【ACL Findings 2021】《 Does Robustness Improve Fairness? Approaching Fairness with Word Substitution Robustness Methods for Text Classification》阅读笔记
英文标题:Unsupervised Label Refinement Improves Dataless Text Classification
中文翻译:鲁棒性可以提高公平性吗? ―基于词替换的鲁棒性文本分类方法
原文链接: https://arxiv.org/pdf/2106.10826.pdf
文章目录
Abstract
现存的来减少模型结果差异的去偏方法 主要集中在数据增强、在模型embedding上去偏或在训练过程中添加基于公平的优化目标。另外,经过认证的词替换鲁棒性方法被推广,以减少虚假特征和同义词替换对模型预测的影响。虽然二者的最终目标不同,但它们都是鼓励模型对当输入产生某些变化时做出相同的预测。在本文中,我们研究了被认证的词替换鲁棒性方法在提高多文本分类任务的概率等和机会等方面的效用。我们观察到,经过认证的鲁棒性方法提高了公平性,并且在训练中使用,对于鲁棒性和偏差缓解这两个方面都有改进。
一、Introduction
随着自然语言处理(NLP)技术越来越多地应用于必要的现实应用中,如社交媒体、医疗保健、个人助理和法律,必须确保这些系统不会最终为用户创造不确定的结果,或为来自不同背景的客户提供区别的体验。这包括确保不同的群体的模型表现没有显著差异,如不同的性别或种族。一些研究证明了NLP系统中的社会偏差,并提出了各种方法来减轻这种偏差。这些方法包括创建平衡数据集,开发针对特定公平概念优化的方法,模型校准,减少表征偏差。在这项研究中,本文重点关注违禁词(敏感词)分类和维基百科上的职业分类,确保公平性意味着确保模型可以在所有例子中识别出对相似准确性的违禁词,而不会被在例子中受保护的例子干扰。过去的研究表明,违禁词分类模型会错误地将包含某些受保护属性的文本分类为违禁词。领先的社交媒体平台和互联网公司使用违禁词性分类模型来内容审核,因此在这种模型中存在偏见可能导致弱势的群体禁言。同样,对于职业分类,一个公平的模式应该正确地识别职业,无论这个人是否属于弱势群体。
本文作者利用基于GloVe的CNN模型和Bert探讨了鲁棒性方法对公平性的影响。比较了这些鲁棒性方法与流行的去偏方法的在公平性方面的影响。
作者发现,在性别和性取向维度的一些文本分类任务中,鲁棒性方法在公平指标上取得了良好的性能,超过了去偏的方法。此外,在公平性和鲁棒性的联合训练性能超过了鲁棒性和偏差缓解方法的单独训练。综合分析和可视化表明,鲁棒方法降低了性别标记的特征重要性。作者总结自己的贡献如下:
- 我们证明了经过认证的鲁棒性方法可以被使用并与去偏方法相集成,以有效地提高模型在几种公平概念上的性能,特别是机会相等和概率相等的性能。
- 通过将鲁棒性方法与公平性相结合,我们可以在降低偏差的同时提高模型的鲁棒性,这对创建可靠的NLP系统具有重要意义。我们的研究的实际意义包括应用于行业中使用的模型,以处理可能与培训数据不同的客户输入(健壮),并尽量减少对客户的任何意外影响(公平)。通过这项研究,我们的目标是激励未来的工作,旨在开发联合优化模型的多个可信方面的方法;特别是那些解决模型鲁棒性和公平性的方法。
二.Notion
作者首先定义了本文中所考虑的公平性的概念。然后,我们讨论了经过认证的鲁棒性方法,与如何应用它们来减少模型中的偏差。
2.1公平性概念
在本文中,我们关注于衡量公平的两个概念――概率相等和机会相等,因为它们在NLP应用中常用于量化偏差。我们在第3节中描述了与这些概念相关的指标。我们给出了这些关于英语文本毒性和职业分类的应用例子。
- 概率相同:一个模型针对保护属性A和结果Y实现相等概率。对于y∈{0,1},如果P(Yˉ=1|A=0,Y=y)=P(Yˉ=1|A=1,Y=y),直观上说,这意味着该模型应该具有各组相同的真实阳性率和假阳性率。对于违禁词分类,相等的概率意味着一个模型应该能够有效地检测到违禁词即使它包含所有受保护属性队列的标识符,而不是屏蔽掉任何一个队列。先前的研究表明,模型不成比例地预测与LGBTQ相关的句子会有违禁词,这可能屏蔽掉LGBTQ问题讨论和LGBTQ的声音
个人理解: 当y的ground truth是1时,无论A是否受保护的属性,模型预测输出1或者0的情况概率相等。即A的变化不会对预测产生影响,真假阳率相等
