����Ŀ¼
1. ��������?
(1)����ͨ���ռ������ѵ������������,�������ַ����ɱ���,���Ҳ�����Ϊ����,��ʱ���ں���ȡ�úܸߵij�Ч;
(2)Ҳ����ͨ��������������������������,���ض���ijЩ�������ѵ��������������Ӱ�졣
(3)���������Ѿ�ӵ�����㹻��ĸ���������,���ǿ��������������������ϵ�Ӱ�졣
2. ��κ���ģ�͵ĸ��Ӷ�?
��ס:ģ��Խ����,������ϵĺ���Ҳ��Խ����,����ҲԽ���������;����ģ���ڼ�,�ֺ�������Ƿ���,���ܹ�ѧϰ�����ݵĹؼ�������
�����ǻ���һ������ֱ��,�������к��� f f f��,���� f = 0 f = 0 f=0(�������붼�õ�ֵ 0 0 0)��ij�������������,���ǿ���ͨ����������ľ��������������ĸ��Ӷ�����������Ӧ����ξ�ȷ�ز���һ����������֮��ľ�����?û��һ����ȷ�Ĵ𰸡���ʵ��,������ѧ��֧,�������������Ͱ��úտռ�����,���������ڻش�������⡣
һ�ּķ�����ͨ�����Ժ��� f ( x ) = w ? x f(\mathbf{x}) = \mathbf{w}^\top \mathbf{x} f(x)=w?x�е�Ȩ��������ij�������������临����,���� �� w �� 2 \| \mathbf{w} \|^2 ��w��2��Ҫ��֤Ȩ�������Ƚ�С,��÷����ǽ��䷶����Ϊ�ͷ���ӵ���С����ʧ����������
����,������ǵ�Ȩ������������̫��,���ǵ�ѧϰ�㷨���ܻ����������С��Ȩ�ط��� �� w �� 2 \| \mathbf{w} \|^2 ��w��2��������������Ҫ�ġ����ǵ���ʧ����ʽ����:
L ( w , b ) = 1 n �� i = 1 n 1 2 ( w ? x ( i ) + b ? y ( i ) ) 2 . L(\mathbf{w}, b) = \frac{1}{n}\sum_{i=1}^n \frac{1}{2}\left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right)^2. L(w,b)=n1?i=1��n?21?(w?x(i)+b?y(i))2.
3. ͨ�����Ʋ�����ѡ��Χ������ģ������(���Ӷ�)
- ʹ�þ���������ΪӲ������
m i n ?? L ( w , b ) s u b j e c t ?? t o ?? �O �O w �O �O 2 ? �� min \; L(w,b) \quad subject \; to \; ||w||^2 \leqslant \theta minL(w,b)subjectto�O�Ow�O�O2?��
* ͨ��������ƫ��b(�����벻���Ƶ�����)
* С �� \theta ����ʾ��ǿ�������� - ʹ�þ���������Ϊ��������
* ����ÿ�� �� \theta ���������ҵ� �� \lambda ��ʹ��֮ǰ��Ŀ�꺯���ȼ������湫ʽ(ʹ���������ճ���֤��):
m i n ?? L ( w , b ) + �� 2 �O �O w �O �O 2 min \; L(w,b) + \frac{\lambda}{2}||w||^2 minL(w,b)+2��?�O�Ow�O�O2
* ������ �� \lambda �����������������Ҫ�̶�
* �� = 0 \lambda = 0 ��=0:������
* �� �� �� \lambda \rightarrow \infty ������: w ? �� 0 w^* \rightarrow 0 w?��0
4. ���������Ȩ��˥��?
-
�����ݶ�
? ? w ( L ( w , b ) + �� 2 �O �O w �O �O 2 ) = ? L ( w , b ) ? w + �� w \frac{\partial}{\partial w}(L(w,b)+\frac{\lambda}{2}{||w||}^2) = \frac{\partial L(w,b)}{\partial w} + \lambda w ?w??(L(w,b)+2��?�O�Ow�O�O2)=?w?L(w,b)?+��w -
ʱ��t���²���
w t + 1 = w t ? �� ( ? L ( w t , b ) ? w t + �� w t ) w_{t+1} = w_t - \eta (\frac{\partial L(w_t,b)}{\partial w_t} + \lambda w_t) wt+1?=wt??��(?wt??L(wt?,b)?+��wt?)
w t + 1 = ( 1 ? �� �� ) w t ? �� ? L ( w t , b t ) ? w t w_{t+1} = (1-\eta \lambda)w_t - \eta \frac{\partial L(w_t,b_t)}{\partial w_t} wt+1?=(1?����)wt??��?wt??L(wt?,bt?)?- �� \eta ��Ϊѧϰ��
- ͨ�� �� �� < 1 \eta \lambda < 1 ����<1,�����ѧϰ��ͨ����֮ΪȨ��˥��
���Կ����������������loss function���ݶ�ֻ���� w t w_t wt?���������һ�� ? �� �� -\eta \lambda ?������,ͨ�� ? �� �� < 1 -\eta \lambda<1 ?����<1��ô���ǵõ����ݶȸ������ͻ����ݶȸ��µķ����ϻ���һЩ,�Ӷ��������ݶȸ��µIJ��ӡ�
5. ���ӻ��ؿ����������������Ȩ��˥�����ﵽ�������ϵ�Ŀ�ĵ�
Ȩ��˥�˴���ʵ��(��������2021����ѧ���ѧϰ�γ��еĽ�ѧ����):
ѵ���Ĺ�ʽΪ:
y
=
0.05
+
��
i
=
1
d
0.01
x
i
+
?
