�����Ķ��ʼ�(6):Self-Supervised Convolutional Subspace Clustering Network,�Լල����������
ǰ��
���Ե�ʱ����������Ķ�������һ֪��� �����ض�һ�鲢��¼�µļ��⡣
ժҪ
���������������:
- ���������Ա�����ӿռ������ڵ�ά�����ӿռ�IJ������ݵ�ѧϰ�еõ��˹㷺��Ӧ�á�Ȼ��,�ӿռ������������ܵ�������,��Ϊʵ�ʵ�ԭʼ�Ӿ����ݲ�һ�������������������ӿռ��С�
- ��һ����,����������(ConvNet)�ѱ�֤���Ǵ��Ӿ���������ȡ������������������,��ѵ��������ConvNetͨ����Ҫ�����ı������,�����ӿռ����Ӧ�����Dz����õġ�
���������S2ConvSCN�������
- ����ģ��ConvNet������ȡ��ѧϰ����
- �Ա�ʾģ�������ӿռ����
- ����ģ�������Լල,����һ��˫���Լල����,ͨ��������ʧ�ල����ģ���ѵ��,ͨ��������ʧ�ල�Ա���ģ�͵�ѵ��
1 ���
�ԡ���Ҫ��������:
�����ӿռ����������ķ�չ��ȡ���˾�ijɹ�,������ʵ�����ݲ�һ���������ӿռ�ģ����һ��,����ʵ��Ӧ���е������Էdz����ޡ�����,������ͼ�������,ʵ�ʵ�����ͼ��ͨ���Dz������,���ҳ�����������������ƺͱ���ı仯���ӿռ����ܴ���ͬһ������Ӧ��ͼ����λ�������ӿռ���������Ȼ���������ͼ�����+�ӿռ����ļ���,�����ֲ�����ģ������������Χ�����ݱ仯,����Ρ�ƽ�Ƶȡ���һ�ַ�����,��ִ���ӿռ����֮ǰ,��Ϊ��Ϊͼ����ƵIJ���������,����SIFT��HOG��PRICoLBP��Ȼ��,�����������ϻ���ʵ���϶�û��֤�ݱ�����Щ������ѭ�����ӿռ�ģ�͡�
����������������֮ǰ��˵��������ע��Ϣ��Ϊ����û�б�����ݵ�����½�������ѧϰ,�������������,�����ӿռ䲢�������ݵ��Ա��Ҳ���Ƕ�ÿ��������������������������������ϱ���,�Ӷ�֧�־���ģ���ѵ����Ȼ��,����ȱ����Ч�ļල,�����ַ����к���ѧϰ���õ�������ʾ��
ģ����
����Ͷ�塣���������һ�ֶ˵��˿�ѵ����ͬʱ��������ѧϰ���ӿռ����Ŀ��,��Ϊ�Լල�����ӿռ�������硣����������,����ʹ�õ�ǰ�ľ����������Ҽල����ѧϰ�����ұ���ģ���ѵ��,���ܹ���������ӿռ��������ܡ������ر���������������Լලģ��:
-
����ģ��,��ʹ�õ�ǰ�ľ��������ල�Ա���ϵ����ѧϰ��ͨ���յ��Ա��������affinity���������ݻ���,���ල���γ����������ĵ�ǰ���ǩһ�µ����ݻ��֡�
-
