目录
原文地址:
https://arxiv.org/abs/1812.03982
代码地址:
https://github.com/facebookresearch/SlowFast
以下,大标题对应的是论文里的章节,但是论文的翻译我进行了一定的裁剪,加入了一些自己的理解。如果有困惑想要一探究竟的,可以评论留言,我们一起讨论一起学习,也可以多回去找找原文的解释和代码里的实现。
1. Introduction
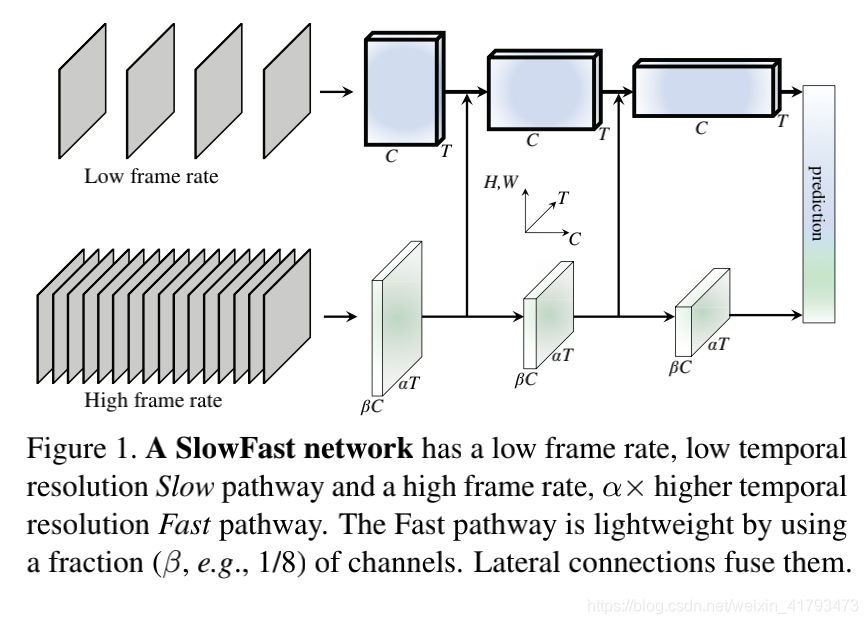
SlowFast网络用于视频识别。在视频处理领域中,动作分类和检测效果都很好。
它的特征就是,用快、慢两个通道,来分别以高帧率运行来捕捉运动信息,和以低帧率运行捕捉空间语义信息。
这是因为,空间的信息通常来说变换得缓慢。挥舞的手不会在挥舞动作的范围内改变其作为“手”的身份;不管一个人在一段视频内的动作是跑或是跳,他都是属于“人”这个分类。
所以希望识别类别相关的信息可以刷新的缓慢,而对于识别动作的信息刷新的快一点。
这一方法是受视网膜神经节细胞的原理启发。在这些细胞中,有约80%是P-cells,提供空间细节和色彩信息,较慢的时间分辨率,对刺激反应慢;约15-20%是M-cells,运行在较高的时间频率,对于快的变化反应灵敏,对空间、色彩信息不敏感。
所以SlowFast中,快通道即是模仿M-cells,轻量,被设计为捕捉更多的动作信息,更少的空间信息;慢通道同理即是模仿P-cells。
论文在Kinetics-400[30]、Kinetics-600[3]、Charades[43]和AVA[20]数据集上评估了SlowFast的方法。在Kinetics动作分类数据集上的综合消融实验证明了SlowFast的有效性。SlowFast networks在所有数据集上建立了一个新的SOTA,与文献中以前的系统相比有了显著的改进。
2. Related Work
Spatiotemporal filtering
动作可以表示为时空对象,并通过时空中的定向过滤来捕获,就像HOG3D[31]和长方体[10]所做的那样。3D ConvNets[48,49,5]将2D图像模型[32,45,47,24]扩展到时空域,以类似方式处理空间和时间维度。还有一些相关的方法侧重于使用时间步长进行长期滤波和合并[52、13、55、62],以及将卷积分解成单独的二维空间和一维时间滤波器[12、50、61、39]。
除了时空过滤或其可分离版本之外,我们的工作还通过使用两种不同的时间速度来更彻底地分离模组专业知识。
Optical flow for video recognition
