周学习笔记(2021.7.19-2021.7.25)
7.19
1. Colab 画图中文为乱码
(1)安装字体包
!gdown --id 1fsKERl26TNTFIY25PhReoCujxwJvfyHn
import matplotlib as mpl
zhfont = mpl.font_manager.FontProperties(fname='SimHei .ttf')
(2)调用绘图函数时设置对应属性(双引号引用中文,且前面用u)
fig2=plt.figure(2)
fig2.set(alpha=0.2)
label_0 = train.gender[train.label == 0].value_counts()
label_1 = train.gender[train.label == 1].value_counts()
df=pd.DataFrame({u'购买':label_1, u'未购买':label_0})
df.plot(kind="bar",stacked=True)
plt.xlabel(u"性别",fontproperties=zhfont) #负责横坐标
plt.ylabel(u"人数",fontproperties=zhfont) #负责纵坐标
plt.title(u"性别购买情况",fontproperties=zhfont)
plt.legend(prop=zhfont) #负责图例
#plt.show()

博客搜索最多的解决方案
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号#有中文出现的情况,需要u'内容'
2. python 函数
函数头括号里的形参可以不声明变量类型
3. 得到字典中最大值对应的键
4. 离散数据编码
5.表示学习
6. 数据EDA
如果使用 LGB 等树模型可以直接空缺,让树自己去优化
很多模型对nan有直接的处理,不需要额外填充缺失值
7.20
1.机器学习中的偏差和方差
偏差指的是算法在大型训练集上的错误率;方差指的是算法在测试集上的表现低于训练集的程度。
2. GBDT
CatBoost和XGBoost、LightGBM并称为GBDT的三大主流神器,都是在GBDT算法框架下的一种改进实现
3. 高基数类别特征 catogory_encoder
(1)目标编码
(2)平均数编码
(3)留一法编码
4.何时不需要编码
将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码。(如Titanic中的age特征)
有些基于树的算法在处理变量时,并不是基于向量空间度量,数值只是个类别符号,即没有偏序关系,所以不用进行独热编码。 Tree Model不太需要one-hot编码: 对于决策树来说,one-hot的本质是增加树的深度。
5. python 字符串连接
6.欠采样和过采样
7. dataframe获得列名和行名称
dfname._stat_axis.values.tolist() # 行名称
dfname.columns.values.tolist() # 列名称
8. drop()的使用
drop() 删除行和列
drop([ ],axis=0,inplace=True)
- drop([]),默认情况下删除某一行;
- 如果要删除某列,需要axis=1;
- 参数inplace 默认情况下为False,表示保持原来的数据不变,True 则表示在原来的数据上改变。
7.21
1.python相关
(1)list.index() 用于从列表中找出某个值第一个匹配项的索引位置
(2)line.strip() 去掉每行头尾空白
(3) 可以复用的封装函数放在上面,即xxx外面,但是针对本程序执行的代码需要放在此判断条件里面,表示不被其他引言该模块的代码执行

2. C++相关
(1)两种定义常量方式
- 使用 #define 预处理器 #define 大写变量名 数值
- 使用 const 关键字 const 变量类型 变量名=数值
(2)在函数声明中,参数的名称并不重要,只有参数的类型是必需的
(3)^ 不表示次幂,表示异或操作;次幂使用pow( , )
(4)vector能够存放任意类型元素
(5)使用迭代器访问vector
Vector<int> c
for(auto it=c.begin();it!=c.end();it++){
Cout<<*it;
}
(6)
vector<string> s 单向量
vector<string> s[5] 向量数组
(7) cin.getline(s1,10000)
可以接收空格;三个参数,依次是接受字符串的变量、接收字符的个数、结束字符。当第三个参数省略时,系统默认为’\0’