����ģ��,��ʹ�õ�ǰ�ľ��������ල����ѧϰ��ѵ��������ͨ����С��������ѧϰģ����ѵ���ķ�����������;������ɵĵ�ǰ���ǩ֮��ķ��������ʵ�ֵġ�
���ѵ�������������ʾ�������Ա�������ݷָ�����ѧϰ�����й�ͬѧϰ�ͽ���ȷ���ġ��Ӹ����Ͻ�,��ʼ�ľ���������ʵ�����ݷָ��ȫ�Ǻ�,��˳�ʼ�����Ҽල���ѵ���������������,����ѧϰ�����������Ҽල������,��Ϊ����ȷ��ǩ�����ݲ������õ���Ϣ���Ľ����������ʾ������ѧϰ���õ����ұ���,�Ӷ��������õ����ݷָ
2 ��ع���
2.1 ��ԭʼ�ռ�ľ���
�ԡ�
2.2 ��Feature space���ӿռ����
��һ������ʹ��DZ�������ռ�,ͨ��Mercer���յ���ͨ������ֽ�����ڶ�������ʹ����ʽ�����ռ�,ͨ���ֶ�������ȡ��ƻ��������ѧϰ��
DZ�������ռ�
�����������������˼�����ԭʼ����ӳ�䵽һ����ά��DZ�������ռ�,������ռ��н����ӿռ����,����,�ں�ϡ���ӿռ������ͺ˵��ȱ�ʾ������ʹ����Ԥ����Ķ���ʽ��˹�ˡ�Ȼ�����ܱ�֤����ЩԤ������յ���DZ�������ռ��е�������Ȼλ�ڵ�ά�ӿռ��С�
��һ�ַ���ͨ������ֽ����DZ�������ռ䡣��������Ա任��������ĵ��ȱ�ʾ;�����Ա任��ϡ���ʾ���������Ż���Ȼ��,ѧϰ���Ա任�ı�ʾ������Ȼ���ޡ�
��ʽ�����ռ�
���ѧϰ��һ�ֶ˵��˿�ѵ���ķ�ʽѧϰ�߲�������ǿ�����������˴������о���Ȥ[10,15]��������,��һЩ�о������ѧϰ����Ӧ�����ӿռ�����е�������ȡ������,
- ��һ��ȫ���ӵ�����Զ�����������,����������ֹ�����������(����SIFT��HOG����)��ϡ������ұ���ģ��
- һ�־����Դ�ģ�͵ĵ��Ӿ����Ա������硣��Ȼ�Ѿ������˺ܺõľ��ྫ��,������Щ������Ȼ�Ǵ��ŵ�,��Ϊû�н��������п������õļල��Ϣ��������ѧϰ����,Ҳû�п�����һ��������ѧϰ���ӿռ������ȫ��ϵ������Ż���ܡ�
- ����һ��,����һ�������ӿռ��ض����������ӿռ��ض�����������ȶԿ����硣Ȼ��,��������Ҫʹ��ÿ���ӿռ��ά��,��ͨ����δ֪�ġ�
��S2ConvSCN��,���ڵ��Ӿ������������ȡ�ͻ����Ա��������ѧϰ����ͨ����������ķ�����ʵ�ֵġ�
3 ���ģ��
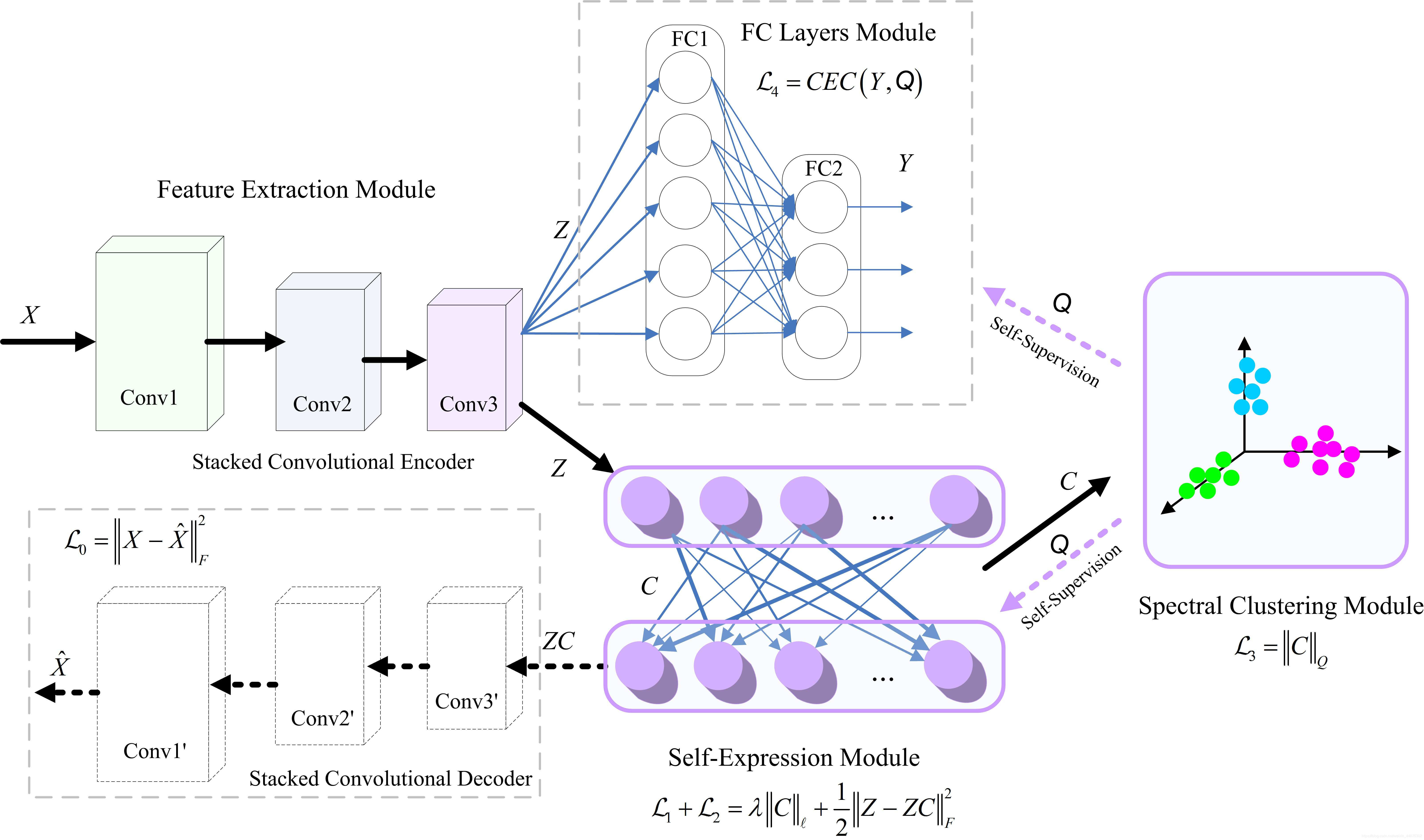
3.1 ��ʽ
��������,���ǵ�������������ȡģ�顢���ұ���ģ����Լලģ�����,�����Լලģ��ѵ��ǰ����ģ�顣
������ȡģ��
Ϊ���ڱ��ֿռ�ֲ��Ե�ͬʱ��ȡ�ֲ�����,�������ɶ��������ѵ���ɵľ��������硣��ô�������һ����������������Ԫ��������ͼ,����ͼconcat��ɵľ���z���Ƕ�ԭʼͼ���һ�ֱ�ʾ��Ϊ�˼ල������ȡģ���Ƿ�ѧ�������õ�������Ϣ,֮��Ὣԭʼ�;���decoder�õ��Ļָ�ͼ����бȽ�,������ԭʼͼ��ͻָ�ͼ�����С����:
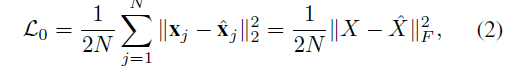
�Ա���ģ��
����˼��,���Ա���ģ�����ġ���ʧ�����Ǵ�
?
\ell
?������SSC,����
C
C
C��Ϊ�յ��õ���affinityϵ������,��Ȼ
C
C
C�ڶԽ����ϵ�ϵ��(Ҳ�������ݵ��Լ�)��ҪΪ0,
Z
Z
Z����һ��������ȡģ��õ���:
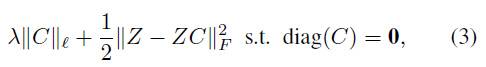
�Լලģ��
�õ��˾���
C
C
C֮��õ�
A
=
1
2
(
�O
C
�O
+
�O
C
�O
?
)
A=\frac{1}{2}(|C|+|C|^\top)
A=21?(�OC�O+�OC�O?),Ȼ����
A
A
A�Ͻ�������õ���ͬ��ķָ�,��һ������ͨ����С��һ����ʧ����:
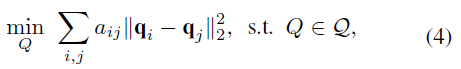
����
Q
=
{
Q
��
0
,
1
n
��
N
:
1
?
Q
=
1
?
,
r
a
n
k
(
Q
)
=
n
}
\mathcal Q=\{Q�� {0,1}^{n��N}:1^?Q=1^?, rank(Q)=n\}
Q={Q��0,1n��N:1?Q=1?,rank(Q)=n}��һ�����n���ָ����Ч�ָ����,
q
i
q_i
qi?��
q
j
q_j
qj?�ֱ���
Q
Q
Q�ĵ�
i
i
i�к͵�
j
j
j��,��ʾÿ�����ݵ��ָ�������������ϵ����ʵ����,��Ȼ����������
Q
��
Q
Q�� \mathcal Q
Q��Q�����,����ͨ���ſ��˸�
Q
��
Q
Q�� \mathcal Q
Q��Q��Լ����
Q
Q
?
=
I
QQ^? = I
QQ?=I
ע����������һ�����ݼ��ı�ǩ,��������һ�����������ݵ����ȷ���ǩ,�����������˹������ݵ����������Ϣ�����ʹ�������������������ල������ȡ���Ա���ģ�͵�ѵ����
ԭ����,��������ȡģ��ѧϰ��������Ӧ�ð����㹻����Ϣ��Ԥ�����ݵ�����ǩ�����,������������ȡģ��Ļ�����������һ�������,����ϣ�������������������ɵı�ǩһ�µı�ǩ��
����,��������ķָ��������������һ����ֵ�ָ����,�þ��������ʾ�ض����ݵ�ʱӦʹ����Щ���ݵ����Ϣ��
���,���ǽ������Ŀ�꺯����Ϊһ����ʧ�������뵽���ǵ����繫ʽ��,�ල�Ա���ģ��ѵ�������á����ǽ������������С������ϸ�����������Լලģ�顣
3.2 �ල�Ա���ģ��
����
A
=
1
2
(
�O
C
�O
+
�O
C
�O
?
