һ������������״
1.1 �����������ı�Ҫ��
�ڵ��������������,��ȫ�����Э����Ϊ���������ṩ���ܵ�һ����ҪЭ�顣�����е�����ʵ�������Ա���������ʽ����,��������Э���װ�ɲ�ͬ��ʽ�����ݰ�֮��,���������н��д��䡣����������Э�������¼���:
- Ӧ�ò�Э��:HTTP-���ı�����Э��,�������û��ڿͻ�����Web������֮����б��Ľ�������ʽ,�ṩ��ҳͨ��;DNS-����ϵͳ,�ṩ������ת����IP��ַ��������������;FTP-�ļ�����Э��;
- ��ȫ����Э��:TLS-����㰲ȫ��(��ǰ��ΪSSL-��ȫ���ֲ�),�ṩ����ͨ��;IPsec-IP��ȫЭ��,�ṩ����㰲ȫ�Ա�֤;
- �����ʹ����Э��:IP-����Э��,���������ַ;ICMP-���������Ʊ���Э��,��������·����֮�䴫�ݿ�����Ϣ,��������������;UDP-�û����ݱ�Э��,�ṩ���ɿ��������ӵ�ʵʱ���ݴ������;TCP-�������Э��,�ṩ�ɿ����������ӵ����ݴ������
���Ĺ�ע������TLS/SSLЭ����ܵ�������������ļ�����⡣TLS(Transport Layer Security)��Ϊ����㰲ȫ��,SSL(Secure Sockets Layer)��Ϊ��ȫ�Ӳ�,SSL��TLS��ǰ��,���߶����ڰ�ȫ�����Э��,������������ϵ�еĴ�����Ӧ�ò�֮��,�����ṩ�ͻ����������֮��ļ���ͨ�š�

��ͼ��ʾ����ʹ��Wiresharkץȡ��һ���������ı���,���Ǵ���ѡȡһ��TLS������Ϣ,����ͼ�Ľ�������п��Կ���,TLSʵ���Ͼ���ͨ���ڴ����֮��������һ����ȫ�Ӳ���ʵ�ְ�ȫ���ܹ��ܵġ�

������,�Ϸ����������Ѿ�������TLS��������ͨ��google���ٶȼ������ص���ҳ���Ѿ����ģʹ����HTTPS��
- Google,��Chrome�е�HTTPS���������,2019��10��,Chrome������ҳ�����ü��ܵı����Ѿ��ﵽ��95%;
- �ٶ�,������һֱǿ����վ����HTTPS,ʹ��HTTPS����վռ��Ԥ�Ƴ���60%;
- ��
ע:HTTPS����˼��,������HTTP�Ļ�����Ӧ����TLS/SSLЭ�顣��������������һ����ҳ,����ҳ��url����������ʽ��ͷ,��˵��������ʹ�����లȫ�����Э���ṩ�ļ��ܷ���
���ͬʱ,Խ��Խ��Ķ�������Ҳ��ʼ����TLS������αװ�ɿ���������������,��ͼ�ӱܰ�ȫ��⡣��һ���������������������������,����������ľ����������������Ⱦʽ��������没�����������ȡ�Gartner��˾������Ԥ��,ֱ��2020��,��Ȼ���г���60%����ҵ����Ч����HTTPS����,�����������н������س���70%�Ķ������������,ʵ�ּ��ܶ�����������Ч����Ƿdz��б�Ҫ�ġ�
1.2 ���ܶ��������ļ�ⷽ��
���е���Լ��ܶ��������ļ�ⷽ����Ҫ��Ϊ��������:
| ��ⷽ�� | ��Ҫ˼�� | �ŵ� | ������ | �������� |
|---|---|---|---|---|
| ��ͳ��������ⷽ�� | ��Ȱ����(DPI) | ���ȷ�ȸ� | ��������˽���������㿪�������� | δ��������Ϊ�� |
| ���ڻ���ѧϰ�ͱ������ݵ�������ⷽ�� | Data omnia | ��Ч��ʶ��������� | ����ȶ����д���֤ | δ���ܡ������������� |