(8)strlen 计算字符串的长度,以结束符0x00 为字符串结束,头文件为string.h
? sizeof() 计算的则是分配的数组 str[20]所占的内存空间的大 小,不受里面存储的内容改变
char str[20]='0123456789';
int a =strlen(str); //a=10
int b=sizeof(str); //b=20
3. 大二上学业知识
(1)操作系统
- 安全性算法vs死锁检测算法
安全性算法对应的结论:安全状态或者不安全状态
死锁检测算法对应的结论:死锁或者不死锁
- 相关进程vs无关进程
如果一个进程的执行不影响其他进程的执行,且与其他进程的进展情况无关,即它们是各自独立的,则说这些并发进程的相互之间是无关的。显然,无关的并发进程一定没有共享的变量,它们分别在各自的数据集合上操作
如果一个进程的执行依赖其他进程的进展情况,或者说,一个进程的执行可能影响其他 进程的执行结果,则说这些并发进程是相关的
(2)计算机系统组成
- 常用换算
1KB=2^10B
1MB=2^10KB
1GB=2^10MB
1TB=2^10GB
- two’s complement representation 两位补码表示
- IEEE 754
标准格式包括数符―阶码(含阶符)―小数点―尾数
基数为2
用移码表示阶码(与补码相差一个符号位)
用原码表示尾数
根据原码的规格化表示,最高数字为总是1,该标准将这个1默认存储3
短实数(单精度数)――符号位1位,阶码8位,尾数23位
长实数(双精度数)――符号位1位,阶码11位,尾数52位
- 定点表示&浮点表示
小数点位置是否固定,分为定点数与浮点数
定点机分为小数定点机和整数定点机,两种定点机在原码/补码/反码上均有表示数的范围
浮点数表示包括阶符、阶码、数符、尾数
? 注:尾数位数反映精度,阶码位数反映表示范围,阶符和数 符共同反映小数点位置
基数不同,浮点数的规格化形式不同
基数越大,可表示的浮点数的范围越大,精度越低
- 有关定点数、浮点数的计算题
1)题目叙述
将某数表示成二进制定点数和浮点数,
并写出它在定点机和浮点机中的三种机器数及阶码为移码,尾数为补码的形式
其中数值部分均取 10 位,数符取 1 位,浮点数阶码取 5 位(含1位阶符)2)具体解法(例题)
二进制形式――根据寄存器位数要求分别写出定点表示(在二进制基础上)――浮点规格化表示
符号(规格化的尾数)x 2^阶码――定点机原/补/反――浮点机原/补/反――阶码移码尾数补码
- 易混概念
微命令:控制部件通过控制线向执行部件发出各种控制命令
微指令:一组可以实现一定操作功能的微命令的组合
微操作:相对于指令完成的功能而言的,指的是一个部件能够完成的基本操作
微程序:一条机器指令的功能是由许多条微指令组成的序列来实现的,这个微指令序列通常叫做微程序
4. RNN & LSTM &双向LSTM
1)RNN 链式多次复制同一神经网络
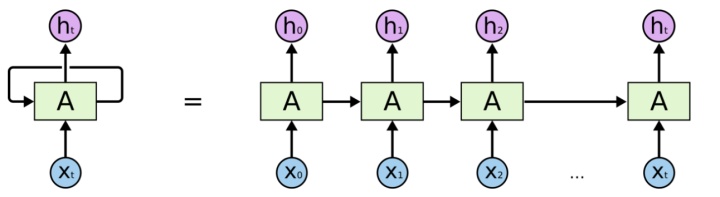
关键在于连接先前的信息到当前的任务上,但相关信息和预测的词位置之间的间隔应该是很小的。随着间隔不断增大,RNN会丧失学习到连接如此远的信息的能力
2)改进――LSTM网络 遗忘门\更新门\输出门
3)再度改进――双向LSTM网络,因为有的时候不能只靠前面的信息推测,还需要综合后面的信息
5. 定积分的分部积分公式
∫ a b u d v = [ u v ] a b ? ∫ a b v d v \int_a^budv=[uv]_a^b-\int_a^bvdv ∫ab?udv=[uv]ab??∫ab?vdv
6. PTA相关
Map<int,int> 是数组的升级版,如果int a[0xffffff]肯定不行,但是map可以。
7. 模型参数和超参数
模型参数是在模型训练时学习的,不能任意设置
超参数是用户在训练机器学习模型前可以设置的参数
随机森林中超参数的例子有:森林中拥有的决策树的数量、每次分割时需要考虑的最大特征数量,或者树的最大深度
8. k-fold交叉验证
只将数据分成一组训练数据和一组验证数据,则模型性能指标高度依赖于这两组数据
机器学习模型只进行一次训练和评估,则性能就取决于那一次评估。而且在对同一数据的不同子集进行训练和评估时,学习模型的表现可能会非常不同,这仅仅是因为选取的子集不同。
如果我们把这个过程分解为多次训练和验证测试,每次训练和评估我们的模型都是在不同的数据子集上,最后在多次评估中观察模型的平均表现
9. 贝叶斯优化
一种更好的超参数调优方法
10. 缺失值的处理方式

11. loc & iloc
data.loc[逻辑表达式,属性列名]=赋值
