在实时通讯技术迅猛发展的今天,人们对通话时的降噪要求也不断提高。深度学习也被应用于实时的噪声抑制。在 LiveVideoStackCon 2021 上海站中,声网Agora 音频算法负责人冯建元分享深度学习落地移动端的范例,遇到的问题和未来的展望。
文 / 冯建元
整理 / LiveVideoStack
尊敬的各位来宾大家好,我是来自声网的冯建元。今天给大家介绍一下我们在如何基于深度学习做实时噪声抑制,这也是一个深度学习落地移动端的范例。

我们就按照这样一个顺序来进行介绍。首先噪声其实是有一些不同的种类,它们是如何进行分类的,如何选择算法并怎样通过算法去解决这些噪声的问题;另外,会介绍如何通过深度学习的方式去设计一些这样的网络,如何通过AI的模型去进行算法的设计;另外,我们都知道深度学习网络的算力,模型不可避免的都会比较大。我们在落地一些RTC的场景时,不可避免会遇到一些问题,有哪些问题是需要我们解决的,如何解决模型大小的问题、算力的问题;最后会介绍目前降噪能达到什么样的效果和一些应用的场景,以及如何能将噪声抑制等做得更好。
01.噪声的分类与降噪算法的选择
先了解下我们平时的噪声都有哪些种类。

其实噪声不可避免的会跟着你所处的环境,所面临的物体都会发出各种各样的声音。其实每一个声音都有自己的意义,但如果你在进行实时沟通时,只有人声是有意义的,那其他声音你可能会把它认为是噪音。其实很多噪声是一个稳态的噪声,或者说平稳的噪声。比如说我这种录制的时候可能会有一些底噪,你现在可能听不到。比如说空调运行时会有一些呼呼的风声。像这些噪声都是一些平稳的噪声,它不会随着时间变化而去变化。这种可以通过我知道这个噪声之前是什么样的,我把它estimate出来,就通过这样的方式,在之后如果这个噪声一直出现就可以通过很简单的减法的方式把它去掉。像这种平稳的噪声其实很常见,但其实不是都那么平稳,都能那么方便的去去除。另外,还有很多噪声是不平稳的,你不能预测这个房间里会不会有人突然手机铃声响起来了;突然有人在旁边放了一段音乐或者在地铁、在马路上车子呼啸而过的声音。这种声音都是随机出现的,是不可能通过预测的方式去解决的。其实这块也是我们会用深度学习的原因,像传统的算法对于非稳态的噪声会难以消除和抑制。
在使用场景上来说,就算你是很安静的会议室或者在家,可能也不可避免的会被设备引入的一些底噪或一些突发的噪声都会产生一些影响。这一块也是在实时通讯中不可避免的一道前处理的工序。
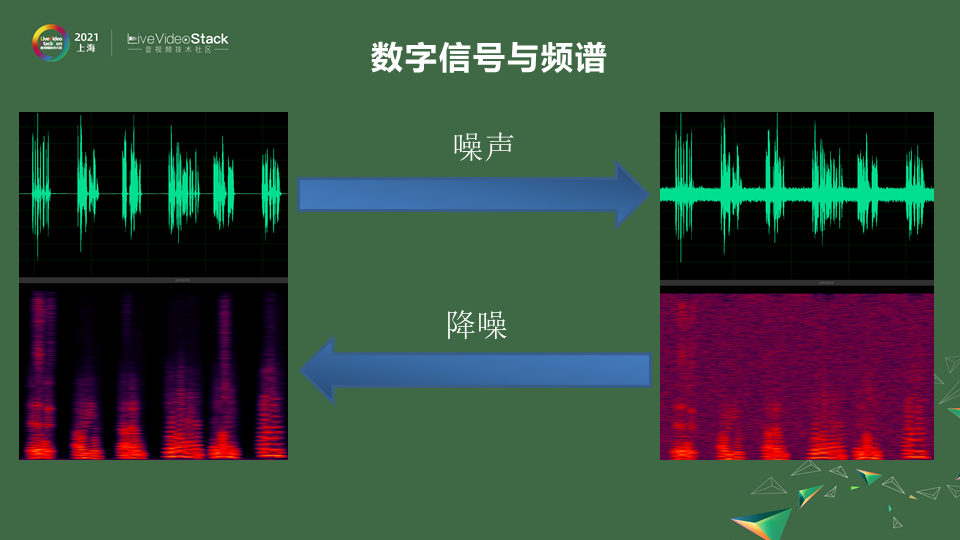
