�˹����� (AI)
һ���˹����ܼ��
1.1.�˹����ܷ�չ��ʷ
ͼ�����




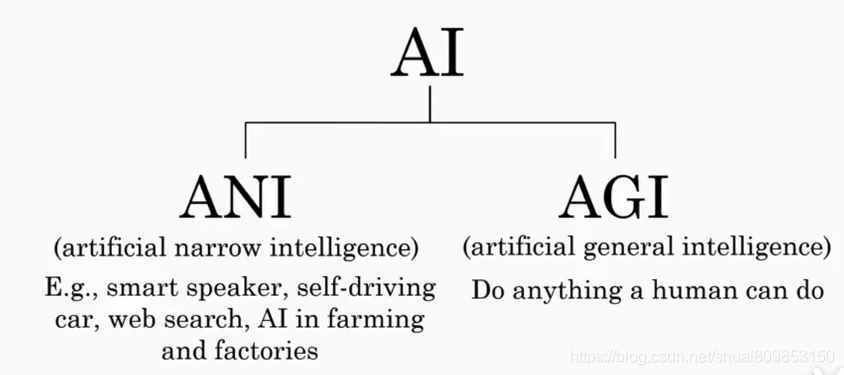
ANI :���˹�����
AGI:ǿ�˹�����

1.2.�˹����ܷ�չ�ر���Ҫ��
1.2.1.��Ҫ��
1)����
2)�㷨
3)������:CPU,GPU,TPU
CPU:��Ҫ�ʺ�IO�ܼ�������
GPU:��Ҫ�ʺϼ����ܼ�������
�����ܼ��ij���:��ν�����ܼ��͵ij���,�����������ʱ�仨�ڼĴ���������,�Ĵ������ٶȺʹ��������ٶ��൱,�ӼĴ�����д���ݼ���û���ӳ�,����һ�¶Ա�,��ȡ�ڴ���ӳٴ�ż��ٸ�ʱ������,��Ӳ�̵��ٶȾͲ�˵��,��ʹ��ssd,Ҳ�Ǻ�����

1.3.�˹����ܷ�֧����
1.4.�˹����ܡ�����ѧϰ�����ѧϰ�Ĺ�ϵ
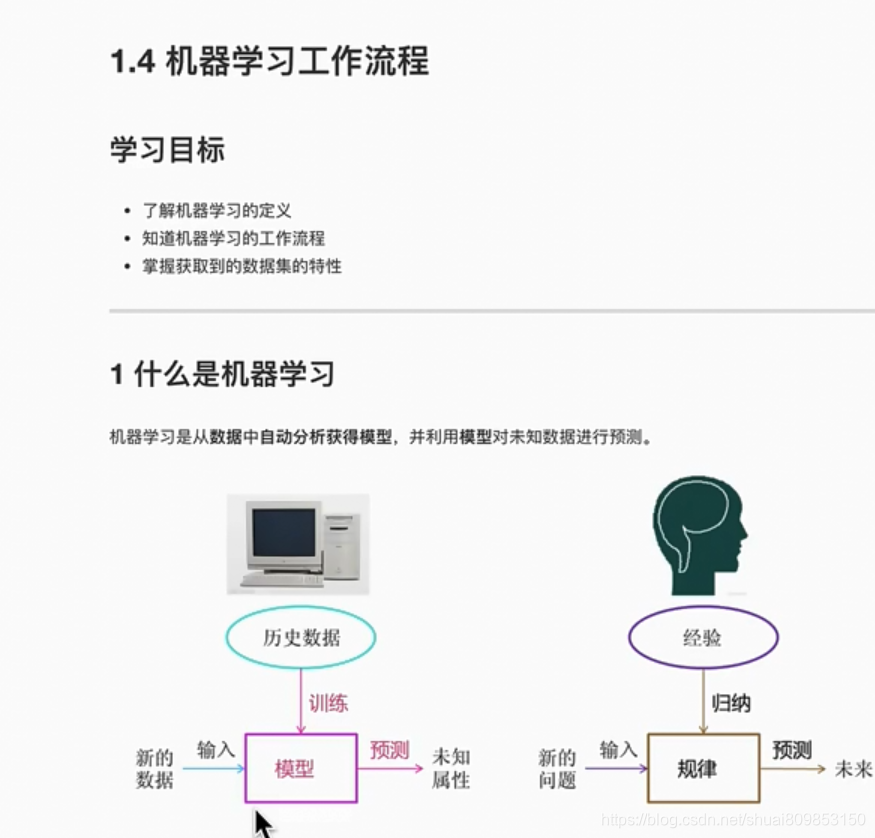
��Щ���˹����ܡ�����ѧϰ�����ѧϰ�ĸ���ʮ�ֻ���,���ܶ��ҵ��ȴ����˵������֮��Ĺ�ϵ,�����˸�������������о����ѧϰ֮ǰ,�����ȴ����������������Դ��ʼ��
������˵,�˹����ܡ�����ѧϰ�����ѧϰ���ǵļ������������ݼ��ġ��˹�������������ĸ������ѧϰ�ǵ�ǰ�Ƚ���Ч��һ��ʵ���˹����ܵķ�ʽ�����ѧϰ�ǻ���ѧϰ�㷨�������ŵ�һ����֧,��Щ��ȡ���������Ľ�չ,������˴������ͳ����ѧϰ�㷨�����ߵĹ�ϵ�� ͼ1 ��ʾ,��:�˹����� > ����ѧϰ > ���ѧϰ��
ͼ1:�˹����ܡ�����ѧϰ�����ѧϰ���߹�ϵʾ��

�����溬��,�˹��������з�����ģ�⡢�������չ�˵����ܵ����ۡ�������������Ӧ��ϵͳ��һ���µļ�����ѧ�������������ֻ������Ŀ��,��û��������,���ʵ���˹����ܴ��ڵ������ͷ�
1.2.
�������ݿ�ѧ


��������ѧϰ
3.1.ʲô�ǻ���ѧϰ
3.2.����ѧϰ��������

3.3.����ѧϰ�㷨����

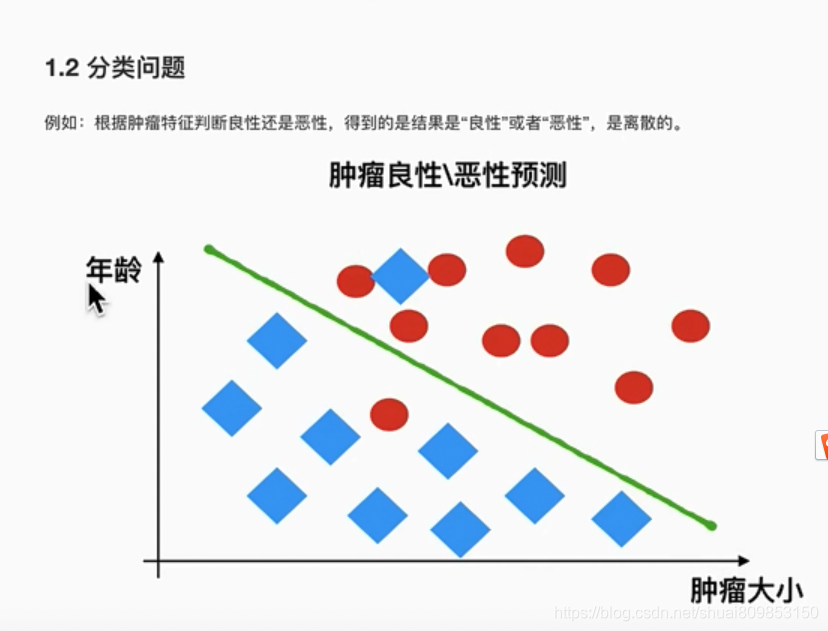

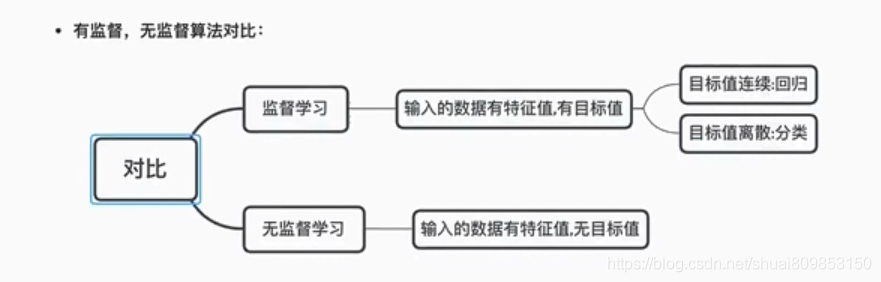
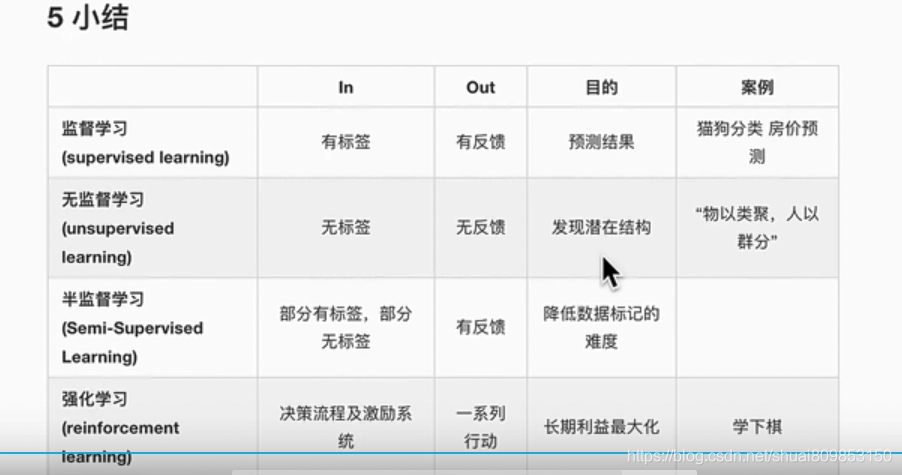
3.3 ����ѧϰ������
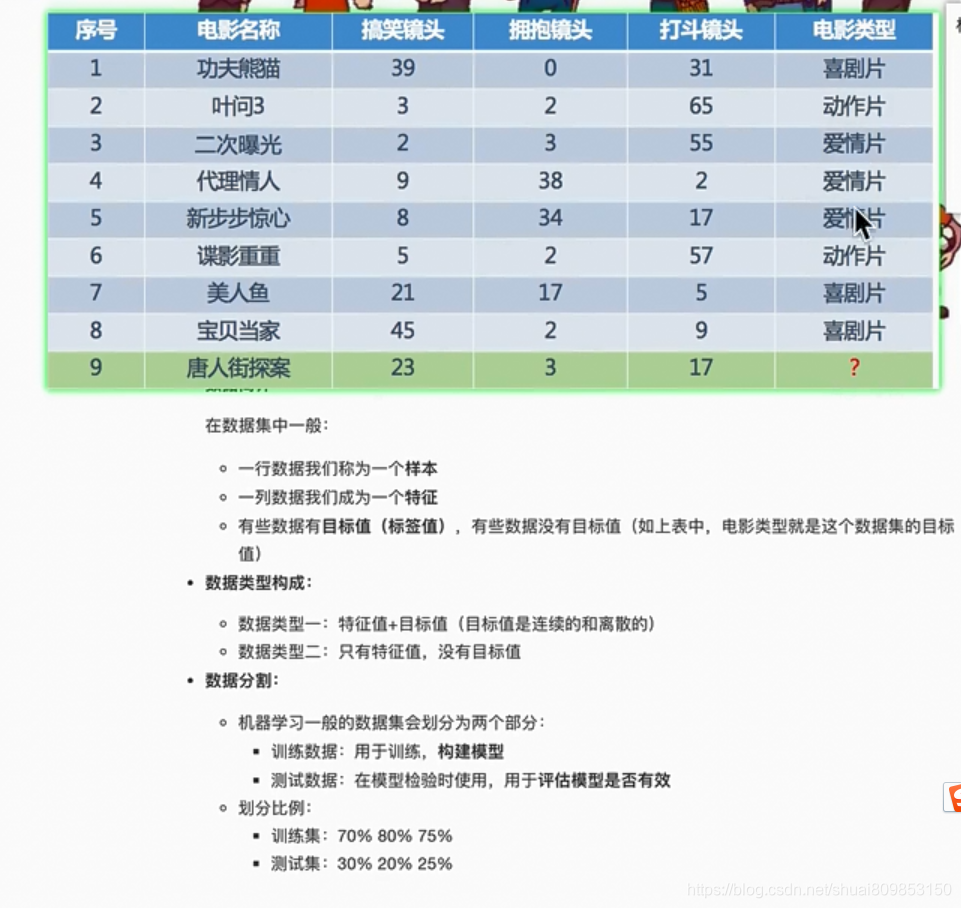
�ڻ���ѧϰ��,��һ�ֽ�����û����ѵ���͡��Ķ����������֮,��ָ��û���κ�һ���㷨���������ⶼ��Ч,�ڼලѧϰ(��Ԥ�⽨ģ)��������ˡ�
����,�㲻��˵���������DZȾ�������,��֮��Ȼ���кܶ�������������,�������ݼ��Ĵ�С�ͽṹ��
���,��Ӧ����Ծ������Ⳣ�Զ��ֲ�ͬ�㷨,������һ�����ݡ����Լ������������ܡ�ѡ����ʤ�ߡ�
��Ȼ,�㳢�Ե��㷨�����ʺ��������,Ҳ����ѡ����ȷ�Ļ���ѧϰ������ȷ�,�������Ҫ��ɨ����,����ܻ�����������ɨ����ϰ�,�����㲻���ó����ӿ�ʼ������
��ԭ��
����Ҳ��һ���ձ�ԭ��,�����мල����ѧϰ�㷨Ԥ�⽨ģ�Ļ�����
����ѧϰ�㷨������Ϊѧϰһ��Ŀ�꺯�� f,�ú������������ X ��õ�ӳ�䵽������� Y:Y = f(X)
����һ���ձ��ѧϰ����,���ǿ��Ը���������� X ���������� Y ����Ԥ�⡣���Dz�֪������ f �����ӻ���ʽ���������֪���Ļ�,���ǽ���ֱ��ʹ����,����Ҫ�û���ѧϰ�㷨��������ѧϰ��
����Ļ���ѧϰ�㷨��ѧϰӳ�� Y = f(X) ��Ԥ���� X �� Y�������Ԥ�⽨ģ��Ԥ�����,���ǵ�Ŀ���Ǿ�����������ȷ��Ԥ�⡣
�������˽����ѧϰ����֪ʶ������,���Ľ��������ݿ�ѧ��ʹ�õ� top 10 ����ѧϰ�㷨��
- ���Իع�
���Իع������ͳ��ѧ�ͻ���ѧϰ����֪��������������㷨֮һ��
Ԥ�⽨ģ��Ҫ��ע��С��ģ�������߾�����������ȷ��Ԥ��,�Կɽ�����Ϊ���ۡ����ǽ����á����ð���ͳ��ѧ���ڵĺܶͬ������㷨,������������ЩĿ�ġ�
���Իع�ı�ʾ��һ������,��ͨ���ҵ�����������ض�Ȩ��(��Ϊϵ�� B),������һ�����ʺϱ�ʾ������� x ��������� y ��ϵ��ֱ��
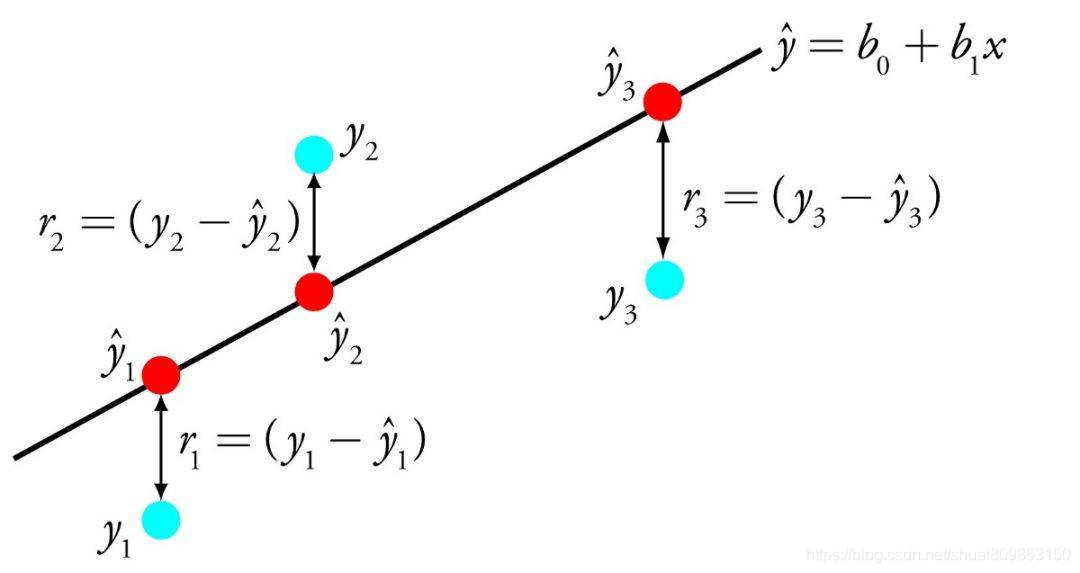
���Իع�
����:y = B0 + B1 * x
���ǽ��������� x Ԥ�� y,���Իع�ѧϰ�㷨��Ŀ�����ҵ�ϵ�� B0 �� B1 ��ֵ��
����ʹ�ò�ͬ�ļ�����������ѧϰ���Իع�ģ��,����������ͨ��С���˷����ݶ��½��Ż������Դ����⡣
���Իع��Ѿ������� 200 ����,���õ��˹㷺�о���ʹ�����ּ�����һЩ�����Ǿ�����ȥ���dz�����(���)�ı���,��ȥ������������һ�ֿ��١��ļ���,�������ȳ���һ�¡�
- Logistic �ع�
Logistic �ع��ǻ���ѧϰ��ͳ��ѧ�н������һ�ּ��������ǽ���������������ѡ������
Logistic �ع������Իع�����,Ŀ�궼���ҵ�ÿ�����������Ȩ��,��ϵ��ֵ�������Իع鲻ͬ����,Logistic �ع�������Ԥ��ʹ�ñ���Ϊ logistic �����ķ����Ժ������б任��
logistic ������������һ����� S,���ҿ��Խ��κ�ֵת���� 0 �� 1 �������ڡ���dz�ʵ��,��Ϊ���ǿ��Թ涨 logistic ���������ֵ�� 0 �� 1(����,����С�� 0.5 �����Ϊ 1)��Ԥ�����ֵ��
Logistic �ع�
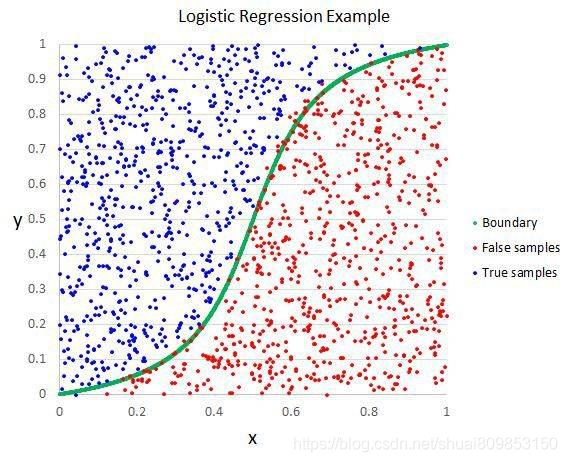
����ģ�͵�ѧϰ��ʽ,Logistic �ع��Ԥ��Ҳ������Ϊ��������ʵ��(������� 0 �� 1)�ĸ��ʡ��������ҪΪԤ���ṩ�������ݵ���������á�
�����Իع�һ��,Logistic �ع���ɾ������������ص������Լ��dz�����(���)������ʱЧ�����á�����һ�����ٵ�ѧϰģ��,���Ҷ��ڶ���������dz���Ч��
- ��������(LDA)
Logistic �ع���һ�ַ����㷨,��ͳ��,��������ֻ������ķ������⡣��������������ϵ����,��ô�����б��������ѡ�����Է��༼����
LDA �ı�ʾ�dz���ֱ�ӡ��������ݵ�ͳ�����Թ���,��ÿ�������м��㡣������������� LDA ����:
ÿ������ƽ��ֵ;
�������ķ��
��������
����Ԥ��ķ����Ǽ���ÿ�������б�ֵ���Ծ߱����ֵ��������Ԥ�⡣�ü����������ݳʸ�˹�ֲ�(��������),������Ԥ�ȴ�������ɾ���쳣ֵ�����Ǵ�������Ԥ�⽨ģ�����һ�ּ�ǿ��ķ�����
- ������ع���
��������Ԥ�⽨ģ����ѧϰ��һ����Ҫ�㷨��
������ģ�͵ı�ʾ��һ���������������㷨�����ݽṹ�еĶ�����,ûʲô�ر�ġ�ÿ���ڵ����һ��������������� x �ñ����ϵ�һ���ָ��(�������������)��
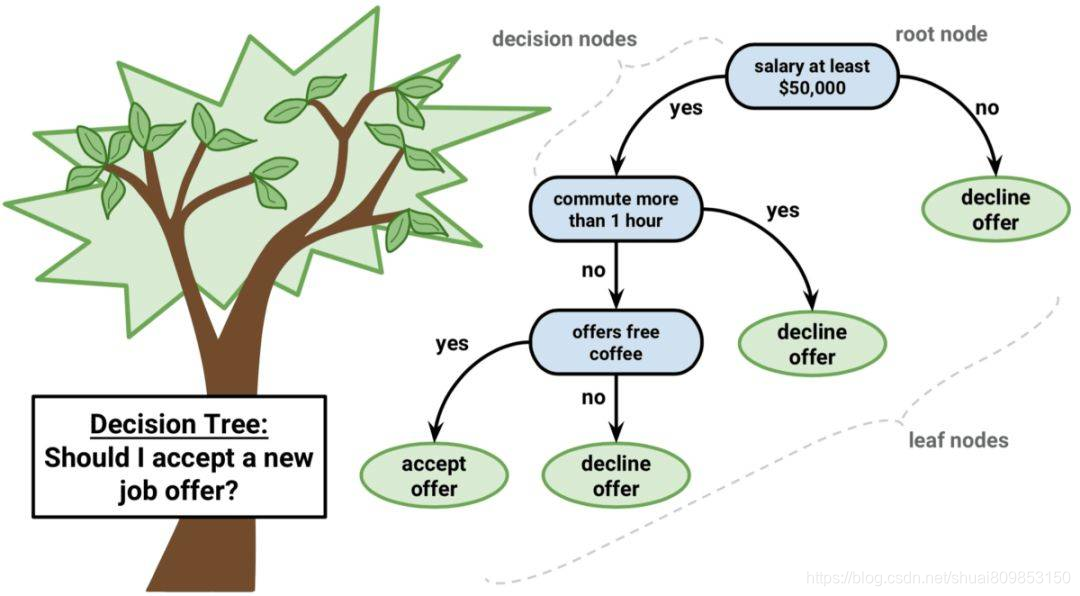
������
��������Ҷ�ڵ����һ������Ԥ���������� y��ͨ�����������ķָ��,ֱ������һ��Ҷ�ڵ㲢����ýڵ�����ֵ�Ϳ�������Ԥ�⡣
������ѧϰ�ٶȺ�Ԥ���ٶȶ��ܿ졣���ǻ����Խ����������,���Ҳ���Ҫ���������ر�����
- ���ر�Ҷ˹
���ر�Ҷ˹��һ�����Ǻ�ǿ���Ԥ�⽨ģ�㷨��
��ģ�������ָ������,�����ָ��ʶ�����ֱ�Ӵ�ѵ�������м������:1)ÿ�����ĸ���;2)����ÿ�� x ��ֵ,ÿ�������������ʡ�һ���������,����ģ�Ϳ�����ʹ�ñ�Ҷ˹�����������ݽ���Ԥ�⡣�����������ʵֵʱ,ͨ������һ����˹�ֲ�(��������),��������ԼĹ�����Щ���ʡ�
��Ҷ˹����
���ر�Ҷ˹֮���������ص�,����Ϊ������ÿ����������Ƕ����ġ�����һ��ǿ��ļ���,��ʵ�����ݲ������,����,�ü����ڴ������������Ϸdz����á�
- K �����㷨
KNN �㷨�dz�������Ч��KNN ��ģ�ͱ�ʾ������ѵ�����ݼ����Dz��Ǻܼ�?