有一个经典的研究分支专注于基于光流的手工制作的时空特征。这些方法,包括流直方图[33]、运动边界直方图[6]和轨迹图[53],在深度学习普及之前,在动作识别方面表现出了竞争性的表现。
在深层神经网络的背景下,双流方法[44]通过将光流视为另一种输入模式来利用光流。该方法已成为文献〔12, 13, 55〕中许多竞争性结果的基础。然而,考虑到光流是手工设计的表示,并且两种流方法通常不能与光流一起端到端地学习,因此在方法上是不令人满意的。
3. SlowFast Networks
(更多详细内容写在下篇,因为对我来说挺难的)
SlowFast网络可以被描述成是单流结构,在两种帧率上运行。
然而更好地反应P细胞M细胞的原理,还是把结构理解为一个慢通道、一个快通道,用横向连接融合成一个SlowFast网络。
4. Experiments: Action Classification
论文中使用标准评估协议在四个视频识别数据集上评估我们的方法。
对于动作分类实验,用Kinetics-400、Kinetics-600、Charades。
对于动作检测实验,使用AVA数据集。
训练
我们的基于Kinetics的模型是从随机初始化(“从头开始”)开始训练的,不需要使用ImageNet[7]或任何预训练。我们按照[19]中的方法使用同步SGD训练。详情见附录。
对于时域,我们从全长视频中随机采样一个片段(αT×τ帧),慢路径和快路径的输入分别为T帧和αT帧;对于空间域,我们从视频或其水平翻转中随机裁剪224×224像素,其中较短的一侧随机在[256,320]像素采样。
推论
按照通常的做法,我们从一个视频沿其时间轴统一采集10个剪辑。对于每个片段,我们将较短的空间侧缩放到256像素,并按照[56]的代码,进行3次256×256的裁剪以覆盖空间维度,作为完全卷积测试的近似值。我们对预测的softmax分数取平均值。
我们报告了实际的推理时间计算。由于现有论文对裁剪的推理策略不同,因此在空间和时间上都存在ping/clipping。与以前的工作相比,我们报告了推断时每个时空“视图”(带有空间裁剪的时间片段)的FLOPs以及使用的视图数。回想一下,在我们的例子中,推断时间-空间大小是2562(而不是2242用于训练),使用了10个时间片段,每个片段有3个空间裁剪(30个视图)。
数据集
Kinetics-400包括400个人体动作类别的240k培训视频和20k验证视频。
Kinetics-600包括600个类别的392k训练视频和30k验证视频。
我们报告了Top-1和Top-5 的classification accuracy分类准确率(%)。我们报告了single、spatially center-cropped clip的计算成本(in FLOPs)。
