????������Ҫ���������ѧϰ����㷨�����о����ʵ���һЩ���ĸ���,��������ϸ�µĽ��,��������ҡ�
????��������������,ԭ������:https://github.com/HarleysZhang/2019_algorithm_intern_information/blob/master/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E9%9D%A2%E8%AF%95%E9%A2%98.md
����Ұ
????��һ����Ԫ��ǰһ����Ԫ�ĸ��ܿռ�,����ͼ��ʾ:
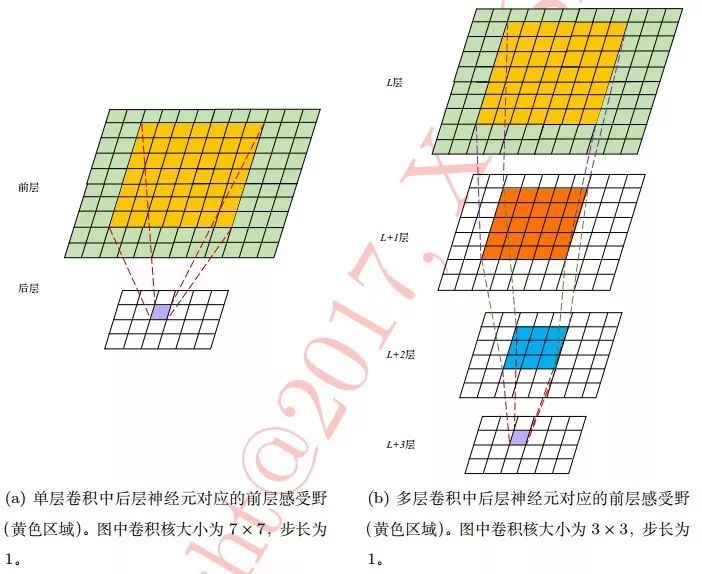
????ע��:С������(��33)ͨ�������ӿ�ȡ����������(��77)ͬ�ȹ�ģ�ĸ���Ұ,�������С����������������:
? ? 1��С�������������,������������Ƚ�����ǿ����������(model capacity)���Ӷ�(model complexity)
? ? 2����ǿ������������ͬʱ�����˲���������
������������
????���������еľ����˲�����ͨ������ѵ��������
????ͨ�������˵�����Լ�����������������Ľ���,���������ɻ�ȡͼ������ͬ��������;������һ���ģʽ��������Ϊ���и߲�����ġ������ʾ,Ҳ�����Զ�ѧϰ��ͼ��ĸ߲�������
CNNȨֵ��������
????����Ȩֵ���������˲�������,�˲����IJ����ǹ̶���,��������ͬ���˲���ȥɨһ��ͼ��,��ȡһ����������,�õ�feature map���ھ���������,ѧ����һ���˲���,���൱��������һ������,����˲�����ͼ���л���,����������ȡ,Ȼ�����н����������������ᱻ�ɼ�����������,�ͺñ������ˮƽ�ߡ�
CNN�ṹ�ص�
????�ֲ�����,Ȩֵ����,�ػ�����,���νṹ��
? ? 1���ֲ�����ʹ���������ȡ���ݵľֲ�����
? ? 2��Ȩֵ��������������ѵ���Ѷ�,һ��Filterֻ��ȡһ������,������ͼƬ(��������/�ı�) �н��о���
? ? 3���ػ���������νṹһ��,ʵ�������ݵĽ�ά,���Ͳ�εľֲ�������ϳ�Ϊ�ϸ߲�ε�����,�Ӷ�������ͼƬ���б�ʾ��
pooling������
????��������ƽ�Ʋ����ԡ���Ͽ�����������Сλ�Ƶ�����������
????��С����ͼ��С����ϲ�Կռ�ֲ���������²���,ʹ��һ����Ҫ�IJ������ͼ���������,��������Ϸ��ա�
????����Ͽ��Դ��������ԡ�����Ŀǰ����ϸ����õ�ԭ��֮һ��
????Reference
?(��)������Ӿ��Ĵ��������(���ࡢ��λ����⡢�ָ�
��������IJ����
????���������ɻ�ȡͼ������ͬ��������,����ϵȲ����ɶ���Щ���������ںϺͳ���,�������ɾ�������ϵȲ����Ķѵ�,����õ�����������ӷ�������(���Ե��������)���ɵ��߲������ʾ(���ɡ�ͷ����ģʽ)��
ʲô�������ݼ����ʺ����ѧϰ
????���ݼ�̫С,������������ʱ,���ѧϰ�����������ѧϰ�㷨,û���������ơ�
????���ݼ�û�оֲ��������,Ŀǰ���ѧϰ���ֱȽϺõ�������Ҫ��ͼ��/����/��Ȼ���Դ���������,��Щ�����һ�������Ǿֲ�����ԡ�ͼ���������������,�����ź�����λ��ϳɵ���,�ı������е�����ϳɾ���,��Щ����Ԫ�ص����һ��������,��ʾ�ĺ���ͬʱҲ���ı䡣����û�������ľֲ�����Ե����ݼ�,������ʹ�����ѧϰ�㷨���д������ٸ�����:Ԥ��һ���˵Ľ���״��,��صIJ����������䡢ְҵ�����롢��ͥ״���ȸ���Ԫ��,����ЩԪ�ش���,������Ӱ����صĽ����
ʲô����ݶ���ʧ����
????�������ѵ����,ͨ���ı���Ԫ��Ȩ��,ʹ��������ֵ�����ܱƽ���ǩ�Խ������ֵ,ѵ���ձ�ʹ��BP�㷨,����˼����,�����������ǩ�����ʧ����ֵ,Ȼ������������ÿ����Ԫ���ݶ�,����Ȩֵ�ĵ�����
????�ݶ���ʧ�����Ȩֵ���»���,ģ��ѵ���Ѷ����ӡ�����ݶ���ʧ��һ��ԭ����,���༤��������ֵ��ѹ�ں�С��������,�ڼ�������˽ϴ�Χ�Ķ��������ݶ�Ϊ0,���ѧϰֹͣ��
Overfitting���
????������ν�����,ָ����һ��ģ���ڸ���֮��,�����Ժܺõء����䡱ÿһ��ѵ����������������IJ��ֶ�������ȥ��ѵ���������е�ͨ�����ơ�����Ͼ��������:ģ����ѵ����������ʧ������С,Ԥ��ȷ�ʽϸ�;�����ڲ�����������ʧ�����Ƚϴ�,Ԥ��ȷ�ʽϵ͡�
Parameter Norm Penalties(���������ͷ�);Dataset Augmentation (���ݼ���ǿ);Early Stopping(��ǰ��ֹ);Parameter Tying and Parameter Sharing (���������������);Bagging and Other Ensemble Methods(Bagging ���������ɷ���);dropout;regularization;batch normalizatin���ǽ��Overfitting�ij����ֶΡ�
L1��L2����
??? L1 ����(L1 norm)��ָ�����и���Ԫ�ؾ���ֵ֮��,Ҳ�и����ƽС�ϡ��������ӡ�(Lasso regularization)������ ���� A=[1,-1,3], ��ô A �� L1 ����Ϊ |1|+|-1|+|3|�����ܽ�һ�¾���:
? ? 1��L1 ����: Ϊ x ��������Ԫ�ؾ���ֵ֮�͡�
? ? 2��L2 ����: Ϊ x ��������Ԫ��ƽ���͵� 1/2 �η�,L2 �����ֳ� Euclidean ������ Frobenius ����
? ? 3��Lp ����: Ϊ x ��������Ԫ�ؾ���ֵ p �η��͵� 1/p �η�. ��֧��������ѧϰ������,L1 ����ʵ����һ�ֶ��ڳɱ�����������ŵĹ���,���,L1 ��������ͨ����ɱ����������� L1 ����,ʹ��ѧϰ�õ��Ľ������ϡ�軯,�Ӷ�����������ȡ������
??? L1 ��������ʹȨֵ����ϡ��,����������ȡ��L2 �������Է�ֹ�����,����ģ�͵ķ���������
TensorFlow����ͼ
??? Tensorflow ��һ��ͨ������ͼ����ʽ����������ı��ϵͳ,����ͼҲ��������ͼ,���Ѽ���ͼ������һ������ͼ,Tensorflow �е�ÿһ�����㶼�Ǽ���ͼ�ϵ�һ���ڵ�,���ڵ�֮��ı������˼���֮���������ϵ��
BN(����һ��)������
?(1). ����ʹ�ø��ߵ�ѧϰ�ʡ����ÿ���scale��һ��,ʵ����ÿ����Ҫ��ѧϰ���Dz�һ����,ͬһ�㲻ͬά�ȵ�scale����Ҳ��Ҫ��ͬ��С��ѧϰ��,ͨ����Ҫʹ����С���Ǹ�ѧϰ�ʲ��ܱ�֤��ʧ������Ч�½�,Batch Normalization��ÿ�㡢ÿά��scale����һ��,��ô���ǾͿ���ֱ��ʹ�ýϸߵ�ѧϰ�ʽ����Ż���
????(2). �Ƴ���ʹ�ýϵ͵�dropout��?dropout�dz��õķ�ֹoverfitting�ķ���,������overfit��λ�����������ݱ߽紦,�����ʼ��Ȩ�ؾ��Ѿ����������ڲ�,overfit����Ϳ��Եõ�һ���Ļ��⡣����������ģ�ͷֱ�ʹ��10%��5%��0%��dropoutѵ��ģ��,��֮ǰ��40%-50%���,���Դ�����ѵ���ٶȡ�
????(3). ����L2Ȩ��˥��ϵ��������һ��������,�߽紦�ľֲ����������м�ά��Ȩ��(б��)�ϴ�,ʹ��L2˥�����Ի�����һ����,��������Batch Normalization,�Ϳ������ֵ������,�����н���Ϊԭ����5����
????(4). ȡ��Local Response Normalization�㡣����ʹ����һ��Normalization,��ʹ��LRN���Ե�û��ô��Ҫ�ˡ�����LRNʵ����Ҳû��ôwork��
?(5). Batch Normalization���������ݵķֲ�,�����Ǽ����,����ÿһ��������һ�����˾�ֵΪ0����Ϊ1�ķֲ�,�Ᵽ֤���ݶȵ���Ч��,���Խ�����������е��ݶ����⡣Ŀǰ�����϶���������,����BN��ԭʼ������Ϊ�Ļ�����Internal Covariate Shift(ICS)���⡣
ʲô���ݶ���ʧ�ͱ�ը,��ô���?
????��ѵ���϶������ģ��ʱ,һ�������ݶ���ʧ����(gradient vanishing problem)���ݶȱ�ը����(gradient exploding problem)��ע���ڷ�����,������ģ�Ͳ����϶�ʱ,�ݶ���ʧ���ݶȱ�ը�Dz��ɱ���ġ�
����������е��ݶȲ��ȶ���,����ԭ������ǰ����ϵ��ݶ��������ں�������ݶȵij˻��������ڹ���IJ��ʱ,�ͳ��������ڱ����ϵIJ��ȶ�������ǰ��IJ�Ⱥ���IJ��ݶȱ仯��С,�ʱ仯����,���������ݶ���ʧ���⡣ǰ���Ⱥ�����ݶȱ仯����,�������ݶȱ�ը���⡣
????����ݶ���ʧ���ݶȱ�ը����,���õ������¼�������:
????Ԥѵ��ģ�� + ��
????�ݶȼ��� + ����
????relu��leakrelu��elu�ȼ����
????BN����һ��
????CNN�еIJв�ṹ
????LSTM�ṹ
RNNѭ������������
????ѭ��������(recurrent neural network, RNN), ��ҪӦ��������ʶ������ģ�͡����������Լ�ʱ������������ϡ��ھ���Ӧ����,�����������ڲ�ͬ�Ŀռ�λ�ù�������,ѭ�����������ڲ�ͬ��ʱ��λ�ù�������,�Ӷ��ܹ�ʹ�����IJ����������ⳤ�ȵ����С�RNN���Կ�������ͬһ������ṹ��ʱ�������ϱ����ƶ�εĽ��,��������ƶ�εĽṹ��Ϊѭ����,������ѭ���������ṹ��RNN���ʵ������Ĺؼ���RNN����������������,һ����Ϊ��һʱ�̵�״̬,��һ����Ϊ��ǰʱ�̵�����������
ѵ��������ģ�Ͳ�����,�Ƿ�˵�����ģ����Ч,��ģ�Ͳ�������ԭ������Щ?