- 机会相等: 如果P(Yˉ=1|A=0,Y=1)=P(Yˉ=1|A=1,Y=1),则保护属性A和结果Y实现机会平等(Hardt等人,2016)。这是一个均衡概率的正结果,其中模型必须在组间具有相等的真阳率。对于职业分类,机会平等意味着一个模型能够正确地分类所有群体人物的职业,从而使结果公平,如工作推荐网站的匹配算法。
个人理解: 当y ground truth为1时,无论A是否收到保护,模型预测输出y=1的概率都相等,即其真阳都相等(存疑,感觉这两个概念存在重叠,感觉是包含关系)
2.2 用认证过的鲁棒性方法来去偏差
为不同的目的而设计的,认证后的鲁棒性方法提出多种方法来训练模型,成功保证词替换后的鲁棒性。通过将经过认证的鲁棒性方法适应公平性的应用,我们的目标是使模型对输入中存在的虚假保护属性信息不变,从而提高机会相等和概率相等。
形式上,如果任何句子x,由单词替换修改组成句子x‘,f(x)=f(x’)=y,那么模型f肯定是稳健的。在上下文的鲁棒性上,单词替换包括交换一个词与其同义词(通常使用修改后的单词嵌入来定义)。例如,如果x=“服务员和顾客谈论他们的问题”,x‘可能包括“女服务员和顾客谈论他们的不安”。在公平的背景下,我们认为“服务员”和“女服务员”或性别代词在违禁词和职业分类中具有相同的含义,并有相同的标签。
在本文中,我们使用了两种最近开发的认证鲁棒性方法,间隔边界传播(IBP)(Jia等,2019)和safer的(Ye等,2020)。给定每个单词的一组扰动,这两个模型确保了单词替换不会影响模型的预测。
三.公平性与鲁棒性的联系
为了更好地理解文本分类中公平性和认证鲁棒性之间的联系,我们实证分析了用各种鲁棒性和公平性方法组合增强的模型,如下所示。
- 分类器(基线):基本文本分类模型。我们考虑了文献中广泛使用的两种分类模型,CNN和BERT。
- 分类器+公平性方法:使用去偏技术训练的文本分类器
- 分类器+鲁棒性方法:用鲁棒性方法训练的文本分类器
- 分类器+鲁棒性方法+性别词扰动:为了确保模型能够来对抗性别替代,我们在IBP的置换集中添加了定义的性别对(例如,她交换他)
- 分类器+鲁棒性方法+公平性方法:文本分类器训练加入公平性和鲁棒性的目标
我们的目标是基于上述配置来回答以下研究问题。
- 鲁棒性方法对去偏方法影响如何(将3与1和2进行比较)?
- 鲁棒性模型扰动集中添加性别词替换的效果有什么影响(比较3和4)?
- 集成偏差缓解和鲁棒性方法(将5与1和3进行比较)有何影响?。
特别是,为了回答最后一个问题,我们考虑将流行的公平性方法(去偏,实例权重,对抗)与IBP结合如下:
-
去偏词嵌入+IBP:我们用hardebias embedding取代了基线CNN模型中的Glove嵌入,同时保持IBP训练方法的其余部分不变。
-
实例权重+IBP:在IBP训练过程中,我们向损失计算中的每个样本添加实例权重。
-
对抗性训练+IBP:我们执行多任务训练,在优化鲁棒性损失和对抗性去偏置损失之间交替进行。我们用IBP训练的模型初始化了对抗性训练。
评估指标我们用三维方法来评估模型:
- 原始任务性能:ROC曲线(AUC)来评估模型的性能偏差
- 模型的公平性:鲁棒性精度(CRA)
- 模型的鲁棒性:使用真阳平等差异(TPED)和假阳平等差异(FPED)。FPED和TPED的计算结果为:
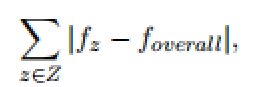
其中f是FPR或TPR取决于我们是计算FPED还是TPED,Z指的是受保护组中所有类的集合。注意,TPED和FPED度量没有考虑模型的性能――例如,对于所有组正概率达到0.的模型的TPED仍然为0。
针对本文的范围和数据集的局限性,我们研究了Bios中的bias的二元性别,以及性别(男性、女性、变性人)和性取向(同性恋/异性恋、异性恋、异性恋、女同性恋、女同性恋、双性恋)的拼图敏感词分类。虽然我们承认有许多重要的属性,但我们将本研究的范围限制在文本分类数据集中存在的属性中。
四 Experiment



五. Conclusion
作者提出了一个研究,研究了词替换鲁棒性方法对公平性的影响。作者在CNN和BERT中,添加IBP和safer等鲁棒性方法在训练比单独增加去偏的方法更能提高公平性指标。考虑到这些有作者鼓励未来使用鲁棒性方法的探索,不仅提高公平度量,而且优化公平性和鲁棒性,这是创建可信的NLP模型的两个重要方面。
未来的工作可能包括研究除性别和性取向以外的属性的鲁棒性和公平的影响,将我们的研究扩展到其他基于词替代的鲁棒性方法,以及探索更复杂的方法,在训练期间结合鲁棒性和缓解偏差的方法。我们还打算将研究扩展到研究隐私服务方法对鲁棒性和公平的影响