NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
ժҪ
��ϵͳ�Ļ���������һ��������������������ķ���������ͳ��ͳ�ƻ�������ģ��,��ϵͳ����Ŀ�����ڴ���һ����������,��������ܱ���ͬ����������������ܡ� �������������������ģ��ͨ�����ڱ�����-����������,����Դ���ӱ��뵽һ���̶����ȵ�����,���������ͨ�����������ɷ��롣����ƪ������,���Dz���ʹ��һ���̶�����������һ��ƿ��,������Ա�����-������Ϊ����������,����ͨ������һ��ģ���Զ�����(���Ե�)����Դ���ӵ���Ԥ��һ��Ŀ�����صIJ�������չ��һ��,�����ؽ��ⲿ����ȷ���γ�ΪӲ�Ρ���������·���,������Ӣ���������������������Ƚ��Ļ��ڶ����ϵͳ�������ķ������ܡ����Է�����ʾͨ��ģ�ͷ��ֵ�(��)��������ǵ�ֱ���dz����Ǻϡ�
1 ����
����������һ���Ի���������˵�¸��ֵķ���,�����Kalchbrenner��Blunsom(2013)��Sutskever��(2014)��Cho��(2014b)���������ͳ���Զ���Ϊ�����ķ���ϵͳ(��Koehn2003),���ϵͳ�ɺܶ�С�ķֱ��������������,����������ͼ������ѵ��һ�������ġ����������,��һ�����Ӳ������һ����ȷ�ķ��롣
��������������������ģ�����ڱ���-�������(Sutskever��2014)������ÿһ������ʹ��һ���������ͽ�����,�������һ���ض����Եı�����Ӧ����ÿһ������,Ȼ��Ƚ������(Hermann �� Blunsom 2014)��һ��������������ͱ���һ��Դ���������һ���̶����ȵı�����һ�����������һ������ӱ���������С����еı�����-������ϵͳ,����һ�����Զ���һ����������һ�����������,����ѵ���������Դ������ȷ����ĸ��ʡ�
���������-������������DZ����������������Ҫ�ܹ�ѹ��Դ�������б�Ҫ����Ϣ��һ���̶����ȵ������С�����ܶ���������Ը������ӵ�ʱ�������ѵ�,��������Щ��ѵ�����Ͽ��еľ��ӻ����ġ�Cho��(2014b)չʾһ�������ı�����-�����������ܵ�ȷ���ٶ�����������ӳ��ȵ����ӡ�
Ϊ���跨����������,���������˱�����-������ģ�͵���չ,��ģ��ѧϰ���϶���ͷ��롣ÿ�α������ģ����һ������������һ����ʱ,��(��)������һ��Դ����������صļ�����Ϣ��һ��λ�á����ģ��Ȼ��Ԥ��һ��Ŀ�������������Ϊ������Դλ�ú�������ǰ����Ŀ�굥�ʵĹ�����
��������������Ľ�����-���������ͬ��������������Ҫ��ͼ����һ����������ӵ������̶����ȵ��������෴,������������ӵ�һ��ʱ����������ҵ��������ĵ�ʱ����Ӧ�Ե�ѡ���������Ӽ���������������ģ�ʹӱ��������Դ���ӵ���Ϣѹ��,����Դ���ӵij���,��һ���̶����ȵ����������DZ�¶�������ģ���õĴ������䡣
���������,����չʾ�����������ķ�������ѧϰ����ͷ���ķ����Ȼ����ı�����-��������������������˷������ܡ�������߸�����ֳ�������,�����������ⳤ�ȵľ��ӽ��й۲졣��Ӣ�뷨�ķ���������,���������ʵ��,ʹ��һ����ģ��,����������൱��ӽ���ͳ���Զ���Ϊ������ϵͳ������,���Եķ�����ʾ�����ģ�ͷ�����һ�����Է����ƺ����ŵ�(��)������Դ���Ӻ����Ӧ��Ŀ����ӡ�
2 ����:��������
��һ�����ʵĹ۵�,����ȼ��ڸ�һ��Դ����x,�����������y,����Ŀ�����y������ a r g ? m a x y p ( y �O x ) arg\ max_yp(y|x) arg?maxy?p(y�Ox) .������������,������ϲ�����ģ��ʹ�ò���ѵ�����Ͽ�����ɶԾ��ӵ��������ʡ�һ��ͨ������ģ��ѧϰ�������ֲ�,����һ��Դ������Ӧ�ķ����ܱ�����,ͨ����������������ʵľ��ӡ�
���,���������Ѿ����ʹ��������ֱ��ѧϰ��������ֲ�(������,Kalchbrenner��Blunsom 2013��Cho 2014��Sutskever 2014��Cho 2014b��Forcada��Neco1997��)������������뷽����������������Ե����,��һ���ֱ���Դ����x�͵ڶ����ֱ���Ŀ�����y������,(Cho et al. 2014a)��(Sutskever et ak. 2014)ʹ������ѭ��������(RNN)ȥ����ɱ䳤�ȵľ��ӵ�һ���̶����ȵ�����Ȼ��ȥ�������������һ���ɱ䳤�ȵ�Ŀ����ӡ�
������һ����ȫ�µķ���,���������Ѿ�չʾǰ;�����Ľ����Sutskever et al. (2014)������RNN����ʱ����(LSTM)Ϊ��Ԫ����������ʵ���˽ӽ���ͳ���Զ���Ϊ�����Ļ�������ϵͳ��Ӣ�뷨�ķ������������Ƚ������� 1 ^1 1��������ϵͳ����������ڵķ���ϵͳ,����,�ڶ���������ֶ����(Cho et al. 2014a)��(Sutskever et at. 2014)���������ֺ���(Sutskever et al. 2014),�Ѿ�ʹ֮������֮ǰ���Ƚ�������ˮƽ��
2.1 RNN ������-������
������,���Ǽ�Ҫ�����µײ���,����RNN������-������,Cho et at(2014a)��Sutskever et al.(2014)���֮�����Ǵ���һ������ļܹ�,ͬʱѧϰ����ͷ��롣
�ڱ�����-���������,һ����������ȡ����ľ���,һ��ʱ������
x
=
(
x
a
,
.
