[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (20) �� Elastic Training Operator
����Ŀ¼
0x00 ժҪ
Horovod ��һ����� AllReduce �ķֲ�ʽѵ����ܡ�ƾ����� TensorFlow��PyTorch ���������ѧϰ��ܵ�֧��,�Լ�ͨ���Ż����ص�,Horovod ���㷺Ӧ�������ݲ��е�ѵ���С�
������ horovod on k8s �����һƪ,���� MPI-Operator ���ܱ���θĽ�,��Ҫ���Ǹ��� Elastic Training Operator ���� �ŶӵIJ���������ѧϰԴ�롣���Ա����Դ���Դ��Ϊ����
��ϵ������������������:
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� Horovod �� (1) ����֪ʶ
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (2) �� ��ʹ���߽Ƕ�����
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (3) �� Horovodrun��������ʲô
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (4) �� ������� & Driver
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (5) �� �ںϿ��
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (6) �� ��̨�̼ܹ߳�
[\Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (7) �� DistributedOptimizer
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (8) �� on spark
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (9) �� ���� on spark
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (10) �� run on spark
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (11) �� on spark �� GLOO ����
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (12) �� ����ѵ������ܹ�
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (13) �� ����ѵ��֮ Driver
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (14) �� ��η��ֽڵ����?
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (15) �� �㲥 & ֪ͨ
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (16) �� ����ѵ��֮Worker��������
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (17) �� ����ѵ��֮�ݴ�
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (18) �� kubeflow tf-operator
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (19) �� kubeflow MPI-operator
0x01 ����֪ʶ
0x01, 0x02 ���ھ������� Elastic Training Operator �ŶӲ�������,���������úܸ�����
1.1 ���������
Kubernetes ���Ƽ����ṩ�����Ժ�������,���ǿ���ͨ�� cluster-AutoScaler �����Ϊѵ���������õ��Բ���,���� Kubernetes �ĵ�������,���贴��,���� GPU �豸��ת��
����������ģʽ���ѵ�������������������в���:
- ��֧���ݴ�,������ Worker �����豸ԭ��ʧ��,����������Ҫֹͣ������
- ѵ������һ��ʱ��ϳ�,ռ��������,����ȱ�ٵ�������������Դ����ʱ,����������ֹ,������Ϊ����ҵ���ڳ���Դ��
- ѵ������ʱ��ϳ�,��֧�� worker ��̬����, ����ȫ��ʹ����ռʵ��,������������Լ۱�
��θ�ѵ�������赯������,������Լ۱ȵĹؼ�·�������� horovod �ȷֲ�ʽ�����֧���� Elastic Training,������ѵ��������Ҳ��������һ��ѵ��������ִ�еĹ����ж�̬�����ݻ�������ѵ�� worker, �Ӳ�������ѵ��������жϡ���Ҫ�ڴ�����������������,�ɲο�:https://horovod.readthedocs.io/en/stable/elastic_include.html��
1.2 mpi-operator ��ȱ��
�� mpi-operator ��,����ѵ���� Worker ������Ϊ��̬��Դ��ƺ�ά��,֧�ֵ���ѵ��ģʽ��,�����������������,ͬʱҲ����ά���������ս,����:
- ����ͨ�� horovod �ṩ�� horovordrun ��Ϊ���,horovod �� launcher ͨ�� ssh ��½ worker,��Ҫ��ͨ launcher �� worker ֮��ĵ�½������
- ������㵯�Ե� Elastic Driver ģ��ͨ��ָ�� discover_host �ű���ȡ���� worker ������Ϣ,�Ӷ������ֹͣ worker ʵ������ worker �仯ʱ,����Ҫ���� discover_host �ű��ķ���ֵ��
- ����ռ��۸����ȳ�����,��ʱ��Ҫָ�� worker ����,K8s ԭ���ı���Ԫ�� deployment,statefulset ������ָ�����ݵij�����
�����������,������ƿ����� et-operator,�ṩ TrainingJob CRD ����ѵ������, ScaleOut �� ScaleIn CRD �������ݺ����ݲ���, ͨ�����ǵ����,ʹ���ǵ�ѵ����������е��ԡ������������Դ,��ӭ��������������²ۡ�
��Դ������ַ:https://github.com/AliyunContainerService/et-operator
0x02 ����ܹ�
TrainingJob Controller ��Ҫ�����¹���:
- ά�� TrainingJob �Ĵ���/ɾ����������,�Լ�����Դ������
- ִ�������ݲ�����
- �ݴ�,�� worker ������,�����µ� worker ���뵽ѵ���С�
2.1 ��Դ����
TrainingJob ����Դ����˳������:
- ������ͨ ssh �������Կ��, ���� secret��
- ���� workers,���� service �� pod,���� secret ��Կ��
- ���� configmap, ���� discover_host �ű� , hostfile �ļ���
- ���� launcher,���� configmap������ hostfile �������������˹�ϵ��,���� hostfile ����ͨ�� initcontainer �� configmap ����������Ŀ¼��
TrainingJob �����Դ:

2.2 ��ɫ
TrainingJob CR �����÷�Ϊ Lanucher �� Worker���� Launcher ��ָ������ľ��������ִ��, Ĭ�� et-operator ����� worker �������,����һ�� hostfile �ļ��� discover_host �ű�,discover_host �ű����ص� Launcher �� /etc/edl/discover_hosts.sh �ļ�, ����ڽű��� horovodrun ִ����ͨ�� --host-discovery-script ����ָ������ Worker ������ָ�� worker �ľ���� GPU ռ�� ,������ͨ�� maxReplicas / minReplicas ָ�� workers �ĸ�����������Χ��

2.3 ����������
����������ͼ����:
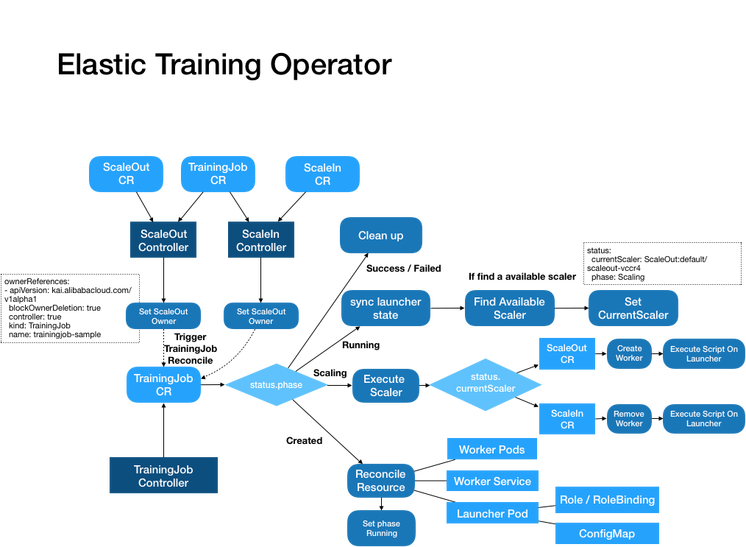
0x03 ���
��ʵ,ѧϰ ETO ��Ҫ����ѧϰ������ݺ����ݡ�����Ϊ��ѧϰ���,���ǻ�����Ҫ����һ�³�������
����Ϥ K8S ��ͬѧ˳��Ҳһ���� CRD ���ʹ�á�
3.1 ����
��ڴ����� main.go/main ����,����ڿ��Կ���,
- ������ Controller.Manager��
- ������� Manager,���������� Reconciler :TrainingJobReconciler,ScaleInReconciler,ScaleOutReconciler��
- Ȼ������ Manager;
func main() {
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
