该系列主要是听李宏毅老师的《深度强化学习》过程中记下的一些听课心得,除了李宏毅老师的强化学习课程之外,为保证内容的完整性,我还参考了一些其他的课程,包括周博磊老师的《强化学习纲要》、李科浇老师的《百度强化学习》以及多个强化学习的经典资料作为补充。
使用说明
- 笔记【4】到笔记【11】?为李宏毅《深度强化学习》的部分;
- 笔记 【1】和笔记?【2】?根据《强化学习纲要》整理而来;
- 笔记 【3】?和笔记?【12】根据《百度强化学习》?整理而来。
一、强化学习基本知识
(1)基本概念
强化学习关注的是智能体在未知环境中如何获得最大的奖励。
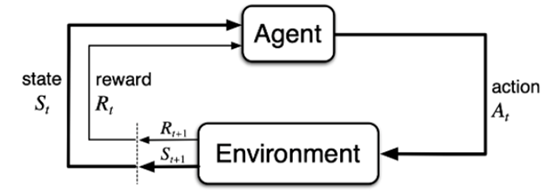
?图1.强化学习过程示意图
如图1所示,强化学习中重要的两个主体为Agent和Environment。其中Agent即智能体(也就是你所写的算法),比如在游戏中Agent指玩家;Environment即外部环境,比如在游戏中指游戏环境。强化学习的过程就是不断通过Agent和Environment这两者的交互来获得最大奖励值,具体过程为:智能体Agent根据当前环境Environment的状态state,从而输出一个动作action,该动作执行之后就会对环境产生影响,从而使得环境的状态发生变化,并且获得对应的奖励reward,根据变化后的状态,智能体又做出下一个动作,进而作用于环境……在这个过程中Agent的目的就是尽可能多的从环境中获得奖励。
(2)强化学习vs监督学习
监督学习就是把人为标注好的数据输入网络,网络通过这些数据进行学习。其中这些数据之间满足独立同分布,也就是说他们共同满足某种分布并且互不关联。在学习过程中,如果网络输出了错误的预测结果,那么这些带标注的数据马上就能告诉它:你预测错误了,正确的答案应该是…,并且将这一次的预测偏差算入损失函数,之后一步步减小这个损失函数,从而训练出网络。
举个例子,要利用监督学习训练一个识别飞机和汽车的网络。首先对各种飞机和汽车图片进行人工标注,之后将该标注完成的数据集输入网络,在训练过程中,当网络将一张飞机图片预测成汽车时,图片上的标注会告诉它:错误,正确答案应该是飞机。此时网络就会根据此反馈调整自己的参数,从而一步步使得结果更加准确。
根据上述例子可知,(1)监督学习中的反馈是非常及时的,可以在网络产生结果之后马上反馈,(2)反馈结果不但会给出预测正误的判断,并且会直接给出正确答案,(3)训练数据之间独立同分布,也即没有关联。
强化学习的训练过程则比较像一个玩游戏的过程,从第一步开始采取一个动作,改变环境状态之后再采取下一个动作,所以训练数据之间具有时间上的强关联性,是一个序列,而不是独立同分布的;并且执行了一个动作之后,不会有标签来告诉你该动作执行的对不对、正确的应该是怎么做;此外,强化学习的奖励往往有延迟,比如对于游戏而言,只有等到游戏结束,我们才能知道该动作对于赢得游戏有没有帮助,所以该动作的奖励可能要到很久以后才能知道,也即延迟奖励。
表1 强化学习与监督学习的比较
| 强化学习 | 监督学习 | |
| 训练数据 | 具有时间关联的序列 | 独立同分布的标注数据 |
| 反馈时间 | 延迟奖励 | 即时反馈 |
| 反馈结果 | 奖励值 | 正确答案 |
| 试错探索 | 会探索新的行为 | 不会 |
(3)相关术语

??图2.对当前状态的可能展开
如图所示,在强化学习里面,从当前状态生成很多结果的展开称为rollout,一场游戏叫做一个episode(回合)或者trial(实验),游戏中智能体所采取的动作与状态的序列τ = (s0?,a0?,s1?,a1?,…),称为一个trajectory(轨迹)。此外,在强化学习中我们常常提到观测observation,它类似于状态state,其中state是对世界的完整描述,不会有信息遗漏,而observation可能会有部分遗漏。
表2 相关术语
| 常用名词 | 英文术语 |
| 智能体 | Agent |
| 环境 | Environment |
| 状态 | State |
| 观测 | Observation |
| 动作 | Action |
| 奖励 | Reward |
| 展开 | Rollout |
| 回合 | Episode |
| 序列 | Trajectory |
(4)强化学习到深度强化学习
①经典的强化学习方法其实是手工设计特征,然后去训练价值函数。该手工特征可以描述当前状态,得到该特征后,通过训练分类网络或者价值评估函数来做决策。
②深度强化学习=深度学习+强化学习,可以将上述过程改成端到端的训练过程。输入状态之后,不用手动设计特征,直接通过神经网络来拟合价值函数等,从而输出动作。
二、序列决策(Sequential Decision Making)过程
(1) Sequential Decision Making
在强化学习过程中,agent会产生很多观测obversation,在每一个观测之后采取一个动作,并且获得一个奖励。所以历史是观测、动作以及奖励这三部分的序列:
Ht?=O1?,R1?,A1?,…,At?1?,Ot?,Rt?
agent在采取动作时,会依据先前得到的历史,所以可以将整个游戏的状态看出关于历史的函数:
St?=f(Ht?)
(2)状态和观测有什么关系?
状态state是对于世界的完整描述,不存在信息的遗漏;观测observation是部分描述,可能存在信息遗漏。
环境有自己的函数来更新状态,agent内部也有自己的函数来更新状态,当两者相等时,称为full observability,即完全可观测。换句话说,当agent能够观测到环境的全部状态时,我们就说这个环境是完全可观测的(fully observed)。在这种情况下,强化学习通常被建模成一个MDP,这个后续再详细讲解。?
当agent只能观测到部分环境状态时,我们称环境为部分可观测(partially observed),此时强化学习通常被建模成一个POMDP问题,这个也后续再详细讲解。
(3)动作空间
在给定的环境中,有效动作的合集称为动作空间。根据环境的不同可分为离散动作空间与连续动作空间,比如一个棋盘中,棋子只能上下左右移动,就是离散动作空间,如果机器人360度都可以移动,就是连续动作空间。
三、agent包含的成分
一个强化学习的agent由以下中的一个或者多个组成:
- 策略函数(policy function):用于选取下一步动作;
- 价值函数(value function):用于评估当前状态的价值;
- 模型(model):表示agent对环境的理解。
根据以上三者可对强化学习进行不同的分类:

?