Charades包含157个类别的9.8k训练视频和1.8k验证视频,在一个多标签分类设置中,活动平均持续30秒。性能以平均精度(mAP)衡量。
【Top-1 Accuracy和Top-5 Accuracy】
(以下解释转载自网络):
我们知道ImageNet有大概1000个分类,而模型预测某张图片时,会给出1000个从高到低排名的概率,表示网络预测该图片属于各类的概率。Top-1 Accuracy是指排名第一的类别与实际结果相符的准确率。 Top-5 Accuracy是指排名前五的类别包含实际结果的准确率。
https://www.bbsmax.com/A/WpdKYgVAJV/
4.1. Main Results
Kinetics-400
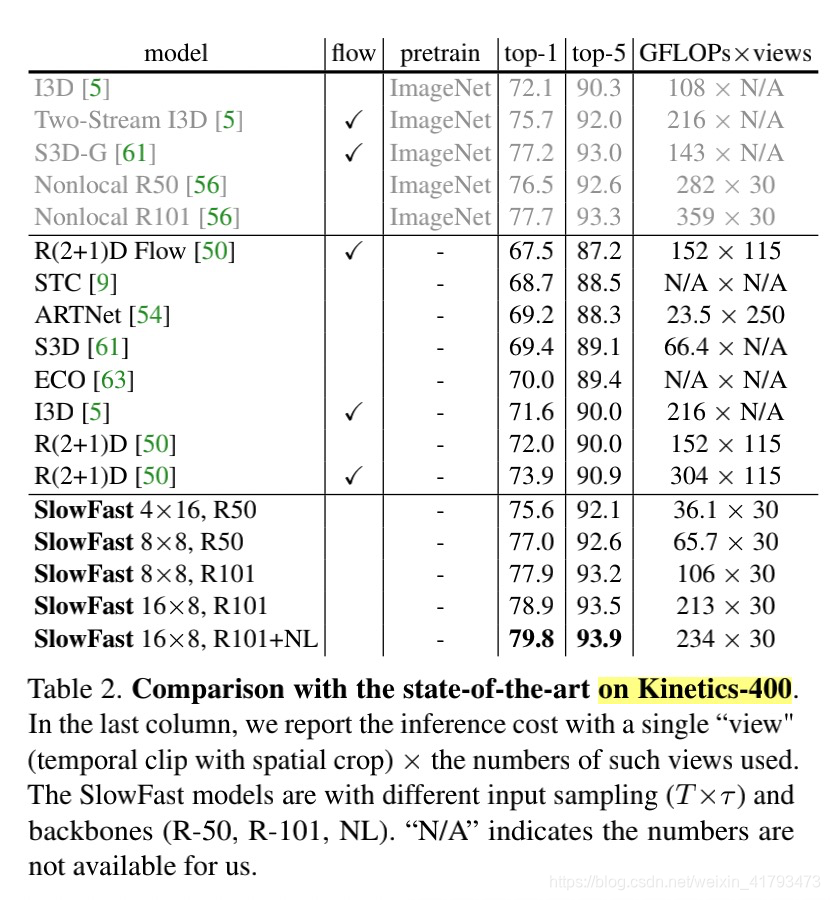
Table 2显示了论文中使用各种输入采样(T×τ)和主干网:ResNet-50/101(R50/101)和非局部(Nonlocal),进行的SlowFast的实例化的SOTA的比较。
怎么读下面这张表。
model
SlowFast T*τ, R50/R101/+NL
SlowFast模型具有不同的输入采样(T×τ)和主干(R-50、R-101、NL)
其他的SOTA模型,有标注相关的论文的,可以去原文点击跳转了解。
flow
optical flow。在论文第一章中提到: Our method does not compute optical flow, and therefore, our models are learned end-to-end from the raw data.我们的方法不计算光流,因此,我们的模型是从原始数据端到端学习的。估计这个flow指的是这个。
pretrain
Our models on Kinetics are trained from random initialization (“from scratch”), without using ImageNet or any pre-training.
top-1/top-5
Top-1 Accuracy是指排名第一的类别与实际结果相符的准确率 Top-5 Accuracy是指排名前五的类别包含实际结果的准确率
GFLOPs * views
In the last column, we report the inference cost with a single “view"(temporal clip with spatial crop) × the numbers of such views used.
