一、主要思想
基于先前我们所拥有的传统机器学习的分类器或者回归器,我们在第一层输出一系列预测结果。再基于这一系列预测结果,作为第二层模型的context输入,再最后输出一个集成的预测结果。
二、Blending
数据集T
【步骤】总结来说:训练集用来训练第一层模型,验证集用来调参,测试集用来度量模型效果
(1)将数据划分为训练集和测试集(test_set),再将训练集二次划分为训练集(train_set)和验证集(val_set)
(2)创建第一层的多个模型,这些模型可以同质化也可以异质化
(3)使用train_set训练(2)中的多个模型,然后用训练好的模型对val_set,test_set做预测得到val_predict,test_predict
(4)创建第二层模型,使用val_predict作为训练集训练第二层的模型
(5)使用第二层训练好的模型对第二层测试集test_predict进行预测,最后得到的cost即为整个预测集的误差
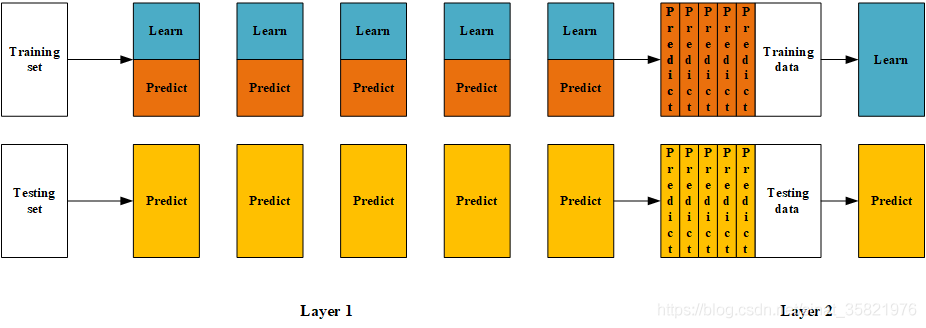
?(图片转自https://blog.csdn.net/sinat_35821976/article/details/83622594)
三、Stacking
【Blending的缺点】Blending在模型搭建过程中,第二层集成模型的训练只用到了validation set,这是对数据的浪费
【步骤】
(1)基于数据集T生成训练集train_set和测试集test_set。
(2)在第一层中,对train_set做K折交叉验证:每次验证都相当于用(K-1)/K的train_set训练一个模型,再用拟合好的模型对1/K的train_set做预测(得到1/K*#(train_set)个预测label),同时也对test_set做预测得到#(test_set)个预测label
(3)对(2)得到的K个1/K部分的train_set预测,我们将这一系列预测值合并为一列向量,这其实就是第一层中的一个基模型在K折交叉验证中对每个样本的一次预测,记为;同时对(2)中对test_set做预测得到的K*#(test_set)个预测label,做平均或加权平均,形成
(4)上述(3)是一个基模型在第一层所输出的结果,当我们对N个基模型做完之后会得到。我们最终第二层集成模型的拟合是以A整体为train_set,即用A1至AN作为N个context预测train_set样本对应的ground truth;同时以B整体为test_set。

?
?(图片转自Datawhale)
四、优缺点对比
Blending的优点:
- 比stacking更加简单(Blending的stacker feature直接由validation set和test set产生,不涉及K折交叉验证)
Blending的缺点:
- 使用hold-out作为测试集,而非cv,在训练stacker模型上用的数据量相对Stacking来说更少
- blending更容易过拟合
- Stacking使用多次CV更加robust