.
.
,
x
T
x
)
x=(x_a,...,x_{T_x})
x=(xa?,...,xTx??),ת���һ��
2
^2
2����c,��õķ�����ʹ��һ��RNNʹ��
h
t
=
f
(
x
t
,
h
t
?
1
)
a
n
d
c
=
q
(
{
h
1
,
.
.
.
,
h
T
x
}
)
(1)
h_t=f(x_t,h_{t-1})\tag{1}\\ and\\ c=q(\{h_1,...,h_{T_x}\})
ht?=f(xt?,ht?1?)andc=q({h1?,...,hTx??})(1)
��
h
t
��
R
n
h_t\in \mathbb{R}^n
ht?��Rn��tʱ�̵�����״̬,c��һ��������������״̬ʱ��,f��q��һЩ�����Եĺ�����Sutskever et al(2014)ʹ��һ��LSTM��Ϊf������
q
(
{
h
1
,
.
.
.
,
h
T
}
)
=
h
T
q(\{h1,...,h_T\})=h_T
q({h1,...,hT?})=hT?
1 ^1 1���ǵ���ʶ�����Ƚ�������,��ͳ���Զ���Ϊ����������û��ʹ���κ�������Ϊ�����������
2 ^2 2����֮ǰ���������(������:Cho et al 2014a. Sutskever et al.2014;Kalchbrenner��Blunsom 2013)ʹ�ñ���һ���ɱ䳤���������Ϊ�̶����ȵ�����,�����DZ����,����������һ���䳤�������������������,���ǽ��ں���չʾ��
������ͨ���������������c������֮ǰԤ��ĵ���
{
y
1
,
.
.
.
,
y
t
��
?
1
}
\{y_1,...,y_{t^{'}-1}\}
{y1?,...,yt��?1?}��ʱ����ѵ����Ԥ����һ������
y
t
��
y_{t^{'}}
yt��?.���仰˵,������ͨ���ֽ����ϸ��ʳ��������������巭��y�ĸ��ʡ�
p
(
y
)
=
��
t
=
1
T
p
(
y
t
�O
{
y
1
,
.
.
.
,
y
t
?
1
}
,
c
)
,
(2)
p(y)=\prod^T_{t=1}p(y_t|\{y_1,...,y_{t-1}\}, c),\tag{2}
p(y)=t=1��T?p(yt?�O{y1?,...,yt?1?},c),(2)
��
y
=
(
y
1
,
.
.
.
y
T
y
)
y=(y_1,...y_{T_y})
y=(y1?,...yTy??).ʹ��һ��RNN,ÿһ���������ʱ���ģΪ:
p
(
y
t
�O
{
y
1
,
.
.
.
,
y
t
?
1
}
,
c
)
=
g
(
y
t
?
1
,
s
t
,
c
)
,
(3)
p(y_t|\{y_1,...,y_{t-1}\},c)=g(y_{t-1},s_t,c),\tag{3}
p(yt?�O{y1?,...,yt?1?},c)=g(yt?1?,st?,c),(3)
����g�Ƿ����Ե�,���ܶ��ε�,���������
y
t
y_t
yt?,��
s
t
s_t
st?��RNN������״̬����Ӧ��ע��,����ʹ�������ܹ�,����һ��RNN�ͷ�����������Ļ��(Kalchbrenner��Blunsom 2013)
3 ѧϰ����ͷ���
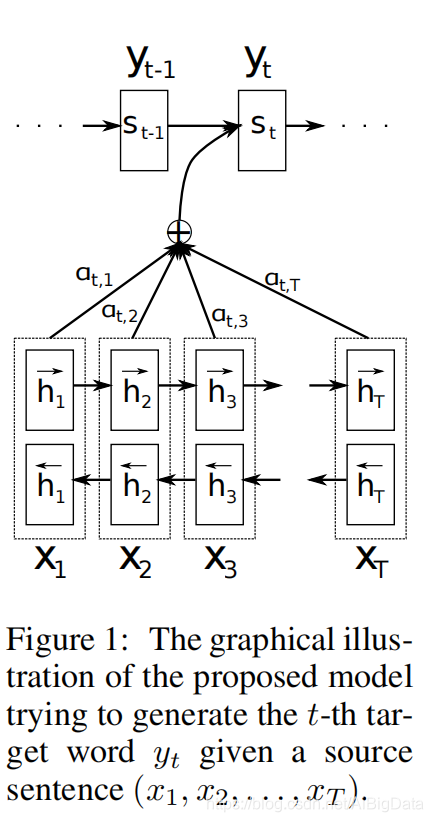
������½�,���ǹ���������������������һ������ļܹ�������¼ܹ���һ��˫��RNN�����Ϊһ��������(��3.2)���ڽ��뷭����ڼ�ģ������Դ���Ľ�������(��3.1)
3.1 ������:һ������
��һ���µ�ģ�ͼܹ�,�����ڵ�ʽ�ж���ÿһ����������KaTeX parse error: \tag works only in display equations
���� s i s_i si?��ʱ��iRNN����״̬,ͨ�� s i = f ( s i ? 1 , y i ? 1 , c i ) s_i=f(s_{i-1},y_{i-1},c_i) si?=f(si?1?,yi?1?,ci?)�����㡣
��Ӧ��ע�ⲻ����ڵı�����-����������(����ʽ(2)),����ĸ�����ÿһ��Ŀ��� y i y_i yi?�����Բ�ͬ��������Ϊ������
���������� c i c_i ci?ȡ���ڱ��������������ӳ�䵽һ��ʱ���ע�� ( h 1 , . . . , h T x ) (h_1,...,h_{T_x}) (h1?,...,hTx??)��ÿһ��ע�� h 1 h_1 h1?����������������,�ص��ע�������еĵ�i�����ʵ���Χ��Ϣ��������ϸ�Ľ���ע����ô��������һ�½ڡ�
Ȼ������������
c
i
c_i
ci?����Ϊ��Щע��
h
i
h_i
hi?�ļ�Ȩ��
c
i
=
��
j
=
1
T
x
��
i
j
h
j
(5)
