ע:�����ǹ��ڱ����ʵ��ѧ³����ʦ������Ӿ������ѧϰ�γ�ȫ���������粿�����ݵıʼ���һЩ�������⡣
�γ���Ƶ����
ȫ����������
ȫ����������ģ��
����ȫ����������ģ������:
f
=
W
2
m
a
x
(
0
,
W
1
x
+
b
1
)
+
b
2
f = W_2max(0,W_1x+b_1)+b_2
f=W2?max(0,W1?x+b1?)+b2?
�������Է��������������,maxΪ������������Է�������W���Կ���ģ��,ģ���������������������ȫ������������
W
1
W_1
W1?Ҳ���Կ���ģ��,ģ�������Ϊָ��,������Ϊ��ÿһ��������ӵ�в�ֹһ��ģ��,һ���������ж��ģ��,Ȼ��
W
2
W_2
W2??�ں�����ģ���ƥ������ʵ�����յĴ�֡�����ÿ��������ά��,
W
1
W_1
W1??�������������Լ�������Ҳ����ģ�������Ϊָ��,������������ͼ���ά��,
b
1
b_1
b1?��ά�Ⱦ�Ӧ������
W
1
W_1
W1?��������ͬ,1��,��
W
2
W_2
W2?���������������,��������������Ϊָ����
W
1
W_1
W1?������������,��10��,���������ͼ����
3072
��
1
3072 \times 1
3072��1ά,ָ��
W
1
W_1
W1?������Ϊ100,����
W
1
W_1
W1??��ά�Ⱦ���
100
��
3027
100 \times 3027
100��3027ά,
W
1
W_1
W1?��x��˺�õ��ľ���ά�Ⱦ���
100
��
1
100 \times 1
100��1ά,
b
1
b_1
b1?Ϊ
100
��
1
100 \times 1
100��1ά,���Ϻ�ά�Ȳ���,��ͨ��max����,ά�Ȳ��ᷢ���仯,��
W
2
W_2
W2?Ϊ
10
��
100
10 \times 100
10��100ά,��
W
1
W_1
W1?��˺�͵õ���
10
��
1
10 \times 1
10��1��
ȫ�����������������������Բ��ɷ�ƽ��ķ������⡣