�����ص��ע���ڻ���ѧϰ�ͱ����������ݵ�������ⷽ��,�ڽ��ܸ÷���ǰ��Ҫ�˽����¼�������:
-
��Ȱ����(DPI, Deep Packet Inspection)����:ͨ��������������ݰ��е������������ж�����������;
-
Data omnia:����ͨ����չ����¼�����������ص����б����������ݶ���������;
-
������������:������˵,������������֮���������������ص����ݶ�������Ϊ�����������ݡ�������Է�Ϊ��������:
- �ɹ۲��Ԫ����:�������ͷ���ֶ��е�ԴĿ��IP�Ͷ˿�,�Լ������������ֽ��������ݰ����ȡ���Ϊ�������ܲ���ֻ������������ݶ�����ı�������ͳ������;
- TLS��ͷ������:����TLS����������,����ͷ���ֶ���δ�����ܵ�,����ζ�ſ���ͨ����ȡTLSͷ���ֶ��е�һЩ�������ƶ�����������;
- ����������:���������ij���������������������,����HTTP��DNS��������
���,���ڻ���ѧϰ�ͱ����������ݵ�������ⷽ���Ĺ������̿��Լ�Ҫ��������:���ȶ�ǰ���ᵽ�ļ�����������ݽ��вɼ�,Ȼ�������Щ���ݶԼ����������������з���,�������õ��������������ѧϰ����ģ��,���ڷ���ģ�����Լ��������������������������ж�����һ������Ҫ��ɵ�����ʵ���Ͼ���һ�����������⡣
��������������������
��һ������Ҫ���ڵ�һ���������۵�������������ݶԼ�������������������չ�������������������ֱ�Ϊ:
- �ɹ۲������Ԫͳ������:������ͳ�����ݡ��ֽڷֲ��Լ����鳤�Ⱥͷ��鵽��ʱ����������;
- δ���ܵ�TLSͷ����Ϣ����:�������ڿͻ��˺ͷ��������ض�TLS����;
- ��������������:����DNS��HTTP����������
����ϣ���ܹ�ͨ��������Щ����,���յõ�����һ��1*nά����������,�������뵽�����Ļ���ѧϰ�������С�

2.1 �ɹ۲������Ԫͳ������
2.1.1 ��ͳ������
- ������������ֽ��������ݰ���(����ϱ���Ϊ������������������)
- Դ�˿ں�Ŀ�Ķ˿�
- �����ܳ���ʱ��(����Ϊ��λ)
��������ֵ������,���ǿ���ֱ�ӽ�ԭ��ֵ���Ӵ��������ӵ���������֮�С�
2.1.2 �ֽڷֲ�
�ֽڷֲ���ָ���ݰ���Ч������������ÿ���ֽ�ֵ�ļ���,Ҳ���Ǽ���һ���ֽڿ���ȡ����256����ֵ���������г��ֵ�Ƶ�Ρ�ѡȡ��һ��������Ϊ���ܹ��ṩ���������ݱ��������������Ϣ,�ܶ���������ķǷ���Ϊ��������������Щ��Ϣ�С����ֽڷֲ����������ڷ������Ч�غ��е����ֽ���,���Եõ��ֽڷֲ�Ƶ��,�������Ƶõ��ֽڷֲ�����,���ս���һ������ʾΪһ��1*256ά���ֽڷֲ��������С�
2.1.3 ���鳤�Ⱥͷ��鵽����ʱ�������
�����������绷����,�ַ����ṩ�̻���Բ�ͬ��ҵ�����Ͷ��������е����ݰ���С�ͷ���Ƶ�ʽ��д���,�Դ�����û������顣������һ˼��,���ǿ��Ƕ�����������ͼ���в�ͬ������ҵ�����͵Ĺ�����Ϊʱ,�Dz���Ҳ��������ʱ���������������������ֳ�һ���IJ�����?