loc 是 location 索引可以用列名,也可以用序号
iloc 中的i是integer,索引只接受序号
行和列之间是逗号,连续索引用冒号,非连续索引用列表
data.loc[:,'列一'] #取出所有行第一列,loc可以理解为传入两个参数一个是关于行的,一个是关于列的。
data.loc[:,['列一','列四','列三']] #取出所有行多列,就把列名包裹成列表的形式。
data.loc[0:5,['列一','列四','列三']] #取出某几行某几列,把行索引和列名传入。
data.loc[data['列四']==138,['列二','列三','列四']] #loc的条件筛选
data.iloc[:,1:4]
data.iloc[3,[1,5]] #返回索引为3的行,索引为1和5的列。
data.iloc[1:8,[1,5]] #取出索引为1到7的行,索引为1和5的列。
data.loc[0:3] #按照名称取数据
data.iloc[0:3] #按照位置取数据
12. sklearn 常用模块
preprocessing模块:预处理
metrics模块:评价指标
13. 常见的填充方法
(1)填充固定值
选取某个固定值/默认值填充缺失值。
train_data.fillna(固定值, inplace=True) # 填充 0
(2)填充均值
对每一列的缺失值,填充当列的均值。
train_data.fillna(train_data.mean(),inplace=True) # 填充均值
(3)填充中位数
对每一列的缺失值,填充当列的中位数。
train_data.fillna(train_data.median(),inplace=True) # 填充中位数
(4)填充众数
对每一列的缺失值,填充当列的众数。由于存在某列缺失值过多,众数为nan的情况,因此这里取的是每列删除掉nan值后的众数。
train_data.fillna(train_data.mode(),inplace=True) # 填充众数,该数据缺失太多众数出现为nan的情况
正确写法:train_data.Embarked[train_data.Embarked.isnull()] = train_data.Embarked.dropna().mode()
这是针对具体某个属性
具体某个属性有两种写法,一种是train_data.Embarked,另外一种是train_data[‘Embarked’]
14. 数挖竞赛相关
拿到二分类问题首先应该关注样本正负比例是否平衡
替换数据中的缺失值为常规缺失值
train['age'].replace('-', np.nan, inplace=True)
15. .count() & .sum() & .value_counts()
(1) count()
str.count(‘char’,start,end) 统计字符串里某个字符出现的次数
list.count(obj) 统计列表里某个元素出现的次数
dataframe.count(axis=0/1) 计算每列或每行的非na单元格 默认为0 (统计一整列) 1则为统计一整行
附:len(data[‘age’]) 展示该列行数,na也统计在内
(2) sum()
data.sum() axis=0 计算每列和 axis=1 计算每行和

16. 分类&回归常见的评估指标
- 对于二类分类器/分类算法,评估指标主要有accuracy,[Precision,Recall,F-score,Pr曲线],ROC-AUC曲线
- 对于多类分类器/分类算法,评价指标主要有accuracy, [宏平均和微平均,F-score]
- 于回归预测类算法,评价指标主要有平均绝对误差(Mean Absolute Error,MAE),均方误差(Mean Squared Error,MSE),平均绝对百分误差(Mean Absolute Percentage Error,MAPE),均方根误差(Root Mean Squared Error), R2(R-Square)
17. bug――" ‘tuple’ object is not callable"
import pandas as pd
data=pd.DataFrame(columns=['a','b'],data=[[1,2],[1,4],[1,],[3,1]])
data

data.shape #(4,2)
data.shape() #不可以
data.shape[0] #4
18. np.nan
np.nan 和 None 的区别
19. 可视化
(1)直方图
plt.hist(train_data['price'], orientation='vertical', histtype='bar', color='red')