在最后一列中,我们报告了单个“视图”(带有空间裁剪的时间片段)的推理成本×使用的此类视图的数量。
论文中对上表的结论:
- 与之前最先进的Nonlocal R101[56]相比,我们的最佳模型:SlowFast 16*8,R101+NL提供了2.1%的更高的top-1精度。
- 值得注意的是,我们的所有结果都比没有ImageNet预训练(即第三大横栏的结果都比第二大横栏的结果好)的现有结果要好得多。特别是,我们的模型(79.8%)比以前的最佳结果(73.9%)好5.9%。我们对Slowfast网络的ImageNet预训练进行了实验,发现预训练和从无到有训练(随机初始化)的性能相似(±0.3%)。
- 我们的结果实现了低的推理时间成本。我们注意到,许多现有模型使用沿时间轴的极密集的采样,这可能导致在推断时超过100个views(最后一列)。这一成本在很大程度上被忽视了。相比之下,我们的方法不需要很多时间片段,因为时间分辨率高但速度快。我们的每个时空视图的成本可能很低(例如36.1 GFLOPs),但仍然是准确的。
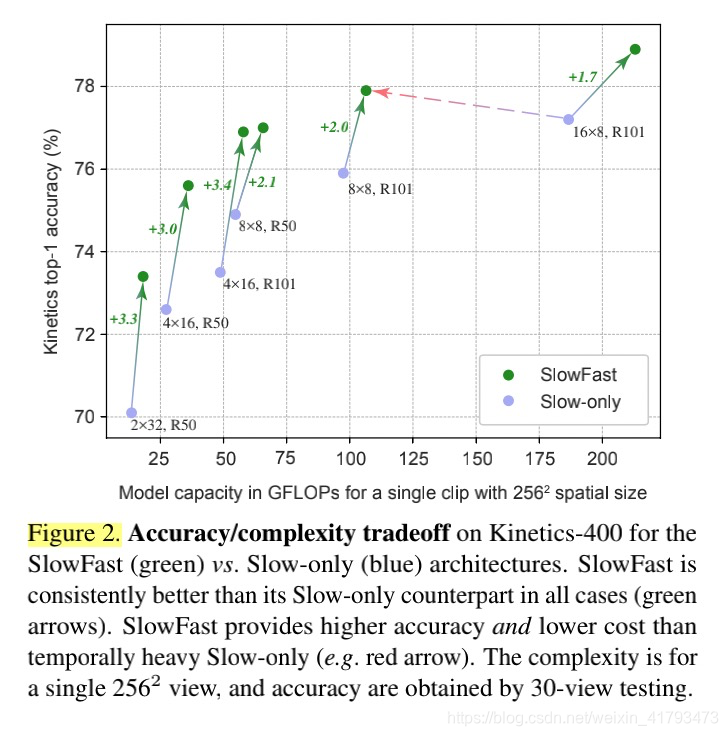
Figure 2. 对于SlowFast(绿色)与Slow-only(蓝色)架构,Kinetics-400的准确性/复杂性权衡。在所有情况下,SlowFast始终优于其唯一的Slow-only对应物(绿色箭头)。与仅使用temporally heavey Slow-only(如红色箭头)相比,慢速提供了更高的精度和更低的成本。复杂度是针对单个2562视图,精度是通过30视图测试获得的。
Figure 2显示,对于所有变体,Fast路径能够以相对较低的成本持续改进Slow数器部分的性能。
【说实话,这里的single 2562 view和30-view还没搞懂】
【接下来对Kinetics-600、Charades的分析就不说了。具体看论文吧。】
4.2. Ablation Experiments
本节提供了关于Kinetics-400的ablation study(消融研究),比较了精确度和计算复杂性。
ablation:
1 surgical removal of a body part or tissue
2 the erosive process that reduces the size of glaciers
An ablation study typically refers to removing some “feature” of the model or algorithm, and seeing how that affects performance.
Slow vs. SlowFast
We first aim to explore the SlowFast complementarity by changing the sample rate (T×τ ) of the Slow pathway. Therefore, this ablation studies α, the frame rate ratio between the Fast and Slow paths. Fig. 2 shows the accuracy vs. complexity tradeoff for various instantiations of Slow and SlowFast models. It is seen that doubling the number of frames in the Slow pathway increases performance(vertical axis) at double computational cost (horizontal axis), while SlowFast significantly extends the performance of all variants at small increase of computational cost, even if the Slow pathways operates on higher frame rate. Green arrows illustrate the gain of adding the Fast pathway to the corresponding Slow-only architecture. The red arrow illustrates that SlowFast provides higher accuracy and reduced cost.