MetricsBindAddress: metricsAddr,
LeaderElection: enableLeaderElection,
Port: 9443,
})
const jobPollInterval = "5s"
if err = controllers.NewReconciler(mgr, parseDurationOrPanic(jobPollInterval)).SetupWithManager(mgr); err != nil {
os.Exit(1)
}
if err = controllers.NewScaleOutReconciler(mgr, parseDurationOrPanic(jobPollInterval)).SetupWithManager(mgr); err != nil {
os.Exit(1)
}
if err = controllers.NewScaleInReconciler(mgr, parseDurationOrPanic(jobPollInterval)).SetupWithManager(mgr); err != nil {
os.Exit(1)
}
if err := mgr.Start(ctrl.SetupSignalHandler()); err != nil {
os.Exit(1)
}
}
3.2 ����
��������þ��ǽ�������Ϣ����Ӧ����,���������Ӧ��Щ CR��
-
���� TrainingJob ��,et-operator ͬʱ֧�� ScaleOut �� ScaleIn ���� CRD,�·�ѵ���������ݺ����ݲ�����
-
���·�һ�� ScaleOut CR,ScaleOutController ���� Reconcile, ���﹤���ܼ�,���� ScaleOut CR �е� Selector �ֶ�,�ҵ� Scaler ��Ӧ�� TrainingJob,���õ� CR �� OwnerReferences �ϡ�
-
TrainingJobController �м��������� TrainingJob �� ScaleOut CR �и���, ���� TrainingJob �� Reconcile,�������� TrainingJob �� OwnerReference ָ��� ScaleIn �� ScaleOut, ���ݴ���ʱ���״̬ʱ�����ִ�е����ݻ������ݡ�
-
ִ������ʱ,����ͨ�� ScaleIn CR �е� spec.toDelete.count �� spec.toDelete.podNames �ֶ�ָ�����ݵ� worker��ͨ�� count �������ݵ�����,��ͨ�� index �����ɸߵ������� Worker��
func (r *ScaleInReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&kaiv1alpha1.ScaleIn{}).
Complete(r)
}
func (r *ScaleOutReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&kaiv1alpha1.ScaleOut{}).
Complete(r)
}
func (r *TrainingJobReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&kaiv1alpha1.TrainingJob{}).
Owns(&kaiv1alpha1.ScaleIn{}).
Owns(&kaiv1alpha1.ScaleOut{}).
Owns(&corev1.Pod{}).
Owns(&corev1.Service{}).
Owns(&corev1.ConfigMap{}).
Owns(&corev1.Secret{}).
// Ignore status-only and metadata-only updates
//WithEventFilter(predicate.GenerationChangedPredicate{}).
Complete(r)
}
0x04 TrainingJobReconciler
˳�Ŵ�������һ��,Ѱ�������˼�뾫֮����
4.1 Reconcile
k8s operator ��reconcile���� �����þ��Dz��ϵ�watch,����Դ�仯ʱ �ͻᴥ��reconcile����,�������ж��ٴεı仯�ͻ�ִ�ж��ٴε�reconcile������
������Ϣ����ʱ��,Reconcile ������õ����á�
func (r *TrainingJobReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
// Fetch latest training job instance.
sharedTrainingJob := &kaiv1alpha1.TrainingJob{}
err := r.Get(context.Background(), req.NamespacedName, sharedTrainingJob)
trainingJob := sharedTrainingJob.DeepCopy()
// Check reconcile is required.
// No need to do reconcile or job has been deleted.
r.Scheme.Default(trainingJob)
return r.ReconcileJobs(trainingJob)
}
4.2 ReconcileJobs
��Ϊ��Ϣ��״̬�� ����,���������� initializeJob,���ҽ��� reconcileResource��
func (r *TrainingJobReconciler) ReconcileJobs(job *kaiv1alpha1.TrainingJob) (result reconcile.Result, err error) {
oldJobStatus := job.Status.DeepCopy()
defer func() {
latestJob := &kaiv1alpha1.TrainingJob{}
err := r.Get(context.Background(), types.NamespacedName{
Name: job.Name,
Namespace: job.Namespace,
}, latestJob)
if err == nil {
if latestJob.ObjectMeta.ResourceVersion != job.ObjectMeta.ResourceVersion {
latestJob.Status = job.Status
job = latestJob
}
}
r.updateObjectStatus(job, oldJobStatus)
}()
switch job.Status.Phase {
case commonv1.JobSucceeded, commonv1.JobFailed:
err = r.cleanup(job)
case "", commonv1.JobCreated: // ���״̬Ϊ�� ���� JobCreated,���ʼ��
r.initializeJob(job)
err = r.reconcileResource(job)
case commonv1.JobRunning:
err = r.reconcileJobRunning(job)
case commonv1.Scaling:
err = r.executeScaling(job)
}
if err != nil {
if IsRequeueError(err) {
return RequeueAfterInterval(r.PollInterval, nil)
}
return RequeueAfterInterval(r.PollInterval, err)
}
return NoRequeue()
}
4.3 reconcileResource
reconcileResource ��ʵ���ǵ��� doSteps,����һ��״̬��������ʼ����
func (r *TrainingJobReconciler) reconcileResource(job *kaiv1alpha1.TrainingJob) error {
steps := r.newSteps()
err := r.doSteps(job, steps)
return err
}
4.4 doSteps
newSteps ������һ����״̬��,��һ����ʼ������,��������ִ��,doSteps �����״̬���в�ͬ�ķ�֧������
�м�����Ҫ˵��:
- Created ֮��ļ���״̬,Ӧ����: WorkersCreated ��> WorkersReady ----> LauncherCreated ��> JobRunning��
- ������º�״̬,����Ӧ action ���֮��Ӧ�ôﵽ��״̬��
- �� for ѭ��֮��,�����ǰ Job �Ѿ��ﵽ��ij��״̬,����������,ֱ��ijһ��δ��״̬,��ȥִ�ж�Ӧ��action������������˵,��� WorkersCreated ��ִ�е� JobRunning��
- ��ij��״̬��Ӧ�� Action ��,ִ�����֮��,������ Job Ϊ��� ���״̬��
��������:
func (r *TrainingJobReconciler) newSteps() []Step {
return []Step{
Step{
JobCondition: commonv1.WorkersCreated,
Action: r.createTrainingJobWorkers,
},
Step{
JobCondition: commonv1.WorkersReady,
Action: r.waitWorkersRunning,
},
Step{
JobCondition: commonv1.LauncherCreated,
Action: r.createLauncher,
},
Step{
JobCondition: commonv1.JobRunning,
Action: r.syncLauncherState,
},
}
}
