这里写目录标题
机器学习
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。

特征工程

特征提取
将任意数据(如文本或图像)转换为可用于机器学习的数字特征
特征预处理
通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
特征降维
指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
机器学习算法分类
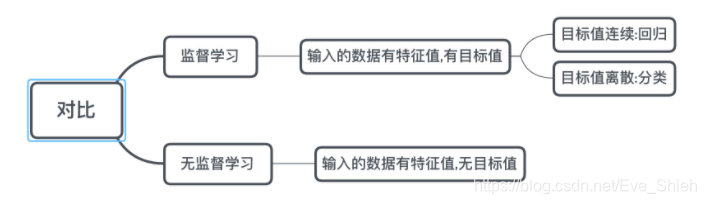
监督学习
定义:
输入数据是由输入特征值和目标值所组成。
函数的输出可以是一个连续的值(称为回归),
或是输出是有限个离散值(称作分类)。
非监督学习
定义:
输入数据是由输入特征值组成,没有目标值
输入数据没有被标记,也没有确定的结果。样本数据类别未知;
需要根据样本间的相似性对样本集进行类别划分。
有监督,无监督算法对比:
半监督学习
定义:
训练集同时包含有标记样本数据和未标记样本数据。
强化学习
主要包含五个元素:agent, action, reward, environment, observation;
强化学习的目标就是获得最多的累计奖励。
模型评估
分类模型评估

回归模型评估


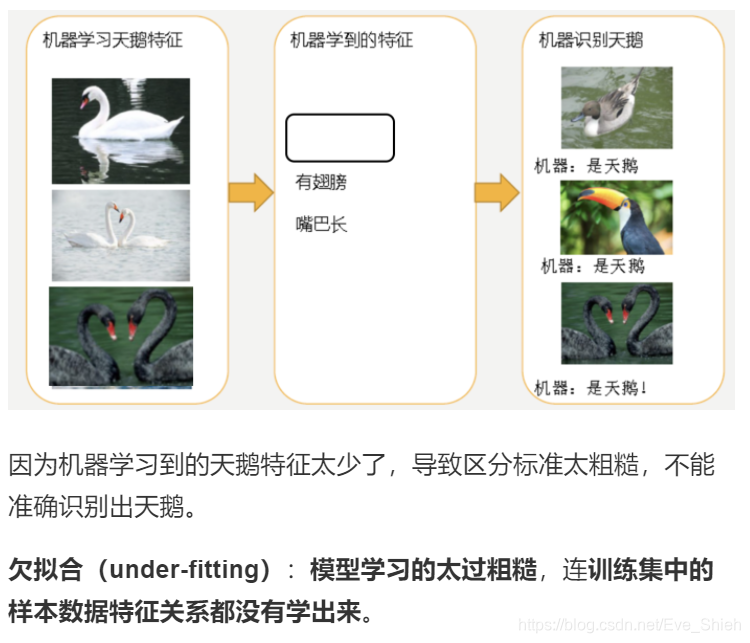
欠拟合
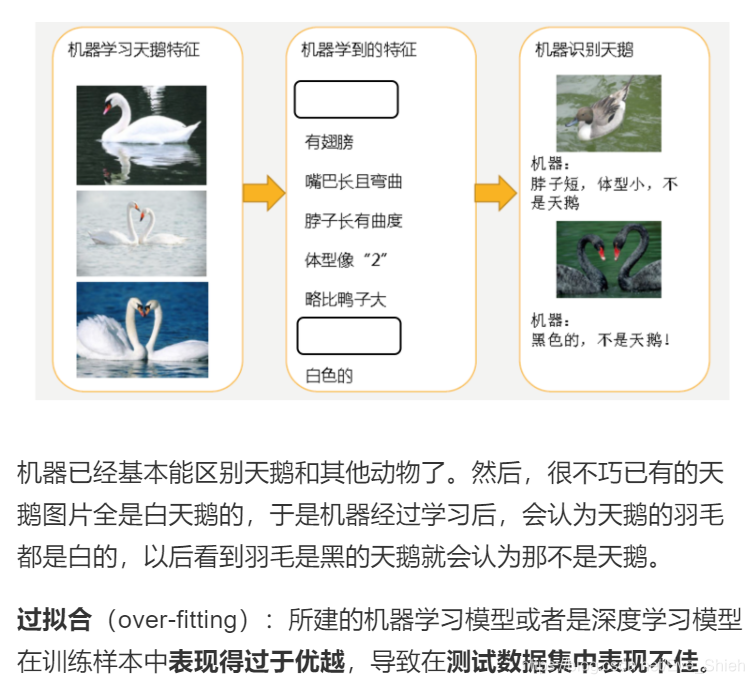
模型评估用于评价训练好的的模型的表现效果,其表现效果大致可以分为两类:过拟合、欠拟合。
过拟合
Matplotlib、Numpy、Pandas
Matplotlib
数据可视化