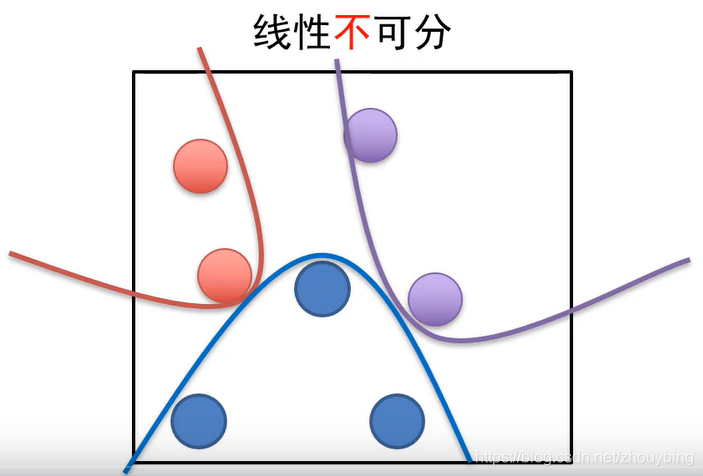
ȫ����������ı�ʾ����:
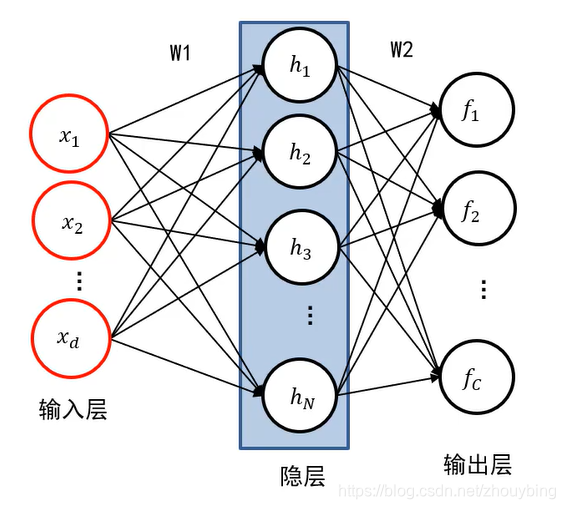
��ͼΪһ������ȫ����������ı�ʾ,������dz�����㻹ʣ�����㡣�����ͱ�ʾΪ���������ͼ��,������ά��Ҳ��������ͼ���ά��,Ҳ����d����Ԫ���м��������൱�� W 1 �� x W_1 \times x W1?��x��Ľ��,����Ԫ�ĸ�����������ָ����ģ��ĸ���Ҳ���� W 1 W_1 W1??������������������,����Ԫ�ĸ��������������������㵽����ı�,���൱�� W 1 W_1 W1?,x������ W 1 W_1 W1?��˵������õ�����,��ͼ��֪,��һ���ÿһ����Ԫ����һ���ÿһ����Ԫ��������,��˱���Ϊȫ���������硣
ע����ȫ�����������ģ�������DZ���Ҫ�����,����������һ������ȫ�����������ģ��:
f
=
W
3
m
a
x
(
0
,
W
2
m
a
x
(
0
,
W
1
x
+
b
1
)
+
b
2
)
+
b
3
f=W_3max(0,W_2max(0,W_1x+b_1)+b_2)+b_3
f=W3?max(0,W2?max(0,W1?x+b1?)+b2?)+b3?
���ȥ�������:
f
=
W
3
W
2
W
1
x
+
W
3
W
2
b
1
+
W
3
b
2
+
b
3
=
W
x
+
b
f=W_3W_2W_1x+W_3W_2b_1+W_3b_2+b_3=Wx+b
f=W3?W2?W1?x+W3?W2?b1?+W3?b2?+b3?=Wx+b
��Ȼȥ���������ȫ�����������ģ�;ͱ����һ�����Է�������
���õļ����
Sigmoid:
f
=
1
(
1
+
e
?
x
)
f = \frac{1}{(1+e^{-x})}
f=(1+e?x)1?
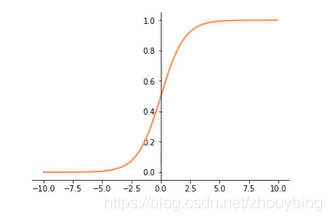
tanh:
f
=
e
x
?
e
?
x
e
x
+
e
?
x
f = \frac{e^x-e^{-x}}{e^x+e^{-x}}
f=ex+e?xex?e?x?
