ǿ�����ɭ�֡�
- monotone_constraints:�ɱ䵥���Ե�Լ��,��ijЩ�����,����зdz�ǿ�ҵ�����������Ϊ��ʵ�Ĺ�ϵ����һ��������,�����ʹ��Լ�����������ģ�͵�Ԥ�����ܡ�(����params_constrained[��monotone_constraints��] = ��(1,-1)��,(1,-1)���Ǹ���XGBoost�Ե�һ��Ԥ�����ʩ�����ӵ�Լ��,�Եڶ���Ԥ�����ʩ�Ӽ�С��Լ����)
- Linear Booster�IJ���:
- lambda(reg_lambda):Ĭ��= 0,L2����Ȩ������Ӵ�ֵ��ʹģ���ӱ��ء���һ��Ϊѵ��ʾ������
- alpha(reg_alpha):Ĭ��= 0,Ȩ�ص�L1��������Ӵ�ֵ��ʹģ���ӱ��ء���һ��Ϊѵ��ʾ������
- updater:Ĭ��= shotgun��
- shotgun:����shotgun�㷨��ƽ�������½��㷨��ʹ�á� hogwild��������,���ÿ�����ж�������ȷ���Ľ��������
- coord_descent:��ͨ�����½��㷨��ͬ���Ƕ��̵߳�,���Ի����ȷ���ԵĽ��������
- feature_selector:Ĭ��= cyclic������ѡ�������
- cyclic:ͨ��ÿ��ѭ��һ��������ʵ�ֵġ�
- shuffle:������cyclic,������ÿ�θ���֮ǰ��������������任��
- random:һ�����(�зŻ�)����ѡ������
- greedy:ѡ���ݶ�����������(̰��ѡ��)
- thrifty:����̰������ѡ��(������greedy)
- top_k:Ҫѡ�������Ҫ������(��greedy��thrifty��)
-
�������(���������������������Ż�Ŀ���ÿһ������Ķ���������)
- objective:Ĭ��=reg:squarederror,��ʾ��Сƽ����
- reg:squarederror,��Сƽ����
- reg:squaredlogerror,����ƽ����ʧ�� 1 2 [ l o g ( p r e d + 1 ) ? l o g ( l a b e l + 1 ) ] 2 \frac{1}{2}[log(pred+1)-log(label+1)]^2 21?[log(pred+1)?log(label+1)]2
- reg:logistic,���ع�
- reg:pseudohubererror,ʹ��αHuber��ʧ���лع�,���Ǿ�����ʧ��������ѡ��
- binary:logistic,��Ԫ��������ع�,������ʡ�
- binary:logitraw:���ڶ����Ʒ�������ع�,��ת��֮ǰ������÷֡�
- binary:hinge:�����Ʒ���Ľ�����ʧ����ʹԤ��Ϊ0��1,�����Dz������ʡ�(SVM���ǽ�����ʧ����)
- count:poisson �C�������ݵIJ��ɻع�,���ɷֲ������ƽ��ֵ��
- survival:cox:�����ȷ������ʱ�����ݽ���Cox�ع�(��ֵ����Ϊ��ȷ������ʱ��)��
- survival:aft:���ڼ������ʱ�����ݵļ��ٹ���ʱ��ģ�͡�
- aft_loss_distribution:survival:aft��aft-nloglik������ʹ�õĸ����ܶȺ�����
- multi:softmax:����XGBoost��ʹ��softmaxĿ����ж������,����Ҫ����num_class(����)
- multi:softprob:��softmax��ͬ,���������,���Խ�һ������Ϊ�������������ÿ������ÿ�����ݵ��Ԥ����ʡ�
- rank:pairwise:ʹ��LambdaMART���гɶ�����,�Ӷ�ʹ�ɶ���ʧ��С����
- rank:ndcg:ʹ��LambdaMART�����б�ʽ����,ʹ���������ۻ�����(NDCG)���
- rank:map:ʹ��LambdaMART�����б�ƽ������,ʹƽ��ƽ������(MAP)���
- reg:gamma:ʹ�ö������ӽ���٤���ع顣�����٤���ֲ���ƽ��ֵ��
- reg:tweedie:ʹ�ö������ӽ���Tweedie�ع顣
- �Զ�����ʧ����������ָ��:https://xgboost.readthedocs.io/en/latest/tutorials/custom_metric_obj.html
- eval_metric:��֤���ݵ�����ָ��,������Ŀ�����Ĭ��ָ��(�ع������,�������,������ƽ��ƽ������),�û��������Ӷ������ָ��
- rmse,���������; rmsle:�������������; mae:ƽ���������;mphe:ƽ��αHuber����;logloss:��������Ȼ; error:�����Ʒ��������;
- merror:������������; mlogloss:����logloss; auc:���������; aucpr:PR�����µ����;ndcg:��һ���ۼ��ۿ�;map:ƽ������;
- seed :���������,[Ĭ��= 0]��
- objective:Ĭ��=reg:squarederror,��ʾ��Сƽ����
-
�����в���(���ﲻ˵��,��Ϊ�����������п���̨�汾)
from IPython.display import IFrame
