深入浅出强化学习编程实战(第7章) -- 策略梯度方法2算法实战
一、回顾
策略梯度基本思想详见:我的上一篇博客
这篇博客提到策略梯度的基本思想:
1、参数化策略
2、找到目标函数
3、通过优化目标函数找到最优策略
最终得到的目标函数的梯度为:
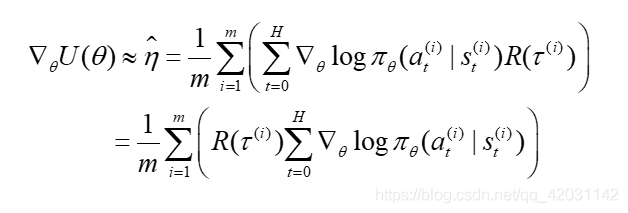
二、REINFORCE算法
本篇博客的目标是介绍一个利用该梯度公式来找到最优策略的一个算法:REINFORCE算法
?2.1? 梯度变形
观察上面梯度公式,内层累加时,每个t对应的
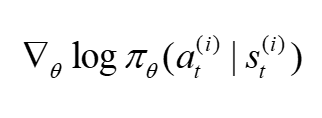
?需要乘以整条轨迹的累计奖励,然而当前t时刻的动作其实和过去的奖励是没有关系的,所以该公式可以改成:
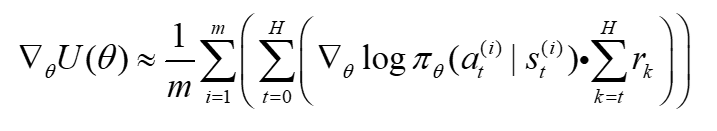
这相当于引入了因果性。同时另一个好处是可以减小方差。
2.2? 算法详情

分析:如图中算法所示,利用给定策略采样一条轨迹,?对每个时刻对应的
都乘以t时刻以后可以得到的奖励和,这里用Vt表示。
将第二层的for循环全部累加,可以得到
 ??
??
????????该算法和?2.1节的变形后的梯度公式是一样的。不同的是,这里只采样一条轨迹,即公式中的m=1。
所以引出了本书第二个算法。基于REINFORCE的批策略梯度算法
2.3??基于REINFORCE的批策略梯度算法
算法详见课本,区别在于从采样一条轨迹变成了采样N条轨迹,使得其完全符合变形后的梯度公式
3、算法实现
3.1 离散动作环境下的实现
离散动作的实现依赖于softmax函数