我们首先通过改变慢通路的采样率(T×τ)来探索SlowFast互补性。因此,本次消融研究的是快慢路径之间的帧速率比α。Fig. 2显示了Slow和SlowFast模型的各种实例化的精度与复杂性之间的权衡。可以看出,将慢速路径中的帧数增加一倍会以两倍的计算成本(水平轴)提高性能(垂直轴),而SlowFast在计算成本小幅度增加的情况下显著扩展所有变体的性能,即使慢速路径以更高的帧速率运行。绿色箭头说明了将快速路径添加到相应的纯慢速体系结构的好处。红色箭头表明,SlowFast提供了更高的精度和更低的成本。
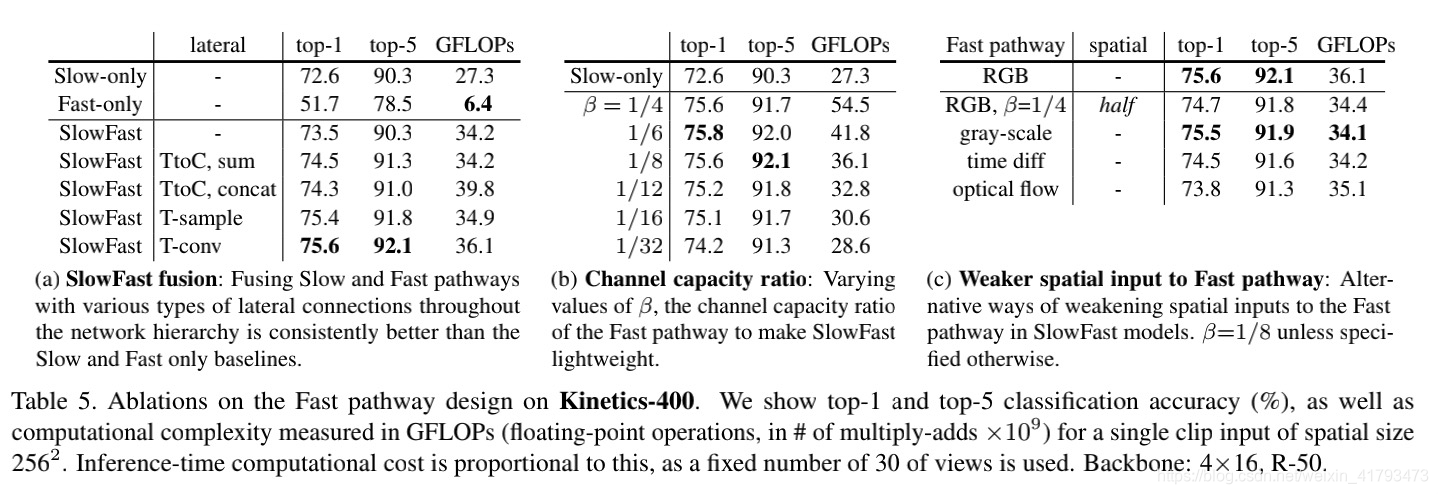
接下来,Table 5显示了快速路径设计上的一系列消融研究,使用默认的SlowFast,T×τ=4×16,R-50实例化(在表1中指定),依次分析。
对于Table 5更多的分析请看论文。
5. Experiments: AVA Action Detection
Dataset
AVA数据集[20]关注人类行为的时空定位。数据取自437部电影。时空标签以每秒一帧的速度提供,每个人都用一个边界框和(可能是多个)动作进行注释。注意,AVA的难点在于动作检测,而演员定位的难度较小[20]。我们使用的AVA v2.1中有211k训练和57k验证视频片段。我们遵循标准协议[20],对60个类别进行评估(见Fig. 3)。性能指标是超过60个类的平均精度(mAP),使用0.5的帧级IoU阈值。
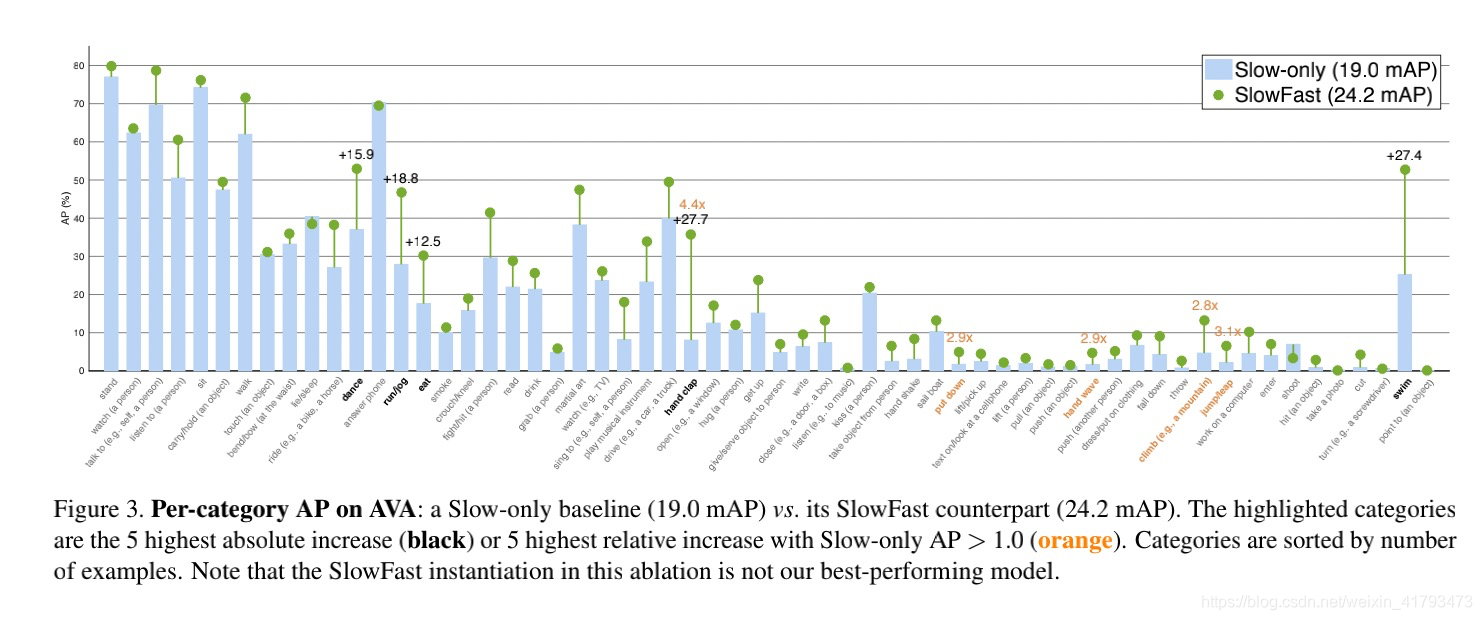
Detection architecture