func (r *TrainingJobReconciler) doSteps(job *kaiv1alpha1.TrainingJob, steps []Step) error {
for _, step := range steps {
if hasCondition(*job.GetJobStatus(), step.JobCondition) {
continue
}
err := step.Action(job)
break
}
return nil
}
���Ծ�������:
Request("")
K8S +--------------------> Reconcile
+
|
|
v
+----------------------+---------------------+
| ReconcileJobs |
| + |
| | |
| +------------------------------+ |
| | | | |
| v v v |
| "", JobCreated JobRunning Scaling |
+--------+-----------------------------------+
|
|
v
reconcileResource
+
|
|
v
+---------+---------------+
| doSteps |
| |
| |
| WorkersCreated +---------> createTrainingJobWorkers
| |
| |
| WorkersReady +----------> waitWorkersRunning
| |
| |
| LauncherCreated +--------> createLauncher
| |
| |
| JobRunning +------------> syncLauncherState
| |
+-------------------------+
4.5 createTrainingJobWorkers
�� doSteps ������,������ createTrainingJobWorkers ���Action����������� Job ״̬Ϊ WorkersCreated��
func (r *TrainingJobReconciler) createTrainingJobWorkers(job *kaiv1alpha1.TrainingJob) error {
if job.GetAttachMode() == kaiv1alpha1.AttachModeSSH {
if cm, err := r.GetOrCreateSecret(job); cm == nil || err != nil {
updateStatus(job.GetJobStatus(), common.JobFailed, trainingJobFailedReason, msg)
return nil
}
}
workers := getJobReplicasWorkers(job)
job.Status.TargetWorkers = workers
// ����worker
if err := r.CreateWorkers(job, workers); err != nil {
updateStatus(job.GetJobStatus(), common.JobFailed, trainingJobFailedReason, msg)
return nil
}
// ������״̬
updateJobConditions(job.GetJobStatus(), common.WorkersCreated, "", msg)
return nil
}
4.5.1 CreateWorkers
CreateWorkers ����д���worker,�籾��ǰ�����,worker ���� service �� pod,���Դ������̾���Ϊ:
-
���� ��һ��ͬ������CreateWorkers ����Ӵ��� workerService��
-
���� newWorker ȥ���� Pod��
func (r *TrainingJobReconciler) CreateWorkers(job *kaiv1alpha1.TrainingJob, workers []string) error {
return r.createWorkers(job, workers, func(name string, index string) *corev1.Pod {
worker := newWorker(job, name, index)
return worker
})
}
4.5.1.1 createWorkers
�����ѭ������ createWorker ������������һϵ�� workers��
func (r *TrainingJobReconciler) createWorkers(job *kaiv1alpha1.TrainingJob, workers []string, newPod PodTplGenerator) error {
// ����,����
for _, podName := range workers {
index, err := getWorkerIndex(job.Name, podName)
if err != nil {
return err
}
_, err = r.createWorker(job, int32(index), newPod)
if err != nil {
return err
}
}
return nil
}
4.5.1.2 createWorker
��������ݲ����� worker Pod �����ж�,���������,�� ijһ�� worker��
func (r *TrainingJobReconciler) createWorker(job *kaiv1alpha1.TrainingJob, index int32, workerPodTempl PodTplGenerator) (*corev1.Pod, error) {
name := getWorkerName(job.Name, int(index))
indexStr := strconv.Itoa(int(index))
pod := &corev1.Pod{}
nsn := types.NamespacedName{
Name: name,
Namespace: job.Namespace,
}
err := r.Get(context.Background(), nsn, pod)
if err != nil {
// If the worker Pod doesn't exist, we'll create it.
if errors.IsNotFound(err) {
// ���û��pod,����Ҳ���Դ���pod
worker := workerPodTempl(name, indexStr)
if job.GetAttachMode() == kaiv1alpha1.AttachModeSSH {
util.MountRsaKey(worker, job.Name)
}
if err = r.Create(context.Background(), worker); err != nil {
return nil, err
}
}
}
service := &corev1.Service{}
err = r.Get(context.Background(), nsn, service)
if errors.IsNotFound(err) {
// ����newService ���о��崴��
err = r.Create(context.Background(), newService(job, name, indexStr))
}
return nil, nil
}
4.5.1.3 newService
������������崴��service,���ǰ�תǧ�ء�
func newService(obj interface{}, name string, index string) *corev1.Service {
job, _ := obj.(*kaiv1alpha1.TrainingJob)
labels := GenLabels(job.Name)
labels[labelTrainingRoleType] = worker
labels[replicaIndexLabel] = index
return &corev1.Service{ // ���崴��
ObjectMeta: metav1.ObjectMeta{
Name: name,
Namespace: job.Namespace,
Labels: labels,
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(job, kaiv1alpha1.SchemeGroupVersionKind),
},
},
Spec: corev1.ServiceSpec{
ClusterIP: "None",
Selector: labels,
Ports: []corev1.ServicePort{
{
Name: "ssh-port",
Port: 22,
},
},
},
}
}
4.5.2 newWorker
newWorker ���� Pod,���DZȽϳ�������·��
func newWorker(obj interface{}, name string, index string) *corev1.Pod {
job, _ := obj.(*kaiv1alpha1.TrainingJob)
labels := GenLabels(job.Name)
labels[labelTrainingRoleType] = worker
labels[replicaIndexLabel] = index
podSpec := job.Spec.ETReplicaSpecs.Worker.Template.DeepCopy()
// keep the labels which are set in PodTemplate
if len(podSpec.Labels) == 0 {
podSpec.Labels = make(map[string]string)
}
for key, value := range labels {
podSpec.Labels[key] = value
}
// RestartPolicy=Never
setRestartPolicy(podSpec)
container := podSpec.Spec.Containers[0]
// if we want to use ssh, will start sshd service firstly.