抛开我们平时会碰到的这些噪声在感官上的理解。看到它在数字方面,在信号层面是一个怎么样的表现。噪声,声音都是通过空气的传播介质的传播最后到你耳朵里,通过你耳毛的感应,最后形成心里的感知。在这些过程中,比如我们采用一些麦克风的信号,在一些采集的时候它是一个wave的信号。它是一些上下震荡的一些波形。那如果是干净的人声,他说话的时候会看到一些波形,他不说话的时候基本就是0,那如果加上一些噪声它就会变成右边一样,会有波形上的一些混叠,噪声的震动会和人声的震动混叠在一起,会有一些模糊不清。即使不在说话也会有一些波形。这是直接从wave信号的层面,如果说把它通过傅里叶变换,变到频域上来看,在不同的频率上,人声的发音一般在20赫兹到2k赫兹之间,人还会有基频、振峰、谐波的产生。你可以看到人在频谱上是这样一些形状,但是你加上噪声会发现频谱变得模糊不清,频谱不该出现能量的地方有很多能量。
做噪声抑制其实就是做一个inverse,一个反向的过程。把这些时域的信号通过一些滤波的方式变成一个纯净的信号。也可以通过频域的方式把这些嘈杂的噪点去掉,形成一些比较纯净的语料。
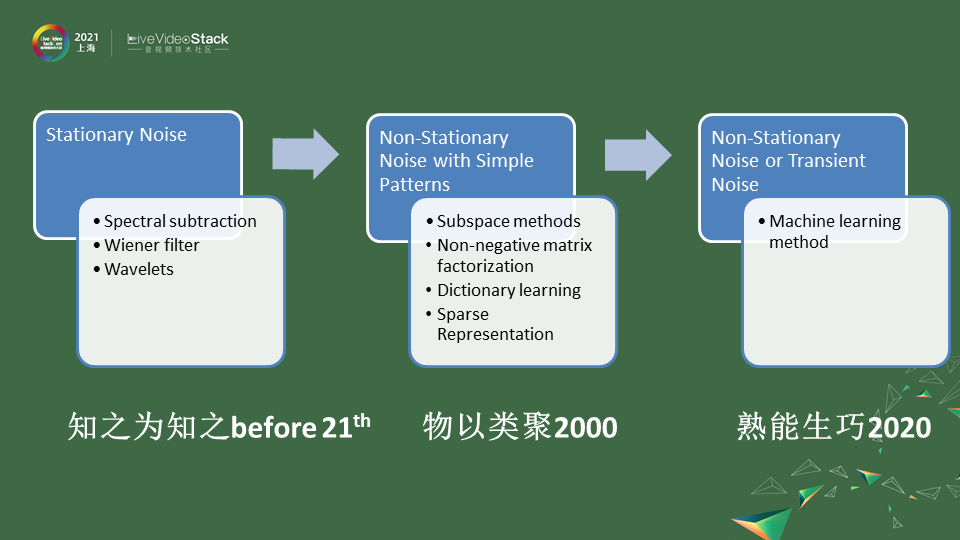
降噪这种算法很早之前就有了,在贝尔实验室发明电话的时候就发现噪声会有很大的通信的影响。不同的信噪比会导致由于香农定理影响你的带宽,你是一个纯净的信号甚至可以用比较小的带宽进行一个传输。在2000年之前我们可以把这些算法统称为,知之为知之。
第一块,它们主要针对比较稳态的噪声就是Stationary Noise,为什么叫知之为知之呢,就是你不再说话没有人声的时候就只有噪声,另外你去通过静音段噪声的捕捉去构建出噪声的一些分布。因为它是稳态的噪声,它随着时间的变化也没有那么剧烈,以后就算是有人声了,你也可以通过你estimate好的模型去进行一些谱减或者是维纳滤波的方式解决。像这种Stationary Noise是因为一开始我们的元器件有很多底噪,所以他们第一个会干掉这种Stationary Noise的噪声。其实方法来说就是一些谱减法、维纳滤波,后来可能有高级一点波差、小波分解,这些方法都万变不离其宗,它会通过静音段estimate它的这样的noise,在以后的过程中就可以通过一些谱减的方法来解决。