plt.show()
(2)plt.figure()
主要参数为figsize figsize=() 指定宽和高,单位为英寸
(3)sns.kdeplot()
(4)sns.distplot() 核密度+直方图
(5)data[‘age’].skew()
偏度(skewness),是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征
(6)data[‘age’].kurt()
峰度
20. any()
df.isnull().any()则会判断哪些”列”存在缺失值
any 实现了 “或” 运算,all实现了“与”运算
由于isnull() 会在缺失值处返回true,所以凡是出现缺失的列都会被筛出来
7.22
1. format格式化 & f_string
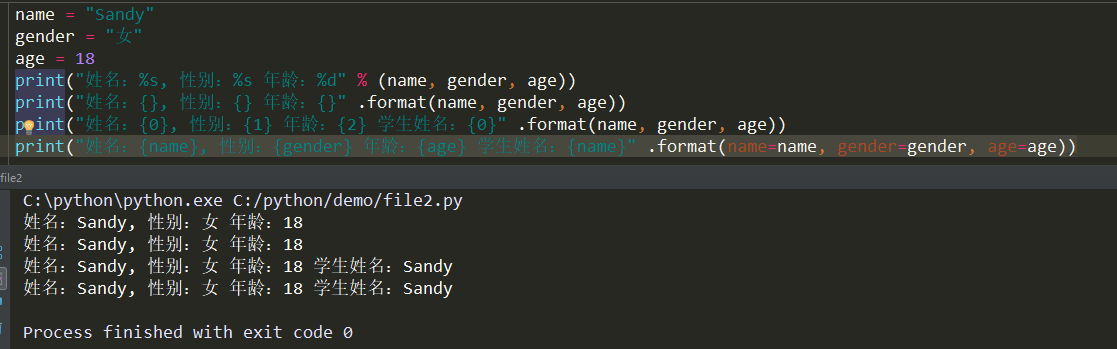
>>> number = 7
>>> f'My lucky number is {number}'
'My lucky number is 7'
2. .endswith()
判断字符串是否以指定字符或子字符串结尾,返回值为布尔类型
str.endswith(“suffix”, start, end) 或 str[start,end].endswith(“suffix”)
3. df.dtypes & astype() & .select_dtypes()
(1)df.dtypes 只能看属性类型,但是info() 可以看很多
(2) astype() 用于改变类型
(3)直接选择数字型或类别型的属性
DataFrame.select_dtypes(include=None, exclude=None)
适用于没有直接label encoding的数据
numeric_features = Train_data.select_dtypes(include=[np.number]) #数字特征
categorical_features = Train_data.select_dtypes(include=[np.object]) #类别特征
4. set_index(’’) & reset_index()
将表格中自动生成的从0开始的行序号换掉,换成表格中的一列数据

import pandas as pd
df1 = pd.read_excel("demo.xlsx")
print(df1.set_index('编号'))

5. GBDT
Gradient Boost Decision Tree(梯度提升决策树)
对于LightGBM和Xgboost,不需要处理None的缺失值
对于不合理的数据,做一个降低权重的处理(对LightGBM而言,见参数sample_weight)
6. 特征选择
xgb模型特征重要性输出+Boruta特征选择法
Boruta采用随机森林的办法抽取特征、打乱特征顺序计算特征的重要性
Boruta的目标就是选择出所有与因变量相关的特征集合,而不是针对特定模型选择出可以使得模型cost function最小的特征集合。Boruta算法的意义在于可以帮助我们更全面的理解因变量的影响因素,从而更好、更高效地进行特征选择。
Boruta算法思想:
将原特征real features进行shuffle构造出shadow features,将real features与shadow features拼接作为特征矩阵进行训练,最后以shadow features的feature importance得分最为参考base, 从real features中选出与因变量真正相关的特征集合。
7. 样本增强
针对小样本
8. 数据预处理
(1)错误数据
EDA发现,将其删除或者将其当缺失值。很正常,可能存在记录异常,还有比较难判断的异常值,利用统计分布,3sigma原则等对于数据进行异常值识别,在识别出异常情况后分析对应是真实异常还是记录异常等
(2)模型相关
线性类的模型,需要对类别特征进行特殊处理,连续的值也需要进行简单的Normalize,方便模型更好的吸收数据
GBDT类的模型,需要考虑特征的相对大小,而不需要过多处理缺失值
(3)结构性的文本类数据展开;时间序列类将数据进行pivot操作
(4)产生新变量:用户月均、年均消费金额和消费次数;家庭人均年收入;用户在线交易终止的次数占用户在线交易成功次数的比例;用户下单付费的次数占用户下单次数的比例;用户在制定商品类目的消费金额占其他全部消费金额的比例
(5)改善数据分布特征
通过取对数,开平方根,取倒数,开平方,取指数的方法使得不对称分布的数据呈现(或近似)正态分布,并形成倒钟形曲线
(6)分箱转换
当自变量与因变量之间有比较明显的非线性关系时,分箱操作可用于探索和发现这些相关系性
(7)标准化转换
离差标准化
0-1均值化
(8)归一化
为了消除不同特征之间不同量纲差异的一种方式,而归一化方式也有多种,比如0-1归一化,最大值归一化,也有做log特征分布调节等等,各种方式达到的效果也不同
(9)去噪
部分比如电力负荷数据可能存在高频噪声,用傅里叶或者小波去噪有时会达到不错的效果
(10)逻辑清洗
去重
删掉极端值
9. 缺失值的处理
(1)对于NN或者lr等模型而言,一般需要对缺失值进行填补
(2)数值特征取mean(),类别特征取mode()
(3)若已知缺失值和某些特征存在很强的关联,也可以做关联填充
例如体重缺失的时候,使用身高^2 * 系数的方法填充
(4)有时缺失值本身可能存在意义,也可以额外增加一列isnull特征,从而保留该信息
(8)填充KNN数据
from fancyimpute import KNN
data_x=pd.DataFrame(KNN(k=6).fit_transform(train_data_x), columns=features)
10. 收敛&泛化能力
收敛是指这个算法有能力找到局部的或者全局的最小值,一般形容基于梯度下降算法的模型
泛化能力是指一个机器学习算法对于没有见过的样本的识别能力
11. 过采样 & 欠采样――SMOTE
12. sklearn中的pipeline
封装流水线
- 对数据正态化时, 为了防止数据泄露, 采用“Pipeline”来正态化数据和对模型进行评估(慢慢品)
13. ubuntu
操作系统
14. df.melt()
df.melt() 是 df.pivot() 逆转操作函数
将列名转换为列数据(columns name → column values),重构DataFrame
如果说 df.pivot() 将长数据集转换成宽数据集,df.melt() 则是将宽数据集变成长数据集
7.23
1. 长尾分布
图片参考:知乎魏秀参
长尾分布在某种程度上可以说是比正态分布更加广泛存在的一种自然分布,头部几类更为常见,数量较多

2. 数据分箱
-
缺失值单独一个箱
-
逻辑回归中进行分箱是非常必要的,其他树模型可以不进行分箱
-
分箱一般都是针对连续型数据(如价格、销量、年龄)进行的。但是从理论上,分箱也可以对分类型数据进行。比如,有些分类型数据可取的值非常多,像中国的城市这种数据,这种情况下可以通过分箱,让已经是离散型的数据变得更加离散,比如,城市可以被划分为一级城市、二级城市、三级城市,或者把垃圾分为有害垃圾、可回收垃圾、湿垃圾、干垃圾等等
-
优点
模型的鲁棒性和稳定性增强
过拟合性降低
泛化能力增强
加快模型的训练速度
把一个特征离散为N个哑变量(Dummy Variable)之后,每一个哑变量就会产生一个单独的权重,相当于为模型引入非线性,进而提升模型表达能力,加大模型拟合能力
-
卡方分箱
以卡方验证为基础衍生,对两个相邻的区间进行卡方验证,验证是否存在分布上的差异
-
应用
分箱操作一般只在分类问题中进行,在分类问题中,对逻辑回归算法,分箱是极为重要且必须的。而对于树模型,如lightGBM、XGBoost等模型,分箱不是一个必须操作,但是却能够预防模型的过拟合并使模型的稳定性更好。
就是分类问题中的逻辑回归(LR,Logistic Regression)算法。之所以它必须用分箱,原因是逻辑回归的本质是线性模型,如果不进行分箱,不只特征的鲁棒性会极差,而且会导致模型的倾斜,很可能无法产生很好的结果。
而树模型(lightGBM、XGBoost等)对所有的输入特征都当做数值型对待,如果是离散型的数据,是需要进行One-Hot编码的,即将特征转化为哑变量(Dummy Variables)。因此分箱不是必须的,但是分箱仍然可以帮助模型预防过拟合。需要注意的只是,分箱后,还是需要把数据进行哑变量处理的。
4. 插值法
根据现有的数据点,构造函数,增加数据
5. pd.cut() & pd.qcut()
通用参数:data 待分组的数据;n 分成几组
-
pd.cut() 等距分箱
-
pd.qcut() 等频分箱
6. L1正则化 & L2正则化
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型叫 做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
7. 自回归问题
回归是建立模型,是输入输出之间的固定关系。而自回归是时间序列模型,训练得到的模型表示了随时间变化的 y 之间的相互依赖性与相关性