c_i=\sum^{T_x}_{j=1}\alpha_{ij}h_j\tag{5}
ci?=j=1��Tx??��ij?hj?(5)
ÿһ��ע��
h
j
h_j
hj?Ȩ��
��
i
j
\alpha_{ij}
��ij?ͨ������Ĺ�ʽ������
��
i
j
=
e
x
p
(
e
i
j
)
��
k
=
1
T
x
e
x
p
(
e
i
k
)
(6)
\alpha_{ij}=\frac{exp(e_{ij})}{\sum^{T_x}_{k=1}exp(e_{ik})}\tag 6
��ij?=��k=1Tx??exp(eik?)exp(eij?)?(6)
������
e
i
j
=
a
(
s
i
?
1
,
h
j
)
e_{ij}=a(s_{i-1}, h_j)
eij?=a(si?1?,hj?)��һ������ģ��,��������λ��j�����λ��iƥ��ĸ��á������������RNN���ز�״̬
s
i
?
1
s_{i-1}
si?1?Ϊ����(���ڷ���
y
i
y_i
yi?֮ǰ,��ʽ(4))����������ӵ�j��ע��
h
j
h_j
hj?.
����ȷ������ģ�Ͳ���a��Ϊ������������,�������е��������ϵͳ�������ͬѵ����ע�ⲻ��ͳ��������,���벻�ÿ������صı������෴,����ģ��ֱ�Ӽ���һ��������,��������ʧ�������ݶ�ͨ������������ݶȱ�ʹ�����ڹ�ͬ��ѵ������ģ�ͺ�ȫ������ģ��һ����
����������������ע��Ȩ�غ�������һ��������ע�͵ķ���,���������˿��ܶ���Ŀ��ܡ�ʹ�� �� i j \alpha_{ij} ��ij?��Ϊһ������,Ŀ�굥�� y i y_i yi?��������߷���һ��Դ���� x j x_j xj?.Ȼ��,��i������������ c i c_i ci?�DZ�������ע�ͳ�������ע���� �� i j \alpha_{ij} ��ij?
���� �� i j \alpha_{ij} ��ij?,��������������� e i j e_{ij} eij?,��Ӧ��ע�� h j h_j hj?����Ҫ��,����֮ǰ������״̬ s i ? 1 s_{i-1} si?1?������һ������״̬ s i s_i si?������ y i y_i yi?.ֱ�۵�,���ڽ�������ע�������ơ�����������Դ��������Ҫע��IJ��֡�ͨ��ʹ�ý�������ע��������,���Ǽ����˱���������Ҫ��������Դ���ӵ��̶�������Ϣ��������������·���,��Ϣ�ܱ�����,ͨ��ע�͵�ʱ��,ͨ����Ӧ�Ľ������ܱ���ѡ��Ļָ���
3.2 ������:����ע�����е�˫��RNN
ͨ����RNN,ʹ�õ�ʽ(1)����,��ȡһ��������� x \textbf x x,��˳��,�ӵ�һ����ʶ�� x 1 x_1 x1?��ʼ�����һ�� x T x x_{T_x} xTx??��������Ȼ,��������ķ�����,����ϣ��ÿ�����ʵ�ע�Ͳ����ܸ���ǰ��ĵ���,�����ܸ�������ĵ��ʡ����,�������˫��RNN(BiRNN,Schuster��Paliwal,1997),����Ѿ��ɹ���ʹ��������ʶ��(������Graves et al.2013)��
һ��BiRNN��һ������ͷ���RNN��ɡ�����RNN f �� \mathop{f} \limits ^{\rightarrow} f��?��ȡ���������Ϊ����˳��(�� x 1 x_1 x1?�� x T x x_{T_x} xTx??)���Ҽ���һ����������״̬��ʱ��(KaTeX parse error: Expected group after '^' at position 12: {\mathop{h}^? \limits \right��,��,KaTeX parse error: Expected group after '^' at position 12: {\mathop{h}^? \limits \right��).����RNNKaTeX parse error: Expected group after '^' at position 11: \mathop{f}^? \limits \lefta����ȡʱ��ķ���˳��(�� x T x x_{T_x} xTx??�� x 1 x_1 x1?),���·�������״̬ʱ��(KaTeX parse error: Expected group after '^' at position 12: {\mathop{h}^? \limits \lefta��,��,KaTeX parse error: Expected group after '^' at position 12: {\mathop{h}^? \limits \lefta��)