������������,����ʹ���������ɷ������н�ģ���ڽ��������ɷ���֮ǰ,������Ҫ���˽�һ�������ɷ�������ʲô�������ɷ�����Ҳ��������,��һ���ʱ���ĺ�����ָ,һ��������̵���һ��״̬,��Զֻ������ǰ��״̬����,��������ȥ���κ�״̬���ء����һ������������������ɷ�����,��ô��������һ�������ɷ����е�һ����
���ھ��崦������ʱ������ʱ,�����ɷ��������þ���:�������������е�ÿ��ֵӳ���һ��״̬(������һ�����һ��ӳ��,�����ֵ����ͬʱ��Ӧ��һ��״̬),ͬʱ����Щֵ֮���ʱ���ϵӳ��ɸ���״̬֮���ת����Ϊ,����Щת����Ϊ�洢��һ��״̬ת�ƾ���,�پ���һϵ�й�һ���ͱ�ƽ������,���յõ���һ��״̬ת�Ƹ������С�
���ڷ��鳤��,�����㳤����Ч�غ�(��ACK)���ش�,���ݰ����ȱ���ΪUDP��TCP��ICMP���ݰ���Ч���صĴ�С,������ݰ��IJ�������������֮һ,��������ΪIP���ݰ��Ĵ�С������䵥ԪMTUһ��Ϊ1500�ֽ�,�������Э�����ݰ�����Ч��������Ϊ:TCP - (0, 1460B], UDP/ICMP - (0, 1472B], IP - (0, 1480B]�����ڷ��鵽����ʱ��,��ֱ���Ϊ���뼶��
������������,�����ǽ����鳤�����кͷ��鵽����ʱ�����е�ֵ�ֱ���ɢ��Ϊ10����ͬ��С�ġ����ӡ�,��ʾ10����ͬ��״̬��
- ��������:�������ɷ�����10������,ÿ������150�ֽ�
- ʱ������:�������ɷ�����10������,ÿ������50ms
Ȼ����ת�ƾ���A,����ÿһ��A[i,j]��ʾ��i�͵�j������֮���ת�����������,�Ծ���A���н��й�һ���õ�ת�Ƹ��ʾ���,�ٽ��б�ƽ�������õ�����1*100ά��״̬ת�Ƹ�������,�����յ������ɷ����������������������������ѧϰ�㷨��������
2.2 δ���ܵ�TLSͷ����Ϣ����
2.2.1 TLS��
TLS���ڴ�֮ǰ��SSL���ǰ�ȫ�����Э��,��λ�ڴ�����Ӧ�ò�֮��,
����������ͨ��Ӧ�ó���֮���ṩ��ȫͨ��,��֤���ݵ������Ժͱ����ԡ�TLSЭ���Զ�����������Э��ͼ�¼Э�鹲������Э����ɡ�����,TLS����Э������ͨ�ſͻ��˺ͷ�����֮��Э�̰�ȫ����,�Խ�����һ����״̬���ӽ������ݴ��䡣ͨ������Э�̹���,ͨ��˫����Ҫȷ��ʹ�õ�Э��汾�������㷨��֤��ͻỰ��Կ����Ϣ��
����δ���ܵ�TLSͷ����Ϣ����,������Ҫ��עTLS����Э���е���Ϣ����ΪTLS����Э���������ص�:һ��TLS��Ȼ����������,����û�м������ֹ���;������Э��İ汾���¹�����,���������ֲ����������й��ı�,�����ζ�����ǿ���ͨ������TLS����Э���е�һЩ���������������Խ��к������Ʋ⡣