我们的检测器类似于Faster R-CNN[40],只需对视频进行最小的修改。我们使用慢速网络或其变体作为主干网。我们将res5的空间步长设置为1(而不是2),并对其过滤器使用2的膨胀。这将使res5的空间分辨率提高2倍。我们在res5的最后一个特征图中提取感兴趣区域(RoI)特征[17]。我们首先通过沿时间轴复制,将一帧处的每个2D RoI扩展为3D RoI,类似于[20]中介绍的方法。随后,我们在空间上通过RoIAlign[22]计算RoI特征,在时间上通过全局平均池计算RoI特征。然后对RoI特征进行最大合并,并将其输入到基于sigmoid的每类分类器中,以进行多标签预测。
我们遵循以前的工作,使用预先计算的建议[20,46,29]。我们的区域建议由现成的人员检测器计算,即,该检测器未与动作检测模型联合训练。我们采用了一种由Detectron训练的人员检测模型[18]。它是带有ResNeXt-101-FPN[60,35]主干网的Faster R-CNN。它是在ImageNet和COCO人体关键点图像上预先训练的[36]。我们在AVA上对该检测器进行微调,以进行人员检测。人探测器产生93.9AP@50在AVA验证集上。然后,用于行动检测的区域建议是检测到的人的标定框,置信度大于0.8(the region proposals foraction detection are detected person boxes with a confidence of > 0.8不会翻译了。。。),对于人物类,召回率为91.1%,准确率为90.7%。
Training
我们从Kinetics-400分类模型中初始化网络权重。我们使用逐步学习率,当验证误差饱和时,学习率降低10倍。我们训练14k迭代(211k数据为68个时代),第一个1k迭代为线性预热。我们使用10-7重量衰减。所有其他超参数与Kinetics实验中相同。Ground-truch boxes用作训练样本。输入是大小为224x224的实例化特定帧αT×τ。