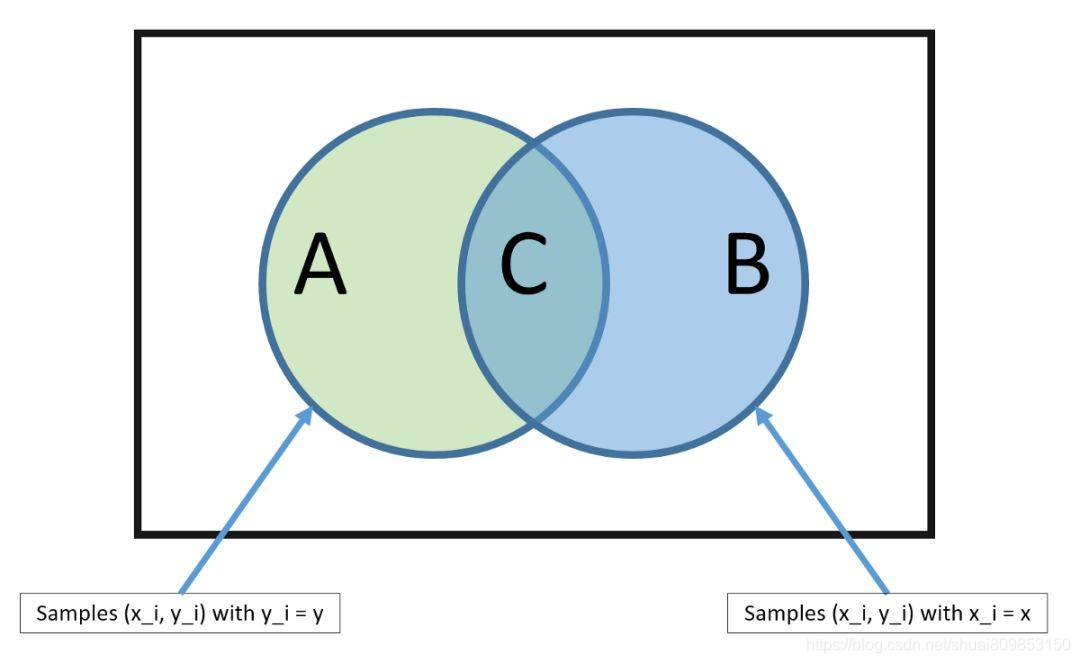
KNN �㷨������ѵ���������� K ��������ʵ��(����)�������� K ��ʵ�����������,��Ԥ�������ݵ㡣���ڻع�����,�������ƽ���������,���ڷ�������,�����������(�������)���ֵ��
�����������ȷ������ʵ����������ԡ�������ԵĶ�����λ��ͬ(���綼����Ӣ���ʾ),��ô��ļ�����ʹ��ŷ����þ���,����Ը���ÿ���������֮��IJ�ֱֵ�Ӽ����������ֵ��
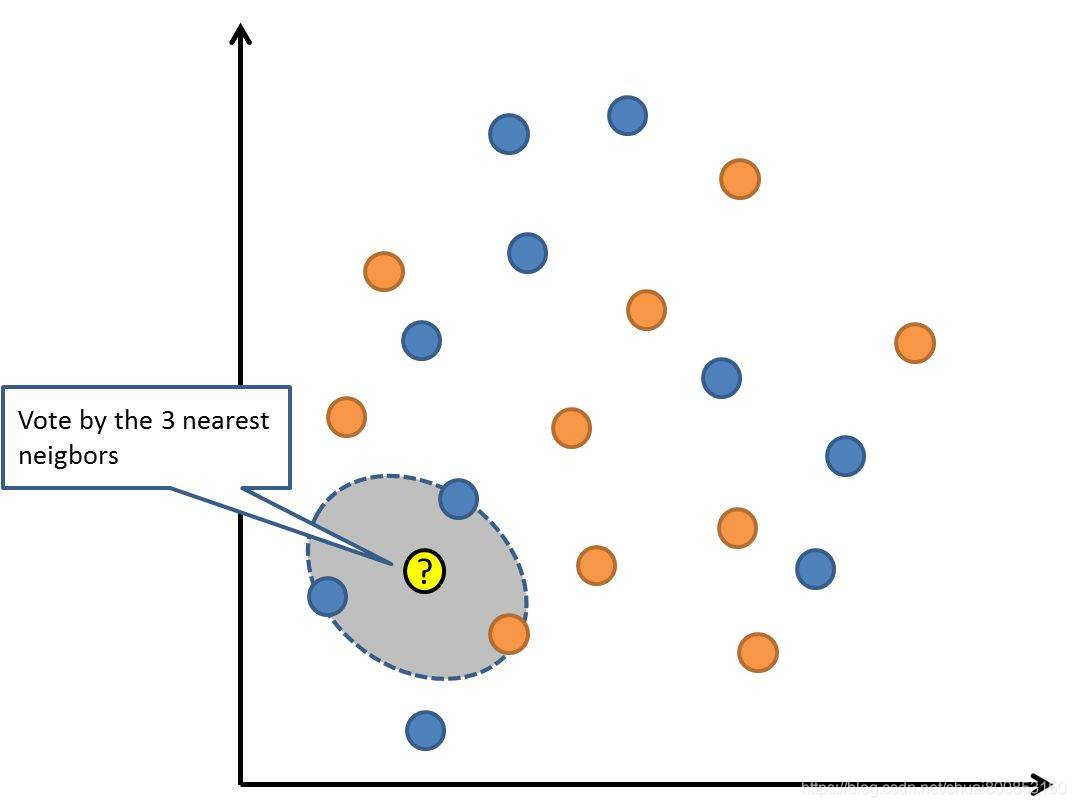
K �����㷨
KNN ��Ҫ�����ڴ��ռ����洢��������,����ֻ������ҪԤ��ʱ��ִ�м���(��ѧϰ)���㻹������ʱ���º���ѵ��ʵ��,�Ա���Ԥ���ȷ�ԡ�
���������Եĸ�������ڷdz��ߵ�ά��(�ܶ��������)�л��߽�,����㷨����������ϵ����ܲ�������Ӱ�졣�ⱻ��Ϊά�����ѡ���������ֻʹ����Щ��Ԥ�������������ص����������
- ѧϰ��������
K �����㷨��һ��ȱ��������Ҫ��������ѵ�����ݼ���ѧϰ���������㷨(��� LVQ)��һ���˹��������㷨,��������ѡ��ѵ��ʵ��������,����ȷ��ѧϰ��Щʵ��Ӧ����ʲô���ġ�
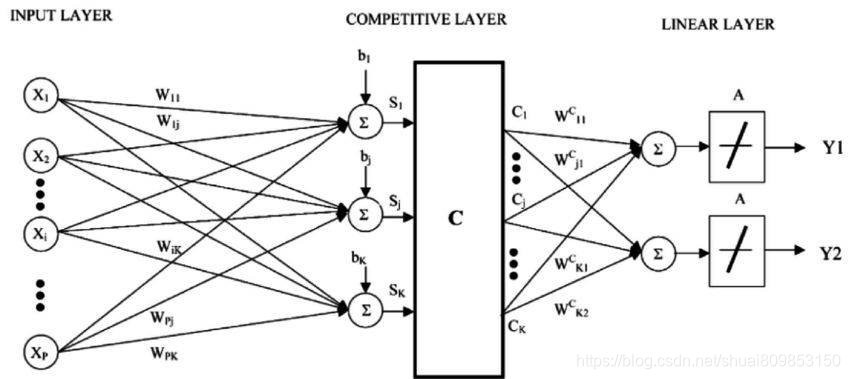
ѧϰ��������
LVQ �ı�ʾ���뱾�����ļ��ϡ���Щ���ڿ�ʼʱ���ѡ���,����������ѧϰ�㷨�Ķ�ε�������õ��ܽ�ѵ�����ݼ�����ѧϰ֮��,�뱾����������Ԥ��(���� K �����㷨)�������ƵĽ���(���ƥ����뱾����)ͨ������ÿ���뱾������������ʵ��֮��ľ����ҵ���Ȼ�����ƥ�䵥Ԫ�����ֵ��(�ع��е�ʵ��ֵ)��ΪԤ�⡣��������µ�������,ʹ�������ͬ�ķ�Χ(���� 0 �� 1 ֮��),�Ϳ��Ի����ѽ����
����㷢�� KNN ��������ݼ��ϴﵽ�ܺõĽ��,�볢���� LVQ ���ٴ洢����ѵ�����ݼ����ڴ�Ҫ��
- ֧��������(SVM)
֧�����������������ܻ�ӭ����㷺���۵Ļ���ѧϰ�㷨֮һ��
��ƽ���Ƿָ���������ռ��һ���ߡ��� SVM ��,ѡ��һ��������õظ�������������(��� 0 ����� 1)����������ռ���зָ�ij�ƽ�档�ڶ�ά��,����Խ�����Ϊһ����,���Ǽ������е�����㶼���Ա���������ȫ�ķֿ���SVM ѧϰ�㷨�ҵ��˿����ó�ƽ�����������ѷָ��ϵ����
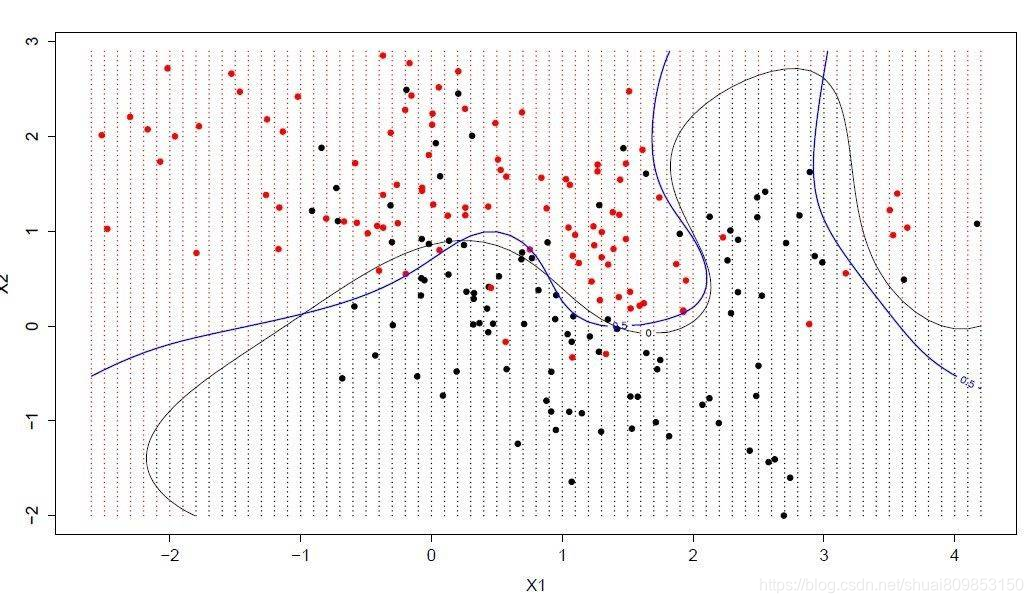
֧��������
��ƽ�����������ݵ�֮��ľ��뱻��Ϊ������ֿ�����������õĻ�������ij�ƽ��߱��������ֻ����Щ���붨�峬ƽ������������йء���Щ�㱻��Ϊ֧������,����֧�ֻ����˳�ƽ�档ʵ����,�Ż��㷨����Ѱ��������ϵ����ֵ��
SVM ��������ǿ����������õķ�����֮һ,ֵ��һ�ԡ�
- Bagging �����ɭ��
���ɭ���������к���ǿ��Ļ���ѧϰ�㷨֮һ������ Bootstrap Aggregation(�ֳ� bagging)���ɻ���ѧϰ�㷨��һ�֡�
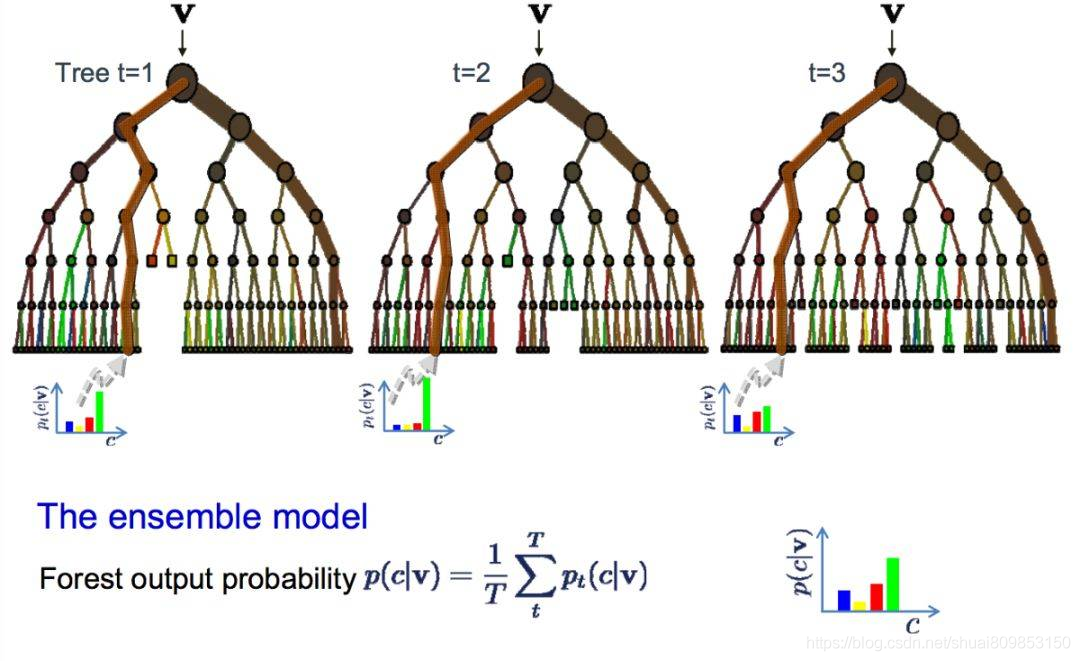
bootstrap �Ǵ����������й���������һ��ǿ���ͳ�Ʒ���������ƽ��������������г�ȡ��������,����ƽ��ֵ,Ȼ��ƽ�����е�ƽ��ֵ�Ա���õĹ�����ʵ��ƽ��ֵ��
bagging ʹ����ͬ�ķ���,��������������ͳ��ģ��,������Ǿ���������ѵ�������г�ȡ�������,Ȼ���ÿ������������ģ��������Ҫ�������ݽ���Ԥ��ʱ,ÿ��ģ�Ͷ�����Ԥ��,�������е�Ԥ��ֵƽ���Ա���õĹ�����ʵ�����ֵ��
���ɭ��
���ɭ���Ƕ����ַ�����һ�ֵ���,�����ɭ�ֵķ����о������������Ա���ͨ����������������д��ŷָ�,������ѡ����ѷָ�㡣
���,���ÿ����������������ģ�ͽ�����������ʽ�õ���������ͬ,������Ȼ���������Ҳ�ͬ,������Ȼ��ȷ�ġ�������ǵ�Ԥ����Ը��õĹ�����ʵ�����ֵ��
������÷���ϸߵ��㷨(�������)�õ��˺ܺõĽ��,��ôͨ������ͨ�� bagging ���㷨����ø��õĽ����
- Boosting �� AdaBoost
Boosting ��һ�ּ��ɼ���,����ͼ����һЩ��������������һ��ǿ����������ͨ����ѵ�������й���һ��ģ��,Ȼ���ڶ���ģ�������Ծ�����һ��ģ�͵Ĵ�������ɡ�һֱ����ģ��ֱ���ܹ�����Ԥ��ѵ����,�����ӵ�ģ�������Ѿ��ﵽ���������
AdaBoost �ǵ�һ��Ϊ��������������ɹ��� boosting �㷨���������� boosting �������㡣�ִ� boosting ���������� AdaBoost ֮��,��������������ݶ�������
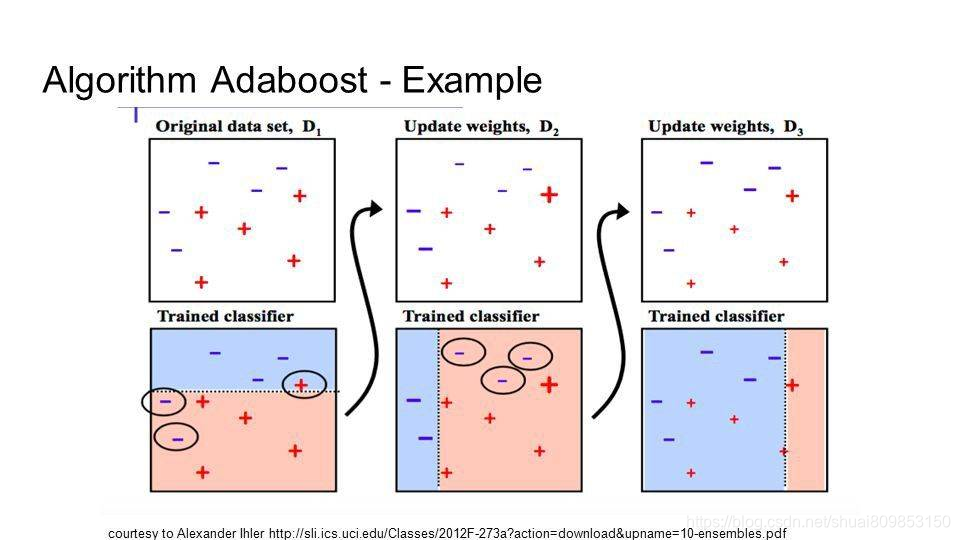
AdaBoost
AdaBoost ��̾�����һ��ʹ�á��ڵ�һ������������֮��,����ÿ��ѵ��ʵ��������������������һ��������Ӧ�ö�ÿ��ѵ��ʵ����������ע����������Ԥ���ѵ�����ݱ��������Ȩ��,������Ԥ������ݷ����Ȩ�ؽ��١����δ���ģ��,ÿ��ģ����ѵ��ʵ���ϸ���Ȩ��,Ӱ����������һ����������ѧϰ�������о���������֮��,�������ݽ���Ԥ��,����ͨ��ÿ����������ѵ�������ϵľ�ȷ�����������ܡ�
��Ϊ�ھ����㷨������Ͷ����̫��ע����,���Ծ߱���ɾ���쳣ֵ�ĸɾ����ݷdz���Ҫ��
�ܽ�
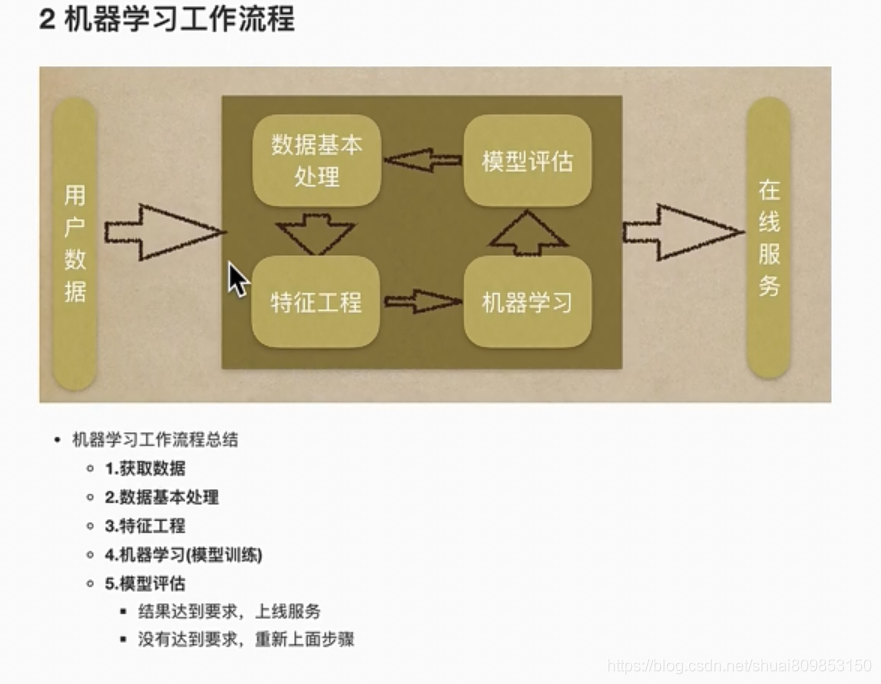
��ѧ������Ը��ֻ���ѧϰ�㷨ʱ������:����Ӧ�����ĸ��㷨?���������Ĵ�ȡ���ںܶ�����,����:(1)���ݵĴ�С������������;(2)���õļ���ʱ��;(3)����Ľ�����;(4)��������Щ������ʲô��
��ʹ�Ǿ���ḻ�����ݿ�ѧ���ڳ��Բ�ͬ���㷨֮ǰ,Ҳ���ֱ������㷨�������á���Ȼ���кܶ������Ļ���ѧϰ�㷨,����ƪ���������۵������ܻ�ӭ���㷨��������ǻ���ѧϰ������,�⽫��һ���ܺõ�ѧϰ��㡣
2. ����ѧ��:
�˹�������
3.4.����ѧϰģ������
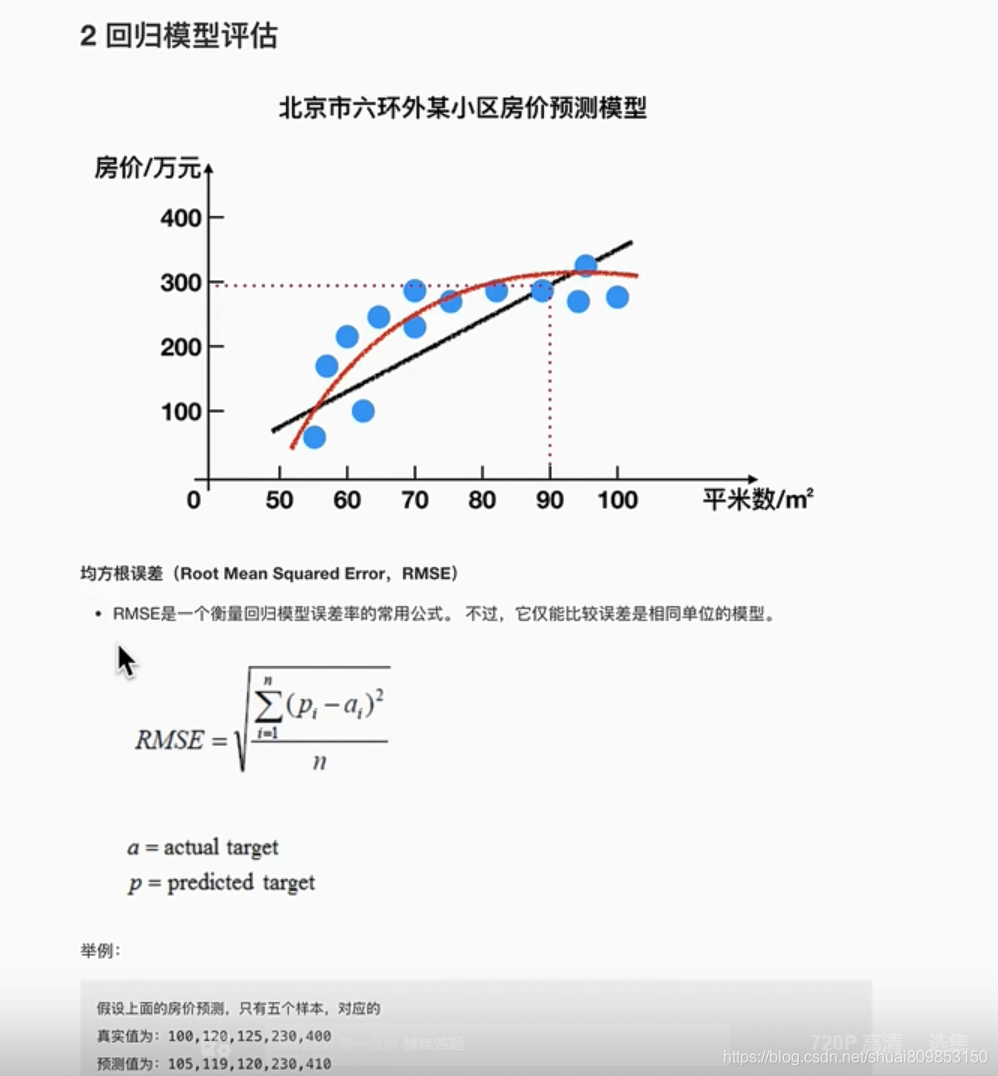

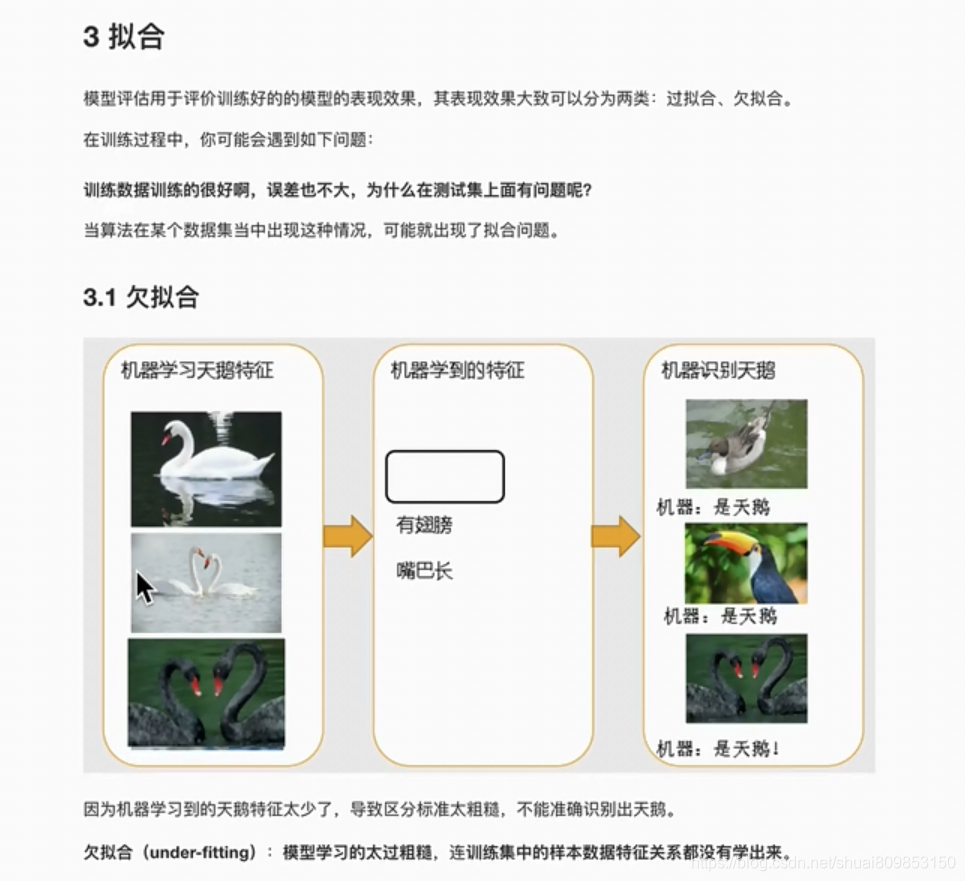
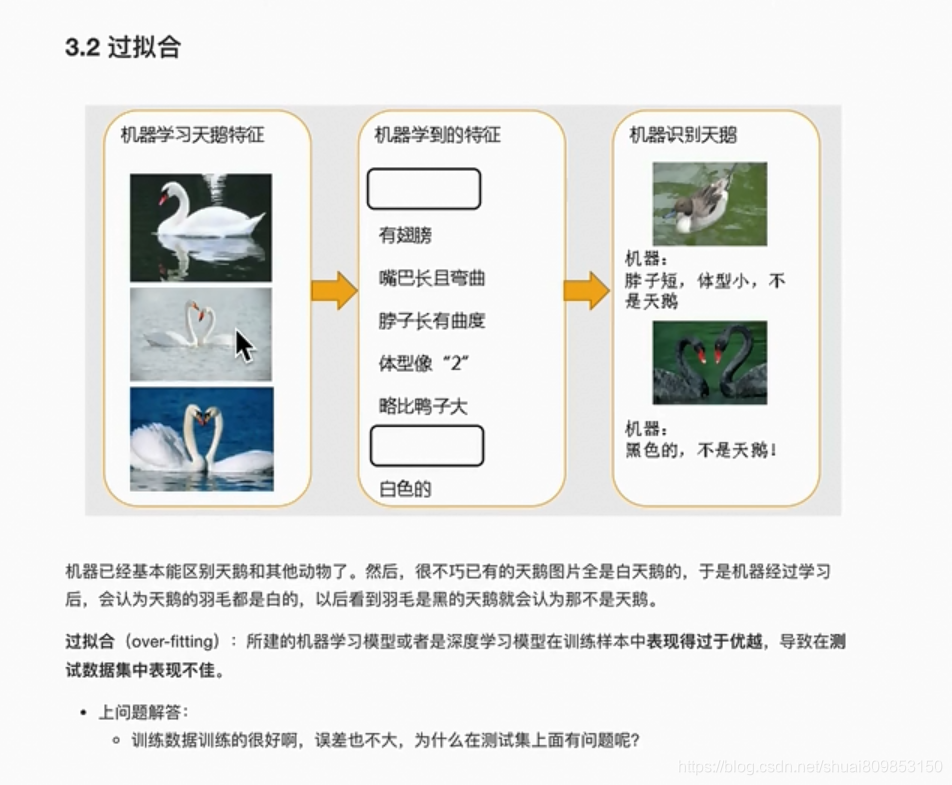

3.5.����ѧϰ���ù���
�ġ����ѧϰ
4.1.���ѧϰ�C��������
���ѧϰ�ĸ���Դ���˹���������о�,��������ز�Ķ���֪������һ�����ѧϰ�ṹ�����ѧϰͨ����ϵͲ������γɸ��ӳ���ĸ߲��ʾ������������,�Է������ݵķֲ�ʽ������ʾ���о����ѧϰ�Ķ������ڽ���ģ�����Խ��з���ѧϰ��������,��ģ�����ԵĻ�������������,����ͼ��,�������ı��ȡ�
���ѧϰ��һ��ģʽ����������ͳ��,�;����о����ݶ���,��Ҫ�漰�����:
(1)���ھ��������������ϵͳ,������������(CNN)��
(2)���ڶ����Ԫ���Ա���������,�����Ա���( Auto encoder)�Լ��������ܵ��㷺��ע��ϡ���������( Sparse Coding)��
(3)�Զ���Ա���������ķ�ʽ����Ԥѵ��,������ϼ�����Ϣ��һ���Ż�������Ȩֵ�������������(DBN)��
ͨ����㴦��,����ʼ�ġ��Ͳ㡱������ʾת��Ϊ���߲㡱������ʾ��,�á���ģ�͡�������ɸ��ӵķ����ѧϰ�����ɴ˿ɽ����ѧϰ����Ϊ���С�����ѧϰ��(feature learning)��ʾѧϰ��(representation learning)��

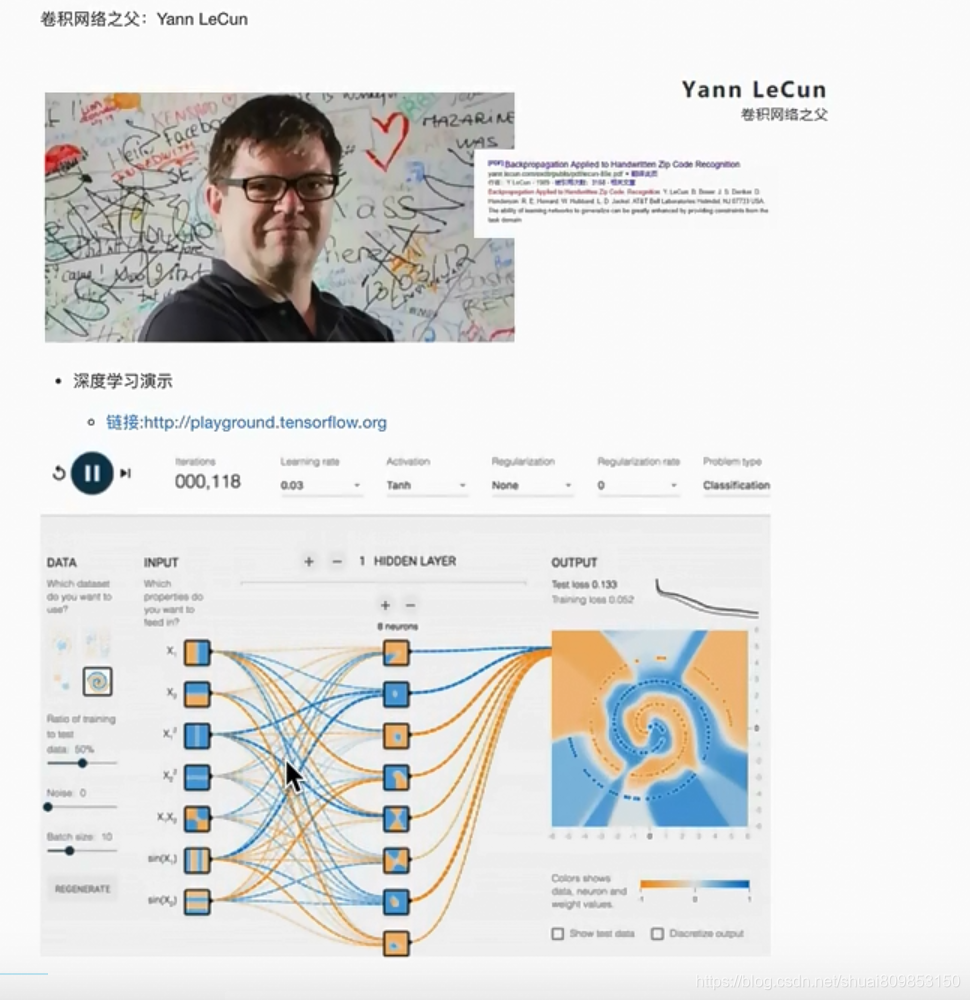
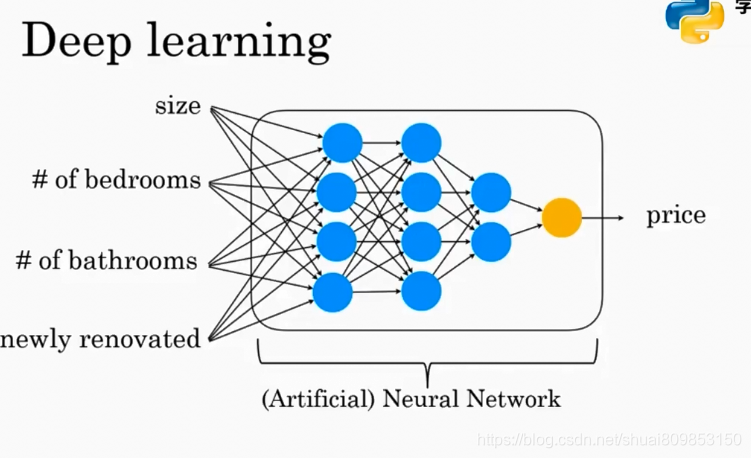
4.2.���ѧϰ���㸺������

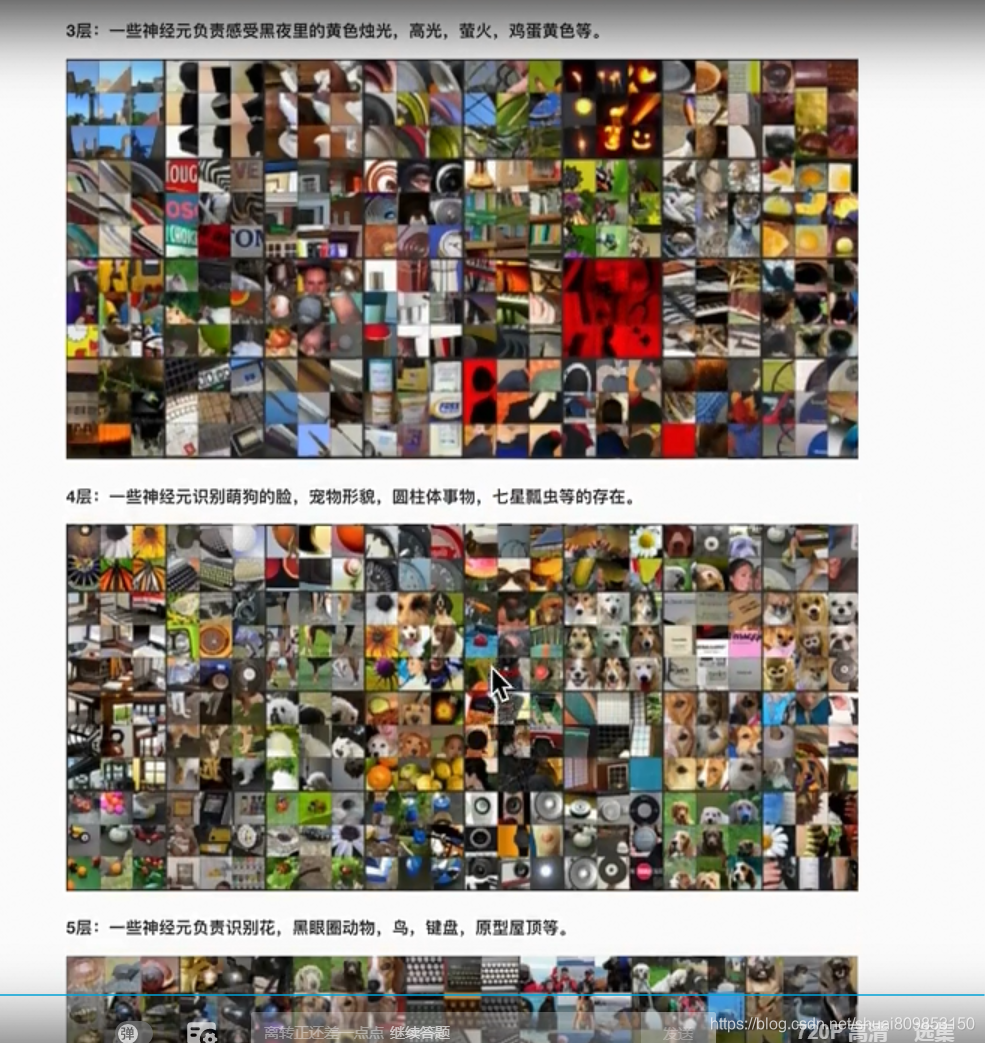