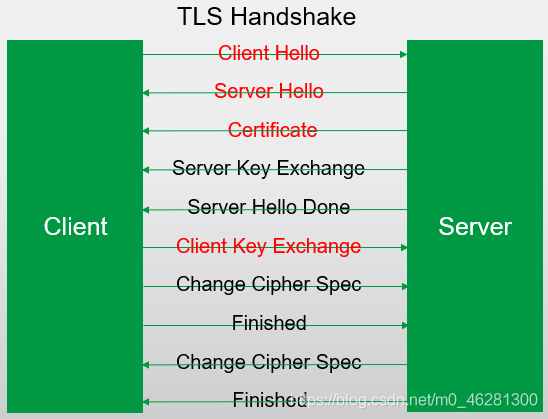
��ͼ��ʾ����TLS v1.2�����һ�����ֹ��̡����а���һЩ�ؼ�����Ϣ��:
-
�ͻ��˷���Client Hello��Ϣ,���Դ��л�ȡ���ͻ����ṩ�IJ�����Ϣ,����:
- �г����������б�(Cipher Suites)
- ��Կ�����㷨�������㷨
- ������֤��Ϣ��(MAC)�㷨
- ֧�ֵ���չ�б�(Extensions):�ṩ����ܻ��趨
- �г����������б�(Cipher Suites)
-
����������Server Hello��Ϣ,���Դ��л�ȡ�������������IJ�����Ϣ,����ѡ������������TLS��չ��
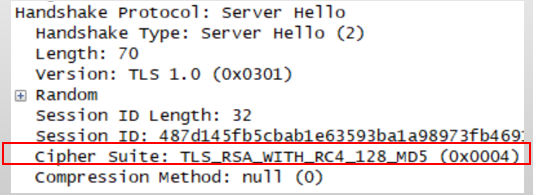
��ͼ��һ���������е�Server Hello��Ϣ����,���Դ��п���������ѡ����������,����ÿ������������һ����֮��Ӧ��ʮ��������ֵ��ͼ��Cipher Suite�ֶα���ĺ�����:����TLSЭ��,��Կ�����㷨ѡ��RSA,�����㷨ѡ��RC4(��Կ����Ϊ128λ),��ϣ�㷨ѡ��MD5,�����������Ӧ��ֵΪ0x0004��
-
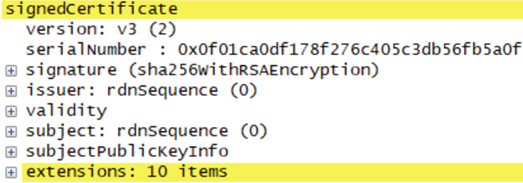
����������Certificate��Ϣ,���к��з�����ǩ����֤����Ϣ������ͼ��ʾ,������֤����Ϣ����ʾ����Ϣ���е�SignedCertificate�ֶ���,����֤��ǩ���㷨��ǩ��������֤����Ч�ڡ�֤������ȡ�
-
��Կ������Ϣ,���Դ�Client Key Exchange��Ϣ�л�ȡ�����������趨����Կ�����㷨��һЩ������
���,�ھ����������ȡ������,���ǿ��Դӿͻ��˺ͷ����������Ƕ���չ����
2.2.2 ���ڿͻ��˵��ض�TLS����
ͨ��ͳ�Ʒ���,���ǿ��Է��ֻ��ڿͻ��˵��������������������Ͷ��������д��������ԵIJ��졣��Щ����Ϊ:
- �ͻ�������Կ�����㷨��ѡ�õĹ�Կ����:��Client Key Exchange��Ϣ���ռ���,��ʾΪ��������ֵ
- �ͻ����г����������б�:��Client Hello��Ϣ���ռ�,ȡ��ʮ�����ƴ�������ض����ȵĶ���������
- �ͻ���֧�ֵ���չ�б�:���������б�����
��ͼΪ�������������ͳ�Ʒ���ͼ��

ע:ͼ����ɫ��ʾ��������,��ɫ��ʾ��������,�������ʾ�������IJ�ͬȡֵ,�������ʾ����ռ�İٷֱȡ�
����,��Կ���ȿ���ֱ������ֵ��ʽ��ʾ,����������TLS��չ��ֱ���һ����������������ʽ�洢,�����е�1��0��ʾ��ǰ���������Ƿ���ڸ�λ������������������TLS��չ��
2.2.3 ���ڷ��������ض�TLS����
ͨ��ͳ�Ʒ���,���ǿ��Է��ֻ��ڷ��������������������������Ͷ��������д��������ԵIJ��졣��Щ����Ϊ:
- ������ѡ����������:��Server Hello��Ϣ���ռ�
- ������ѡ����TLS��չ:������������
- ������ǩ����֤����Ϣ:��Certificate��Ϣ���ռ�,����֤���������SAN������������Ч�����Լ��Ƿ�����ǩ��֤��
ע:SAN��ָ���ⱸ������,��������֤�������ȱʧ��Ϣ;��������������ʹ����ǩ��֤���TLS��������Ƶ�ʱ��������ݴ�Լ�߳�һ����������
��ͼΪ�������������ͳ�Ʒ���ͼ��

����,ѡ����TLS��չ�б�ͬ�����Բ��ö�����������������ʾ��ʽ����ʾ,������������ֵ����������ֱ�����ӵ���������֮�С�
2.3 ��������������
2.3.1 DNS��������
DNS����������ָ����Ŀ��IP��ַ��TLS��ص�DNS��Ӧ,���ṩ������ʹ�õĵ�ַ,�Լ������ƹ�����TTL,ͬʱ�ܹ�����������п���ȱʧ��һЩ��Ϣ������,DNS��Ӧ�������ṩ��Ŀ��IP�������Ķ�Ӧ��ϵ,����ǩ���ĽǶ�����,DNS�ṩ�����Ķ�̬���ǵ�����������IP��ַ��,��������Ϣ�ܹ��ṩһ��ǿ��ĺ���������(��¼��Щ�Ѿ����Ϊ����������������ڷ�����Щ����)��
��������˼��,�������ȶ�DNS����������������ͳ�Ʒ���,������������������������Ͷ��������д��������ԵIJ���:
- ��������
- DNS��Ӧ���ص�IP��ַ��
- DNS TTLֵ:һ������������¼��DNS�������ϵĻ���ʱ��(32�����TTLֵ���б���һ����������ѡ��)
- ������Alexa������:����������վ�����ȶȵ�һ������ָ��
ע:������Alexa������ʵ������һ���������������Ļ���,ѡȡ��һ������ԭ���ǿ��ǵ�������������������������ȶ������DZȽϵ͵ġ�
��ͼΪ�������������ͳ�Ʒ���ͼ��
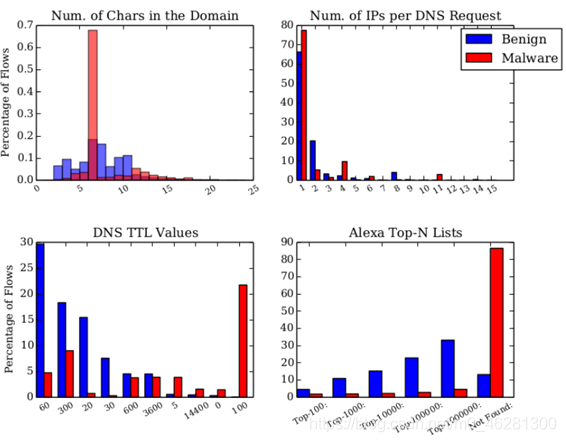
����ǰ������ֵ������,���账������ֱ�����ӵ�����������,��������Alexa��������������ͨ��һ��1*6ά�Ķ�������������ʾ,��6��ά�ȷֱ��ʾ�����Ƿ���Alexa���ǰ100/1000/10000/100000/1000000�Լ����ڰ��е����,Ȼ����һ������Ϊÿ������ѡ����Ӧ�����,������һ��ͽ��������ڵ�λ�ñ��Ϊ1��
2.3.2 HTTP��������
HTTP����������ָ��TLS�� 5 min����������ͬԴIP��ַ����������HTTP��������������������HTTPͷ����ijЩ�ֶ�(����content-type, server��)������һЩ����,��˵��HTTP�ֶ��ܹ��ܺõ�ָʾһЩ������
����������˼��,����ͬ��ѡȡ�������ܹ���ӳ���������Ͷ�������֮������Ե�HTTP������������:
- ���������HTTP�ֶε�����:��һ�������Ʊ���������������ʾ���й۲쵽��HTTPͷ,����κ�HTTP�������ض��ı�ͷֵ,����������HTTP�����,����������Ϊ1