)
A=\frac{1}{2}(|C|+|C|^\top)
A=21?(�OC�O+�OC�O?)���Եõ�:
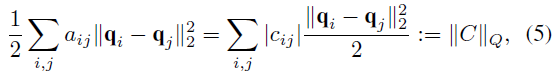
���ǰ�����ʧ����õ���
�O
�O
C
�O
�O
Q
||C||_Q
�O�OC�O�OQ?������
C
C
C��
Q
Q
Q֮��IJ��졣��Ȼ��С��
�O
�O
C
�O
�O
Q
||C||_Q
�O�OC�O�OQ?��Ҫ��
q
i
=
q
j
q_i=q_j
qi?=qj?ʱ��ϵ��
c
i
j
c_ij
ci?j�Ų�Ϊ��,Ҳ����ǿ��ϵ��
c
i
j
c_ij
ci?j�ڵ�i��j�����ݵ�����ͬһ���ӿռ�ʱ�Ų�Ϊ�㡣
Ҳ����˵,��ǰ����Ľ���ϲ����Ա���ģ���п����ṩ���Ա������C�ļල��
3.3 �ල������ȡģ��
����õ��Ľ��ͬ���������ڼල������ȡ�������һ��nά����,����������õ���n����ͬ���ӿռ����ʵ����pά��������ȡģ����������һ�������ȫ���Ӳ��������⺯���ƽ��������з���,���Ҳ��nά,�Ӷ�������Ľ�����бȽϡ�
��
y
y
yΪFC���nά���,����
y
��
R
n
y�� \mathbb R^n
y��Rn,Ϊ���������Ҽල��Ϣ��ѵ������������,��������ʧ+������ʧ(CEC)��������:
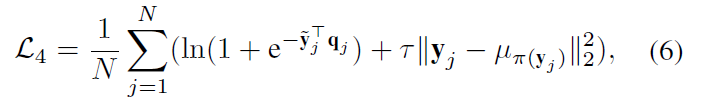
ǰһ���ǽ�������ʧ,��һ����ѹ�����ڲ����������ʧ��
���� y ~ j \tilde y_j y~?j?��softmax������� y j y_j yj?, �� �� ( y j ) \mu_{\pi (y_j)} ����(yj?)?�� y j y_j yj?��Ӧ�ľ�������, �� ( y j ) ��(y_j) ��(yj?)�Ǵ�����õ�������� y j y_j yj?��index(Ҳ��������ķ�����)��
ע�����������Ϊ���������ṩα��ǩ�����,�������õ��ķ����ǩ��ָ��˳�������IJ���һ����Ϊ�˽���������,����ʹ���������㷨(munkres)��α��ǩ�������еõ��������֮������ƥ��,Ȼ���ٽ��������뵽���н�������ʧ���Լලģ���С�
3.4 ѵ��S2ConvSCN
����ʧ������:
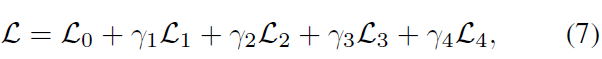
��һ��Ϊencoder��decoder���ع���ʧ,�ڶ�������Ϊ
?
1
\ell_1
?1?����(���滹Ū��һ��
?
2
\ell_2
?2?�İ汾��Ч���ƺ�����
?
1
\ell_1
?1?����)���Ա���Ķ�����,������Ϊ�ල�Ա���ģ���
�O
�O
C
�O
�O
Q
||C||_Q
�O�OC�O�OQ?,������Ϊ�ල������ȡģ���CEC��
ע��:���ܳɱ�������,����������� �� 3 = �� 4 = 0 ��_3=��_4=0 ��3?=��4?=0,��ô�����Լල����ʧ,���ǵ�S2ConvSCN���˻�ΪDSCNet��
�ƺ���Ҫ�ĵ��κܸ���,������ѵѵ����������,��������˽���취,��ʵ�鲿������˵���˸��� L \mathcal L L����Ҫ��
Ϊ��ѵ��S2ConvSCN,������������β���:
a)�Ե��Ӿ��������Ԥѵ��,���ṩS2ConvSCN�ij�ʼ��;
b) ���������ṩ���Լල��Ϣ�������������ѵ����
a)�������Ԥѵ��
ֻʹ�� L 0 \mathcal L_0 L0?����ѵ��,��FC��Ȩ������, C = I C=I C=I,�Լල������
b)��������ѵ��
Ԥѵ��֮��,���ڸ����ض�������
Q
Q
Q,���Ǹ���S2ConvSCN��
T
0
T_0
T0?��epoch����������,Ȼ��ִ������������
Q
Q
Q������:
