2. Boosting�����Ļ���˼·
����ʽ����Boosting˼��֮ǰ,�����Ƚ�����������:
��һ������:��֪�������û���������Ȿ,���ǽ�ÿ�β���Ĵ�����Ŀ��¼�ڴ��Ȿ��,��ͣ�ķ���,ֱ��������ȫ����(Ҳ�����ܹ��ڿ������ܹ���һ����)��
�ڶ�������:����һ������������˵,�����ר�ҵ��жϽ����ʵ����ۺ����������ж�,Ҫ�������κ�һ��ר�ҵ����ж�Ҫ�á�ʵ��������һ�֡�������Ƥ������������ĵ�������
���������Ӷ�˵��Boosting�ĵ���,Ҳ���Dz������ظ�ѧϰ�ﵽ���յ�Ҫ��
Boosting������뷢չ�벻��Valiant�� Kearns��Ŭ��,��ʷ������Valiant�� Kearns�����"ǿ��ѧϰ"��"����ѧϰ"�ĸ����ʲô��"ǿ��ѧϰ"��"����ѧϰ"��?�ڸ��ʽ�����ȷPACѧϰ�Ŀ����:
- ��ѧϰ:ʶ�������С��1/2(��ȷ�ʽ�������²��Ըߵ�ѧϰ�㷨)
- ǿѧϰ:ʶ��ȷ�ʺܸ߲����ڶ���ʽʱ������ɵ�ѧϰ�㷨
�dz���Ȥ����,��PAC ѧϰ�Ŀ����,ǿ��ѧϰ������ѧϰ�ǵȼ۵�,Ҳ����˵һ��������ǿ��ѧϰ�ij�ֱ�Ҫ�������������������ѧϰ�ġ�����һ��,�������:��ѧϰ��,����Ѿ�����������ѧϰ�㷨,�ܷ���������ǿ��ѧϰ�㷨����Ϊ,����ѧϰ�㷨��ǿ��ѧϰ�㷨���öࡣ�����������Ǵ���ѧϰ�㷨����,����ѧϰ,�õ�һϵ����������(�ֳ�Ϊ����������),Ȼ��ͨ��һ������ʽȥ�����Щ������������һ��ǿ���������������Boosting��������ͨ���ı�ѵ�����ݼ��ĸ��ʷֲ�(ѵ�����ݲ�ͬ������Ȩֵ),��Բ�ͬ���ʷֲ������ݵ����������㷨ѧϰһϵ�е�����������
����Boosting������˵,������������Ҫ������:��һ����ÿһ��ѧϰӦ����θı����ݵĸ��ʷֲ�,�ڶ�������ν������������������������������������,��ͬ��Boosting�㷨���в�ͬ�Ĵ�,���ǽ���������һ������Boosting�㷨----Adaboost,������Ҫ����Adaboost����ô���������������Լ�Ϊʲô��ô�����ġ�
3. Adaboost�㷨
Adaboost�Ļ���ԭ��

����Adaboost��˵,�����������������ķ�ʽ��:1. �����Щ��ǰһ�ַ�������������������Ȩ��,��������Щ����ȷ�����������Ȩ�ء�����һ��,��Щ����һ�ַ�������û�еõ���ȷ���������,������Ȩ�ص�������ں�һ�ֵ�ѵ���С����ܹ�ע����2. �������������������ͨ����ȡ��Ȩ���������ķ�ʽ,������˵,�Ӵ��������ʵ͵�����������Ȩ��,��Ϊ��Щ�������ܸ��õ���ɷ�������,����С��������ʽϴ������������Ȩ��,ʹ���ڱ��������С�����á�
����,�������������Adaboost�㷨:(�ο����ʦ�ġ�ͳ��ѧϰ������)
�������һ���������ѵ�����ݼ�:
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
?
?
,
(
x
N
,
y
N
)
}
T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\}
T={(x1?,y1?),(x2?,y2?),?,(xN?,yN?)},����ÿ���������������������ɡ�����
x
i
��
X
?
R
n
x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}
xi?��X?Rn,���
y
i
��
Y
=
{
?
1
,
+
1
}
y_{i} \in \mathcal{Y}=\{-1,+1\}
yi?��Y={?1,+1},
X
\mathcal{X}
X�������ռ�,$ \mathcal{Y}
��
��
��
��
��
,
��
��
��
��
��
��
��
�����,������շ�����
����������,��������������G(x)
��
A
d
a
b
o
o
s
t
��
��
��
��
:
(
1
)
��
ʼ
��
ѵ
��
��
��
��
��
��
:
��Adaboost�㷨����: (1) ��ʼ��ѵ�����ݵķֲ�:
��Adaboost��������:(1)��ʼ��ѵ������������:D_{1}=\left(w_{11}, \cdots, w_{1 i}, \cdots, w_{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N$
(2) ����m=1,2,��,M
- ʹ�þ���Ȩֵ�ֲ� D m D_m Dm?��ѵ�����ݼ�����ѧϰ,�õ�����������: G m ( x ) : X �� { ? 1 , + 1 } G_{m}(x): \mathcal{X} \rightarrow\{-1,+1\} Gm?(x):X��{?1,+1}
- ���� G m ( x ) G_m(x) Gm?(x)��ѵ�����ϵķ�������� e m = �� i = 1 N P ( G m ( x i ) �� y i ) = �� i = 1 N w m i I ( G m ( x i ) �� y i ) e_{m}=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)=\sum_{i=1}^{N} w_{m i} I\left(G_{m}\left(x_{i}\right) \neq y_{i}\right) em?=��i=1N?P(Gm?(xi?)��?=yi?)=��i=1N?wmi?I(Gm?(xi?)��?=yi?)
- ���� G m ( x ) G_m(x) Gm?(x)��ϵ�� �� m = 1 2 log ? 1 ? e m e m \alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}} ��m?=21?logem?1?em??,�����log����Ȼ����ln
- ����ѵ�����ݼ���Ȩ�طֲ�
D m + 1 = ( w m + 1 , 1 , ? ? , w m + 1 , i , ? ? , w m + 1 , N ) w m + 1 , i = w m i Z m exp ? ( ? �� m y i G m ( x i ) ) , i = 1 , 2 , ? ? , N \begin{array}{c} D_{m+1}=\left(w_{m+1,1}, \cdots, w_{m+1, i}, \cdots, w_{m+1, N}\right) \\ w_{m+1, i}=\frac{w_{m i}}{Z_{m}} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right), \quad i=1,2, \cdots, N \end{array} Dm+1?=(wm+1,1?,?,wm+1,i?,?,wm+1,N?)wm+1,i?=Zm?wmi??exp(?��m?yi?Gm?(xi?)),i=1,2,?,N?
����� Z m Z_m Zm?�ǹ淶������,ʹ�� D m + 1 D_{m+1} Dm+1?��Ϊ���ʷֲ�, Z m = �� i = 1 N w m i exp ? ( ? �� m y i G m ( x i ) ) Z_{m}=\sum_{i=1}^{N} w_{m i} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right) Zm?=��i=1N?wmi?exp(?��m?yi?Gm?(xi?))
(3) ����������������������� f ( x ) = �� m = 1 M �� m G m ( x ) f(x)=\sum_{m=1}^{M} \alpha_{m} G_{m}(x) f(x)=��m=1M?��m?Gm?(x),�õ����յķ�����
G ( x ) = sign ? ( f ( x ) ) = sign ? ( �� m = 1 M �� m G m ( x ) ) \begin{aligned} G(x) &=\operatorname{sign}(f(x)) \\ &=\operatorname{sign}\left(\sum_{m=1}^{M} \alpha_{m} G_{m}(x)\right) \end{aligned} G(x)?=sign(f(x))=sign(m=1��M?��m?Gm?(x))?
�����Adaboost�㷨������˵��:
���ڲ���(1),����ѵ�����ݵ�Ȩֵ�ֲ��Ǿ��ȷֲ�,��Ϊ��ʹ�õ�һ��û��������Ϣ��������ÿ�������ڻ�����������ѧϰ������һ����
���ڲ���(2),ÿһ�ε��������Ļ���������
G
m
(
x
)
G_m(x)
Gm?(x)�ڼ�Ȩѵ�����ݼ��ϵķ��������
e
m
=
��
i
=
1
N
P
(
G
m
(
x
i
)
��
y
i
)
=
��
G
m
(
x
i
)
��
y
i
w
m
i
\begin{aligned}e_{m} &=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right) =\sum_{G_{m}\left(x_{i}\right) \neq y_{i}} w_{m i}\end{aligned}
em??=i=1��N?P(Gm?(xi?)��?=yi?)=Gm?(xi?)��?=yi?��?wmi??��������
G
m
(
x
)
G_m(x)
Gm?(x)�з�����������Ȩ�غ�,���ֱ��˵����Ȩ�طֲ�
D
m
D_m
Dm?��
G
m
(
x
)
G_m(x)
Gm?(x)�ķ��������
e
m
e_m
em?��ֱ�ӹ�ϵ��ͬʱ,�ڲ���(2)��,�������������
G
m
(
x
)
G_m(x)
Gm?(x)��ϵ��
��
m
\alpha_m
��m?,
��
m
=
1
2
log
?
1
?
e
m
e
m
\alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}}
��m?=21?logem?1?em??,����ʾ��
G
m
(
x
)
G_m(x)
Gm?(x)�����շ���������Ҫ�Գ̶�,
��
m
\alpha_m
��m?��ȡֵ�ɻ���������
G
m
(
x
)
G_m(x)
Gm?(x)�ķ����������ֱ�ӹ�ϵ,��
e
m
?
1
2
e_{m} \leqslant \frac{1}{2}
em??21?ʱ,
��
m
?
0
\alpha_{m} \geqslant 0
��m??0,����
��
m
\alpha_m
��m?����
e
m
e_m
em?�ļ��ٶ�����,��˷��������ԽС�Ļ��������������շ�����������Խ��!
**����Ҫ��,���ڲ���(2)�е�����Ȩ�صĸ���: **
w
m
+
1
,
i
=
{
w
m
i
Z
m
e
?
��
m
,
G
m
(
x
i
)
=
y
i
w
m
i
Z
m
e
��
m
,
G
m
(
x
i
)
��
y
i
w_{m+1, i}=\left\{\begin{array}{ll} \frac{w_{m i}}{Z_{m}} \mathrm{e}^{-\alpha_{m}}, & G_{m}\left(x_{i}\right)=y_{i} \\ \frac{w_{m i}}{Z_{m}} \mathrm{e}^{\alpha_{m}}, & G_{m}\left(x_{i}\right) \neq y_{i} \end{array}\right.
wm+1,i?={Zm?wmi??e?��m?,Zm?wmi??e��m?,?Gm?(xi?)=yi?Gm?(xi?)��?=yi??
���,����ʽ���Կ���:������������
G
m
(
x
)
G_m(x)
Gm?(x)��������������Ȩ������,����ȷ���������Ȩ�ؼ���,����������
e
2
��
m
=
1
?
e
m
e
m
\mathrm{e}^{2 \alpha_{m}}=\frac{1-e_{m}}{e_{m}}
e2��m?=em?1?em??����
���ڲ���(3),�������
f
(
x
)
f(x)
f(x)ʵ���˽�M�������������ļ�Ȩ����,ϵ��
��
m
\alpha_m
��m?��־�˻���������
G
m
(
x
)
G_m(x)
Gm?(x)����Ҫ��,ֵ��ע�����:���е�
��
m
\alpha_m
��m?֮�Ͳ�Ϊ1��
f
(
x
)
f(x)
f(x)�ķ��ž���������x������һ�ࡣ
Adaboost�Ļ���ԭ��
����Adaboost��˵,�����������������ķ�ʽ��:1. �����Щ��ǰһ�ַ�������������������Ȩ��,��������Щ����ȷ�����������Ȩ�ء�����һ��,��Щ����һ�ַ�������û�еõ���ȷ���������,������Ȩ�ص�������ں�һ�ֵ�ѵ���С����ܹ�ע����2. �������������������ͨ����ȡ��Ȩ���������ķ�ʽ,������˵,�Ӵ��������ʵ͵�����������Ȩ��,��Ϊ��Щ�������ܸ��õ���ɷ�������,����С��������ʽϴ������������Ȩ��,ʹ���ڱ��������С�����á�
����,�������������Adaboost�㷨:(�ο����ʦ�ġ�ͳ��ѧϰ������)
�������һ���������ѵ�����ݼ�:
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
?
?
,
(
x
N
,
y
N
)
}
T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\}
T={(x1?,y1?),(x2?,y2?),?,(xN?,yN?)},����ÿ���������������������ɡ�����
x
i
��
X
?
R
n
x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}
xi?��X?Rn,���
y
i
��
Y
=
{
?
1
,
+
1
}
y_{i} \in \mathcal{Y}=\{-1,+1\}
yi?��Y={?1,+1},
X
\mathcal{X}
X�������ռ�,$ \mathcal{Y}
��
��
��
��
��
,
��
��
��
��
��
��
��
�����,������շ�����
����������,��������������G(x)
��
A
d
a
b
o
o
s
t
��
��
��
��
:
(
1
)
��
ʼ
��
ѵ
��
��
��
��
��
��
:
��Adaboost�㷨����: (1) ��ʼ��ѵ�����ݵķֲ�:
��Adaboost��������:(1)��ʼ��ѵ������������:D_{1}=\left(w_{11}, \cdots, w_{1 i}, \cdots, w_{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N$
(2) ����m=1,2,��,M
- ʹ�þ���Ȩֵ�ֲ� D m D_m Dm?��ѵ�����ݼ�����ѧϰ,�õ�����������: G m ( x ) : X �� { ? 1 , + 1 } G_{m}(x): \mathcal{X} \rightarrow\{-1,+1\} Gm?(x):X��{?1,+1}
- ���� G m ( x ) G_m(x) Gm?(x)��ѵ�����ϵķ�������� e m = �� i = 1 N P ( G m ( x i ) �� y i ) = �� i = 1 N w m i I ( G m ( x i ) �� y i ) e_{m}=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)=\sum_{i=1}^{N} w_{m i} I\left(G_{m}\left(x_{i}\right) \neq y_{i}\right) em?=��i=1N?P(Gm?(xi?)��?=yi?)=��i=1N?wmi?I(Gm?(xi?)��?=yi?)
- ���� G m ( x ) G_m(x) Gm?(x)��ϵ�� �� m = 1 2 log ? 1 ? e m e m \alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}} ��m?=21?logem?1?em??,�����log����Ȼ����ln
- ����ѵ�����ݼ���Ȩ�طֲ�
D m + 1 = ( w m + 1 , 1 , ? ? , w m + 1 , i , ? ? , w m + 1 , N ) w m + 1 , i = w m i Z m exp ? ( ? �� m y i G m ( x i ) ) , i = 1 , 2 , ? ? , N \begin{array}{c} D_{m+1}=\left(w_{m+1,1}, \cdots, w_{m+1, i}, \cdots, w_{m+1, N}\right) \\ w_{m+1, i}=\frac{w_{m i}}{Z_{m}} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right), \quad i=1,2, \cdots, N \end{array} Dm+1?=(wm+1,1?,?,wm+1,i?,?,wm+1,N?)wm+1,i?=Zm?wmi??exp(?��m?yi?Gm?(xi?)),i=1,2,?,N?
����� Z m Z_m Zm?�ǹ淶������,ʹ�� D m + 1 D_{m+1} Dm+1?��Ϊ���ʷֲ�, Z m = �� i = 1 N w m i exp ? ( ? �� m y i G m ( x i ) ) Z_{m}=\sum_{i=1}^{N} w_{m i} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right) Zm?=��i=1N?wmi?exp(?��m?yi?Gm?(xi?))
(3) ����������������������� f ( x ) = �� m = 1 M �� m G m ( x ) f(x)=\sum_{m=1}^{M} \alpha_{m} G_{m}(x) f(x)=��m=1M?��m?Gm?(x),�õ����յķ�����
G ( x ) = sign ? ( f ( x ) ) = sign ? ( �� m = 1 M �� m G m ( x ) ) \begin{aligned} G(x) &=\operatorname{sign}(f(x)) \\ &=\operatorname{sign}\left(\sum_{m=1}^{M} \alpha_{m} G_{m}(x)\right) \end{aligned} G(x)?=sign(f(x))=sign(m=1��M?��m?Gm?(x))?
�����Adaboost�㷨������˵��:
���ڲ���(1),����ѵ�����ݵ�Ȩֵ�ֲ��Ǿ��ȷֲ�,��Ϊ��ʹ�õ�һ��û��������Ϣ��������ÿ�������ڻ�����������ѧϰ������һ����
���ڲ���(2),ÿһ�ε��������Ļ���������
G
m
(
x
)
G_m(x)
Gm?(x)�ڼ�Ȩѵ�����ݼ��ϵķ��������
e
m
=
��
i
=
1
N
P
(
G
m
(
x
i
)
��
y
i
)
=
��
G
m
(
x
i
)
��
y
i
w
m
i
\begin{aligned}e_{m} &=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right) =\sum_{G_{m}\left(x_{i}\right) \neq y_{i}} w_{m i}\end{aligned}
em??=i=1��N?P(Gm?(xi?)��?=yi?)=Gm?(xi?)��?=yi?��?wmi??��������
G
m
(
x
)
G_m(x)
Gm?(x)�з�����������Ȩ�غ�,���ֱ��˵����Ȩ�طֲ�
D
m
D_m
Dm?��
G
m
(
x
)
G_m(x)
Gm?(x)�ķ��������
e
m
e_m
em?��ֱ�ӹ�ϵ��ͬʱ,�ڲ���(2)��,�������������
G
m
(
x
)
G_m(x)
Gm?(x)��ϵ��
��
m
\alpha_m
��m?,
��
m
=
1
2
log
?
1
?
e
m
e
m
\alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}}
��m?=21?logem?1?em??,����ʾ��
G
m
(
x
)
G_m(x)
Gm?(x)�����շ���������Ҫ�Գ̶�,
��
m
\alpha_m
��m?��ȡֵ�ɻ���������
G
m
(
x
)
G_m(x)
Gm?(x)�ķ����������ֱ�ӹ�ϵ,��
e
m
?
1
2
e_{m} \leqslant \frac{1}{2}
em??21?ʱ,
��
m
?
0
\alpha_{m} \geqslant 0
��m??0,����
��
m
\alpha_m
��m?����
e
m
e_m
em?�ļ��ٶ�����,��˷��������ԽС�Ļ��������������շ�����������Խ��!
**����Ҫ��,���ڲ���(2)�е�����Ȩ�صĸ���: **
w
m
+
1
,
i
=
{
w
m
i
Z
m
e
?
��
m
,
G
m
(
x
i
)
=
y
i
w
m
i
Z
m
e
��
m
,
G
m
(
x
i
)
��
y
i
w_{m+1, i}=\left\{\begin{array}{ll} \frac{w_{m i}}{Z_{m}} \mathrm{e}^{-\alpha_{m}}, & G_{m}\left(x_{i}\right)=y_{i} \\ \frac{w_{m i}}{Z_{m}} \mathrm{e}^{\alpha_{m}}, & G_{m}\left(x_{i}\right) \neq y_{i} \end{array}\right.
wm+1,i?={Zm?wmi??e?��m?,Zm?wmi??e��m?,?Gm?(xi?)=yi?Gm?(xi?)��?=yi??
���,����ʽ���Կ���:������������
G
m
(
x
)
G_m(x)
Gm?(x)��������������Ȩ������,����ȷ���������Ȩ�ؼ���,����������
e
2
��
m
=
1
?
e
m
e
m
\mathrm{e}^{2 \alpha_{m}}=\frac{1-e_{m}}{e_{m}}
e2��m?=em?1?em??����
���ڲ���(3),�������
f
(
x
)
f(x)
f(x)ʵ���˽�M�������������ļ�Ȩ����,ϵ��
��
m
\alpha_m
��m?��־�˻���������
G
m
(
x
)
G_m(x)
Gm?(x)����Ҫ��,ֵ��ע�����:���е�
��
m
\alpha_m
��m?֮�Ͳ�Ϊ1��
f
(
x
)
f(x)
f(x)�ķ��ž���������x������һ�ࡣ
����,����ʹ��sklearn��Adaboost�㷨���н�ģ:
���ΰ�������ʹ��һ��UCI�Ļ���ѧϰ����Ŀ�Դ���ݼ�:���Ѿ����ݼ�,�����ݼ������� ( https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data )�ϻ�á������ݼ�������178��������13������,�Ӳ�ͬ�ĽǶȶԲ�ͬ�Ļ�ѧ���Խ�������,���ǵ������Ǹ�����Щ����Ԥ����������һ�����(������Դ��python����ѧϰ(�ڶ��桷)
4. ǰ��ֲ��㷨
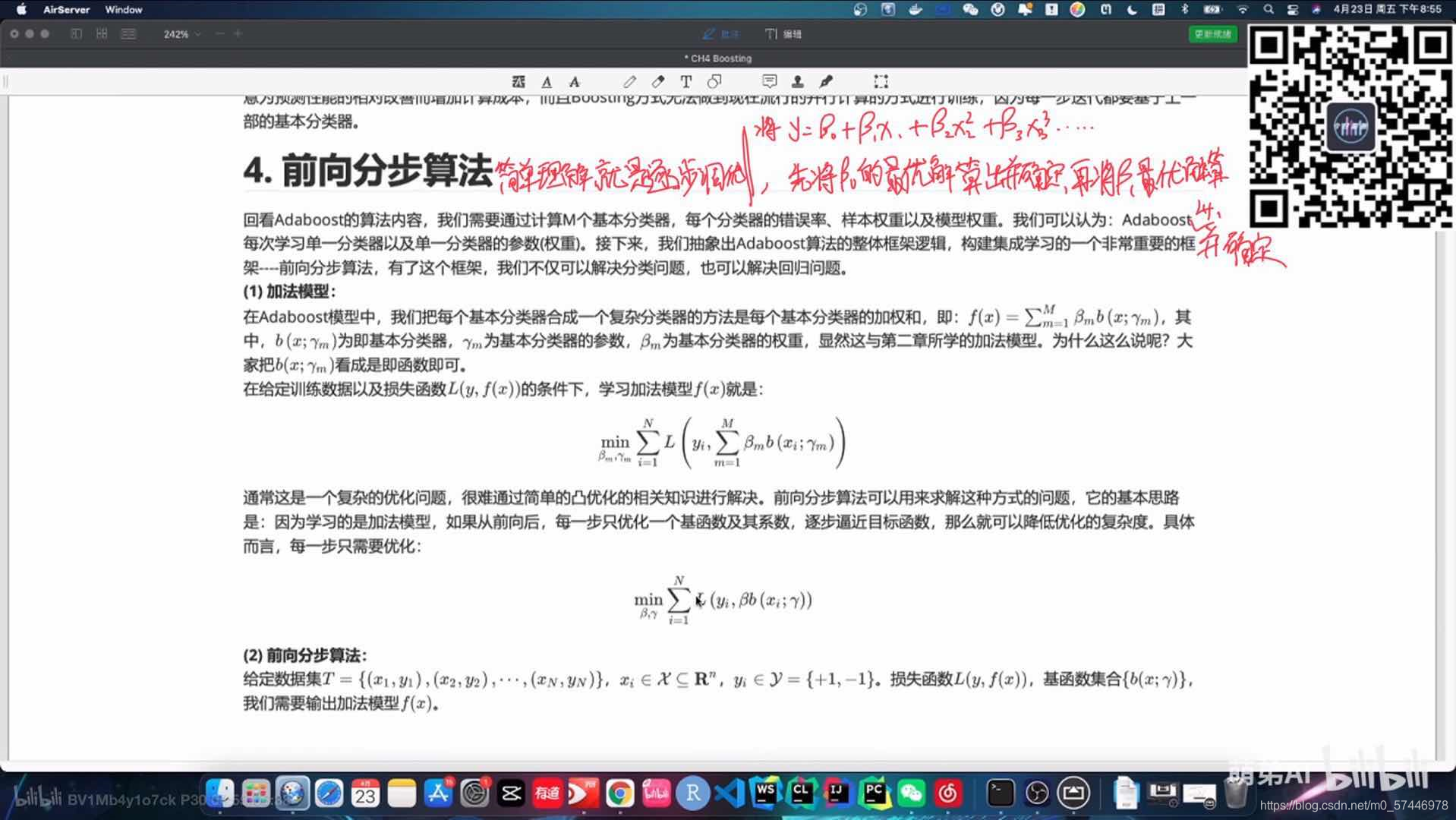
�ؿ�Adaboost���㷨����,������Ҫͨ������M������������,ÿ���������Ĵ����ʡ�����Ȩ���Լ�ģ��Ȩ�ء����ǿ�����Ϊ:Adaboostÿ��ѧϰ��һ�������Լ���һ�������IJ���(Ȩ��)��������,���dz����Adaboost�㷨����������,��������ѧϰ��һ���dz���Ҫ�Ŀ��----ǰ��ֲ��㷨,����������,���Dz������Խ����������,Ҳ���Խ���ع����⡣
(1) �ӷ�ģ��:
��Adaboostģ����,���ǰ�ÿ�������������ϳ�һ�����ӷ������ķ�����ÿ�������������ļ�Ȩ��,��:
f
(
x
)
=
��
m
=
1
M
��
m
b
(
x
;
��
m
)
f(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right)
f(x)=��m=1M?��m?b(x;��m?),����,
b
(
x
;
��
m
)
b\left(x ; \gamma_{m}\right)
b(x;��m?)������������,
��
m
\gamma_{m}
��m?�����������IJ���,
��
m
\beta_m
��m?Ϊ������������Ȩ��,��Ȼ����ڶ�����ѧ�ļӷ�ģ�͡�Ϊʲô��ô˵��?��Ұ�
b
(
x
;
��
m
)
b(x ; \gamma_{m})
b(x;��m?)�����Ǽ��������ɡ�
�ڸ���ѵ�������Լ���ʧ����
L
(
y
,
f
(
x
)
)
L(y, f(x))
L(y,f(x))��������,ѧϰ�ӷ�ģ��
f
(
x
)
f(x)
f(x)����:
min
?
��
m
,
��
m
��
i
=
1
N
L
(
y
i
,
��
m
=
1
M
��
m
b
(
x
i
;
��
m
)
)
\min _{\beta_{m}, \gamma_{m}} \sum_{i=1}^{N} L\left(y_{i}, \sum_{m=1}^{M} \beta_{m} b\left(x_{i} ; \gamma_{m}\right)\right)
��m?,��m?min?i=1��N?L(yi?,m=1��M?��m?b(xi?;��m?))
ͨ������һ�����ӵ��Ż�����,����ͨ�����Ż������֪ʶ���н����ǰ��ֲ��㷨��������������ַ�ʽ������,���Ļ���˼·��:��Ϊѧϰ���Ǽӷ�ģ��,�����ǰ���,ÿһ��ֻ�Ż�һ������������ϵ��,�ƽ�Ŀ�꺯��,��ô�Ϳ��Խ����Ż��ĸ��Ӷȡ��������,ÿһ��ֻ��Ҫ�Ż�:
min
?
��
,
��
��
i
=
1
N
L
(
y
i
,
��
b
(
x
i
;
��
)
)
\min _{\beta, \gamma} \sum_{i=1}^{N} L\left(y_{i}, \beta b\left(x_{i} ; \gamma\right)\right)
��,��min?i=1��N?L(yi?,��b(xi?;��))
(2) ǰ��ֲ��㷨:
�������ݼ�
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
?
?
,
(
x
N
,
y
N
)
}
T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\}
T={(x1?,y1?),(x2?,y2?),?,(xN?,yN?)},
x
i
��
X
?
R
n
x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}
xi?��X?Rn,
y
i
��
Y
=
{
+
1
,
?
1
}
y_{i} \in \mathcal{Y}=\{+1,-1\}
yi?��Y={+1,?1}����ʧ����
L
(
y
,
f
(
x
)
)
L(y, f(x))
L(y,f(x)),����������
{
b
(
x
;
��
)
}
\{b(x ; \gamma)\}
{b(x;��)},������Ҫ����ӷ�ģ��
f
(
x
)
f(x)
f(x)��
- ��ʼ��: f 0 ( x ) = 0 f_{0}(x)=0 f0?(x)=0
- ��m = 1,2,��,M:
- (a) ��С����ʧ����:
( �� m , �� m ) = arg ? min ? �� , �� �� i = 1 N L ( y i , f m ? 1 ( x i ) + �� b ( x i ; �� ) ) \left(\beta_{m}, \gamma_{m}\right)=\arg \min _{\beta, \gamma} \sum_{i=1}^{N} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+\beta b\left(x_{i} ; \gamma\right)\right) (��m?,��m?)=arg��,��min?i=1��N?L(yi?,fm?1?(xi?)+��b(xi?;��))
�õ����� �� m \beta_{m} ��m?�� �� m \gamma_{m} ��m? - (b) ����:
f m ( x ) = f m ? 1 ( x ) + �� m b ( x ; �� m ) f_{m}(x)=f_{m-1}(x)+\beta_{m} b\left(x ; \gamma_{m}\right) fm?(x)=fm?1?(x)+��m?b(x;��m?)
- (a) ��С����ʧ����:
- �õ��ӷ�ģ��:
f ( x ) = f M ( x ) = �� m = 1 M �� m b ( x ; �� m ) f(x)=f_{M}(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right) f(x)=fM?(x)=m=1��M?��m?b(x;��m?)
����,ǰ��ֲ��㷨��ͬʱ����m=1��M�����в���
��
m
\beta_{m}
��m?,
��
m
\gamma_{m}
��m?���Ż������Ϊ���������
��
m
\beta_{m}
��m?,
��
m
\gamma_{m}
��m?�����⡣
(3) ǰ��ֲ��㷨��Adaboost�Ĺ�ϵ:
�������ﲻ�����ǵ��ص�,������Ҫ��������Ľ���,�������֤��,�����֤�������ʦ�ġ�ͳ��ѧϰ�������ڰ��µ�3.2�ڡ�Adaboost�㷨��ǰ��ֲ��㷨������,Adaboost�㷨���ɻ�����������ɵļӷ�ģ��,��ʧ����Ϊָ����ʧ������