if len(container.Command) == 0 {
if job.GetAttachMode() == kaiv1alpha1.AttachModeSSH {
container.Command = []string{"sh", "-c", "/usr/sbin/sshd && sleep 365d"}
} else {
container.Command = []string{"sh", "-c", "sleep 365d"}
}
}
podSpec.Spec.Containers[0] = container
// ������pod
return &corev1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: name,
Namespace: job.Namespace,
Labels: podSpec.Labels,
Annotations: podSpec.Annotations,
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(job, kaiv1alpha1.SchemeGroupVersionKind),
},
},
Spec: podSpec.Spec,
}
}
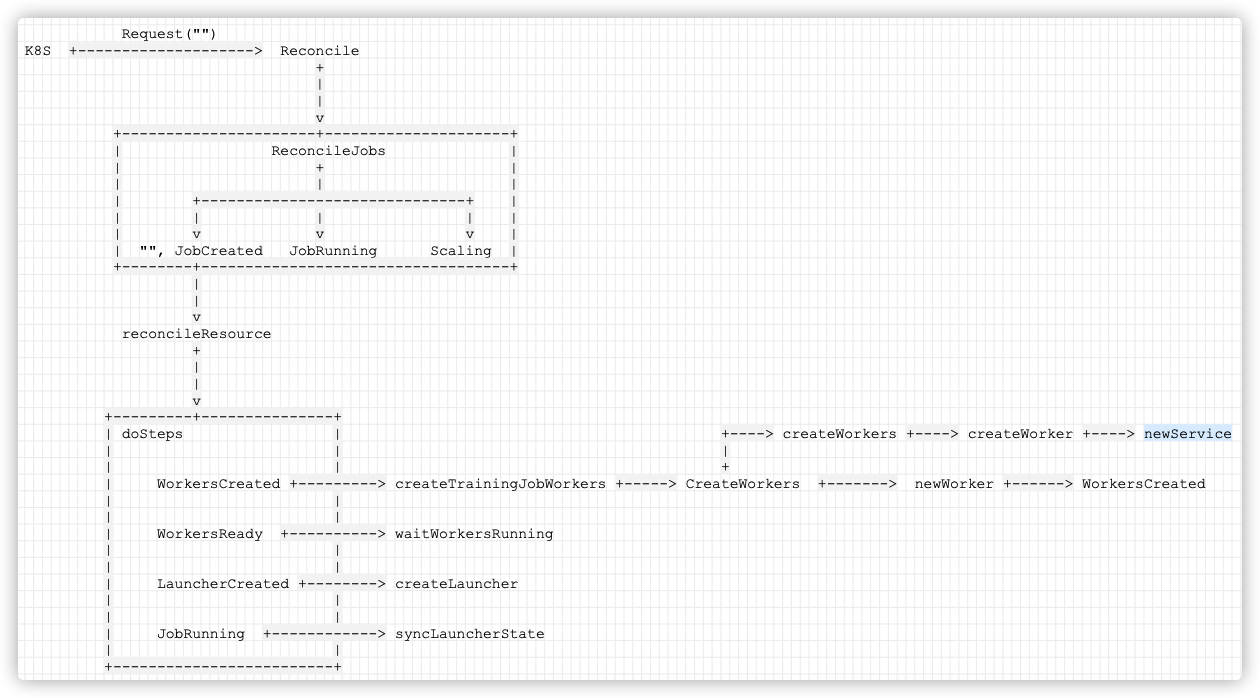
������:
Request("")
K8S +--------------------> Reconcile
+
|
|
v
+----------------------+---------------------+
| ReconcileJobs |
| + |
| | |
| +------------------------------+ |
| | | | |
| v v v |
| "", JobCreated JobRunning Scaling |
+--------+-----------------------------------+
|
|
v
reconcileResource
+
|
|
v
+---------+---------------+
| doSteps | +----> createWorkers +----> createWorker +----> newService
| | |
| | +
| WorkersCreated +---------> createTrainingJobWorkers +-----> CreateWorkers +-------> newWorker +------> WorkersCreated
| |
| |
| WorkersReady +----------> waitWorkersRunning
| |
| |
| LauncherCreated +--------> createLauncher
| |
| |
| JobRunning +------------> syncLauncherState
| |
+-------------------------+
�ֻ�����:
4.8 createLauncher
������ worker ֮��,�Ϳ�ʼ���� Launcher�����Լ���ִ�� createLauncher��
func (r *TrainingJobReconciler) createLauncher(job *kaiv1alpha1.TrainingJob) error {
if _, err := r.GetOrCreateLauncherServiceAccount(job); err != nil {
updateStatus(job.GetJobStatus(), commonv1.JobFailed, trainingJobFailedReason, msg)
return nil
}
if _, err := r.GetOrCreateLauncherRole(job, 0); err != nil {
updateStatus(job.GetJobStatus(), commonv1.JobFailed, trainingJobFailedReason, msg)
return nil
}
if _, err := r.GetLauncherRoleBinding(job); err != nil {
updateStatus(job.GetJobStatus(), commonv1.JobFailed, trainingJobFailedReason, msg)
return nil
}
if cm, err := r.CreateHostConfigMap(job); cm == nil || err != nil {
updateStatus(job.GetJobStatus(), commonv1.JobFailed, trainingJobFailedReason, msg)
return nil
}
launcher, err := r.GetLauncherJob(job)
if launcher == nil {
if _, err := r.CreateLauncher(job); err != nil {
updateStatus(job.GetJobStatus(), commonv1.JobFailed, trainingJobFailedReason, msg)
return nil
}
}
updateJobConditions(job.GetJobStatus(), commonv1.LauncherCreated, "", msg)
return nil
}
����ȡ�����ص㲽�衣
4.8.1 CreateHostConfigMap
�����ȡ����host�����á�
func (r *TrainingJobReconciler) CreateHostConfigMap(job *kaiv1alpha1.TrainingJob) (*corev1.ConfigMap, error) {
return r.createConfigMap(job, newHostfileConfigMap)
}
func (r *TrainingJobReconciler) createConfigMap(job *kaiv1alpha1.TrainingJob, newCm func(job *kaiv1alpha1.TrainingJob) *corev1.ConfigMap) (*corev1.ConfigMap, error) {
cm := &corev1.ConfigMap{}
name := ctrl.Request{}
name.NamespacedName.Namespace = job.GetNamespace()
name.NamespacedName.Name = job.GetName() + configSuffix
err := r.Get(context.Background(), name.NamespacedName, cm)
if errors.IsNotFound(err) {
if err = r.Create(context.Background(), newCm(job)); err != nil {
return cm, err
}
}
return cm, nil
}
4.8.2 ����pod
4.8.2.1 CreateLauncher
�������pod�Ĵ���
func (r *TrainingJobReconciler) CreateLauncher(obj interface{}) (*corev1.Pod, error) {
job, ok := obj.(*kaiv1alpha1.TrainingJob)
launcher := newLauncher(job) // ����pod
if job.GetAttachMode() == kaiv1alpha1.AttachModeSSH {
util.MountRsaKey(launcher, job.Name)
}
err := r.Create(context.Background(), launcher)
return launcher, nil
}
4.8.2.2 newLauncher
������Ǿ��幹�� Pod��
func newLauncher(obj interface{}) *corev1.Pod {
job, _ := obj.(*kaiv1alpha1.TrainingJob)
launcherName := job.Name + launcherSuffix
labels := GenLabels(job.Name)
labels[labelTrainingRoleType] = launcher
podSpec := job.Spec.ETReplicaSpecs.Launcher.Template.DeepCopy()
// copy the labels and annotations to pod from PodTemplate
if len(podSpec.Labels) == 0 {
podSpec.Labels = make(map[string]string)
}
for key, value := range labels {
podSpec.Labels[key] = value
}
podSpec.Spec.InitContainers = append(podSpec.Spec.InitContainers, initContainer(job))
//podSpec.Spec.InitContainers = append(podSpec.Spec.InitContainers, kubedeliveryContainer())
container := podSpec.Spec.Containers[0]
container.VolumeMounts = append(container.VolumeMounts,
corev1.VolumeMount{
Name: hostfileVolumeName,
MountPath: hostfileMountPath,
},
corev1.VolumeMount{
Name: configVolumeName,
MountPath: configMountPath,
},
corev1.VolumeMount{
Name: kubectlVolumeName,
MountPath: kubectlMountPath,
})
if job.GetAttachMode() == kaiv1alpha1.AttachModeKubexec {
container.Env = append(container.Env, corev1.EnvVar{
Name: "OMPI_MCA_plm_rsh_agent",
Value: getKubexecPath(),
})
}
podSpec.Spec.Containers[0] = container
podSpec.Spec.ServiceAccountName = launcherName
setRestartPolicy(podSpec)
hostfileMode := int32(0444)
scriptMode := int32(0555)
podSpec.Spec.Volumes = append(podSpec.Spec.Volumes,
corev1.Volume{
Name: hostfileVolumeName,
VolumeSource: corev1.VolumeSource{
EmptyDir: &corev1.EmptyDirVolumeSource{},
},
},
corev1.Volume{
Name: kubectlVolumeName,
VolumeSource: corev1.VolumeSource{
EmptyDir: &corev1.EmptyDirVolumeSource{},
},
},
corev1.Volume{
Name: configVolumeName,
VolumeSource: corev1.VolumeSource{
ConfigMap: &corev1.ConfigMapVolumeSource{
LocalObjectReference: corev1.LocalObjectReference{
Name: job.Name + configSuffix,
},
Items: []corev1.KeyToPath{
{
Key: hostfileName,
Path: hostfileName,
Mode: &hostfileMode,
},
{
Key: discoverHostName,
Path: discoverHostName,
Mode: &hostfileMode,
},
{
Key: kubexeclFileName,
Path: kubexeclFileName,
Mode: &scriptMode,
},
},
},
},
})
return &corev1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: launcherName,
Namespace: job.Namespace,
Labels: podSpec.Labels,
Annotations: podSpec.Annotations,
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(job, kaiv1alpha1.SchemeGroupVersionKind),
},
},
Spec: podSpec.Spec,
}
}
����,һ���µ�ѵ��job����������,������չ����:
Request("")
K8S ---------------------> Reconcile
+
|
|
v
+----------------------+---------------------+
| ReconcileJobs |
| + |
| | |
| +------------------------------+ |
| | | | |
| v v v |
| "", JobCreated JobRunning Scaling |
+--------+-----------------------------------+
|
|
v
reconcileResource
+
|
|
v
+---------+---------------+
| doSteps | +----> createWorkers +----> createWorker +----> newService
| | |
| | |
| WorkersCreated +---------> createTrainingJobWorkers +-----> CreateWorkers +-------> newWorker +------> WorkersCreated
| |
| |
| WorkersReady +----------> waitWorkersRunning
| |
| |
| LauncherCreated +--------> createLauncher+----> CreateHostConfigMap +-----> CreateLauncher +------> newLauncher
| |
| |
| JobRunning +------------> syncLauncherState
| |
+-------------------------+
�ֻ�����:

�������job�Ĵ���,���ǿ������ĵĹؼ�������,scaleOut �� scaleIn��
0x05 ScaleOut
5.1 ˼·
ScaleOut ���� CR����:

���·�һ�� ScaleOut CR,ScaleOutController ���� Reconcile, ���﹤���ܼ�,���� ScaleOut CR �е� Selector �ֶ�,�ҵ� Scaler ��Ӧ�� TrainingJob,���õ� CR �� OwnerReferences �ϡ�
��һ�� ScaleOut ��������:
- apiVersion: kai.alibabacloud.com/v1alpha1
kind: ScaleOut
metadata:
creationTimestamp: "2020-11-04T13:54:26Z
name: scaleout-ptfnk
namespace: default
ownerReferences:
- apiVersion: kai.alibabacloud.com/v1alpha1
blockOwnerDeletion: true
controller: true
kind: TrainingJob
name: elastic-training // ָ�����ݶ���TrainingJob
uid: 075b9c4a-22f9-40ce-83c7-656b329a2b9e
spec:
selector:
name: elastic-training
toAdd:
count: 2
5.2 Reconcile
���·�һ�� ScaleOut CR,ScaleOutController ���� Reconcile����Ҫ���ǵ��� setScalingOwner��
func (r *ScaleOutReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
scaleOut, err := getScaleOut(req.NamespacedName, r.Client)
if err != nil {
// Error reading the object - requeue the request.
return RequeueImmediately()
}
if scaleOut == nil || scaleOut.DeletionTimestamp != nil {
return NoRequeue()
}
if isScaleFinished(*scaleOut.GetJobStatus()) {
return NoRequeue()
}
return setScalingOwner(r, scaleOut, r.PollInterval)
}
5.3 setScalingOwner
setScalingOwner �ǹؼ�֮һ��
������Ҫ�Ǵ����� ScaleOut CR û������ OwnerReferences �����,������һ����
���� ���� ScaleOut CR �е� Selector �ֶ�,�ҵ� Scaler ��Ӧ�� TrainingJob,���õ� CR �� OwnerReferences �ϡ�
func setScalingOwner(r client.Client, scaler Scaler, pollInterval time.Duration) (ctrl.Result, error) {
ownerRefs := scaler.GetOwnerReferences()
if len(ownerRefs) == 0 {
trainingJob := &kaiv1alpha1.TrainingJob{}
nsn := types.NamespacedName{}
nsn.Namespace = scaler.GetNamespace()
nsn.Name = scaler.GetSelector().Name
err := r.Get(context.Background(), nsn, trainingJob)
gvk := kaiv1alpha1.SchemeGroupVersionKind
ownerRefs = append(ownerRefs, *metav1.NewControllerRef(trainingJob, schema.GroupVersionKind{Group: gvk.Group, Version: gvk.Version, Kind: gvk.Kind}))
scaler.SetOwnerReferences(ownerRefs)
initializeJobStatus(scaler.GetJobStatus())
updateJobConditions(scaler.GetJobStatus(), v1.JobCreated, "", msg)
err = r.Status().Update(context.Background(), scaler)
err = r.Update(context.Background(), scaler)
}
return NoRequeue()
}
// RequeueAfterInterval requeues after a duration when duration > 0 is specified.
func RequeueAfterInterval(interval time.Duration, err error) (ctrl.Result, error) {
return ctrl.Result{RequeueAfter: interval}, err
}
5.4 TrainingJobController
TrainingJobController �м��������� TrainingJob �� ScaleOut CR �и���, ���� TrainingJob �� Reconcile,�������� TrainingJob �� OwnerReference ָ��� ScaleIn �� ScaleOut, ���ݴ���ʱ���״̬ʱ�����ִ�е����ݻ���������
5.4.1 Reconcile
func (r *TrainingJobReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
rlog := r.Log.WithValues("trainingjob", req.NamespacedName)
// Fetch latest training job instance.
sharedTrainingJob := &kaiv1alpha1.TrainingJob{}
err := r.Get(context.Background(), req.NamespacedName, sharedTrainingJob)
trainingJob := sharedTrainingJob.DeepCopy()
// Check reconcile is required.
// No need to do reconcile or job has been deleted.