���ǻ��ÿһ������ x j x_j xj?��ע��ͨ������ǰ������״̬KaTeX parse error: Expected group after '^' at position 12: {\mathop{h}^? \limits \right���ͷ�������״̬KaTeX parse error: Expected group after '^' at position 12: {\mathop{h}^? \limits \lefta������KaTeX parse error: Expected group after '^' at position 17: ��_j=[{\mathop{h}^? \limits \right��.�����ַ���,ע�� h j h_j hj?��������֮ǰ���ʵĸ���������֮�ʵĸ���������RNN�и��ñ���������������,ע�� h j h_j hj?����۽����� x j x_j xj?����Χ���������Ͷ���ģ���Ժ�ʹ�ô�ע�����м�����������������ʽ5,6
��ͼ1,���ڽ���ģ�͵�ͼ��˵��
4 ʵ������
������Ӣ�뷨����������������ķ���������ʹ��ACL WMT14 3 ^3 3�ṩ��˫��ƽ�����Ͽ⡣��Ϊ�Ƚ�,����Ҳ����RNN������-������������,�����Cho 2014a����ġ��������е�ģ�� 4 ^4 4,����ʹ����ͬ��ѵ���������ص����ݼ���
4.1 ���ݼ�
WMT 14��������Ӣ��ƽ������:Europarl(6100��),��������(550��),UN(42100��)�ͷֱ���ȡ��9000�����Ϻ�27250��,�ܼ�85000�ʡ�����ij���������Cho 2014a,���ǽ����������ϵĴ�С��34800���,ʹ�õ�Axelrod 2011 5 ^5 5����ѡ��ķ����������ἰ��˫������,����û��ʹ���κε�������,����������ʹ��һ�������ģ�ĵ������Ͽ���Ԥѵ��һ������������������news-test-2012��news-test-2013��Ϊ���ǵĿ�����(��֤��)������ģ���ڴ�WMT14��news-test-2014���Լ�,��û�г�����ѵ������3003��������ɡ�
һ��ͨ���Ĵ����зֺ� 6 ^6 6,������ÿ��������ʹ��30000�����Ƶ�Ĵʺ�ѡ������ѵ�����ǵ�ģ�͡��κ�û�г����ں�ѡ�����еĵ��ʶ���ӳ���һ������ı��(UNK).����û�в����κ�������Ԥ����,��������ݽ���Сдת����ʸ���ȡ��
4.2 ģ��
����ѵ������ģ�͡���һ����RNN������-������(RNNencdec,Cho 2014a),�����������ģ��,���ǽ������RNNsearch.����ѵ��ÿ��ģ������:�����ǵ��ʳ��Ȳ�����30�����ʵľ���(RNNencdec-30,RNNsearch-30)��Ȼ�ʵij��Ȳ�����50�ľ��ӡ�(RBBencdec-50,RNNsearch-50)
ÿһ��RNNencdec������-��������1000�����ص�Ԫ 7 ^7 7��RNNsearch��������һ������ͷ���ѭ�����������,ÿһ��RNN��1000�����ز㡣���Ľ�������1000�����ز㡣�������������,����ʹ��һ�����������е�������(Goodfellow et al.2013)���ز�Ϊ�˼���ÿһ��Ŀ�굥�ʵ��������ʡ�(Pascanu et al. 2014)
����ʹ��������ݶ��½���(SGD)��Adadelta(Zeiler 2012)�㷨һ��ѵ��ÿһ��ģ�͡�ÿһ��SGD���·���ÿһ��С��������ʹ��80�����ӽ��м��㡣����ѵ��ÿһ��ģ�ʹ�Լ5�졣
һ��ģ�ͱ�ѵ��,����ʹ��beam searchѰ��һ������Ľ��������������(��Graves 2012; Boulanger-Lewandowski�� 2013;Sutslever 2014)ʹ������������ɷ���,�������ǵ����������ѧϰģ�͡�
������ϸ��������ģ�͵ļܹ�����ѵ���ij���ʹ����ʵ����,�뿴��¼A��B��
5 ���
5.1 �������
�ڱ�1,�����г��˷�������ܲ�����BLEU�����ϡ���������Ĵӱ��������е����,RNNsearch�����ù���ͳ��RNNencdec������Ҫ����,RNNsearch���ܸߴﴫͳ���Զ���Ϊ�����ķ���ϵͳ(Moses)����������������֪�ĵ�������DZ����ǵġ������ش�ijɾ�,����Mosesʹ�ö����ĵ��������(41800��)����ƽ������,����ʹ����Щ����ѵ��RNNsearch��RNNencdec.