????��һ��������ģ�Ͳ�������ԭ���кܶ��ֿ���,�����������¼���:
????û�ж���������һ����
????û�м�����Ľ��������Ľ������Ԥ������������յ�ѵ�����Խ����
????����������Ԥ������
????����ʹ������
??? Batch Size���̫��
????ѧϰ����IJ��ԡ�
????���һ��ļ�����õIJ��ԡ�
????������ڻ��ݶȡ�����Relu�Ը�ֵ���ݶ�Ϊ0,����ʱ,0�ݶȾ��Dz�������
????������ʼ������
????����̫����ز���Ԫ��������
????����ش�,�ο������ӡ�
ͼ������ƽ����������ʲô?
?ƽ������(smoothing)Ҳ��ģ������(bluring),��Ҫ��������ͼ���е���������,ƽ���������õ���;����������ͼ���ϵ�����ʧ��,ƽ����Ҫʹ��ͼ���˲���������,�Ҹ�����Ϊ����ͼ��ƽ����ͼ���˲���ϵ����,��Ϊͼ��ƽ�����õķ�������ͼ���˲�������OpenCV3�г��õ�ͼ���˲��������¼���:
? ? �����˲�����BoxBlur����
????��ֵ�˲�(����ƽ���˲�)����Blur����
????��˹�˲�����GaussianBlur����(��˹��ͨ�˲���ģ��,��˹��ͨ�˲�����)
????��ֵ�˲�����medianBlur����
????˫���˲�����bilateralFilter����?ͼ��������Ϊ��ͻ����ʾͼ��ı߽������ϸ��,��ͼ����ʵ�ֵķ�����ͨ���������Ӻ��˲���ʵ�ֵġ���Canny���ӡ�Sobel���ӡ�Laplacian�����Լ�Scharr�˲�����
VGGʹ��2��3*3����������������?
????(1). ��������������������33��������1��55����ӵ�и��ٵIJ�����,ֻ�к��ߵ�2?3?35?5=0.72��������Ч����һ����,����33�ľ����㴮���൱��һ��55�ľ�����,����Ұ�Ĵ�С����5��5,��1�����ػ����Χ5*5�����ز�������������ͼ���ɶ�̬ͼ��,������������3��3������ѵ�(û�пռ�ػ�)��5��5����Ч����Ұ��
![]()
2��3*3������
????(2). ����ķ����Ա任��2��33������ӵ�б�1��55���������ķ����Ա任(ǰ�߿���ʹ������ReLU�����,������ֻ��һ��),ʹ�þ����������������ѧϰ������ǿ��
paper�и�������ؽ���:���������IJ����7��7����Ч����Ұ����ô���ǻ����ʲô?����ͨ��ʹ������3��3������Ķѵ����滻����7��7�㡣����,���ǽ��������������������,�����ǵ�һ��,��ʹ�þ��ߺ��������б��ԡ����,���Ǽ��ٲ���������:��������3��3�����ѵ�������������C��ͨ��,�ѵ�������IJ���Ϊ3(32C2)=27C2��Ȩ��;ͬʱ,����7��7�����㽫��Ҫ72C2=49C2������,��������81%������Կ����Ƕ�7��7�����˲�����������,��ʹ����ͨ��3��3�˲���(������֮��ע�������)���зֽ⡣
????�˻ش���Բο�TensorFlowʵսp110,���Ϻܶ�ش�˵�IJ�ȫ��
??? Relu��Sigmoid����������?
??? Sigmoid������ʽ����:$\sigma (x)=\frac{1}{1+exp(-x)}$
??? ReLU�������ʽ����:
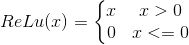
relu�����
??? relu�������� ReLU �����Ҫô�� 0, Ҫô�����뱾������Ȼ���̼�,��ʵ����Ч�����á������Ͽ��˺ܶ�汾�Ľ���,�дӳ���ʵ������Ҳ�д���ѧ�Ϸ���,�����˸���ԱȽ�ֱ�Ļش�,����:
1��ReLU���������,���Լ��ٺܶ������������������ݶ�ʱ,�漰����,��������Խϴ�,����ReLU�����,���Խ�ʡ�ܶ������;
? 2�������ݶ���ʧ���⡣�����������,sigmoid��������ʱ,�����ͻ�����ݶ���ʧ����(��sigmoid�ӽ�������ʱ,�任̫����,��������0,��������������Ϣ��ʧ),�Ӷ��������������ѵ����
? ? 3�����Ի�����������ķ�����Relu��ʹһ������Ԫ�����Ϊ0,����������������ϡ����,���Ҽ����˲�����������ϵ,�����˹��������ķ�����
? 4�����sigmoid�ͺ���,ReLU��������������ݶ��½�����������
????�����
????ReLUΪʲô��SigmoidЧ����
��������Ȩֵ����������?