慢慢大家会发现除了Stationary Noise其实平时通话中想要只保有人声,其他的噪声也要处理,这块到了2000年之后我们会说,因为其实人的声音的分布和风的声音的分布是不一样的,有些风声经过麦克风的,比如我这样吹的,低频部分可能会高一些,高频部分可能衰减的更快。其实都是通过聚类的方式可以把人声和噪声分解开来,主要的思想都是把声音的信号投射到更高维的空间进行聚类,聚类的方式就会有些自适应的方法慢慢可以去使用,也类似于深度学习的前身,会把声音分成不同的种类,在高维空间进行降噪时把符合人声的特点保留下来,其他部分舍去就可以做到。这块方法来说比如Subspace 空间分解,在图像领域大获成功,在音频领域去风噪也比较好的非负矩阵分解。再比如说不止一种噪声,要分解出好多种噪声,像字典学习这种方式也是可以做的。
像常见的一种噪声我们把它叫Non-Stationary Noise with Simple Patterns,是不稳定的噪声,像呼呼的风声,但它可能有固定的模式。比如呼呼的风声有时出现有时没有出现,但它是遵循风的低频比较密集等等这种特征。其中是可以通过一个一个去学习,比如风声、雷电的声音、底噪的声音等等,可以通过学习的方式去实现。现在我们发现,物以类聚的话,噪声的种类是无穷无尽的,每一种机械每一种摩擦每一种风吹过的声音导致的涡流可能都是不一样的。在这种情况下很多噪声混叠我们无法去穷尽,这时候我们就想到通过大量数据去训练一个模型,这样采集到的噪声也好人声的混加也好,能过通过不断的去学习,我们叫它熟能生巧2020。通过训练的方式,通过大量的数据样本,能让模型学到足够的知识,对噪声更加鲁棒,不用一个一个去做分解。
按照这样的思路,已经有很多深度学习的模型可以做到这样噪声的抑制,同时保证它对不同的噪声都有抑制效果。
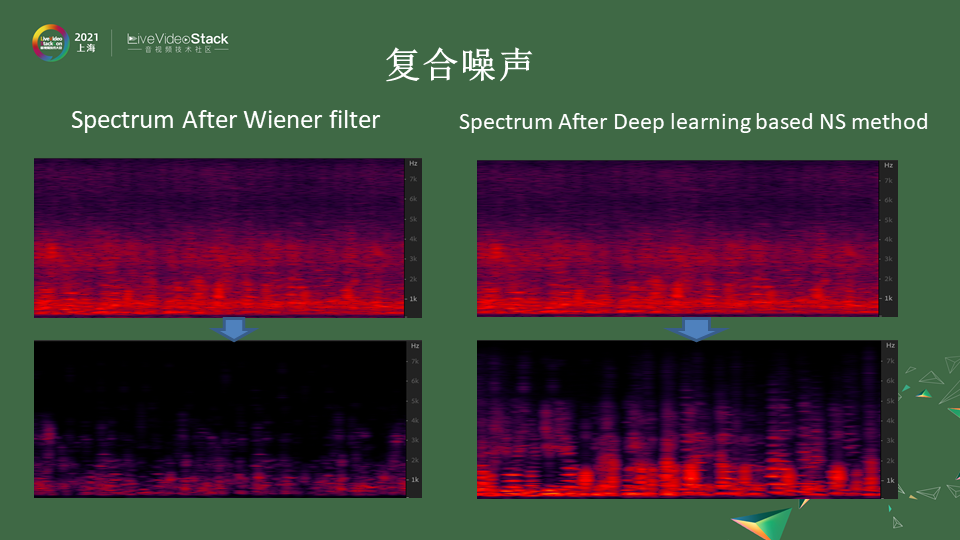
很多噪声不是单一存在的,尤其是一些复合的噪声。比如你在一个咖啡馆里可能会听到那些觥筹交错的声音混杂着各种人在聊天谈话的声音。我们把背景的人声叫Babble noise,Babble就是呢喃的声音,这种背景的噪声你也是想去掉的。多个声音混杂在一起你就会发现它的频谱就像洪水过路一般所有东西都混杂在里面,会很难去去除。如果你用传统的算法,它把明显的人声会保留,比较高频的混叠会更加严重,其实很难去区分开,它把在4k以上的高频统一当成噪声去除掉了。这是传统降噪方法的一些缺陷。
像深度学习的方法,判断一个降噪方法的好坏主要是两点:
第一点,对原声人声的保留程度是怎么样的,是不是对语谱的损伤尽量的小。
第二点,把噪声去得尽量的干净。
满足这两点,右边是深度学习的方法,语谱在高频也可以得到保留,同时噪声也没有混杂在其间。
02.基于深度学习的算法设计
现在针对深度学习方法怎样去设计。
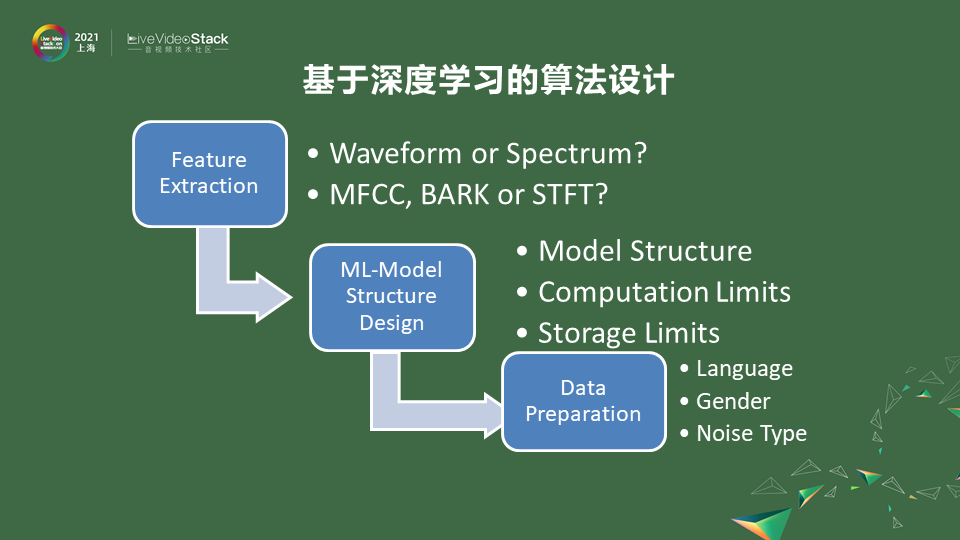
和其他深度学习一样也会包括这几个步骤。
第一步,喂给模型什么样的输入,输入可以去进行选择,我们的声波信号可以通过wave的形式通过频谱的形式或者是更加高维的MFCC的形式甚至心理听阈BARK域的形式去给到它。不同的输入决定了你的模型采用的结构也不一样。在模型结构上,可能会选择类似图像的,如果是频谱可能类似CNN的方法去做。声音是有一定时间连续性的,你也可以通过waveform直接去做。这块选择不同的模型结构,但是我们发现在移动端的时候,也会受到算力和存储空间的限制,可能会对模型进行一些组合,不是用单一的模型去做。在模型的选择这块会有所考量,另外一块也会比较重要就是选择一个合适的数据去训练模型 。
训练模型的过程比较简单,就是把人声信号和噪声信号混在一起喂到程序里,这样模型会给你一个纯净的人声信号。这时就会选择我这个数据是不是为了cover所有不同的语言,上一个会议上也提到不同的语言组成的因素也是不一样的,比如中文会比日文多五六个音素,如果是英文还有五六个音素和中文是不一样的,为了cover住这些的语言可能会选择多语言的数据。另外一块性别也是不一样的,如果语料训练不够均衡,对男声和女声的降噪能力可能有所偏差。另外噪声上的类型可能会有一些选择上的考虑,因为不可能把所有噪声都穷尽,所以会选择一些typical noise。这边大概罗列出来,不同Feature 的选择,模型的设计,以及数据的准备回来看看要注意哪些方向。

我们先看一下我们会选择什么样的数据给到模型。
第一个考虑的是把最原始的wave信号做一个端到端的处理生存一个wave信号。这个想法一开始的时候是被否定的,因为wave信号和它的采样率有关,可能16K的采样率1帧10毫秒会有160个点,数据量非常庞大如果直接喂的话可能导致模型处理需要很大一个模型才能handle。我们在之前就在想能不能转化成频域,在频域上做能减少数据的输入。在17、18年之前都是在频域上去做这个事情,但是在2018年像Tasnet模型已经能通过时域端到端的去生成降噪的一个效果。
频域可能会更早一些,之前在频域上做噪点的去除,通过掩码的形式去解决噪声的问题。比如把噪声的能量去除掉只保留人声的能量。
19年有一篇paper做了一个比较,无论从时域还是频域都可以得到一个比较好的降噪效果,而且模型计算复杂度不是相当的。这个输入信号不会很大程度上决定你模型的算力或者效果,就是可以的。
在这个基础上,时域频域都是可以的话,我们想要进一步减少模型的算力可能需要选用一些高维度像MFCC这种形式去做,这块也是一开始设计模型考量的地方。根据算力限制,本来200多个频点到MFCC只有40个bin,这样就可以减少输入。因为声音存在一些遮蔽效应你可能把它分成一些足够细小的子带就能做到噪声抑制的作用,所以也是行之有效能减少模型算力的方法。
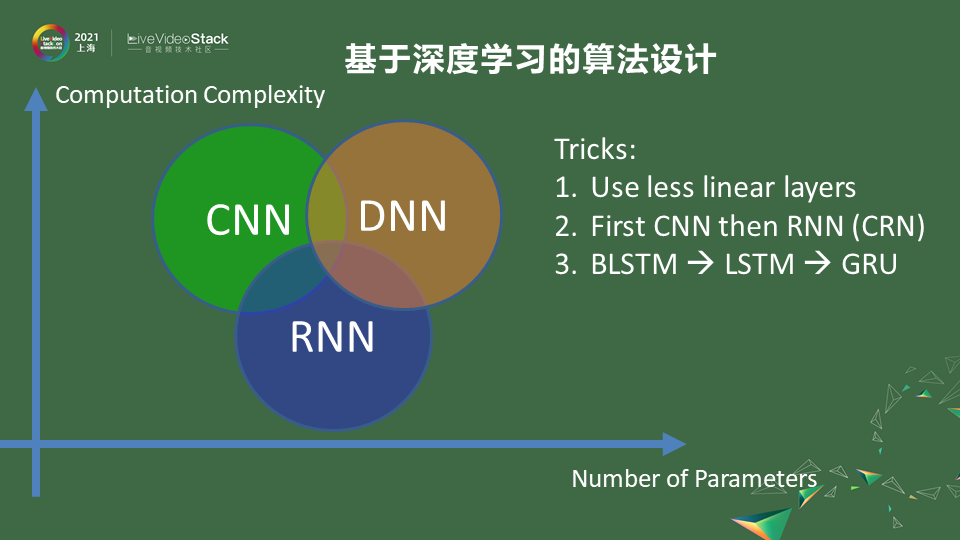
刚刚是讲到信号的输入,在做模型结构选择的时候也会有很多对模型结构算力的考量,可以把模型算力的复杂度和模型参数量画一个XY轴去表正。像一些CNN方法,因为是卷积的存在,里面很多算子是可以复用的,卷积核可以在整个频谱上复用。这种情况下,在同样参数结构中它的算力复杂度会最高,因为它是复用的它的参数量就很小。如果一些手机APP对参数量有限制,比如手机APP不能大于200M可能模型给你的空间就1-2兆,这种情况下尽量选择CNN模型。
参数量并不是一个很大的限制而运算力可能会受到一些挑战,比如一个算力较差的芯片,只有1GHz。这时卷积神经网络的方式并不是适合的,这时可能是用一些linear 这种层来表征,所以linear 也是矩阵乘。矩阵乘在一些DSP芯片和传统CPU方面表现的算力都不是很高,缺点是每个算子是不可复用的。这种情况下参数量比较大,但计算力上可能会更加的小。但只用linear这种方式就像DNN一样只有linear 层,就是它参数很大算力也很大。
前面提到人的说话时间是有连续性的,可以用RNN这种有短时或长时记忆的这种方式,把参数通过实时的自适应去记忆出当前噪声的状态,这样可以进一步减少它的算力。
综合下来说,当你选择模型时尽量少去使用linear layers,这种会带来很大参数量的提升和算力的提升。你可以去融合这些不同的结构,比如先用CNN再用RNN这种CRN的形式,那它第一步通过压缩你输入的维度,再通过长短时记忆的方式,把模型算力进一步的减少。
根据不同场景,如果做离线的处理,可能使用双向的人工神经网络去做效果可能是最好的。在RTC场景中不能去增加延迟。像LSTM这种单向型的网络可能更加合适。如果想进一步减少算力,三个门的LSTM还是太大那就用两个门结构的GRU等等,在一些细节上提升算法的能力。

怎么选择模型结构和使用场景和算力有关。另外一块就是怎么选择喂到模型的数据。数据里面一块是语谱的损伤,要准备更充分干净的语料,里面包括不同的语言、性别,以及语料本身可能含有底噪,尽量选择录音棚消音室录的比较纯净的语料。这样你的reference决定了你的目标可能是比较纯净的,效果会更好一些。