6 ^6 6����ʹ�÷ִʽű��ӿ�Դ�Ļ���������,Moses
7 ^7 7�����������,ͨ��һ�������ص�Ԫ��,��������ζ�����ſص����ص�Ԫ(����¼A.1.1)
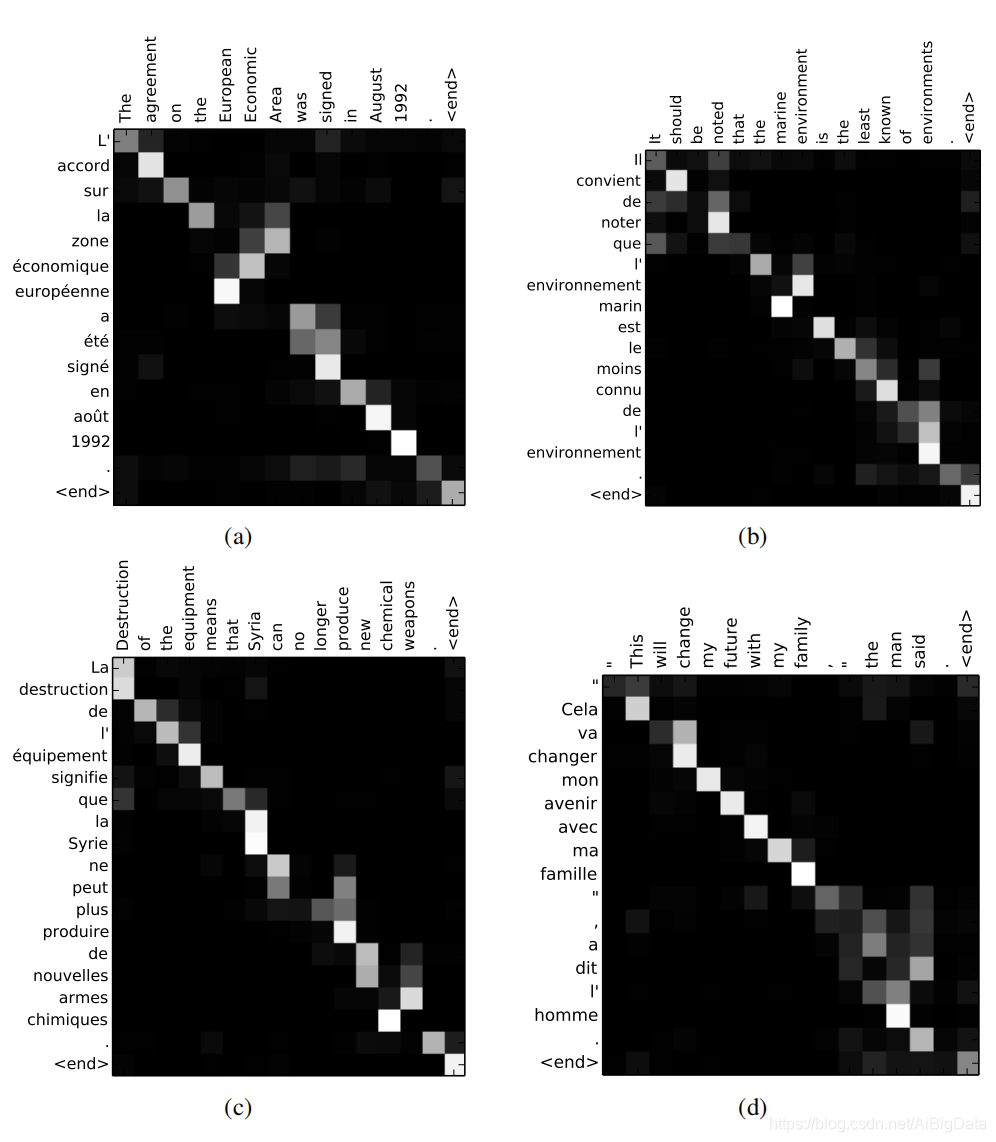
ͼ3:ͨ��RNNsearch50���ֵ�4������������ÿ��ͼ��x���y��ֱ��Ӧ��Դ���ӵĵ���(Ӣ��)�����ɵķ���(����)��ÿһ������չʾ�˵�j��Դ���ʵ���i��Ŀ��ʵ�����Ȩ�� �� i j \alpha_{ij} ��ij?(����ʽ6).�ڻ�ɫͼ��(0:��ɫ,1:��ɫ)��(a)һ������ľ��ӡ�(b-d)�������ѡ�������,�ڲ��Լ���û��δ֪�����ҳ�����10��20����֮�С�
���鷽������Ķ���֮һ��ʹ��һ���̶����ȵ������������ڻ����ı�����-�����������������Ʋ�����ܻ����ƻ����ı�����-�����������ڳ������б��ֵĽϲ��ͼ2,���ǻῴ��RNNencdec�����ܻ����ž��ӳ��ȵ����Ӷ��������½�����һ����,RNNsearch-30��RNNsearch-50˫�������ӵ��Ƚ����ھ��ӵij��ȡ��ر�RNNsearch-50����û�ж��������ӵij��ȴﵽ50���߸��ࡣ�����ģ�͵����Ƴ����˽�����ı�����-������,ͨ����ʵ��һ����ȷ��RNNsearch-30����������RNNencdec-50(����1)
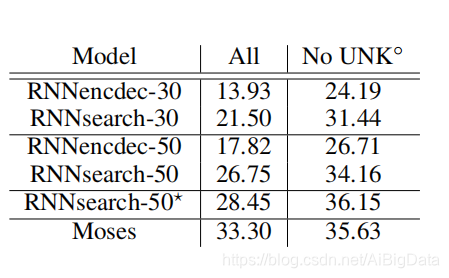
��1:ѵ��ģ���ڲ��Լ���BLEU�������ڶ��к͵����зֱ��չ���������о��Ӻ;����������������ἰ������û��δ֪�ĵ��ʵķ�����ע��RNNsearch-50ѵ����ʱ�����ֱ���ڿ�����������ֹͣ������ ( o ) (^o) (o)��������û��δ֪���ʵľ���ʱ,���Dz�������������[UNK]��ǡ�
5.2 ���Է���
5.2.1 ����
����ķ��������һ��ֱ�۵ķ������(��)���������ɷ���ʺ�Դ�����еĴ�֮�䡣ͨ����ʽ6������Ȩ�� �� i j \alpha_{ij} ��ij?���ӻ��õ���ÿһ��ͼ�ľ����ÿһ����ʾ��Ȩ�غͶ�Ӧ�����ġ������ܿ���������Ŀ�굥��ʱ��Դ�����е��ĸ�λ�ñ����ǵĸ���Ҫ��
��ͼ3�Ķ�����Կ���,Ӣ��ͷ���֮��Ķ����ںܴ�̶����ǵ����ġ����ǿ���ÿһ���������ŶԽ��߶��кܴ��Ȩ�ء���Ȼ,���ǻ�������һЩ��ƽ���ġ��ǵ����Ķ��롣���ݴʺ������ڷ����Ӣ��֮���ǵ��͵�˳��ͬ,�������ǿ��Կ�ͼ3��һ�����ӡ������ͼ,�����ܿ���ģ����ȷ����һ������� [European Economic Area] into [zone��economique europ��een].RNNsearch�ܹ���ȷ�Ķ���[zone]��[area],��������������([European]��[Economic]),Ȼ��һ����һ���ֵ������������ [zone��economique europ��een].