????Ȩֵ(Ȩ��)�������������LeNet5ģ��������ġ���CNNΪ��,�ڶ�һ��ͼƫ���о����Ĺ�����,ʹ�õ���ͬһ�������˵IJ���������һ��3��3��1�ľ�����,�����������9���IJ���������ͼ����,��������Ϊͼ����λ�õIJ�ͬ���ı�������ڵ�Ȩϵ����˵����ֱ��һЩ,������һ�������˲��ı�����Ȩϵ��������¾�����������ͼƬ(��ȻCNN��ÿһ�㲻��ֻ��һ�������˵�,����˵ֻ��Ϊ�˷�����Ͷ���)��
????�����
????�������CNN�е�Ȩֵ����
��fine-tuning(��ģ�͵�����),ΪʲôҪ�����������Ȩֵ?
????ʹ��Ԥѵ��ģ�͵ĺô�,��������ѵ���õ�SOTAģ��Ȩ��ȥ��������ȡ,���Խ�ʡ����ѵ��ģ�ͺ͵��ε�ʱ�䡣
????����Ϊʲôֻ�����������Ȩ��,����Ϊ:(1). CNN�и������ײ��IJ�(����ģ��ʱ�����ӵ�ģ���еIJ�)������Ǹ���ͨ�õĿɸ�������,�������������IJ�(������ӵ�ģ���еIJ�)������Ǹ�רҵҵ��������������Щ��רҵ����������������,���������������ݼ��ϵ�����������(2). ѵ���IJ���Խ��,����ϵķ���Խ�ܶ�SOTAģ��ӵ�г���ǧ��IJ���,��һ����������ݼ���ѵ����ô��������й���Ϸ��յ�,����������ݼ���Imagenet������
????�����
????Python���ѧϰp127.
ʲô��dropout?
??? dropout���Է�ֹ�����,dropout����˵����:������ǰ����ʱ��,��ij����Ԫ�ļ���ֵ��һ���ĸ���pֹͣ����,��������ʹģ�͵ķ����Ը�ǿ,��Ϊ����������ijЩ�ֲ���������
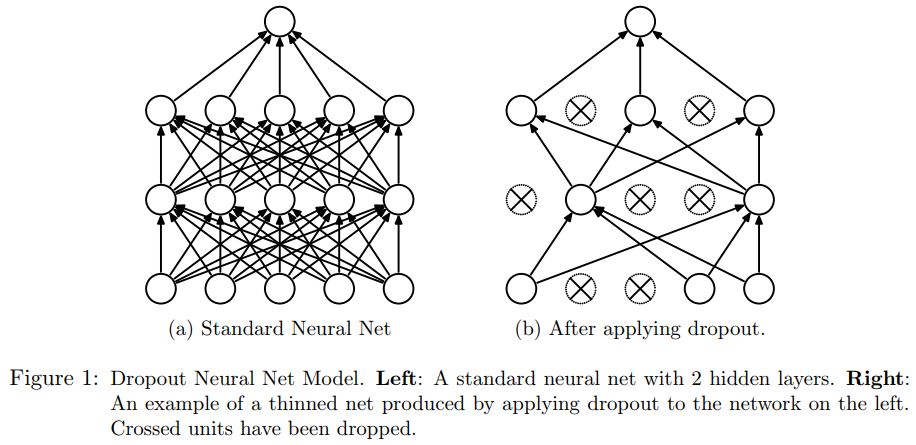
dropouֱ��չʾ
?dropout���幤������
????�� ��������Ϊ��,������������:�������Ȱ���������xͨ������ǰ��,Ȼ�������һ������θ��²������������ѧϰ��ʹ��dropout֮��,���̱������:
????(1). �������(��ʱ)ɾ��������һ���������Ԫ,���������Ԫ���ֲ���(ͼ3������Ϊ������ʱ��ɾ������Ԫ);?
????(2). Ȼ�������xͨ���ĺ���������ǰ������,Ȼ��ѵõ�����ʧ���ͨ���ĵ����練����һС��ѵ������ִ����������̺�,��û�б�ɾ������Ԫ�ϰ�������ݶ��½������¶�Ӧ�IJ���(w,b);
?????(3). Ȼ���ظ���һ����:
? ? 1���ָ���ɾ������Ԫ(��ʱ��ɾ������Ԫ����ԭ��û�и���w����,��û�б�ɾ������Ԫ�Ѿ���������)
? ?2�� �����ز���Ԫ�����ѡ��һ��һ���С���Ӽ���ʱɾ����(ͬʱ���ݱ�ɾ����Ԫ�IJ���)��
? ? 3����һС��ѵ������,��ǰ��Ȼ������ʧ����������ݶ��½������²���(w,b) (û�б�ɾ������һ���ֲ����õ�����,ɾ������Ԫ�������ֱ�ɾ��ǰ�Ľ��)��
dropout���������е�Ӧ��
?(1). ��ѵ��ģ�ͽ�
? ? ���ɱ����,��ѵ�������е�ÿ����Ԫ��Ҫ����һ����������,������ʹ���dropout����ıȽ�ͼ������ʾ:
![]()
dropout��ѵ����
????(2). �ڲ���ģ�ͽ�
????Ԥ��ģ�͵�ʱ��,�����ǵ�ǰ����,ÿ����Ԫ��Ȩ�ز���Ҫ���Ը���p��
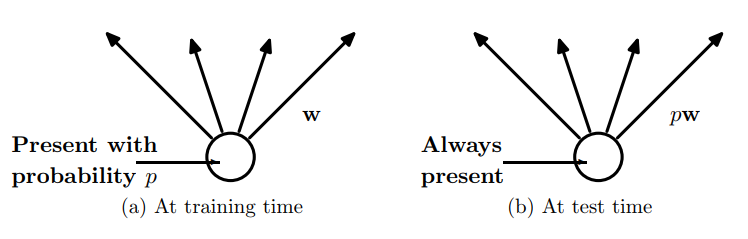
dropout�ڲ���ģ��ʱ
���ѡ��dropout �ĸ���
??? input ��dropout�����Ƽ���0.8, hidden layer �Ƽ���0.5, ����Ҳ������һ����������ȡֵ��(All dropout nets use p = 0.5 for hidden units and p = 0.8 for input units.)