还有一块是能不能cover住噪声,噪声是无穷无尽的,可以根据你的场景,比如会议场景选择一些比较典型的办公室里的人声、手机提示音等等,这些作为训练语料。其实很多噪声是简单噪声的一些组合,当简单噪声数量足够多的时,模型的鲁棒性也会提升,哪怕是一些没有见过的噪声也能cover。噪声有时不能收集的话可以自己做一些,人工合成一些,比如日光灯管、辉光效应造成的杂音、50赫兹的交流电时时刻刻都在释放50赫兹、100赫兹的谐波的噪声。这种噪声可以通过人造的方法去加入训练集里面提升模型的鲁棒性。
03.RTC移动端困境
假设我们已经有一个比较好的模型了,在落地时会遇到哪些困难呢?

在实时互动的场景中,首先它有别于离线的操作,对实时性的要求更高,它要求逐帧计算,非因果不可用,未来的信息是无法去获得的,这样的场景下一些双向的神经网络不可用。
另外要去适配不同的手机、不同的移动终端,这里面受到各种芯片算力的影响,如果想使用更加广泛模型算力会有限制同时模型参数大小也不能过大,尤其是调用芯片是模型参数量很大算力不是很高,但是由于参数的读取IO的操作也会影响到模型最终表现。
场景的丰富性刚才也有提到,一些比较成功的,不同语音比如中英文、日文的cover程度以及噪声的类型。在实时互动场景中不可能让每一个人都在同一个场景说同样的话,场景的丰富性也要考虑其中。
04.如何落地移动端
在这样一些条件下,如何去落地深度学习呢?我们可以从两个方面去解决这些问题。

首先,算法方面可以通过算法突围的方式。刚刚有提到一点,像全卷积的、全linear的,对它的参数对它的算力都有不同,可以通过不同模型的组合,针对不同算力可以组合出不同算力的结构。效果来说可能会有一些偏颇差异,什么样的机型能适用什么样的算法,可以通过这样的模型结构来解决,整体来说是一个组合式的算法,通过模型组合使它的算力能尽量满足它的芯片和存储空间的要求。
第二,整个算法的场景是不一样的,所以会选择不一样的模型去解决,在一开始如果能够选择出场景,比如会议场景,不可能会有音乐、动物的叫声,这些噪声指标就不用特别关注,这些东西可以作为模型裁剪的方向。
算法本身可能模型就是这么大,出来还是一个5-6兆的参数,你可能觉得它还是不够。或者说它的算力在移动端不进行优化,它在内存的调用,芯片存储cache的方面可能都会有问题。会影响到它在推理过程中,实际使用过程中的结果,明明在训练时跑的是ok的,但在落地不同芯片时跑的是不一样的。
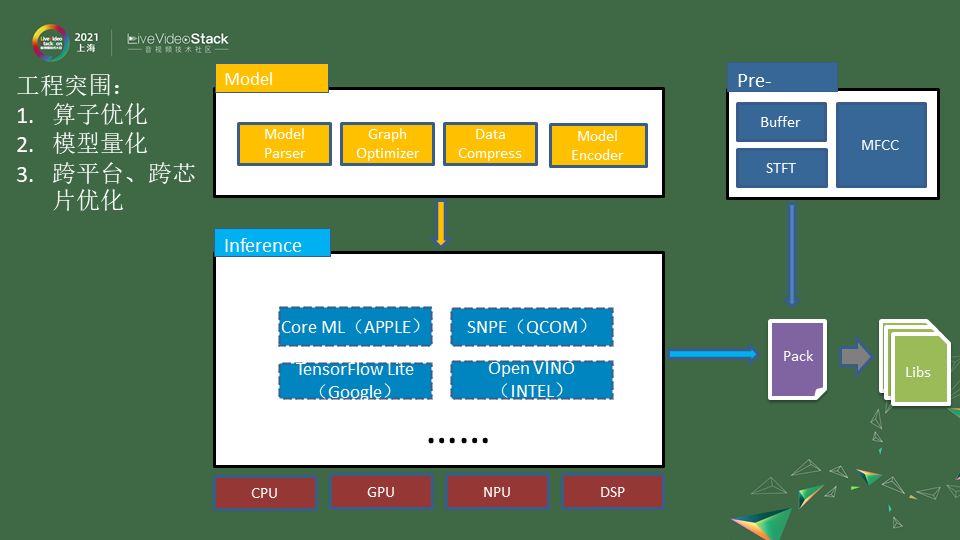