?where?
?
��
N
(
0
,
0.0
1
2
)
.
y = 0.05 + \sum_{i = 1}^d 0.01 x_i + \epsilon \text{ where } \epsilon \sim \mathcal{N}(0, 0.01^2).
y=0.05+i=1��d?0.01xi?+??where??��N(0,0.012).
����ѡ���ǩ�ǹ�����������Ժ�������ǩͬʱ����ֵΪ0,����Ϊ0.01��˹�����ƻ���Ϊ��ʹ����ϵ�Ч����������,���ǿ��Խ������ά�����ӵ�
d
=
200
d = 200
d=200,��ʹ��һ��ֻ����20��������Сѵ������
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l
# ѵ������20,��������100��,��������ά��200,���δ�С5(ѵ������̫С,���������)
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
# ��ʼ��ģ�Ͳ���
def init_params():
w = torch.normal(0,1,size =(num_inputs,1),requires_grad=True)
b = torch.zeros(1,requires_grad=True)
return [w,b]
# ����L2�����ͷ�
def l2_penalty(w):
return torch.sum(w.pow(2))/2
# ����ѵ������
def train(lambd):
w,b = init_params()
net,loss = lambda X:d2l.linreg(X,w,b),d2l.squared_loss
num_epochs ,lr = 500,0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X,y in train_iter:
l = loss(net(X),y)+lambd*l2_penalty(w)
l.sum().backward()
d2l.sgd([w,b],lr,batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
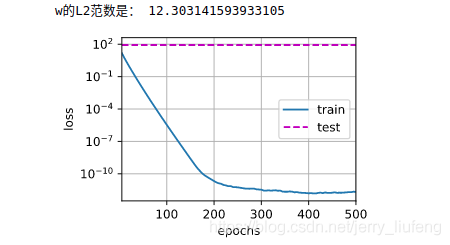
print('w��L2������:', torch.norm(w).item())
# ��������ֱ��ѵ��
train(lambd=0)
# ʹ��Ȩ��˥��
train(lambd=3)
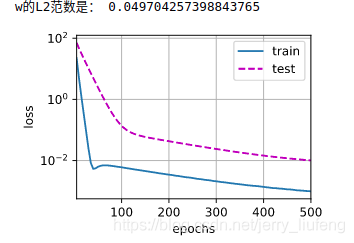
�ɴ˿ɼ�������Ȩ��˥�˵�ȴ�ǻ����˹���ϵ�����(δ������ʱ,��ѵ�����Ͳ����������,���Թ����)��
6. Ϊʲôʹ��ƽ���������DZ�����(ŷ����þ���)?
L ( w , b ) + �� 2 �� w �� 2 , L(\mathbf{w}, b) + \frac{\lambda}{2} \|\mathbf{w}\|^2, L(w,b)+2��?��w��2,
���� �� = 0 \lambda = 0 ��=0,���ǻָ���ԭ������ʧ���������� �� > 0 \lambda > 0 ��>0,�������� �� w �� \| \mathbf{w} \| ��w���Ĵ�С����ʽ�г��� 2 2 2:������ȡһ�����κ����ĵ���ʱ, 2 2 2�� 1 / 2 1/2 1/2�����,��ȷ�����±���ʽ��������Ư���ּ�
���Բ���ƽ��������ԭʼ��Ϊ�����ڼ�����ͨ��ƽ�� L 2 L_2 L2?����,����ȥ��ƽ����,����Ȩ������ÿ��������ƽ���͡���ʹ�óͷ��ĵ�����������:�����ĺ͵��ں͵ĵ�����
7. L1������L2������Ӧ���е�һЩ����
L1������L2����������ͳ��ѧϰ����������Ч���ܻ�ӭ����������
- L1�������Իع���ͳ��ѧϰ�еĻ���ģ��,ͨ����֮Ϊ�������ع顱(lasso regression)
- L1����ʩ�ӵijͷ���֮L2������С,ʹ��ģ�ͽ�����Ȩ������,����Ȩ����Ҫ������һС����������,Ҳ����֮Ϊ������ѡ��,��ijЩ�龰�����Ƿdz���Ҫ�ͱ���Ҫ�ġ�
- L2��������ģ�������˾���ġ���ع顱(ridge regression)
- L2������Ȩ������ʩ���˾�ijͷ�,ʹ�����ǵ�ѧϰ�㷨ƫ�����ڴ��������Ͼ��ȷֲ�Ȩ�ص�ģ��(Ҳ����˵ʹ��ģ�ͶԵ��������е�������³��)