Inference
我们在一个片段上进行推断,在要评估的帧周围有αT×τ帧。我们调整空间尺寸,使其较短的一面是256像素。主干特征提取器是完全卷积计算的,如标准Faster R-CNN[40]。
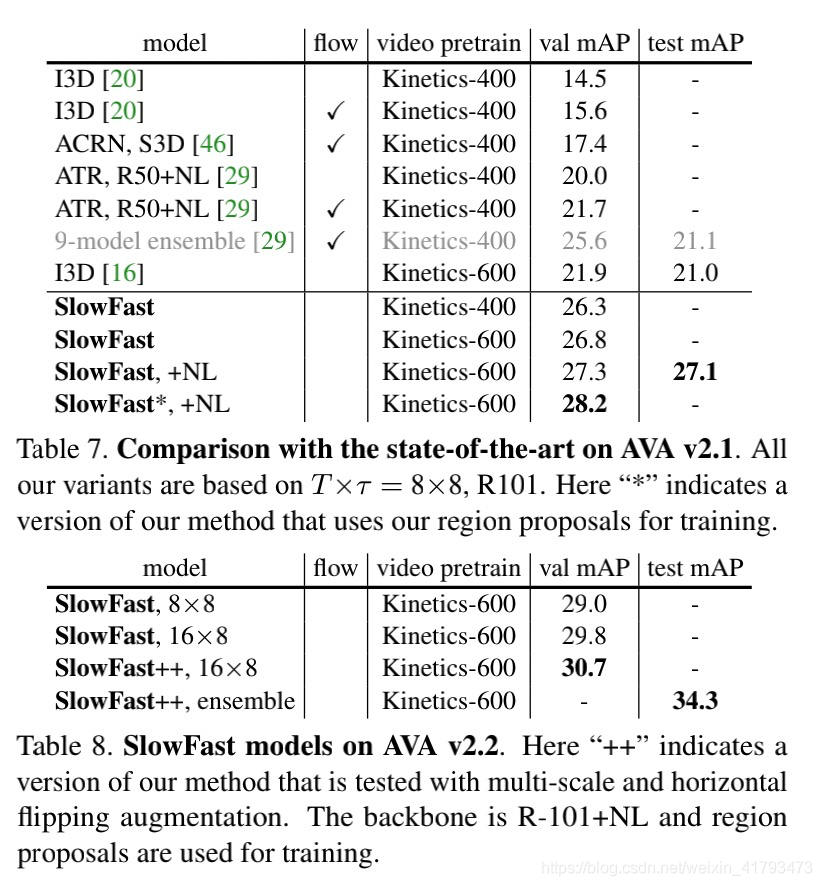
We compare with previous results on AVA in Table 7. An interesting observation is on the potential benefit of using optical flow (see column ‘flow’ in Table 7). Existing works have observed mild improvements: +1.1 mAP for I3D in [20], and +1.7 mAP for ATR in [29]. In contrast, our baseline improves by the Fast pathway by +5.2 mAP (see Table 9 in our ablation experiments in the next section). Moreover, two-stream methods using optical flow can double the computational cost, whereas our Fast pathway is lightweight.
6. Conclusion
时间轴是一个特殊的维度。本文研究了一种结构设计,该设计对比了沿该轴的速度。它实现了最先进的视频动作分类和检测精度。我们希望这种SlowFast的概念将促进视频识别的进一步研究。