IFrame('https://xgboost.readthedocs.io/en/latest/parameter.html', width=1400, height=800)
XGBoost�ĵ���˵��:
�������ŵ�һ�㲽��
-1. ȷ��ѧϰ���ʺ������������ŵij�ʼֵ
-2. max_depth �� min_child_weight ��������
-3. gamma��������
-4. subsample �� colsample_bytree ������
-5. ������alpha����
-6. ����ѧϰ���ʺ�ʹ�ø���ľ�����
XGBoost��ϸ����:
�����api��鿴:https://xgboost.readthedocs.io/en/latest/python/python_api.html
�Ƽ�github:https://github.com/dmlc/xgboost/tree/master/demo/guide-python
���ݽӿ�(XGBoost�ɴ��������ݸ�ʽDMatrix)
# 1.LibSVM�ı���ʽ�ļ�
dtrain = xgb.DMatrix('train.svm.txt')
dtest = xgb.DMatrix('test.svm.buffer')
# 2.CSV�ļ�(���ܺ�����ı�����,��������ı�������������������one-hot)
dtrain = xgb.DMatrix('train.csv?format=csv&label_column=0')
dtest = xgb.DMatrix('test.csv?format=csv&label_column=0')
# 3.NumPy����
data = np.random.rand(5, 10) # 5 entities, each contains 10 features
label = np.random.randint(2, size=5) # binary target
dtrain = xgb.DMatrix(data, label=label)
# 4.scipy.sparse����
csr = scipy.sparse.csr_matrix((dat, (row, col)))
dtrain = xgb.DMatrix(csr)
# pandas���ݿ�dataframe
data = pandas.DataFrame(np.arange(12).reshape((4,3)), columns=['a', 'b', 'c'])
label = pandas.DataFrame(np.random.randint(2, size=4))
dtrain = xgb.DMatrix(data, label=label)
�����Ƽ�:�ȱ��浽XGBoost�������ļ��н�ʹ�����ٶȸ���,Ȼ���ټ��ؽ���
# 1.����DMatrix��XGBoost�������ļ���
dtrain = xgb.DMatrix('train.svm.txt')
dtrain.save_binary('train.buffer')
# 2. ȱ�ٵ�ֵ������DMatrix���캯���е�Ĭ��ֵ�滻:
dtrain = xgb.DMatrix(data, label=label, missing=-999.0)
# 3.��������Ҫʱ����Ȩ��:
w = np.random.rand(5, 1)
dtrain = xgb.DMatrix(data, label=label, missing=-999.0, weight=w)
���������÷�ʽ:
# ���ز���������
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
df_wine.columns = ['Class label', 'Alcohol','Malic acid', 'Ash','Alcalinity of ash','Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols','Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
df_wine = df_wine[df_wine['Class label'] != 1] # drop 1 class
y = df_wine['Class label'].values
X = df_wine[['Alcohol','OD280/OD315 of diluted wines']].values
from sklearn.model_selection import train_test_split # �з�ѵ��������Լ�
from sklearn.preprocessing import LabelEncoder # ��ǩ���������
le = LabelEncoder()
y = le.fit_transform(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test)
# 1.Booster ����
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # ����������
'num_class': 10, # �����,�� multisoftmax ����
'gamma': 0.1, # ���ڿ����Ƿ���֦�IJ���,Խ��Խ����,һ��0.1��0.2�����ӡ�
'max_depth': 12, # �����������,Խ��Խ�������
'lambda': 2, # ����ģ���Ӷȵ�Ȩ��ֵ��L2���������,����Խ��,ģ��Խ��������ϡ�
'subsample': 0.7, # �������ѵ������
'colsample_bytree': 0.7, # ������ʱ���е��в���
'min_child_weight': 3,
'silent': 1, # ���ó�1��û��������Ϣ���,���������Ϊ0.