����������Ƹ�Ӳ�������෴��,�����Ե�,����,��ͼ3(d).����Դ����[the man]������� [l�� homme].�κ�Ӳ�Ķ��뽫��ӳ��[the]��[l��]��[man]��[homme]������ڷ���û�а�����һ������Ҫ���ǽ���[the]�ĵ������������Ƿ�Ӧ�ñ�����Ϊ[le],[la],[les]��[l��].������������Ȼ�Ľ�����������ͨ��ʹģ��[the]��[man]����,�����������,���ǿ���ģ����ȷ����[the]��[l�� ].��ͼ3���ǹ۲���Ƶ���Ϊ������Ŀǰ������С�������һ������ĺô�����Ȼ�Ĵ�����Դ�����Ŀ����ﲻͬ�ij���,�����Ƿ�ֱ����ӳ��һЩ�ʻ���κεط�[NULL] (��2010 Koehn�ĵ��ġ������½� ��)
5.2.2 ������
��ͼ2�������ԵĿ��������ģ��(RNNsearch)�DZȴ�ͳ��ģ��(RNNencdec)�ڷ��볤���ӵ�ʱ����á���ܿ�������RNNsearch����Ҫ����һ�������ӵ�һ����ȫ�̶���������������,����ֻ������������ض�������Χ�IJ��ֽ���ȷ���롣
��Ϊһ������,�������Բ��Լ���һ�����ӡ�
An admitting privilege is the right of a doctor to admit a patient to a hospital or
a medical centre to carry out a diagnosis or a procedure, based on his status as a
health care worker at a hospital.
RNNencdec-50����������ӳɡ�
Un privil ege d��admission est le droit d��un m��edecin de reconna??tre un patient `a
l��h?opital ou un centre m��edical d��un diagnostic ou de prendre un diagnostic en
fonction de son ��etat de sant��e.
RNNencdec-50��ȷ�ķ���Դ���ӵ�[a medical center].��Ȼ,���»�����,��ƫ����Դ���ӵ�ԭʼ���塣����,��Դ������ [based on his status as a health care worker at a hospital]�ı��滻�� [enfonction de son ��etat de sant��e] (��based on his state of health��).
��һ����,RNNsearch-50����������ȷ�ķ���,��������������к��岢��û����©�κ�ϸ�ڡ�
Un privil ege d��admission est le droit d��un m��edecin d��admettre un patient a un
h?opital ou un centre m��edical pour effectuer un diagnostic ou une proc��edure, selon
son statut de travailleur des soins de sant��e `a l��h?opital.
�����ǿ������Բ��Լ�����һ������
This kind of experience is part of Disney��s efforts to ��extend the lifetime of its
series and build new relationships with audiences via digital platforms that are
becoming ever more important,�� he added.
RNNencdec-50�ķ�������
Ce type d��exp��erience fait partie des initiatives du Disney pour ��prolonger la dur��ee
de vie de ses nouvelles et de d��evelopper des liens avec les lecteurs num��eriques qui
deviennent plus complexes.
����֮ǰ������,RNNencdec�����ɴ�Լ30������֮��ʼƫ��Դ���ӵ�ʵ�ʺ��塣����֮��,�����������ʼ��,���л����Ĵ���,����ȱ�������š�
��һ��,RNNsearch-50�ܹ���ȷ�ķ��볤���ӡ�
Ce genre d��exp��erience fait partie des efforts de Disney pour ��prolonger la dur��ee
de vie de ses s��eries et cr��eer de nouvelles relations avec des publics via des
plateformes num��eriques de plus en plus importantes��, a-t-il ajout��e.