????�����
????[Dropout:A Simple Way to Prevent Neural Networks from Overfitting]
????���ѧϰ��Dropoutԭ������
HOG�㷨ԭ������
�����ݶ�ֱ��ͼ(Histogram of Oriented Gradient, HOG)������һ���ڼ�����Ӿ���ͼ������������������������������ӡ���ͨ�������ͳ��ͼ��ֲ�������ݶȷ���ֱ��ͼ�����������������ѧϰȡ�óɹ�֮ǰ,Hog�������SVM���������㷺Ӧ����ͼ��ʶ����,�����˼���л���˽ϴ�ijɹ���
??HOG����ԭ��
??? HOG�ĺ���˼���������ľֲ����������ܹ�����ǿ�ݶȻ��Ե����ķֲ���������ͨ��������ͼ��ָ��С����������(��Ϊcells),ÿ��cell����һ�������ݶ�ֱ��ͼ����cell��pixel�ı�Ե����,��Щֱ��ͼ����Ͽɱ�ʾ��(�����Ŀ���Ŀ��)�����ӡ�Ϊ����ȷ��,�ֲ�ֱ��ͼ����ͨ������ͼ����һ���ϴ�����(��Ϊblock)�Ĺ�ǿ��Ϊmeasure���Աȱ���,Ȼ�������ֵ(measure)��һ�����block�е�����cells�������һ����������˸��õ�����/��Ӱ�����ԡ����������������,HOG�õ��������ӱ����˼��κ�ѧת��������(�������巽��ı�)�����HOG�����������ʺ��˵ļ�⡣
??? HOG������ȡ�������ǽ�һ��image:
? ? 1���ҶȻ�(��ͼ����һ��x,y,z(�Ҷ�)����άͼ��)
? ? 2�����ֳ�Сcells(2*2)
? ? 3������ÿ��cell��ÿ��pixel��gradient(��orientation)
? ? 4��ͳ��ÿ��cell���ݶ�ֱ��ͼ(��ͬ�ݶȵĸ���),�����γ�ÿ��cell��descriptor��
?HOG������ⲽ��
![]()
HOG������ⲽ��
????��ɫ�ռ��һ�������C>�ݶȼ��㡪������->�ݶȷ���ֱ��ͼ������->�ص���ֱ��ͼ��һ���������C>HOG����
????�����
????HOG�������-����
�ƶ������ѧϰ���֪����Щ,�ù���Щ?
????֪������TensorFlow Lite��С��MACE����Ѷ��ncnn��,Ŀǰ��û���ù���
�����������ķ�������
????�ͷ�ֹģ����ϵķ�������,�����ģ���ںϷ�����
BN�㷨,ΪʲôҪ�ں���Ӽ�٤���ͱ���,���ӿ�����?
????���ġ�scale and shift����������Ϊ������ѵ������������⡱�����BN�ܹ��п��ܻ�ԭ��������롣����Ҳ���ԡ�
�����������
�����ʵ��ȥ���Ի�����Ԫ�Ľṹ�����Ϊ��������ļ�Ȩ��,�����������һ������ģ�͡������ÿһ����Ԫ(Ҳ����������Ľڵ�)�����ͨ��һ�������Ժ���,��ô�����������ģ��Ҳ�Ͳ��������Ե���,��������Ժ������Ǽ�����������ļ������:ReLU������sigmoid������tanh������
??? ReLU����:$f(x)=max(x,0)$
??? sigmoid����:$f(x)=\frac{1}{1+e^{-x}}$
??? tanh����:$f(x)=\frac{1+e^{-2x}}{1+e^{-2x}}$
������ͳػ�����ʲô����
1���������в���,�ػ���û�в���
? ? 2������������ڵ������Ȼ�ı�,�ػ��㲻��ı�ڵ��������,������������С�ڵ����Ĵ�С��
����������������㷽��
????������������ά����96963,��һ�������ʹ�óߴ�Ϊ55�����Ϊ16�Ĺ�����(�����˳ߴ�Ϊ55������������Ϊ16),��ô��������IJ�������Ϊ553*16+16=1216��
���������������
????�����е�����ͼ��С���㷽ʽ������,�ֱ��ǡ�VALID���͡�SAME��,�����ͳػ�������,�������Ľ��������ȡ������ʽ:O = (W-F+2P)/S+1,����ͼƬ(Input)��СΪI=WW,������(Filter)��СΪFF,����(stride)ΪS,���(Padding)��������ΪP��
1��SAME��䷽ʽ:������ء�conv2d�������á�
2��VALID��䷽ʽ:���������,Maxpooling2D�������á�"SAME"������ʽ,��������55ͼ��,ͼ���ÿһ���㶼��Ϊ�����˵����ġ����õ�55�Ľ��,ͨ����˵:������ԭͼ��㲹һȦ0,��ԭͼ�ĵ�һ����Ϊ����������,��һȦ0����,������һȦ0������ͼ��ʾ:
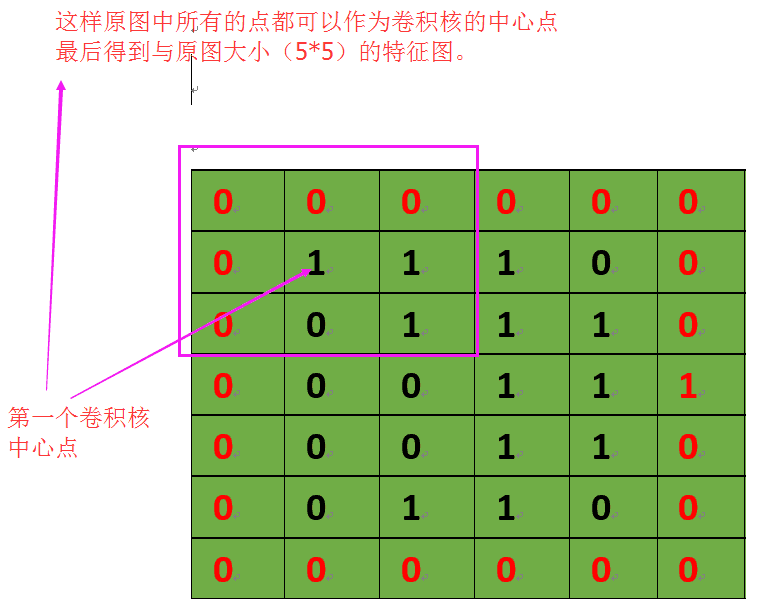
������䷽ʽ
������Ϊʲô�ý�������ʧ����
????�ж�һ����������������������ж�ӽ�,������(cross entroy)�dz��õ����з���֮һ�������ؿ̻����������ʷֲ�֮��ľ���,�Ƿ���������ʹ�ñȽϹ㷺��һ����ʧ�����������������ʷֲ�p��q,ͨ��q����ʾp�Ľ����ع�ʽΪ:H(p,q)=?��p(x)logq(x)
??? softmax��ʽдһ��:

????softmax(y){i} = \frac{e^{yi}}{\sum{j=1}^{n}e^{yj}} softmax��ʽ
1*1��������Ҫ���������¼���
? 1����ά( dimension reductionality )������,һ��500 * 500�Һ��depthΪ100 ��ͼƬ��20��filter����11�ľ���,��ô����Ĵ�СΪ500500*20��
2����������ԡ�������֮��������,1*1�ľ�����ǰһ���ѧϰ��ʾ�������˷����Լ���( non-linear activation ),��������ı�������;
Ŀ�����������
????ȷ�ʡ��ٻ��ʡ�F1
????��������:
??? True Positive(������, TP):������Ԥ��Ϊ������.
??? True Negative(�渺��, TN):������Ԥ��Ϊ������.
??? False Positive(������, FP):������Ԥ��Ϊ������ �� �� (Type I error).
??? False Negative(�ٸ�����, FN):������Ԥ��Ϊ������ �� ©�� (Type II error).
????����(ȷ��)P = TP/(TP+FP) ��ȫ��(�ٻ���)R = TP/(TP+FN) ȷ��������ģ���ж�,����Ԥ��Ϊ�����Ľ����,�ж�����������;�ٻ�����������ģ���ж�ȫ,����Ϊ���������,�ж��ٱ����ǵ�ģ��Ԥ��Ϊ�������Բ���PΪ���ᡢ��ȫ��RΪ������ͼ,�͵õ��˲���-��ȫ������,���**��P-R������,��ʾ�ĸ����ߵ�ͼ��Ϊ��P-R��ͼ�����ʡ���ȫ�����ܵ����ܶ���,���ˡ�ƽ��㡰(BEP),��Ϊ���õ���F1����**:$$F1 = \frac{2PR}{P+R} = \frac{2*TP}{��������+TP-TN}$$
??? F1������һ����ʽ:$F_{\beta}$,�������DZ�����Բ���/��ȫ�ʵ�ƫ��,��ʽ����:$$F_{\beta} = \frac{1+\beta ^{2}PR}{(\beta ^{2}*P)+R}$$ $\beta >1$�Բ�ȫ���и���Ӱ��,$\beta < 1$�Բ����и���Ӱ�졣
????��ͬ�ļ�����Ӿ�����,����������в�ͬ��ƫ��,������ijһ�������һ����ֵ�������,Ŭ��������һ�������Ŀ������,mAP(mean Average Precision)��Ϊһ��ͳһ��ָ�꽫�����ִ����˿��ǡ�
mapָ�����
????������˵����,��Ŀ������,����ÿ��ͼƬ���ģ�ͻ�������Ԥ���(Զ����ʵ��ĸ���),����ʹ��IoU(Intersection Over Union,������)�����Ԥ����Ƿ�Ԥ��ȷ�������ɺ�,����Ԥ��������,��ȫ��R�ܻ�����,�ڲ�ͬ��ȫ��Rˮƽ�¶�ȷ��P��ƽ��,���õ�AP,����ٶ������������ռ������ƽ��,���õ�mAPָ�ꡣ
??������IOU
????������(Intersection-over-Union,IoU),Ŀ������ʹ�õ�һ������,�Dz����ĺ�ѡ��(candidate bound)��ԭ��ǿ�(ground truth bound)�Ľ�����,�����ǵĽ����벢���ı�ֵ���������������ȫ�ص�,����ֵΪ1�����㹫ʽ����:
????����ʵ������:
????# candidateBound = [x1, y1, x2, y2]
????def calculateIoU(candidateBound, groundTruthBound):
????? ? cx1 = candidateBound[0]
????? ? cy1 = candidateBound[1]
????? ? cx2 = candidateBound[2]
????? ? cy2 = candidateBound[3]
????? ? gx1 = groundTruthBound[0]
????? ? gy1 = groundTruthBound[1]
????? ? gx2 = groundTruthBound[2]
????? ? gy2 = groundTruthBound[3]
????? ? carea = (cx2 - cx1) * (cy2 - cy1) #C�����
????? ? garea = (gx2 - gx1) * (gy2 - gy1) #G�����
????? ? x1 = max(cx1, gx1)
????? ? y1 = min(cy1, gy1)? # ԭ��Ϊ(0, 0),����������min����max
????? ? x2 = min(cx2, gx2)
????? ? y2 = max(cy2, gy2)
????? ? w = max(0, (x2 - x1))
????? ? h = max(0, (y2 - y1))
????? ? area = w * h #C��G�����
????? ? iou = area / (carea + garea - area)
????? ? return iou
������ǿ����,����������ǿ������������ǿ��ʲô����?
????����������ǿ����:
��ת:Fliplr,Flipud����ͬ����ת180��,�������ƾ���ķ���,�����ھ����е�ӳ������,����ˮƽ�����¾��淭ת��
��ת:rotate��˳ʱ��/��ʱ����ת,�����ת90-180��,�������ֱ�Եȱʧ���߳�������,����ת45�ȡ�
??����:zoom��ͼ����Ա��Ŵ����С,imgaug�����Scal����ʵ�֡�
????�ü�:crop��һ�������ü�,����������:�����ͼ����ѡ��һ����,Ȼ���ⲿ��ͼ��ü�����,Ȼ�����Ϊԭͼ��Ĵ�С��
?ƽ��:translation��ƽ���ǽ�ͼ������x����y����(������������)�ƶ���������ƽ�Ƶ�ʱ����Ա������м���,����˵����Ϊ��ɫ�ȵ�,��Ϊƽ�Ƶ�ʱ����һ����ͼ���ǿյ�,����ͼƬ�е�������ܳ����������λ��,����˵ƽ����ǿ����ʮ�����á�
???����任:Affine������:ƽ��(Translation)����ת(Rotation)������(zoom)������(shear)��
��������:�����ͨ��������������ѧϰ��Ƶ������ʱ��,Ϊ������Ƶ�����Ĺ����,���������������������������Щ��Ƶ������imgaug��ʹ��GaussianBlur������
���ȡ��Աȶ���ǿ:����ͼ��ɫ�ʽ�����ǿ�IJ���
��:Sharpen��imgaug��ʹ��Sharpen������
????������ǿ������,һ����������ǿ,һ����������ǿ:
������ǿ :?ֱ�Ӷ����ݼ����д���,���ݵ���Ŀ������ǿ���� x ԭ���ݼ�����Ŀ ,���ַ��������������ݼ���С��ʱ��
?������ǿ :?������ǿ�ķ�������,��� batch ����֮��,Ȼ������batch�����ݽ�����ǿ,����ת��ƽ�ơ����۵���Ӧ�ı仯,������Щ���ݼ����ܽ������Լ��������,���ַ��������ڴ�����ݼ�,�ܶ����ѧϰ����Ѿ�֧��������������ǿ��ʽ,���ҿ���ʹ��GPU�Ż����㡣
ROI Pooling�滻ΪROI Align
,������ԭ��
????faster rcnn��roi pooling�滻Ϊroi alignЧ����������
????ROI Poolingԭ��
????ROI Alignԭ��
????Reference
????1.���ѧϰ�е�������ǿ
????Reference
? ? 1����Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift���Ķ��ʼ���ʵ��
? ? 2�����ѧϰ�� Batch NormalizationΪʲôЧ����
? ? 3��������ѧϰ�е��ݶ���ʧ����ըԭ����������
Python/C/C++/���������/ͼ��������
?static�ؼ�������
????��ȫ�ֱ���ǰ���Ϲؼ���static,ȫ�ֱ����Ͷ���Ϊһ��ȫ�־�̬����,ȫ�־�̬���������������ļ�֮���Dz��ɼ���,������ΧΪ�Ӷ���֮����ʼ,���ļ���β��
????�ں�����������ǰ��static,�����ͱ�Ϊ��̬����,��̬����ֻ�����������ļ���ʹ��,���������ļ����á�
C++ָ������õ�����
????ָ�����Լ����ڴ�ռ�,������ֻ��һ������,������Pythondz���������������
????�����ڿ�����, ���ñ������ӵ�һ��Ϸ����ڴ��ַ;
????һ�����ñ���ʼ��Ϊһ������,�Ͳ���ָ����һ������ָ��������κ�ʱ��ָ���κ�һ������;
????���ñ����ڴ���ʱ����ʼ����ָ��������κ�ʱ���ʼ����
????C++����������������
????���������빹�캯����Ӧ,����������������һ������ij�Ա����,������ÿ��ɾ���������Ķ���ʱִ�С����������������������������ȫ��ͬ��,ֻ����ǰ����˸����˺�(~)��Ϊǰ,�����᷵���κ�ֵ,Ҳ���ܴ����κβ�����������������������������(����ر��ļ����ͷ��ڴ��)ǰ�ͷ���Դ��
C++��̬�������麯��������
????��̬�����ڱ����ʱ����Ѿ�ȷ������ʱ��,�麯�������е�ʱ��̬���麯����Ϊ�����麯��������,���õ�ʱ�������һ���ڴ濪����
????++i��i++����
????++i ������1,�ٷ���,i++,�ȷ��� i,������1.