'eta': 0.007, # ��ͬѧϰ��
'seed': 1000,
'nthread': 4, # cpu �߳���
'eval_metric':'auc'
}
plst = params.items()
# evallist = [(dtest, 'eval'), (dtrain, 'train')] # ָ����֤��
ѵ��:
# 2.ѵ��
num_round = 10
bst = xgb.train( plst, dtrain, num_round)
#bst = xgb.train( plst, dtrain, num_round, evallist )
����ģ��:
# 3.����ģ��
bst.save_model('0001.model')
# dump model
bst.dump_model('dump.raw.txt')
# dump model with feature map
#bst.dump_model('dump.raw.txt', 'featmap.txt')
���ر����ģ��:
# 4.���ر����ģ��:
bst = xgb.Booster({'nthread': 4}) # init model
bst.load_model('0001.model') # load data
������ͣ����:
# 5.Ҳ����������ͣ����(��Ҫ������֤��)
train(..., evals=evals, early_stopping_rounds=10)
Ԥ��:
# 6.Ԥ��
ypred = bst.predict(dtest)
������Ҫ������ͼ:
# 1.������Ҫ��
xgb.plot_importance(bst)
# 2.���������
#xgb.plot_tree(bst, num_trees=2)
# 3.ʹ��xgboost.to_graphviz()��Ŀ����ת��Ϊgraphviz
#xgb.to_graphviz(bst, num_trees=2)
3��XGBoost����ʾ��
(1)���స��
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # ȷ��
# �����������ݼ�
iris = load_iris()
X,y = iris.data,iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565) # ���ݼ��ָ�
# �㷨����
params = {
'booster': 'gbtree',
'objective': 'multi:softmax',
'num_class': 3,
'gamma': 0.1,
'max_depth': 6,
'lambda': 2,
'subsample': 0.7,
'colsample_bytree': 0.75,
'min_child_weight': 3,
'silent': 0,
'eta': 0.1,
'seed': 1,
'nthread': 4,
}
plst = params.items()
dtrain = xgb.DMatrix(X_train, y_train) # �������ݼ���ʽ
num_rounds = 500
model = xgb.train(plst, dtrain, num_rounds) # xgboostģ��ѵ��
# �Բ��Լ�����Ԥ��
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
# ����ȷ��
accuracy = accuracy_score(y_test,y_pred)
print("accuarcy: %.2f%%" % (accuracy*100.0))
# ��ʾ��Ҫ����
plot_importance(model)
plt.show()
accuarcy: 96.67%
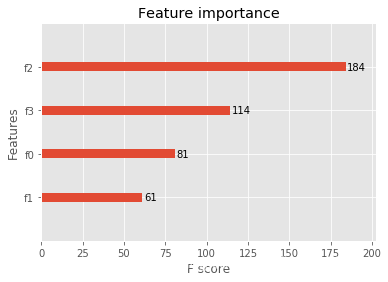
(2)�ع鰸��
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# �������ݼ�
boston = load_boston()
X,y = boston.data,boston.target
# XGBoostѵ������
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
params = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'gamma': 0.1,
'max_depth': 5,
'lambda': 3,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'silent': 1,
'eta': 0.1,
'seed': 1000,
'nthread': 4,
}
dtrain = xgb.DMatrix(X_train, y_train)
num_rounds = 300
plst = params.items()
model = xgb.train(plst, dtrain, num_rounds)
# �Բ��Լ�����Ԥ��
dtest = xgb.DMatrix(X_test)
ans = model.predict(dtest)
# ��ʾ��Ҫ����
plot_importance(model)
plt.show()
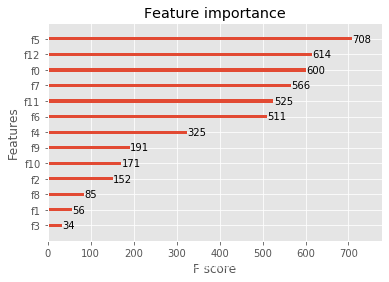
(3)XGBoost����(���sklearn��������)
����ο�:https://www.jianshu.com/p/1100e333fcab
import xgboost as xgb
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import roc_auc_score
iris = load_iris()
X,y = iris.data,iris.target
col = iris.target_names
train_x, valid_x, train_y, valid_y = train_test_split(X, y, test_size=0.3, random_state=1) # ��ѵ��������֤��
parameters = {
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [500, 1000, 2000, 3000, 5000],
'min_child_weight': [0, 2, 5, 10, 20],
'max_delta_step': [0, 0.2, 0.6, 1, 2],
'subsample': [0.6, 0.7, 0.8, 0.85, 0.95],
'colsample_bytree': [0.5, 0.6, 0.7, 0.8, 0.9],
'reg_alpha': [0, 0.25, 0.5, 0.75, 1],
'reg_lambda': [0.2, 0.4, 0.6, 0.8, 1],
'scale_pos_weight': [0.2, 0.4, 0.6, 0.8, 1]
}
xlf = xgb.XGBClassifier(max_depth=10,
learning_rate=0.01,
n_estimators=2000,
silent=True,
objective='multi:softmax',
num_class=3 ,
nthread=-1,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=0.85,
colsample_bytree=0.7,
colsample_bylevel=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=0,
missing=None)
gs = GridSearchCV(xlf, param_grid=parameters, scoring='accuracy', cv=3)
gs.fit(train_x, train_y)
print("Best score: %0.3f" % gs.best_score_)
print("Best parameters set: %s" % gs.best_params_ )
Best score: 0.933
Best parameters set: {��max_depth��: 5}
����LightGBM�㷨
LightGBMҲ����XGBoostһ��,��һ�༯���㷨,����XGBoost������˵��һ����,�㷨��������Xgboostû�г���,ֻ����XGBoost�Ļ����Ͻ������Ż�,��˾Ͳ���ԭ�������ظ�����,���������������������㷨�IJ��:
- �Ż��ٶȺ��ڴ�ʹ��
- �����˼���ÿ���ָ�����ijɱ���
- ʹ��ֱ��ͼ������һ������ٶȡ�
- �����ڴ�ʹ�á�
- ���ٲ���ѧϰ�ļ���ɱ���
- ϡ���Ż�
- ����ɢ��bin�滻������ֵ�����#bins��С,�����ʹ�ý�С����������(����uint8_t)���洢ѵ������ ��
- ����洢������Ϣ���ɶ�������ֵ����Ԥ���� ��
- �����Ż�
- ʹ��Ҷ����Ϊ����ľ����������㷨������������ȵ���
- ���������ı��뷽ʽ���Ż�
- ͨ��������Ż�
- ����ѧϰ���Ż�
- GPU֧��
LightGBM���ŵ�:
1)�����ѵ��Ч��
2)���ڴ�ʹ��
3)���ߵ�ȷ��
4)֧�ֲ��л�ѧϰ
5)���Դ������ģ����
1.�ٶȶԱ�:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-viFt8QU8-1627131148390)(./�ٶȶԱ�.png)]](https://img-blog.csdnimg.cn/531f49810e92456aa281daac9c552325.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0NvZGV3aXRoX2ppbmc=,size_16,color_FFFFFF,t_70)
2.ȷ�ʶԱ�:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-DKEoUTJV-1627131148391)(./ȷ�ʶԱ�.png)]](https://img-blog.csdnimg.cn/d1d762b06ba4418ba4e4ab6f6247fa55.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0NvZGV3aXRoX2ppbmc=,size_16,color_FFFFFF,t_70)
3.�ڴ�ʹ�����Ա�:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-ei5S4Oa3-1627131148393)(./�ڴ�ʹ����.png)]](https://img-blog.csdnimg.cn/bb3dd452d81f45e0b630300c894b6adc.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0NvZGV3aXRoX2ppbmc=,size_16,color_FFFFFF,t_70)
LightGBM����˵��:
�Ƽ��ĵ�1:https://lightgbm.apachecn.org/#/docs/6
�Ƽ��ĵ�2:https://lightgbm.readthedocs.io/en/latest/Parameters.html
1.���IJ���:(�����������DZ���)
- objective(objective,app ,application):Ĭ��regression,����������ʧ����
- �ع�����:
- L2��ʧ:regression(regression_l2,l2,mean_squared_error,mse,l2_root,root_mean_squared_error,rmse)
- L1��ʧ:regression_l1(l1, mean_absolute_error, mae)
- ������ʧ:huber,fair,poisson,quantile,mape,gamma,tweedie