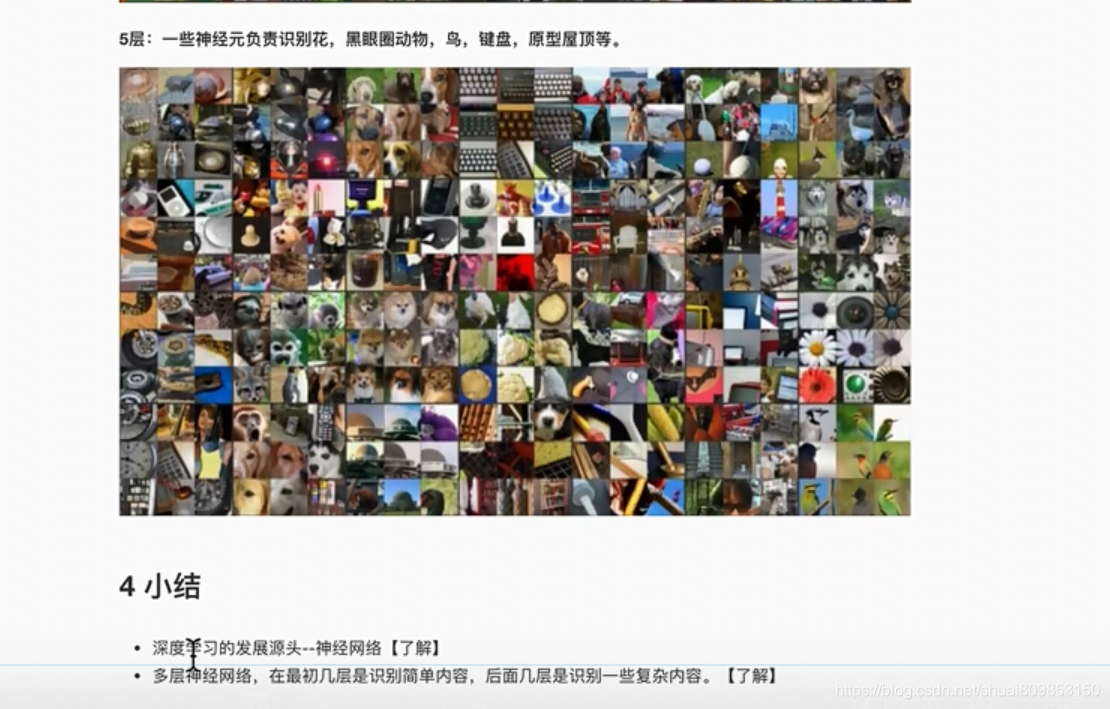
4.3.���ѧϰ����ģ��
1)����������ģ��
���ලԤѵ������֮ǰ,ѵ�����������ͨ���dz�����,������һ�������Ǿ��������硣��������
�����Ӿ�ϵͳ�Ľṹ��������������һ���������������ģ������Fukushima(D������֪���������,������Ԫ֮��ľֲ����Ӻͷֲ���֯ͼ��ת��,������ͬ��������ԪӦ����ǰһ��������IJ�ͬλ��,�õ�һ��ƽ�Ʋ���������ṹ��ʽ������,Le Cun�����ڸ�˼��Ļ�����,������ݶ���Ʋ�ѵ������������,��һЩģʽʶ�������ϵõ���Խ�����ܡ�����,���ھ����������ģʽʶ��ϵͳ����õ�ʵ��ϵͳ֮һ,��������д���ַ�ʶ�������ϱ��ֳ��Ƿ������ܡ�
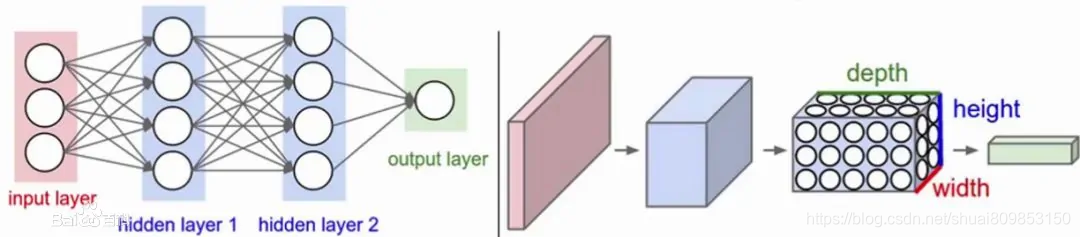
2)�����������ģ��
DBN���Խ���Ϊ��Ҷ˹��������ģ��,�ɶ��������������,����������������Գ�����,����IJ�õ�������һ����Զ����µ���������,��ײ㵥Ԫ��״̬Ϊ�ɼ���������������DBN����2F�ṹ��Ԫ��ջ���,�ṹ��Ԫͨ��ΪRBM(RestIlcted Boltzmann Machine,������������)����ջ��ÿ��RBM��Ԫ�Ŀ��Ӳ���Ԫ��������ǰһRBM��Ԫ��������Ԫ�������������ѧϰ����,������������ѵ����һ��RBM��Ԫ,�����������ѵ���ڶ���RBMģ��,��RBMģ�ͽ��ж�ջͨ�����Ӳ�������ģ�����ܡ����ලԤѵ��������,DBN�������뵽����RBM��,���붥���״̬����ײ�ĵ�Ԫ,ʵ��������ع���RBM��ΪDBN�Ľṹ��Ԫ,��ÿһ��DBN����������
3)��ջ�Ա�������ģ��
��ջ�Ա�������Ľṹ��DBN����,�����ɽṹ��Ԫ��ջ���,��֮ͬ��������ṹ��ԪΪ�Ա���ģ��( auto-en-coder)������RBM���Ա���ģ����һ�������������,��һ���Ϊ�����,�ڶ����Ϊ����㡣
4.4.���ѧϰѵ������
2006��,Hinton������ڷǼල�����Ͻ�������������һ����Ч����,�����Ϊ����:������㹹��������Ԫ,����ÿ�ζ���ѵ��һ����������;�����в�ѵ�����,ʹ��wake-sleep�㷨���е��š�
����������������Ȩ�ر�Ϊ˫���,���������Ȼ��һ������������,�����������Ϊ��ͼģ�͡����ϵ�Ȩ�����ڡ���֪��,���µ�Ȩ�����ڡ����ɡ���Ȼ��ʹ��wake-sleep�㷨�������е�Ȩ�ء�����֪�����ɴ��һ��,Ҳ���DZ�֤���ɵ�����ʾ�ܹ���������ȷ�ĸ�ԭ�ײ�Ľڵ㡣���綥���һ���ڵ��ʾ����,��ô����������ͼ��Ӧ�ü�������ڵ�,�����������������ɵ�ͼ��Ӧ���ܹ�����Ϊһ����ŵ�����ͼ��wake-sleep�㷨��Ϊ��( wake)��˯(sleep)�������֡�
wake��:��֪����,ͨ���������������ϵ�Ȩ�ز���ÿһ��ij����ʾ,����ʹ���ݶ��½��IJ�������Ȩ�ء�
sleep��:���ɹ���,ͨ�������ʾ������Ȩ��,���ɵײ��״̬,ͬʱ�IJ�����ϵ�Ȩ�ء�
���������ķǼලѧϰ
���Ǵӵײ㿪ʼ,һ��һ���������ѵ���������ޱ궨����(�б궨����Ҳ��)�ֲ�ѵ���������,��һ�����Կ�����һ���ලѵ������,��Ҳ�Ǻʹ�ͳ�������������IJ���,���Կ���������ѧϰ���̡������,�����ޱ궨����ѵ����һ��,ѵ��ʱ��ѧϰ��һ��IJ���,�����Կ����ǵõ�һ��ʹ���������������С�����������������,����ģ�������������Լ�ϡ����Լ��,ʹ�õõ���ģ���ܹ�ѧϰ�����ݱ����Ľṹ,�Ӷ��õ�����������б�ʾ����������;��ѧϰ�õ�n-l���,��n-l��������Ϊ��n�������,ѵ����n��,�ɴ˷ֱ�õ�����IJ�����
�Զ����µļලѧϰ
����ͨ������ǩ������ȥѵ��,����Զ����´���,����������������ڵ�һ���õ��ĸ��������һ���ŵ��������ģ�͵IJ���,��һ����һ���мලѵ�����̡���һ������������������ʼ����ֵ����,���ڵ�һ�����������ʼ��,����ͨ��ѧϰ�������ݵĽṹ�õ���,��������ֵ���ӽ�ȫ������,�Ӷ��ܹ�ȡ�ø��õ�Ч�����������ѧϰ������Ч���ںܴ�̶��Ϲ鹦�ڵ�һ��������ѧϰ�Ĺ��̡�
�塢�˹����ܵ�Ӧ��
�����������
https://www.bilibili.com/video/BV1G64y1r71B?from=search&seid=3984056625318733193
https://www.bilibili.com/video/BV1G64y1r71B?p=12&spm_id_from=pageDriver
https://www.bilibili.com/video/BV16g4y1z773?from=search&seid=3984056625318733193
https://www.bilibili.com/video/BV1tK4y1D7ms
https://baike.baidu.com/item/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/3729729?fr=aladdin
https://www.jiqizhixin.com/articles/a-tour-of-the-top-10-algorithms-for-machine-learning-newbies