????const�ؼ�������
??? const���͵Ķ����ڳ���ִ���ڼ䲻�ܱ��ĸı䡣
Pythonװ��������
????װ������������һ�� Python ��������,���������������������ڲ���Ҫ���κδ����ĵ�ǰ�������Ӷ����,װ�����ķ���ֵҲ��һ������/�������������������������ij���,����:������־�����ܲ��ԡ������������桢Ȩ��У��ȳ���,װ�����ǽ����������ľ�����ơ�����װ����,���ǾͿ��Գ���������뺯�����ܱ����ص���ͬ���뵽װ�����в��������á������Ľ�,װ���������þ���Ϊ�Ѿ����ڵĶ������Ӷ���Ĺ��ܡ�
���������߳�����
????�߳��ǽ��̵�һ����,һ������������һ���߳�;
????���ڲ���ϵͳ��˵,һ���������һ������,�����ڵġ�������Ϊ�߳�;
????���̺߳Ͷ�������IJ�ͬ����,�������,ͬһ������,������һ�ݿ���������ÿ��������,����Ӱ��,�����߳���,���б������������̹߳���,����,�κ�һ�����������Ա��κ�һ���߳���,���,�߳�֮�乲����������Σ�����ڶ���߳�ͬʱ��һ������,�����ݸ������ˡ�
????���̼���á�ͨѶ���л��������ȶ��̴߳�,�����̵߳ı����ᵼ������Ӧ�õ��˳���
????���ڴ���IO,�����ʱ������Ҫ���û������Ȳ���ʱ,ʹ�ö��߳����������ϵͳ�IJ����Ժ��û����������Ӧ�Ӷ�����Ѻ��ԡ�
map��reduce�����÷�������
? ?1�� map����������������,һ���Ǻ���,һ����Iterable,map������ĺ����������õ����е�ÿ��Ԫ��,���������Ϊ�µ�Iterator����,��ʾ����������:
????# ʾ��1
????def square(x):
????? ? return x ** 2
????r = map(square, [1, 2, 3, 4, 5, 6, 7])
????squareed_list = list(r)
????print(squareed_list)? # [1, 4, 9, 16, 25, 36, 49]
????# ʹ��lambda����������Ϊһ�д���
????list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
????# ʾ��2
????list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9]))��#��['1', '2', '3', '4', '5', '6', '7', '8', '9']
?ע��map�������ص���һ��Iterator(��������),Ҫͨ��list����ת��Ϊ�����б��ṹ��map()��Ϊ�߽���,��ʵ�����ǰ������������ˡ�
? ? 2��reduce()����Ҳ������������,һ���Ǻ���(��������),һ��������,��map��ͬ����reduce�ѽ�����������е���һ��Ԫ�����ۻ�����,Ч������:reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4) ʾ����������:
????from functools import reduce
????CHAR_TO_INT = {
????? ? '0': 0,
????? ? '1': 1,
????? ? '2': 2,
????? ? '3': 3,
????? ? '4': 4,
????? ? '5': 5,
????? ? '6': 6,
????? ? '7': 7,
????? ? '8': 8,
????? ? '9': 9
????}
????def str2int(str):
????? ? ints = map(lambda x:CHAR_TO_INT[x], str)? # str������Iterable����
????? ? return reduce(lambda x,y:10*x + y, ints)
????print(str2int('0'))
????print(str2int('12300'))
????print(str2int('0012345'))? # 0012345
Python�����dz��������
1��ֱ�Ӹ�ֵ:��ʵ���Ƕ��������(����)��
? ? 2��dz����(copy):����������,���´��������ڲ����Ӷ�����copydz����,û�п����Ӷ���,����ԭʼ���ݸı�,�Ӷ����ı䡣
3�����(deepcopy):copy ģ��� deepcopy ����,��ȫ�����˸��������Ӷ���,��������ȫ�����ġ����,��������������Զ���Ŀ���,����ԭʼ����ĸı䲻�����������κ���Ԫ�صĸı䡣��һ��ʾ������,��������dz�����������������:
????#!/usr/bin/Python3
????# -*-coding:utf-8 -*-
????import copy
????a = [1, 2, 3, ['a', 'b', 'c']]
????b = a? # ��ֵ,�����������
????c = copy.copy(a)? # dz����
????d = copy.deepcopy(a)? # ���
????a.append(4)
????a[3].append('d')
????print('a = ', a)
????print('b = ', b)
????print('c = ', c)
????print('d = ', d)? # [1, 2, 3, ['a', 'b', 'c']]
????�����������:
????a = [1, 2, 3, ['a', 'b', 'c', 'd'], 4] b = [1, 2, 3, ['a', 'b', 'c', 'd'], 4] c = [1, 2, 3, ['a', 'b', 'c', 'd']] d = [1, 2, 3, ['a', 'b', 'c']]
ͼ������
����ҪӰ��ͼ���еĵ�Ƶ����,��Ӱ��ͼ���еĸ�Ƶ����������ҪĿ��������:
? ? 1����ǿͼ���Ե,ʹģ����ͼ���ø�������,��ɫ�������ͻ��,ͼ���������������,�������ʺ����۹۲��ʶ���ͼ��;
? ? 2����������,Ŀ������ı�Ե����,�Ա�����ȡĿ��ı�Ե����ͼ����зָĿ������ʶ��������״��ȡ��,��һ����ͼ������������춨������
????ͼ����һ�������ַ���:
? ? 1���ַ�
? ? 2����ͨ�˲���
????һ����˵,ͼ���������Ҫ���������Ƶ����,�������ڵ�Ƶ����Ҫ�ڸ�Ƶ��,ͬʱͼ���Ե��ϢҲ��Ҫ���������Ƶ���֡��⽫����ԭʼͼ����ƽ������֮��,ͼ���Ե��ͼ������ģ����������֡�Ϊ�˼��������Ч����Ӱ��,����Ҫ����ͼ������,ʹͼ��ı�Ե���������ͼ��������Ŀ����Ϊ��ʹͼ��ı�Ե���������Լ�ͼ���ϸ�ڱ������,����ƽ����ͼ����ģ���ĸ���ԭ������Ϊͼ���ܵ���ƽ�����������,��˿��Զ������������(��������)�Ϳ���ʹͼ���������������������źŵı仯��,�ɸ���Ҷ�任�������ʿ�֪,��������н�ǿ��Ƶ�������á���Ƶ����������,ͼ��ģ����ʵ������Ϊ���Ƶ������˥��,��˿����ø�ͨ�˲�����ʹͼ����������Ҫע���ܹ�����������ͼ������нϸߵ������,������ͼ������ȷ�������,�Ӷ�ʹ���������ӵı��źŻ�Ҫ��,���һ������ȥ��������������ٽ���������
????Reference
????ͼ����ǿ-ͼ����
numpy��˺����
????����ʶ��ij�����,����10512��feature map,�������1000512�����������ŷ�Ͼ���ȥƥ��10512��feature map,�������1000512�����������ŷ�Ͼ���ȥƥ��101000������,�õ����output��
����ѧϰ
????Focal Loss ����һ��
????���ݲ�ƽ����ô��?
????AUC������
????AUC�ļ��㹫ʽ