- ����������:�����ƶ�����ʧ����(�����ع�):binary
- ��������:
- softmaxĿ�꺯��: multiclass(softmax)
- One-vs-All Ŀ�꺯��:multiclassova(multiclass_ova,ova,ovr)
- ������:
- ���ڽ����ص�Ŀ�꺯��(���п�ѡ������Ȩ��):cross_entropy(xentropy)
- �����ص����������:cross_entropy_lambda(xentlambda)
- �ع�����:
- boosting :Ĭ��gbdt,������������,ѡ����gbdt,rf,dart,goss,����:boosting_type,boost
- gbdt(gbrt):��ͳ���ݶ�����������
- rf(random_forest):���ɭ��
- dart:������Իع�����DROPOUT���� Dropouts meet Multiple Additive Regression Trees,�μ�:https://arxiv.org/abs/1505.01866
- goss:�����ݶȵĵ��߲��� Gradient-based One-Side Sampling
- data(train,train_data,train_data_file,data_filename):����ѵ�������ݻ�����file
- valid (test,valid_data,valid_data_file,test_data,test_data_file,valid_filenames):��֤/�������ݵ�·��,LightGBM�������Щ���ݵ�ָ��
- num_iterations:Ĭ��=100,����= INT
- n_estimators:������������,LightGBM�������ڶ�������������num_class * num_iterations
- learning_rate(shrinkage_rate,eta) :������,Ĭ��=0.1
- num_leaves(num_leaf,max_leaves,max_leaf) :Ĭ��=31,һ�����ϵ����Ҷ����
- tree_learner (tree,tree_type,tree_learner_type):Ĭ��=serial,��ѡ:serial,feature,data,voting
- serial:��̨������ tree learner
- feature:�������е� tree learner
- data:���ݲ��е� tree learner
- voting:ͶƱ���е� tree learner
- num_threads(num_thread, nthread):LightGBM ���߳���,Ϊ�˸�����ٶ�, ��������Ϊ������ CPU �ں���, �������̵߳����� (����� CPU ʹ�ó��߳���ʹÿ�� CPU �ں����� 2 ���߳�),��������ݼ�С��ʱ��Ҫ�������õĹ��� (����, �����ݼ��� 10,000 ��ʱ��Ҫʹ�� 64 �߳�),���ڲ���ѧϰ, ��Ӧ��ʹ��ȫ���� CPU �ں�, ��Ϊ��ᵼ���������ܲ��ѡ�
- device(device_type):Ĭ��cpu,Ϊ��ѧϰѡ���豸, �����ʹ�� GPU ����ø����ѧϰ�ٶ�,��ѡcpu, gpu��
- seed (random_seed,random_state):�������������,�����Ӿ��нϵ͵����ȼ�,����ζ���������ȷ������������,���������ǡ�
2.���ڿ���ģ��ѧϰ���̵IJ���:
- max_depth:������ģ�͵�������. ������� #data С������·�ֹ�����. ����Ȼ����ͨ�� leaf-wise ������
- min_data_in_leaf: Ĭ��=20,һ��Ҷ�������ݵ���С����. ����������������ϡ�
- min_sum_hessian_in_leaf(min_sum_hessian_per_leaf, min_sum_hessian, min_hessian):Ĭ��=1e-3,һ��Ҷ���ϵ���С hessian ��. ������ min_data_in_leaf, �����������������.
- feature_fraction:default=1.0,��� feature_fraction С�� 1.0, LightGBM ������ÿ�ε��������ѡ������. ����, �������Ϊ 0.8, ������ÿ����ѵ��֮ǰѡ�� 80% ������,������������ѵ��,����������������ϡ�
- feature_fraction_seed:Ĭ��=2,feature_fraction ����������ӡ�
- bagging_fraction(sub_row, subsample):Ĭ��=1,�������ز�������������ѡ������
- bagging_freq(subsample_freq):bagging ��Ƶ��, 0 ��ζ�Ž��� bagging. k ��ζ��ÿ k �ε���ִ��bagging
- bagging_seed(bagging_fraction_seed) :Ĭ��=3,bagging ��������ӡ�
- early_stopping_round(early_stopping_rounds, early_stopping):Ĭ��=0,���һ����֤���Ķ����� early_stopping_round ѭ����û������, ��ֹͣѵ��
- lambda_l1(reg_alpha):L1����ϵ��
- lambda_l2(reg_lambda):L2����ϵ��
- min_split_gain(min_gain_to_split):ִ���зֵ���С����,Ĭ��=0.
- cat_smooth:Ĭ��=10,���ڷ�������,���Խ��������ڷ��������е�Ӱ��, �����Ƕ����ݺ��ٵ����
3.��������:
- metric:default={l2 for regression}, {binary_logloss for binary classification}, {ndcg for lambdarank}, type=multi-enum, options=l1, l2, ndcg, auc, binary_logloss, binary_error ��
- l1, absolute loss, alias=mean_absolute_error, mae
- l2, square loss, alias=mean_squared_error, mse
- l2_root, root square loss, alias=root_mean_squared_error, rmse
- quantile, Quantile regression
- huber, Huber loss
- fair, Fair loss
- poisson, Poisson regression
- ndcg, NDCG
- map, MAP
- auc, AUC
- binary_logloss, log loss
- binary_error, ����: 0 ����ȷ����, 1 �������
- multi_logloss, mulit-class ��ʧ��־����
- multi_error, error rate for mulit-class �����ʷ���
- xentropy, cross-entropy (���ѡ������Ȩ��), alias=cross_entropy
- xentlambda, ��intensity-weighted�� ������, alias=cross_entropy_lambda
- kldiv, Kullback-Leibler divergence, alias=kullback_leibler
- ֧�ֶ�ָ��, ʹ�� , �ָ�
- train_metric(training_metric, is_training_metric):Ĭ��=False,�������Ҫ���ѵ���Ķ������������ true
4.GPU ����:
- gpu_device_id:defaultΪ-1, ���default��ζ��ѡ��ƽ̨�ϵ��豸��
LightGBM������������ϵ���:
�����:https://blog.csdn.net/u012735708/article/details/83749703
import lightgbm as lgb
from sklearn import metrics
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
canceData=load_breast_cancer()
X=canceData.data
y=canceData.target
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0,test_size=0.2)
### ����ת��
print('����ת��')
lgb_train = lgb.Dataset(X_train, y_train, free_raw_data=False)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train,free_raw_data=False)
### ���ó�ʼ����--����������֤����
print('����')
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'nthread':4,
'learning_rate':0.1
}
### ������֤(����)
print('������֤')
max_auc = float('0')
best_params = {}
# ȷ��
print("����1:���ȷ��")
for num_leaves in range(5,100,5):
for max_depth in range(3,8,1):
params['num_leaves'] = num_leaves
params['max_depth'] = max_depth
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['num_leaves'] = num_leaves
best_params['max_depth'] = max_depth
if 'num_leaves' and 'max_depth' in best_params.keys():
params['num_leaves'] = best_params['num_leaves']
params['max_depth'] = best_params['max_depth']
# �����
print("����2:�������")
for max_bin in range(5,256,10):
for min_data_in_leaf in range(1,102,10):
params['max_bin'] = max_bin
params['min_data_in_leaf'] = min_data_in_leaf
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['max_bin']= max_bin
best_params['min_data_in_leaf'] = min_data_in_leaf
if 'max_bin' and 'min_data_in_leaf' in best_params.keys():
params['min_data_in_leaf'] = best_params['min_data_in_leaf']
params['max_bin'] = best_params['max_bin']
print("����3:�������")
for feature_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_freq in range(0,50,5):
params['feature_fraction'] = feature_fraction
params['bagging_fraction'] = bagging_fraction
params['bagging_freq'] = bagging_freq
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['feature_fraction'] = feature_fraction
best_params['bagging_fraction'] = bagging_fraction
best_params['bagging_freq'] = bagging_freq
if 'feature_fraction' and 'bagging_fraction' and 'bagging_freq' in best_params.keys():
params['feature_fraction'] = best_params['feature_fraction']
params['bagging_fraction'] = best_params['bagging_fraction']
params['bagging_freq'] = best_params['bagging_freq']
print("����4:�������")
for lambda_l1 in [1e-5,1e-3,1e-1,0.0,0.1,0.3,0.5,0.7,0.9,1.0]:
for lambda_l2 in [1e-5,1e-3,1e-1,0.0,0.1,0.4,0.6,0.7,0.9,1.0]:
params['lambda_l1'] = lambda_l1
params['lambda_l2'] = lambda_l2
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['lambda_l1'] = lambda_l1
best_params['lambda_l2'] = lambda_l2
if 'lambda_l1' and 'lambda_l2' in best_params.keys():
params['lambda_l1'] = best_params['lambda_l1']
params['lambda_l2'] = best_params['lambda_l2']
print("����5:�������2")
for min_split_gain in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
params['min_split_gain'] = min_split_gain
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['min_split_gain'] = min_split_gain
if 'min_split_gain' in best_params.keys():
params['min_split_gain'] = best_params['min_split_gain']
print(best_params)
{��bagging_fraction��: 0.7,
��bagging_freq��: 30,
��feature_fraction��: 0.8,
��lambda_l1��: 0.1,
��lambda_l2��: 0.0,
��max_bin��: 255,
��max_depth��: 4,
��min_data_in_leaf��: 81,
��min_split_gain��: 0.1,
��num_leaves��: 10}
�ߡ���ҵ
(1)Adaboost �Ļ���˼·
- ��Adaboost����ԭ��
(2)Adaboost ��GBDT����ϵ������
- ���Ƕ�����boosting��������,ֻ����ʧ������ͬ:AdaBoost ��ͨ�������������ݵ��Ȩ������λģ�͵IJ���,��Gradient Boosting��ͨ�����ݶ�����λģ�͵IJ��㡣
- Adaboostǿ��Adaptive(����Ӧ),ͨ������������Ȩ��(����ִ�����Ȩ��,���ͷֶ�����Ȩ��),���ϼ���������������boosting
- GBDT ������ȷ����ʧ������,���� cart �������Ŀ�����������ʧ���������ǰһ�������ģ�͵ĸ��ݶȷ���������,Ҳ����ϣ������ٶȵ���С��Ԥ��ֵ����ʵֵ֮��IJ���;����ʧ����ѡ��Ϊ square loss ʱ��,�����Ÿ��ݶȷ�����ϱ���Ϊ��ϲв�(ѡ��������ʧ������һ�����ֳ���ϲв������)
����:GBDT��XGBOOST֮����ʲô����
- ��ͳGBDT��CART��Ϊ��������,xgboost��֧�����Է�����,���ʱ��xgboost�൱�ڴ�L1��L2���������˹�ٻع�(��������)�������Իع�(�ع�����)��
- ��ͳGBDT���Ż�ʱֻ�õ�һ������Ϣ,xgboost��Դ��ۺ��������˶���̩��չ��,ͬʱ�õ���һ�Ͷ�������˳����һ��,xgboost����֧���Զ�����ۺ���,ֻҪ������һ�Ͷ�����
- xgboost�ڴ��ۺ����������������,���ڿ���ģ�͵ĸ��Ӷȡ������������������Ҷ�ӽڵ������ÿ��Ҷ�ӽڵ��������score��L2ģ��ƽ���͡���Bias-variance tradeoff�Ƕ�����,���������ģ�͵�variance,ʹѧϰ������ģ���Ӽ�,��ֹ�����,��Ҳ��xgboost���ڴ�ͳGBDT��һ�����ԡ�
- Shrinkage(����),�൱��ѧϰ����(xgboost�е�eta)��xgboost�ڽ�����һ�ε�����,�ὫҶ�ӽڵ��Ȩ�س��ϸ�ϵ��,��Ҫ��Ϊ������ÿ������Ӱ��,�ú����и����ѧϰ�ռ䡣ʵ��Ӧ����,һ���eta���õ�Сһ��,Ȼ������������õô�һ�㡣(����:��ͳGBDT��ʵ��Ҳ��ѧϰ����)
- �г���(column subsampling)��xgboost��������ɭ�ֵ�����,֧���г���,�����ܽ������,���ܼ��ټ���,��Ҳ��xgboost���ڴ�ͳgbdt��һ�����ԡ�
- ��ȱʧֵ�Ĵ���������������ֵ��ȱʧ������,xgboost�����Զ�ѧϰ�����ķ��ѷ���
- xgboost����֧�ֲ��С�boosting����һ�ִ��еĽṹ��?��ô���е�?ע��xgboost�IJ��в���tree���ȵIJ���,xgboostҲ��һ�ε�������ܽ�����һ�ε�����(��t�ε����Ĵ��ۺ����������ǰ��t-1�ε�����Ԥ��ֵ)��xgboost�IJ����������������ϵġ�����֪��,��������ѧϰ���ʱ��һ��������Ƕ�������ֵ��������(��ΪҪȷ����ѷָ��),xgboost��ѵ��֮ǰ,Ԥ�ȶ����ݽ���������,Ȼ��Ϊblock�ṹ,����ĵ������ظ���ʹ������ṹ,����С�����������block�ṹҲʹ�ò��г�Ϊ�˿���,�ڽ��нڵ�ķ���ʱ,��Ҫ����ÿ������������,����ѡ���������Ǹ�����ȥ������,��ô�����������������Ϳ��Կ����߳̽��С�
- �ɲ��еĽ���ֱ��ͼ�㷨�����ڵ��ڽ��з���ʱ,������Ҫ����ÿ��������ÿ���ָ���Ӧ������,����̰�ķ�ö�����п��ܵķָ�㡣��������һ�������ڴ�����ڷֲ�ʽ�����,̰���㷨Ч�ʾͻ��úܵ�,����xgboost�������һ�ֿɲ��еĽ���ֱ��ͼ�㷨,���ڸ�Ч�����ɺ�ѡ�ķָ�㡣(���� XGBoost �����н��ܵļ�Ȩֱ��ͼ,����Ȩֵ�������Ķ����ݶ�,��Ϊ��Ŀ�꺯�����Ի���Ϊ������ϵ��Ϊ H �Ķ��ζ���ʽ)
- XGBoost ���Կ����� GBDT ��һ��������ʵ��,������Ҫ��ȷ��һ��������,XGBoost �� Boosting ��ܵ�һ��ʵ�ֽṹ, lightgbm Ҳ��һ�ֿ��ʵ�ֽṹ,�� GBDT ����һ���㷨ʵ��,���������Ϊ CART ��,���Դ������ࡢ�ع�����,���������������ǽ������������� softmax ת��Ϊ�ع�����������
(3)Boosting ��Bagging ������,�Լ��������ģ�͵ľ���
- Bagging��Boosting���ǽ����еķ����ع��㷨ͨ��һ����ʽ�������,�γ�һ�����ܸ���ǿ��ķ�����,��ȷ��˵����һ�ַ����㷨����װ��������������������װ��ǿ�������ķ�����
- Bagging˼���ʵ����:ͨ��Bootstrap �ķ�ʽ��ȫ�������ݼ����г����õ������Ӽ�,�Բ�ͬ���Ӽ�ʹ��ͬһ�ֻ���ģ�ͽ������,Ȼ��ͶƱ�ó����յ�Ԥ�⡣Bagging��Ҫͨ�����ͷ���ķ�ʽ����Ԥ����
- Boosting������ʹ��ͬһ�����ݼ����з���ѧϰ,�õ�һϵ�м�ģ��,Ȼ�������Щģ����һ��Ԥ������ʮ��ǿ��Ļ���ѧϰģ�͡���Ȼ,Boosting˼��������յ�Ԥ��Ч����ͨ�����ϼ���ƫ�����ʽ,��Bagging���ű��ʵIJ�ͬ��
(4)ʹ�û�������ģ�ͺ�Boosting������ģ��,���������ǵľ��߽߱�
- ��ʹ��sklearn��Adaboost�㷨���н�ģ
(5)����ʹ��XGboostģ�����һ������ķ�������,�����е���
- ��XGBoost����ʾ��(3)
�ܽ�
������Ҫ̽���˻���Boosting��ʽ�ļ��ɷ���,������Ҫ�����˻��ڴ�����������Adaboost,���ڲв�Ľ���������,�����ݶ�������GBDT,����̩�ն����Ƶ�Xgboost�Լ�LightGBM����ʵ�ʵı������߹�����,����Boosting�ļ���ѧϰ��ʽ�Ƿdz���Ч��Ӧ�÷dz��㷺�ġ�
�ο�
��1��https://b23.tv/4Jedpz
��2��https://b23.tv/0pFvvd
��3��https://github.com/datawhalechina/ensemble-learning