在工程上也会进行突围,主要针对模型推理以及一些处理的方式会有所不一样。首先在模型方面会做一些算子的优化,在训练搭建模型的时候都是一层层加上去的,但很多算子可以进行一些融合,包括算子融合、凸优化。一些参数做模型的剪枝、量化,这些都是可以进一步减少模型的算力以及参数量的大小。
第一步就是对模型进行一些裁剪量化,这一块已经能做到让你的模型是最优的最符合场景的。另外在不同的移动终端它的芯片也是不一样的,有些手机可能只有CPU有些好点的手机会有GPU NPU甚至会有的DSP芯片甚至能开放它的算力。
这块我们能更好的去适应芯片,会有一些不同的推理框架,各家都会有一些比较开源的框架可以去使用,比如苹果的Core ML、谷歌的TensorFlow Lite,它会把芯片调度编译层的优化做在里面。在这步上来说,做和不做差异是非常巨大的,因为整个算法怎么运算是一回事,怎么做内存调用、矩阵的计算、浮点计算还是另一回事。做工程化的优化,这种效果可能是百倍的提升。优化可以用开源的框架去做,也可以自己做一些编译的优化,如果你对芯片的算力比较熟悉,比如不同的cache的怎么调用,它的大小是什么,你可以自己去做。可能你做出来的结果比这种开源的框架更有针对性,效果会更好。
在我们把模型和推理引擎整合起来之后,就是我们最后的产品,我们几乎能在所有的终端做好适配,在所有芯片上完整工程化的一个产品,这样能实时使用。
05.降噪demo试听
我们现在听一听降噪效果是什么样的。

【由于平台无法上传音频,所以感兴趣的开发者可以通过访问该链接来试听】
06.Can we do it better?
听完这些demo后,看看我们能做什么让效果变得更好,场景变得更多一些呢?

我们还有很多难以解决的问题。包括一些音乐信息的保留,如果你是在一个音乐场景去开降噪,你会发现伴奏都没有了只剩下人声,这些场景可能会通过更精细化的方式,比如音源分离的方式,能不能把乐器的声音也保留,但有些音乐听上去像噪声是比较难以解决的一个领域。另一块像人声、像Babble noise,背景的这种噪声有时和人声比较难以区别,尤其像鸡尾酒效应,大家都在说话,通过AI判定哪个人说话是真正有效的是比较难。噪声抑制,比如说我们做的都是单通道的,采用一些麦克风阵列可能会做一些指向性的降噪,但这些也是一个比较难的地方,什么声音值得保留,人声和背景声如何分辨这块也是比较难的方向,这也是未来我们会去探索的一个比较明确的方向。
我的分享就到这里,谢谢大家。
The cover from creativeboom.com