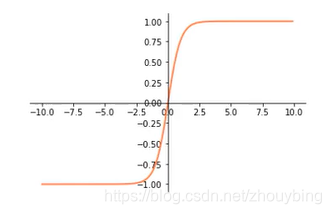
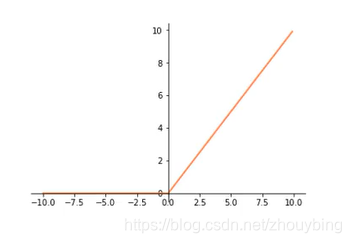
ReLU:
f
=
m
a
x
(
0
,
x
)
f = max(0,x)
f=max(0,x)
Leaky ReLU:
f
=
m
a
x
(
0.1
x
,
x
)
f = max(0.1x,x)
f=max(0.1x,x)
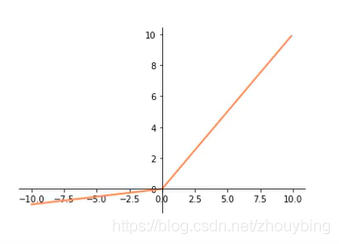
��ѡ���ʱ����ѡ��ReLU������Leakly ReLU����,�����Sigmoid��tanh,ReLU��Leakly ReLU���������ݶ�������˳��,ѵ�����������ø��졣
����ṹ���
����Ҫ�ö��ٸ�����,ÿ������Ҫ���ö��ٸ���Ԫ,��û��һ��ͳһ�Ĵ𰸡����ݷ�����������׳̶�������������ģ�͵ĸ��ӳ̶ȡ���������Խ��,������Ƶ�������ṹ��Ӧ��Խ��,Խ��������,��Ҫע����Ƕ�ѵ�������ྫ����ߵ�ȫ����������ģ��,����ʵ������ʶ������δ������õ�(�����)��

��ͼ��֪��Ԫ����Խ��,�ֽ���Ϳ���Խ����,����������ϵķ���������Խǿ��
SOFTMAX
? �ڼ���������ĵ÷ֺ�,���ǿ���ͨ��softmax�������õ��ķ���ת���ɸ��ʷֲ���
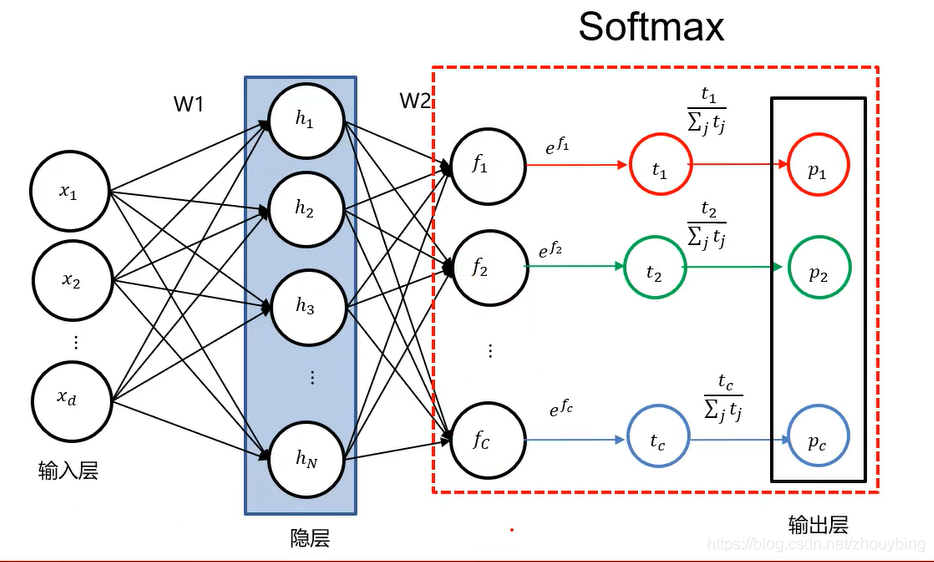
��ͼ��ʾ,�Ƚ��õ��ķ���ȡe��ָ���õ�t,�ټ����t�ĸ���,�͵õ��˽���softmax�������µ������,��ʾΪ���ʡ�
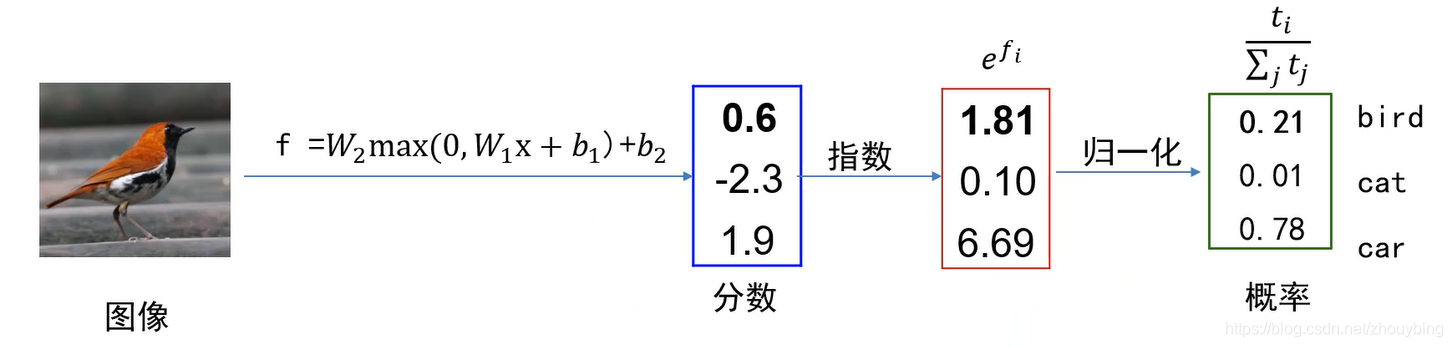
��������ʧ
?��ͨ��softmax������,����Ҫ��μ�����ʧ��,��ͼ��
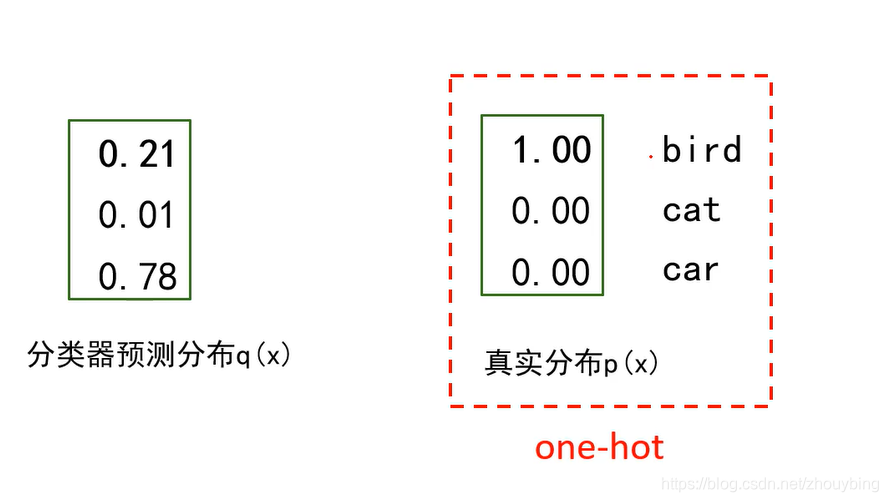
��softmax�����������ʧ����Ҫ���������Ԥ��ֲ�����ʵ�ֲ��ľ���,��Ҫ�õ������ء�
��
:
H
(
p
)
=
?
��
x
p
(
x
)
l
o
g
p
(
x
)
��
��
��
:
H
(
p
,
q
)
=
?
��
x
p
(
x
)
l
o
g
q
(
x
)
��
��
��
:
K
L
(
p
�O
�O
q
)
=
?
��
x
p
(
x
)
l
o
g
q
(
x
)
p
(
x
)
\begin{aligned} ��:H(p)=-\sum_xp(x)logp(x)\\ ������:H(p,q)=-\sum_xp(x)logq(x)\\ �����:KL(p||q)=-\sum_xp(x)log\frac{q(x)}{p(x)} \end{aligned}
��:H(p)=?x��?p(x)logp(x)������:H(p,q)=?x��?p(x)logq(x)������:KL(p�O�Oq)=?x��?p(x)logp(x)q(x)??
���������Ҳ��KLɢ��,�����������������ֲ�֮��IJ������ԡ���Ϊʲô���������Dz�ʹ������ض�ʹ�ý�����,�Խ����ر���:
H
(
p
,
q
)
=
?
��
x
p
(
x
)
l
o
g
q
(
x
)
=
?
��
x
p
(
x
)
l
o
g
p
(
x
)
?
��
x
p
(
x
)
l
o
g
q
(
x
)
p
(
x
)
=
H
(
p
)
+
K
L
(
p
�O
�O
q
)
\begin{aligned} H(p,q)=-\sum_xp(x)logq(x)\\ =-\sum_xp(x)logp(x)-\sum_xp(x)log\frac{q(x)}{p(x)}\\ =H(p)+KL(p||q) \end{aligned}
H(p,q)=?x��?p(x)logq(x)=?x��?p(x)logp(x)?x��?p(x)logp(x)q(x)?=H(p)+KL(p�O�Oq)?
����Ϊ��ʵ�ֲ�������,�ɵ�
H
(
p
)
H(p)
H(p)?Ϊ0,Ҳ���ǽ��������������one-hot��ʽ�µ���ʵ�ֲ�������ȵġ�
��������ʧ�����֧����������ʧ�Ƚ�

�۲�ڶ�������,��������������ʧΪ0,����������������ʧΪ0.2����е��,Ϊʲô��,��Ϊ���ݶ���Ĺ���ֻҪ��ʵ�ķ����������ķ���������1����Ϊ��ʧΪ0,�ڵڶ�����10ǡ�ñ�������������1,��˶�������������ʧΪ0,�����ڽ�����˵,�Ǹ��ݸ��ʷֲ���������ʧ��,��10�����з�����ռ�ı��ؾͱ�0.3��һ��,�����������ʧ��Ȼ��0Ҫ��һЩ����˿��Կ��������ز�����Ҫ����ʵ��ǩ��Ӧ�ķ���Ҫ�����Ļ�Ҫ�����Ӧ�ķ���ռ�ı���Ҫ��,Ҳ���������ķ���ҪС��
����ͼ�뷴��
? ����ͼ��һ������ͼ,��������������,����Լ��м����֮��ļ����ϵ,ͼ�е�ÿ���ڵ��Ӧ��һ����ѧ���㡣

��ν�������ǴӺ���ǰ����ֲ��ݶ�,��������ʽ����һ������������յ��ݶȡ����硣
f
(
w
,
x
)
=
1
1
+
e
w
0
x
0
+
w
1
x
1
+
w
2
f(w,x)=\frac{1}{1+e^{w_0x_0+w_1x_1+w_2}}