r.Scheme.Default(trainingJob)
return r.ReconcileJobs(trainingJob)
}
5.4.2 ReconcileJobs
func (r *TrainingJobReconciler) ReconcileJobs(job *kaiv1alpha1.TrainingJob) (result reconcile.Result, err error) {
oldJobStatus := job.Status.DeepCopy()
logger.Infof("jobName: %v, phase %s", job.Name, job.Status.Phase)
defer func() {
latestJob := &kaiv1alpha1.TrainingJob{}
err := r.Get(context.Background(), types.NamespacedName{
Name: job.Name,
Namespace: job.Namespace,
}, latestJob)
if err == nil {
if latestJob.ObjectMeta.ResourceVersion != job.ObjectMeta.ResourceVersion {
latestJob.Status = job.Status
job = latestJob
}
}
r.updateObjectStatus(job, oldJobStatus)
}()
switch job.Status.Phase {
case commonv1.JobSucceeded, commonv1.JobFailed:
err = r.cleanup(job)
case "", commonv1.JobCreated:
r.initializeJob(job)
err = r.reconcileResource(job)
case commonv1.JobRunning:
err = r.reconcileJobRunning(job)
case commonv1.Scaling:
err = r.executeScaling(job)
default:
logger.Warnf("job %s unknown status %s", job.Name, job.Status.Phase)
}
if err != nil {
if IsRequeueError(err) {
return RequeueAfterInterval(r.PollInterval, nil)
}
return RequeueAfterInterval(r.PollInterval, err)
}
return NoRequeue()
}
���¸��ݵ�ǰ job ״̬��ͬ,����������,���� JobRunning ,Ȼ���� Scaling,���ָ��� JobRunning��
����һһ������
5.5 JobRunning
���������� JobRunning ״̬,�������ο�����δ�����
5.5.1 reconcileJobRunning
func (r *TrainingJobReconciler) reconcileJobRunning(job *kaiv1alpha1.TrainingJob) error {
if err := r.syncLauncherState(job); err != nil {
return err
}
if err := r.syncWorkersState(job); err != nil {
return err
}
if job.Status.Phase == commonv1.JobRunning {
return r.setTrainingJobScaler(job) // ��Ȼ��JobRunning״̬,�Ϳ��Կ�ʼ��������scaler
}
return nil
}
5.5.2 setTrainingJobScaler
����,ͨ�� availableScaleOutList ���� availableScaleInList ,Ȼ�����update��
func (r *TrainingJobReconciler) setTrainingJobScaler(job *kaiv1alpha1.TrainingJob) error {
scaleOut, err := r.availableScaleOutList(job) // �ҵ�scaleout list
scaleIn, err := r.availableScaleInList(job) // �ҵ�scaleIn list
scalerList := append(scaleOut, scaleIn...) // �ϲ�
// Select the latest scaling job
r.updateLatestScaler(job, scalerList) // ��ʼ����
return nil
}
5.5.3 updateLatestScaler
���ݴ���ʱ���״̬ʱ��,�ҵ����һ��Scaler��
func (r *TrainingJobReconciler) updateLatestScaler(job *kaiv1alpha1.TrainingJob, scalers []Scaler) error {
var latestScaler Scaler
if len(scalers) == 0 {
return nil
}
for i, _ := range scalers {
scalerItem := scalers[i]
// ���ݴ���ʱ���״̬ʱ��,�ҵ����һ��Scaler
if latestScaler == nil || latestScaler.GetCreationTimestamp().Time.Before(scalerItem.GetCreationTimestamp().Time) {
latestScaler = scalerItem
}
}
return r.updateCurrentScaler(job, latestScaler)
}
5.5.4 updateCurrentScaler
���ҵ���scaler�������á�
func (r *TrainingJobReconciler) updateCurrentScaler(job *kaiv1alpha1.TrainingJob, scaleItem Scaler) error {
job.Status.CurrentScaler = scaleItem.GetFullName()
msg := fmt.Sprintf("trainingJobob(%s/%s) execute %s", job.Namespace, job.Name, scaleItem.GetFullName())
// ����״̬
r.updateScalerState(scaleItem, job, newCondition(common.Scaling, scalingStartReason, msg))
if err := r.updateObjectStatus(scaleItem, nil); err != nil {
return err
}
return nil
}
5.5.5 updateScalerState
��ʱ������� common.Scaling�������´�����,�ᵽ Scaling ��֧��
func (r *TrainingJobReconciler) updateScalerState(scaleObj Scaler, trainingJob *kaiv1alpha1.TrainingJob, condition common.JobCondition) error {
jobPhase := common.Scaling // ���� common.Scaling�������´�����,�ᵽ Scaling ��֧
currentJob := scaleObj.GetFullName()
if condition.Type == common.ScaleSucceeded || condition.Type == common.ScaleFailed {
jobPhase = common.JobRunning
currentJob = ""
}
setCondition(trainingJob.GetJobStatus(), condition)
updateStatusPhase(trainingJob.GetJobStatus(), jobPhase)
updateTrainingJobCurrentScaler(trainingJob.GetJobStatus(), currentJob)
setCondition(scaleObj.GetJobStatus(), condition)
updateStatusPhase(scaleObj.GetJobStatus(), condition.Type)
return nil
}
������:
1 Request("")
K8S +--------------------> Reconcile <------------------+
2 ScaleOut CR + |
K8S +--------------------> | |
| |
v |
+----------------------+---------------------+ |
| ReconcileJobs | |
| + | |
| | | |
| +------------------------------+ | |
| 1 | | 2 3 | | |
| v v v | |
| "", JobCreated JobRunning Scaling | |
+--------+-------------+---------------------+ |
| | |
1 | | 2 |
v v |
reconcileResource reconcileJobRunning |
+ + |
1 | | 2 |
| | |
v v |
+--------------------+----+ setTrainingJobScaler |
| doSteps | + |
| | | 2 |
| | | |
| WorkersCreated | v |
| | updateScalerState |
| | + |
| WorkersReady | | |
| | | 2 |
| | v |
| LauncherCreated | common.Scaling |
| | + |
| | | |
| JobRunning | | 2 |
| | | |
+-------------------------+ +-------------------------+
5.6 Scaling
5.6.1 executeScaling
���� scale �����Ͳ�ͬ,���в�ͬ��չ��
func (r *TrainingJobReconciler) executeScaling(job *kaiv1alpha1.TrainingJob) error {
if err := r.syncLauncherState(job); err != nil {
return err
}
if job.Status.CurrentScaler == "" {
updateStatusPhase(job.GetJobStatus(), common.JobRunning)
return nil
}
if isFinished(*job.GetJobStatus()) {
return nil
}
scalerType, scalerName := getScalerName(job.Status.CurrentScaler)
// ���� in ���� out ���в�ͬ�Ĵ���
if scalerType == "ScaleIn" {
scaleIn, err := getScaleIn(scalerName, r)
if scaleIn == nil || isScaleFinished(*scaleIn.GetJobStatus()) {
finishTrainingScaler(job.GetJobStatus())
return nil
}
oldStatus := scaleIn.Status.DeepCopy()
defer r.updateObjectStatus(scaleIn, oldStatus)
// ִ�о������ݲ���
if err = r.executeScaleIn(job, scaleIn); err != nil {
return err
}
} else if scalerType == "ScaleOut" {
scaleOut, err := getScaleOut(scalerName, r)
if scaleOut == nil || isScaleFinished(*scaleOut.GetJobStatus()) {
finishTrainingScaler(job.GetJobStatus())
return nil
}
oldStatus := scaleOut.Status.DeepCopy()
defer r.updateObjectStatus(scaleOut, oldStatus)
// ִ�о������ݲ���
if err = r.executeScaleOut(job, scaleOut); err != nil {
}
}
return nil
}
5.6.2 executeScaleOut
������չ��
- ʹ�� setScaleOutWorkers �� scaleOut.Status.AddPods ���������� pods��
- ʹ�� workersAfterScaler �õ� ���յ� worker��
- ʹ�� executeScaleScript ����scale ������
func (r *TrainingJobReconciler) executeScaleOut(job *kaiv1alpha1.TrainingJob, scaleOut *kaiv1alpha1.ScaleOut) error {
initializeJobStatus(scaleOut.GetJobStatus())
if err := r.validateScaleOut(scaleOut); err != nil {
r.updateScalerFailed(scaleOut, job, err.Error())
return err
}
if err := r.setScaleOutWorkers(job, scaleOut); err != nil {
return err
}
err := r.ScaleOutWorkers(job, scaleOut)
if err != nil {
msg := fmt.Sprintf("%s create scaleout workers failed, error: %v", scaleOut.GetFullName(), err)
r.ScaleOutFailed(job, scaleOut, msg)
return err
}
scaleOutWorkers, err := r.getScalerOutWorkers(job, scaleOut)
workerStatuses, _ := r.workerReplicasStatus(scaleOut.GetJobStatus(), scaleOutWorkers)
if workerStatuses.Active < *scaleOut.Spec.ToAdd.Count {
if IsScaleOutTimeout(scaleOut) {
msg := fmt.Sprintf("scaleout job %s execution timeout", scaleOut.GetFullName())
r.ScaleOutFailed(job, scaleOut, msg)
}
return NewRequeueError(fmt.Errorf("wait for workers running"))
}
hostWorkers := r.workersAfterScaler(job.Status.CurrentWorkers, scaleOut)
// execute scalein script
// ִ��scale�ű�
if err := r.executeScaleScript(job, scaleOut, hostWorkers); err != nil {
msg := fmt.Sprintf("%s execute script failed, error: %v", scaleOut.GetFullName(), err)
r.ScaleOutFailed(job, scaleOut, msg)
return err
} else {
job.Status.TargetWorkers = r.workersAfterScaler(job.Status.TargetWorkers, scaleOut)
r.updateScalerSuccessd(scaleOut, job)
}
return nil
}
5.6.3 executeScaleScript
��ʱ����� hostfileUpdateScript,���� host file;
���յ��� executeOnLauncherִ�нű���
func (r *TrainingJobReconciler) executeScaleScript(trainingJob *kaiv1alpha1.TrainingJob, scaler Scaler, workers []string) error {
if isScriptExecuted(*scaler.GetJobStatus()) {
return nil
}
msg := fmt.Sprintf("trainingjob(%s/%s): execute script on launcher for %s", trainingJob.Namespace, trainingJob.Name, scaler.GetFullName())
slots := getSlots(trainingJob)
scriptSpec := scaler.GetScriptSpec()
var script string
// �õ��ű�
if scriptSpec.Script != "" {
script = scalerScript(scriptSpec.GetTimeout(), scriptSpec.Env, scriptSpec.Script, scaler.GetPodNames(), slots)
} else {
hostfilePath := getHostfilePath(trainingJob)
script = hostfileUpdateScript(hostfilePath, workers, slots)
}
// ִ�нű�
_, _, err := r.executeOnLauncher(trainingJob, script)
updateJobConditions(scaler.GetJobStatus(), common.ScriptExecuted, "", msg)
return nil
}
5.6.3.1 hostfileUpdateScript
�õ����յĽű�string��
func hostfileUpdateScript(hostfile string, workers []string, slot int) string {
return fmt.Sprintf(
`echo '%s' > %s`, getHostfileContent(workers, slot), hostfile)
}
5.6.3.2 getHostfileContent
��ȡhost file����
func getHostfileContent(workers []string, slot int) string {
var buffer bytes.Buffer
for _, worker := range workers {
buffer.WriteString(fmt.Sprintf("%s:%d\n", worker, slot))
}
return buffer.String()
}
5.6.3.3 executeOnLauncher
��pod��ִ��
func (r *TrainingJobReconciler) executeOnLauncher(trainingJob *kaiv1alpha1.TrainingJob, script string) (string, string, error) {
var err error
var launcherPod *corev1.Pod
if launcherPod, err = r.GetLauncherJob(trainingJob); err != nil {
}
if launcherPod != nil {
stdOut, stdErr, err := kubectlOnPod(launcherPod, script)
return stdOut, stdErr, nil
}
return "", "", nil
}
5.6.3.4 kubectlOnPod
���� worker��
func kubectlOnPod(pod *corev1.Pod, cmd string) (string, string, error) {
cmds := []string{
"/bin/sh",
"-c",
cmd,
}
stdout, stderr, err := util.ExecCommandInContainerWithFullOutput(pod.Name, pod.Spec.Containers[0].Name, pod.Namespace, cmds)
if err != nil {
return stdout, stderr, err
}
return stdout, stderr, nil
}
������:
1 Request("")
K8S +--------------------> Reconcile <------------------+
2 ScaleOut CR + |
K8S +--------------------> | |
| |
v |
+----------------------+---------------------+ |
| ReconcileJobs | |
| + | |
| | | |
| +------------------------------+ | |
| 1 | | 2 3 | | |
| v v v | | 3
| "", JobCreated JobRunning Scaling +-----------> executeScaling
+--------+-------------+---------------------+ | +
| | | |
1 | | 2 | | 3
v v | v
reconcileResource reconcileJobRunning | executeScaleOut
+ + | +
1 | | 2 | |
| | | | 3
v v | v
+--------------------+----+ setTrainingJobScaler | executeScaleScript
| doSteps | + | +
| | | 2 | |
| | | | | 3
| WorkersCreated | v | v
| | updateScalerState | hostfileUpdateScript
| | + | +
| WorkersReady | | | | 3
| | | 2 | |
| | v | v
| LauncherCreated | common.Scaling | executeOnLauncher
| | + | +
| | | | |
| JobRunning | | 2 | | 3
| | | | v
+-------------------------+ +-------------------------+ kubectlOnPod
0x06 ScaleIn
6.1 ˼·
ScaleIn ���� CR����:

ִ������ʱ,����ͨ�� ScaleIn CR �е� spec.toDelete.count �� spec.toDelete.podNames �ֶ�ָ�����ݵ� worker��
ͨ�� count �������ݵ�����,��ͨ�� index �����ɸߵ������� Worker��
apiVersion: kai.alibabacloud.com/v1alpha1
kind: ScaleIn
metadata:
name: scalein-workers
spec:
selector:
name: elastic-training
toDelete:
count: 1
�����Ҫ�����ض��� Worker,�������� podNames:
apiVersion: kai.alibabacloud.com/v1alpha1
kind: ScaleIn
metadata:
name: scalein-workers
spec:
selector:
name: elastic-training
toDelete:
podNames:
- elastic-training-worker-1
����һ������ʾ��,ָ���������� 1 �� worker:
kubectl create -f examples/scale_in_count.yaml
6.2 Reconcile
���·�һ�� scaleInCR,Controller ���� Reconcile����Ҫ���ǵ��� setScalingOwner��
func (r *ScaleInReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
//silog := r.Log.WithValues("scalein", req.NamespacedName)
scaleIn, err := getScaleIn(req.NamespacedName, r.Client)
if isScaleFinished(*scaleIn.GetJobStatus()) {
return NoRequeue()
}
// ���ϻ������Ǹ���У��
return setScalingOwner(r, scaleIn, r.PollInterval)
}
6.3 setScalingOwner
setScalingOwner �ǹؼ�֮һ��
������Ҫ�Ǵ����� ScaleIn CR û������ OwnerReferences �����,������һ����
���� ���� ScaleIn CR �е� Selector �ֶ�,�ҵ� Scaler ��Ӧ�� TrainingJob,���õ� CR �� OwnerReferences �ϡ�
�����Ƴ����ִ�������롣
func setScalingOwner(r client.Client, scaler Scaler, pollInterval time.Duration) (ctrl.Result, error) {
ownerRefs := scaler.GetOwnerReferences()
if len(ownerRefs) == 0 {
trainingJob := &kaiv1alpha1.TrainingJob{}
nsn := types.NamespacedName{}
nsn.Namespace = scaler.GetNamespace()
nsn.Name = scaler.GetSelector().Name
err := r.Get(context.Background(), nsn, trainingJob)
gvk := kaiv1alpha1.SchemeGroupVersionKind
ownerRefs = append(ownerRefs, *metav1.NewControllerRef(trainingJob, schema.GroupVersionKind{Group: gvk.Group, Version: gvk.Version, Kind: gvk.Kind}))
scaler.SetOwnerReferences(ownerRefs)
initializeJobStatus(scaler.GetJobStatus())
updateJobConditions(scaler.GetJobStatus(), v1.JobCreated, "", msg)
err = r.Status().Update(context.Background(), scaler)
err = r.Update(context.Background(), scaler)
}
return NoRequeue()
}
6.4 executeScaleIn
JobRunning ״̬������ ScaleOut����,�����Թ�,ֱ�ӿ�����executeScaleIn��
ִ������ʱ,����ͨ�� ScaleIn CR �е� spec.toDelete.count �� spec.toDelete.podNames �ֶ�ָ�����ݵ� worker��
ͨ�� count �������ݵ�����,��ͨ�� index �����ɸߵ������� Worker��
�����ϴ������:
setsSaleInToDelete ָ����Щ��Ҫɾ��;
executeScaleScript ִ�нű�;
DeleteWorkers ɾ�� worker;
func (r *TrainingJobReconciler) executeScaleIn(job *kaiv1alpha1.TrainingJob, scaleIn *kaiv1alpha1.ScaleIn) error {
if scaleIn.DeletionTimestamp != nil || isScaleFinished(*scaleIn.GetJobStatus()) {
logger.Info("reconcile cancelled, scalein does not need to do reconcile or has been deleted")
return nil
}
initializeJobStatus(scaleIn.GetJobStatus())
//TODO: Validate the scalein count for minSize
err := r.setsSaleInToDelete(job, scaleIn)
currentWorkers := r.workersAfterScaler(job.Status.CurrentWorkers, scaleIn)
// execute scalein script
if err := r.executeScaleScript(job, scaleIn, currentWorkers); err != nil {
msg := fmt.Sprintf("%s execute script failed, error: %v", scaleIn.GetFullName(), err)
r.updateScalerFailed(scaleIn, job, msg)
return nil
}
toDeleteWorkers := scaleIn.GetPodNames()
remainWorkers := false
if scaleIn.Spec.Script == "" {
if shutdownWorkers, err := r.checkWorkerShutdown(job, toDeleteWorkers); err != nil {
return err
} else {
if len(toDeleteWorkers) != len(shutdownWorkers) {
remainWorkers = true
toDeleteWorkers = shutdownWorkers
}
}
}
if err := r.DeleteWorkers(job, toDeleteWorkers); err != nil {
msg := fmt.Sprintf("%s delete resource failed, error: %v", scaleIn.GetFullName(), err)
r.updateScalerFailed(scaleIn, job, msg)
return nil
}
// wait pods deleted
deleted, _ := r.isWorkersDeleted(job.Namespace, scaleIn.GetPodNames())
if deleted {
job.Status.TargetWorkers = r.workersAfterScaler(job.Status.TargetWorkers, scaleIn)
job.Status.CurrentWorkers = currentWorkers
r.updateScalerSuccessd(scaleIn, job)
return nil
}
if remainWorkers {
msg := "wait for workers process shutdown"
logger.Info(msg)
return NewRequeueError(fmt.Errorf(msg))
}
return nil
}
6.5 setsSaleInToDelete
ͨ�� ScaleIn CR �е� spec.toDelete.count �� spec.toDelete.podNames �ֶ�ָ�����ݵ� worker��
func (r *TrainingJobReconciler) setsSaleInToDelete(job *kaiv1alpha1.TrainingJob, scaleIn *kaiv1alpha1.ScaleIn) error {
podNames := scaleIn.Status.ToDeletePods
if len(podNames) != 0 {
return /*filterPodNames(workers, podNames, false), */ nil
}
workers, err := r.GetWorkerPods(job)
toDelete := scaleIn.Spec.ToDelete
if toDelete.PodNames != nil {
workers = filterPodNames(workers, toDelete.PodNames, false)
} else if toDelete.Count > 0 {
if toDelete.Count < len(workers) {
allPodNames := getSortPodNames(job.Name, workers)
deletePodNames := allPodNames[len(workers)-toDelete.Count:]
workers = filterPodNames(workers, deletePodNames, false)
}
}
for _, worker := range workers {
scaleIn.Status.ToDeletePods = append(scaleIn.Status.ToDeletePods, worker.Name)
}
return nil
}
6.6 DeleteWorkers
����ɾ��worker service �� pods��
func (r *TrainingJobReconciler) DeleteWorkers(trainingJob *kaiv1alpha1.TrainingJob, workers []string) error {
if err := r.DeleteWorkerServices(trainingJob, workers); err != nil {
return fmt.Errorf("delete services failed: %++v", err)
}
if err := r.DeleteWorkerPods(trainingJob, workers); err != nil {
return fmt.Errorf("delete pods failed: %++v", err)
}
return nil
}
6.7 DeleteWorkerPods
ɾ��pods��
func (r *TrainingJobReconciler) DeleteWorkerPods(job *kaiv1alpha1.TrainingJob, pods []string) error {
workerPods, err := r.GetWorkerPods(job)
if pods != nil {
workerPods = filterPodNames(workerPods, pods, false)
}
for _, pod := range workerPods {
deleteOptions := &client.DeleteOptions{GracePeriodSeconds: utilpointer.Int64Ptr(0)}
if err := r.Delete(context.Background(), &pod, deleteOptions); err != nil && !errors.IsNotFound(err) {
r.recorder.Eventf(job, corev1.EventTypeWarning, trainingJobFailedReason, "Error deleting worker %s: %v", pod.Name, err)
//return err
}
r.recorder.Eventf(job, corev1.EventTypeNormal, trainingJobSucceededReason, "Deleted pod %s", pod.Name)
}
return nil
}
����������:
1 Request("")
K8S-----------------> Reconcile <------------------+
2 ScaleOut CR + |
K8S-----------------> | |
| |
v |
+----------------------+---------------------+ |
| ReconcileJobs | |
| + | |
| | | |
| +------------------------------+ | |
| 1 | | 2 3 | | |
| v v v | | 3
| "", JobCreated JobRunning Scaling +---------> executeScaling -----+
+--------+-------------+---------------------+ | + |
| | | | |
1 | | 2 | | 3 | 4
v v | v v
reconcileResource reconcileJobRunning | executeScaleOut executeScaleIn
+ + | + +
1 | | 2 | | |
| | | | 3 | 4
v v | v v
+------------+--------+ setTrainingJobScaler | executeScaleScript executeScaleScript
| doSteps | + | + +
| | | 2 | | |
| | | | | 3 | 4
| WorkersCreated | v | v v
| | updateScalerState | hostfileUpdateScript DeleteWorkers
| | + | + +
| WorkersReady | | | | 3 | 4
| | | 2 | | |
| | v | v v
| LauncherCreated | common.Scaling | executeOnLauncher DeleteWorkerPods
| | + | + +
| | | | | |
| JobRunning | | 2 | | 3 | 4
| | | | v v
+---------------------+ +-------------------------+ kubectlOnPod Delete
����,Horovodϵ�з������,��һƪ��ʼ��������������,�����ڴ���
0xEE ������Ϣ
��������������ͼ�����˼���������
�Ź����˺�:������˼��
������뼰ʱ�õ�����д���µ���Ϣ����,�����뿴�������Ƽ��ļ�������,�����ע��

0xFF �ο�
�� Kubernetes �ϵ������ѧϰѵ������ �C Elastic Training Operator