未来的一个时点可以用之前的时点来进行回归预测,还是那一串数字,但是时间状态不同了,存在不同阶的时滞
8. np.random.randn() & np.random.rand() & np.random.randint()
(1)np.random.randn()
返回一个或一组服从标准正态分布的随机样本值
没有参数返回一个浮点数;有一个参数返回秩为1的数组;有两个或两个以上参数则返回对应维度的数组
(2)np.random.rand()
返回一个或一组服从0-1均匀分布的随机样本值 [0,1)
(3)np.random.randint()
函数原型:np.random.randint(low,high=None,size=None)
返回随机整数或整型数组,范围区间为[low,high),如果high没有填写,则默认生成随机数的范围是[0,low)
9.损失函数 & 目标函数 & 代价函数
-
基本概念
损失函数:计算的是一个样本的误差
代价函数:是整个训练集上所有样本误差的平均
目标函数:代价函数 + 正则化项
10. 最小二乘
7.24
1. 方差和偏差
Bias是用所有可能的训练数据集训练出的所有模型的输出的平均值与真实模型的输出值之间的差异。
Variance是不同的训练数据集训练出的模型输出值之间的差异。
噪声的存在是学习算法所无法解决的问题,数据的质量决定了学习的上限。假设在数据已经给定的情况下,此时上限已定,我们要做的就是尽可能的接近这个上限。
2. np.quantile()
3. plt.subplot() & add_subplot()
(1)plt.figure 绘制一张图片,有返回值
fig=plt.figure(figsize=(4,3),facecolor=‘blue’)
(2)subplot 创建单个子图,无返回值
plt.subplot(221) 分成两行两列第一个子图
(3)plt.plot()
(4)subplots创建多个子图,有两个变量的返回值
fig,axes=plt.subplots(2,2)
ax1=axes[0,0]
ax2=axes[0,1]
ax3=axes[1,0]
ax4=axes[1,1]
ax1.plot()
ax2.plot()
plt.show()
(5)add_subplot 给figure新增子图
fig=plt.figure()
ax1=fig.add_subplot(2,2,1)
4.[调参]贪心调参 网格调参 贝叶斯调参
网格搜索适合于小数据集,数据量比较大的时候可以使用一个快速调优的方法――坐标下降,一种贪心算法,拿当前对模型影响最大的参数调优。直到最优化;再拿下一个影响最大的参数调优,直到所有参数调整完毕
clf=GridSearchCV(model,parameters,cv=5)
bayes优化只能优化连续超参数,因此要加上int()转为离散超参数
5. 字典items()
返回元组列表
best_obj.items(), key=lambda x: x[1]
返回第二维数据,即values
6. cross_val_score()
返回模型的得分
7. 模型融合
加权融合这个一般适用于回归任务中模型的结果层面, 那么分类任务中使用投票法voting
7.25
')
(2)subplot 创建单个子图,无返回值
plt.subplot(221) 分成两行两列第一个子图
(3)plt.plot()
(4)subplots创建多个子图,有两个变量的返回值
fig,axes=plt.subplots(2,2)
ax1=axes[0,0]
ax2=axes[0,1]
ax3=axes[1,0]
ax4=axes[1,1]
ax1.plot()
ax2.plot()
plt.show()
(5)add_subplot 给figure新增子图
fig=plt.figure()
ax1=fig.add_subplot(2,2,1)
4.[调参]贪心调参 网格调参 贝叶斯调参
网格搜索适合于小数据集,数据量比较大的时候可以使用一个快速调优的方法――坐标下降,一种贪心算法,拿当前对模型影响最大的参数调优。直到最优化;再拿下一个影响最大的参数调优,直到所有参数调整完毕
clf=GridSearchCV(model,parameters,cv=5)
bayes优化只能优化连续超参数,因此要加上int()转为离散超参数
5. 字典items()
返回元组列表
best_obj.items(), key=lambda x: x[1]
返回第二维数据,即values
6. cross_val_score()
返回模型的得分
7. 模型融合
加权融合这个一般适用于回归任务中模型的结果层面, 那么分类任务中使用投票法voting
7.25
没学习