��ͬ��������Ѿ�����,���Թ۲���ȷ�����ǵ��ܲ�,RNNsearch�ܹ����볤���ӱȱ���RNNencdecģ���ɿ����ࡣ
��¼C,�����ṩ���ٶ�һЩ�ӳ���Դ���ӵķ�������,��RNNencdec-50,RNNsearch-50�ȸ跭����ͬ�ο�����һ��
6 ��ع���
6.1 ѧϰ����
һ�����ƵĶ��뷽�������Graves(2013)���,����д�ϳɵ���������һ��������Ŷ�Ӧһ��������š���д�ϳ���һ������,��ģ�ͱ�Ҫ�����ɸ���ʱ���ַ�����д�������Ĺ�����,��ʹ��һ����ϸ�˹�˷�������������Ȩ��,����ÿһ���ں˵�λ��,����,ϵ��ͨ������ģ��Ԥ�⡣���ر��,����ģ����Ԥ��λ��ʱ��������������λ�õ������ӡ�
Graves(2013)�����ǵķ�����Ҫ�IJ�ͬ,����Ȩ�ص�ģʽֻ��һ�������ƶ����ڻ��������������,���ǿ��̵�����,��Ϊ�����Ӿ�����Ҫ��������������һ������Ͻ���ȷ�ķ��롣
���ǵķ���, ���仰˵,��Դ���Ӹ��ڷ����е�ÿ��������Ҫ����ÿ�����ʵ�Ȩ�ء����ȱ���Dz����ص�,���ڷ������������������������ֻ��15-40�����ʡ���Ȼ,�������������ƻ�����������������ԡ�
6.2 �������������
�Դ�Bengio 2003�������һ����������ģ��,ʹ��һ����������ģ�����Ԥ�ⵥ�ʵĹ̶�����,����һ���ʵ�������,������㷺ʹ���ڻ��������С���Ȼ,�������������Ҫ�����ڸ��ִ��ͳ�ƻ�������ϵͳ�ṩ��һ����������ͨ��һ���ȴ��ϵͳ���������ѡ�����б���
����,Schwenk(2012)�����ʹ��һ��������������������Դ�����Ŀ�����һ�Եķ�������ʹ�������������һ������������ڶ���Ϊ����ͳ�ƻ�������ϵͳ�����,Kalchbrenner��Blunsom(2013)��Devlin et al.(2014)�����˳ɹ���ʹ����������Ϊ�ȴ淭��ϵͳ�����������ͳ��,һ��������ѵ����Ϊһ��Ŀ�������ģ��ʹ�������ֻ���������һ�������ѡ�б���(��Schwenk et al 2006)
��������ķ����Ѿ�չʾ����߷�������ܳ������Ƚ��Ļ�������ϵͳ,���Ǹ�����Ȥһ��Ұ�IJ�����Ŀ��,��������Ļ�����������һ����ȫ�µķ���ϵͳ���������ƪ�����п��ǵ�������������뷽����֮ǰ�Ĺ�����ȫ��ͬ��������ʹ�������缴���Ѵ�ϵͳ��һ����,���ǵ�ģ�Ͷ����������Ҵ�Դ����ֱ�����ɷ��롣
7 ����
��������Ĵ�ͳ����,����һ��������-����������,��������������ӵ�һ���̶����ȵ�����,һ������ͨ������õ��������ܲ�ʹ�ù̶�������������������һ�������ӷ������������,�������һ��ʵ֤�о�������ͨ��Cho et al (2014b)��Pouget-Abadie et al(2014).
����ƪ����,���������һ������ļܹ������������⡣������չ�˻����ı�����-������ͨ��ʹһ��ģ��(��)����һ������ʡ�,�������ǵ����ı�һ������������,������ÿһ��Ŀ��ʵġ������ģ�ʹӱ������һ��ȫ����Դ���ӵ�һ���̶����ȵ�����,������ģ�ͽ����۽�������һ�����Ŀ�굥�ʵ���Ϣ������һ����Ҫ������Ӱ�����������������ϵͳ�ڸ��������ϲ�����һ���ý��������ͳ�Ļ�������ϵͳ,����ϵͳ�����в���,�����������,��ͬѵ������һ�����õ�log����ͨ��������ȷ�ķ��롣
���Dz��������ģ��,����RNNsearch,��Ӣ�뷨�������ϡ�ʵ����ʾ�����RNNsearch���������ij����˴�ͳ�ı�����-������ģ��(RNNencdec).���ܾ��ӵij��Ȳ��Ҷ���Դ���ӵij��ȸ��ӵ��Ƚ����Ӷ��Եķ������������ǵ���ͨ��RNNsearch(��)���������,�������ƶ�ģ������ȷ�Ķ���Ŀ�굥�ʵ���صĵ���,�������ǵ�����,��Դ������,��Ϊ��������һ����ȷ�ķ��롣
��������Ҫ��,����ķ���ʵ����һ�����Ը��ִ�Ļ��ڶ���ͳ�ƻ�������Ƚϵ����ܡ�����һ�������Ľ��,��������ļܹ�,�������������Ĵ����,ֱ����������������������������ļܹ���ϣ����һ��������õĻ������벢�Ҹ��õ�����һ�����Ȼ���ԡ�
����һ��ʣ�����ս�Ǹ��ô���δ֪��,����ϡ�еĵ��ʡ�����Ҫģ���㷺��ʹ�ò��������������ĵ���ƥ��ǰ���Ƚ��Ļ�������ϵͳ�����ܡ�
��л
���ߺ����лTheano������(Bergstra el al 2010;Bastien et al. 2012)�����Ǹ�л���»������о�����ͼ���֧�ֵ�֧��:NSERC,Calcul Quebec,Compute Canada,the Canada Research Chairs��CIFAR.Bahdanau��л��������ϵͳ��GmbH��֧�֡�����Ҳ��лFelix Hill, Bart vanMerri��enboer, Jean Pouget-Abadie, Coline Devin and Tae-Ho Kim.