f(w,x)=1+ew0?x0?+w1?x1?+w2?1?
�ļ���ͼ��
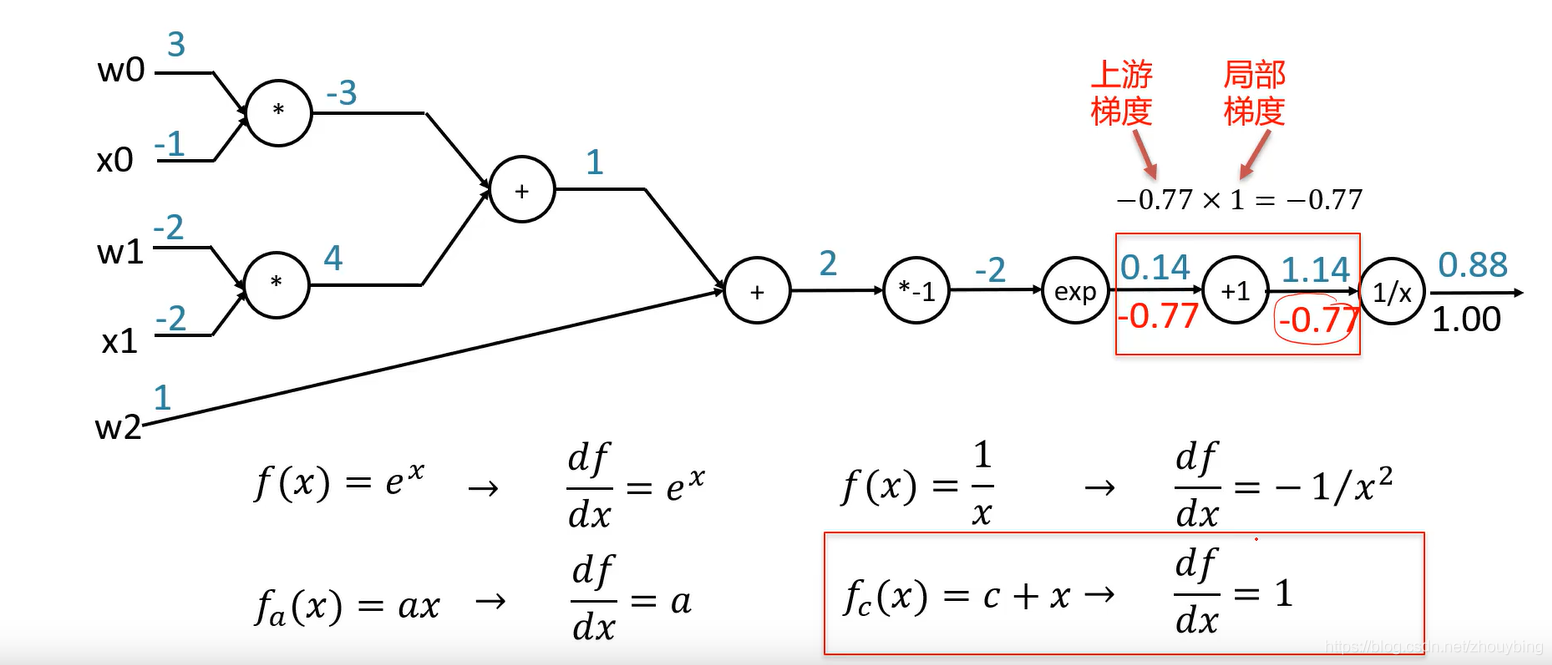
�ݶ��㷨�ĸĽ�
? �ݶ��½��㷨������ɽ�ڼ���,���ȵ�����н�������
������
?�����ۼ���ʷ�ݶ���Ϣ�����ݶ�

�������л����ܰ��Ѿֲ���С��Ͱ���,�ﵽȫ����С�㡣
����Ӧ�ݶ���RMSProp
? ����Ӧ�ݶȷ�ͨ����С����Ěi��,����ƽ̹����i������С��,����ͨ���ȵķ�����ô��Ҫ����������ƽ̹����,������Ϊ�ݶȷ��ȵ�ƽ���ϴ�ķ���������,�ݶȷ��ȵ�ƽ����С�ķ�����ƽ̹����
AdaGrad

AdaGrad��һ������Ӧ���ݶ��㷨�����������,��ô�ݶȵ�ƽ���ͻ�ϴ�,��Ӧ��r�ͻ��,���ѧϰ�ʾͻ�С,�i��Ҳ��С��,��֮ͬ������������㷨Ҳ����һ��ȱ��,��Ϊr��һֱ���ۼ�,��һֱ�������,��rԽ��Խ��,ѧϰ�ʾͻᱣ�ֺ�С,Ҳ��ʧȥ�˶Ԛi���ĵ�������
RMSProp

��AdaGrad�Ļ����ϸ�r������˥����
ADAM
?ADAM����˶�����������Ӧ�ݶȵ�˼�롣

ע����ADAM�д�������ƫ���һ������,����Ϊ�˽��������������,��ν�������������㷨ִ�еij���,v��r����0,�ݶȺ��ݶȵ�ƽ����Ȩ�ض���С,��ôһ��ʼv��rһ����һ����С��ֵ,�����Ļ��������㷨������,�����Ҫ����v��r,t������������,�ʼtΪ1,v��r������һ��С��0����,�ͻ�Ŵ�v��r��ֵ,�Ϳ������㷨�ܿ����������,�ȵ�������κ�,tһֱ����,�����ķ�ĸ�IJ��־�����1,�����������v��r�ͽӽ�ԭ����v��r��