- HTTP�ض��ֶ�(Content-Type��Server��Code)��ȡֵ
��ͼΪ�������������ͳ�Ʒ���ͼ��
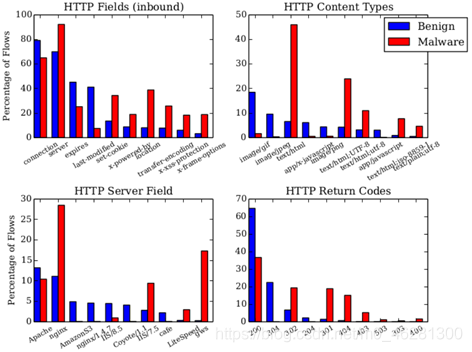
������������������ͬ����ȡ��������������ʽ���Ա�ʾ��
����,���Ǿ��Ѿ�����˼�������������������������,���յõ�������һ��1*nά��������������Ҫ˵������,�����������������Ƕ�������,���Ƕ�����ͨ��ǰ��������������̵õ�������һ��������������n�ľ���ȡֵ��Ҫȡ����ʵ��ʹ�õļ����������ݸ�ʽ��
����ʵ��������
��һ���ֽ���һ��������ʵ���ݼ��ļ�����������ʵ�顣
3.1 ���ݼ�
���ʵ����õ����ݼ���Ϊ�ڰ�������������,����ʵ�����ݶ����ھ���TLS���������Ժ��������������������ع��˵õ�����ȱʧ���ݡ�
- �����������������ݼ�
- 13542��ͬʱ����DNS��HTTP�����ĵĶ���TLS��;
- ��2016��1�µ�4��,����ҵɳ�价�����ռ�;
- ����һ������,�û������ύ���ɵĿ�ִ���ļ�,ÿ���ύ����Ʒ������5 min,����ɻ����ռ����洢ÿ���������������ݰ�����
- �����������������ݼ�
- 42927��ͬʱ����DNS��HTTP�����ĵ�����TLS��;
- 2016��4�µ�5����,�ڴ�����ҵ�������ռ���
3.2 ����ģ��
ʵ��ʹ�����ع������,�����з���������L1���ͷ�(L1-logistic)��
L1-logistic�ع�ģ��ʵ���Ͼ���һ��ʹ����sigmoid������Ϊ��ϵ�����Ĺ�������ģ�͡���L1������Ҫͨ������ʧ����������L1������,�Ӷ�����ϡ��ģ�����ﵽ��ֹ����ϵ�Ŀ�ġ��о��������ַ������dz���Ч,���Ҷ�������������������ַdz��á�
������������ x x x,������ y y y,�������Իع�ģ��Ԥ��ֵ z = h ( x ) = �� T x + b z=h(x)=\omega^Tx+b z=h(x)=��Tx+b,��logistic�ع�ģ������: y = 1 1 + e ? z y = \frac{1}{1+e^{-z}} y=1+e?z1?
�ڴ˻�����,��L1������ʧ����Ϊ: J ( �� ) = ? [ 1 m �� i = 0 m y ( i ) log ? h ( x ( i ) ) + ( 1 ? y ( i ) ) log ? ( 1 ? h ( x ( i ) ) ) ] + �� �� �� �� 1 J(\omega) = -[\frac{1}{m}\sum_{i=0}^{m}y^{(i)}\log{h(x^{(i)})}+(1-y^{(i)})\log{(1-h(x^{(i)}))}]+\lambda\Vert\omega\Vert_1 J(��)=?[m1?i=0��m?y(i)logh(x(i))+(1?y(i))log(1?h(x(i)))]+��������1?
3.3 ʵ�����
�ڱ���ʵ���ṩ�����ݼ���,���õڶ����ֽ��ܵļ�������������������,�õ�һ��800ά���ҵ���������,�������������������ᱻ��һ��Ϊ���ֵ�͵�λ�������ʽ��ͬʱ,���з�������ʹ����ʮ�۽�����֤:ͨ������10��9:1��ѵ��������֤��,���10�β�ͬ�ķ�����,���ȡ10�η�������ƽ��ָ�����������
3.4 �������
ʵ�����Բ�ͬ��������Ϻ�����ȷ������ά����չʾ,����ͼ��ʾ������ȷ����ָ������ȷ�������������������ռ�ı��������Կ���,�ӵ���ʹ��δ���ܵ�TLSͷ����Ϣ����,������ɹ۲������Ԫͳ������,�ٵ����ռ�����������������,�������������ȷ�����ڲ��������ġ�

ʵ��������,��ʹ�ü�������δ���ܵ�TLSͷ����Ϣ,�ܹ�ʵ��96.335%���ܾ���;ʹ�����Լ���������SPLT+BD+TLS����Ϣ,�ܹ�ʵ��99.933%���ܾ���;ʹ��������������б�������,�����ܹ�ʵ��99.993%���ܾ��ȡ�
�ġ��ܽ���չ��
4.1 �ܽ�
���Ľ��ܵĻ��ڻ���ѧϰ�ͱ����������ݵļ��ܶ���������ⷽ��,���ĺ������ڻ���data omnia˼���������ȡ:ͨ���ռ��������������ص����б�����������,���ֲ���ȡ���ںڰ������������Բ��������(����������:�ɹ۲������Ԫͳ��������δ���ܵ�TLSͷ����Ϣ��������������������),���������ڼ��������ķ�������
4.2 չ��
���ڻ��ڻ���ѧϰ�ͱ����������ݵļ��ܶ���������ⷽ���ĺ����о�,�������¼���չ��:
- ����ʵ����¼��������о���������ֶ���Ϣȱʧ������,������TLS�Ự�ָ��������,֤�齫�����ڡ������Ҫͨ��ʵ��ȥ��֤��ͬ������������ʽ��������ϻ�ﵽʲô���ķ���Ч��;
- ʵ�����õ��ĺ��������ݶ�����ɳ���вɼ��Ķ�������ͨ������ͨ�Ų���������,��ֻ�Ǽ��ܶ��������е�һ�ֱ�����ʽ,����ǰ���������������һ����������еı��ֺܿ����Ǹ߶Ƚ��Ƶ�,��Ҳ������ʵ���������շ��������ȷ�ȴﵽ��99.99%���ϵ�ԭ�������ʹ���Ǻ���ȥ��ע���ܶ�������������������ʽ(һ�Ǽ���ͨ���еĶ��������,��CC����;���Ƕ����Ƿ�����Ӧ�õ�ͨ������,��Ƿ�VPN),ͨ��ʵ��ȥ��֤ʹ�õ�ǰ������������ʽ�ļ����������з����Ƿ���Ȼ�ܹ��ﵽ�Ϻõ�Ч��;
- �������Գ��Խ��ж��ֻ���ѧϰ����ģ��(�������ɭ�֡�XGBoost��)�ĶԱ�����֤,ȥ̽����һ���������Ч���Ŀ��ܡ�
�����
[1] Anderson B, McGrew D. Identifying encrypted malware traffic with contextual flow data[C]//Proceedings of the 2016 ACM workshop on artificial intelligence and security. 2016: 35-46.
[2] Korczy��ski M, Duda A. Markov chain fingerprinting to classify encrypted traffic[C]//IEEE INFOCOM 2014-IEEE Conference on Computer Communications. IEEE, 2014: 781-789.
[3] Anderson B, Paul S, McGrew D. Deciphering malware��s use of TLS (without decryption)[J]. Journal of Computer Virology and Hacking Techniques, 2018, 14(3): 195-211.