REFERENCES
Axelrod, A., He, X., and Gao, J. (2011). Domain adaptation via pseudo in-domain data selection. In Proceedings of the ACL Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 355�C362. Association for Computational Linguistics.
Bastien, F., Lamblin, P., Pascanu, R., Bergstra, J., Goodfellow, I. J., Bergeron, A., Bouchard, N., and Bengio, Y. (2012). Theano: new features and speed improvements. Deep Learning and Unsupervised Feature Learning NIPS 2012 Workshop.
Bengio, Y., Simard, P., and Frasconi, P. (1994). Learning long-term dependencies with gradient descent is dif?cult. IEEE Transactions on Neural Networks, 5(2), 157�C166.
Bengio, Y., Ducharme, R., Vincent, P., and Janvin, C. (2003). A neural probabilistic language model.
J. Mach. Learn. Res., 3, 1137�C1155.
Bergstra, J., Breuleux, O., Bastien, F., Lamblin, P., Pascanu, R., Desjardins, G., Turian, J., Warde- Farley, D., and Bengio, Y. (2010). Theano: a CPU and GPU math expression compiler. In Proceedings of the Python for Scienti?c Computing Conference (SciPy). Oral Presentation.
Boulanger-Lewandowski, N., Bengio, Y., and Vincent, P. (2013). Audio chord recognition with recurrent neural networks. In ISMIR.
Cho, K., van Merrienboer, B., Gulcehre, C., Bougares, F., Schwenk, H., and Bengio, Y. (2014a). Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014). to appear.
Cho, K., van Merrie��nboer, B., Bahdanau, D., and Bengio, Y. (2014b). On the properties of neural machine translation: Encoder�CDecoder approaches. In Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation. to appear.
Devlin, J., Zbib, R., Huang, Z., Lamar, T., Schwartz, R., and Makhoul, J. (2014). Fast and robust neural network joint models for statistical machine translation. In Association for Computational Linguistics.
Forcada, M. L. and N? eco, R. P. (1997). Recursive hetero-associative memories for translation. In
J. Mira, R. Moreno-D��?az, and J. Cabestany, editors, Biological and Arti?cial Computation: From Neuroscience to Technology, volume 1240 of Lecture Notes in Computer Science, pages 453�C462. Springer Berlin Heidelberg.
Goodfellow, I., Warde-Farley, D., Mirza, M., Courville, A., and Bengio, Y. (2013). Maxout net- works. In Proceedings of The 30th International Conference on Machine Learning, pages 1319�C 1327.
Graves, A. (2012). Sequence transduction with recurrent neural networks. In Proceedings of the 29th International Conference on Machine Learning (ICML 2012).
Graves, A. (2013). Generating sequences with recurrent neural networks. *arXiv:*1308.0850 [ .NE].
Graves, A., Jaitly, N., and Mohamed, A.-R. (2013). Hybrid speech recognition with deep bidirec- tional LSTM. In Automatic Speech Recognition and Understanding (ASRU), 2013 IEEE Work- shop on, pages 273�C278.
Hermann, K. and Blunsom, P. (2014). Multilingual distributed representations without word align- ment. In Proceedings of the Second International Conference on Learning Representations (ICLR 2014).
Hochreiter, S. (1991). Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, Institut fu��r Informatik, Lehrstuhl Prof. Brauer, Technische Universita��t Mu��nchen.
Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735�C1780.
Kalchbrenner, N. and Blunsom, P. (2013). Recurrent continuous translation models. In Proceedings of the ACL Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1700�C1709. Association for Computational Linguistics.
Koehn, P. (2010). Statistical Machine Translation. Cambridge University Press, New York, NY, USA.
Koehn, P., Och, F. J., and Marcu, D. (2003). Statistical phrase-based translation. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology - Volume 1, NAACL ��03, pages 48�C54, Stroudsburg, PA, USA. Association for Computational Linguistics.
Pascanu, R., Mikolov, T., and Bengio, Y. (2013a). On the dif?culty of training recurrent neural networks. In ICML��2013.
Pascanu, R., Mikolov, T., and Bengio, Y. (2013b). On the dif?culty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning (ICML 2013).
Pascanu, R., Gulcehre, C., Cho, K., and Bengio, Y. (2014). How to construct deep recurrent neural networks. In Proceedings of the Second International Conference on Learning Representations (ICLR 2014).
Pouget-Abadie, J., Bahdanau, D., van Merrie��nboer, B., Cho, K., and Bengio, Y. (2014). Overcoming the curse of sentence length for neural machine translation using automatic segmentation. In Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation. to appear.
Schuster, M. and Paliwal, K. K. (1997). Bidirectional recurrent neural networks. Signal Processing, IEEE Transactions on, 45(11), 2673�C2681.
Schwenk, H. (2012). Continuous space translation models for phrase-based statistical machine translation. In M. Kay and C. Boitet, editors, Proceedings of the 24th International Conference on Computational Linguistics (COLIN), pages 1071�C1080. Indian Institute of Technology Bombay.
Schwenk, H., Dchelotte, D., and Gauvain, J.-L. (2006). Continuous space language models for statistical machine translation. In Proceedings of the COLING/ACL on Main conference poster sessions, pages 723�C730. Association for Computational Linguistics.
Sutskever, I., Vinyals, O., and Le, Q. (2014). Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems (NIPS 2014).
Zeiler, M. D. (2012). ADADELTA: An adaptive learning rate method. *arXiv:*1212.5701 [ .LG].