数据来源:请点击这里
先研究清楚数据。
代码:
import numpy as np
from matplotlib import pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix, roc_auc_score
# 设置输出结果不带省略号
pd.set_option('display.max_colwidth', 1000)
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
np.set_printoptions(threshold=10000)
np.set_printoptions(threshold=10000)
# 读入数据
csvdata = pd.read_csv('healthcare_dataset_stroke_data.csv')
# print(csvdata.head())
# 处理缺失值数据
csvdata['bmi'] = csvdata['bmi'].fillna(csvdata['bmi'].mean())
# print(csvdata['bmi'].mean())
# print(csvdata.head())
# 可视化数据,观察数据内部情况
print(csvdata.shape)
print('\n')
print(csvdata.isnull().sum())
print('\n')
print(csvdata.dtypes)
print('\n')
print(csvdata['gender'].value_counts())
print('\n')
print(csvdata['ever_married'].value_counts())
print('\n')
print(csvdata['work_type'].value_counts())
print('\n')
print(csvdata['Residence_type'].value_counts())
print('\n')
print(csvdata['smoking_status'].value_counts())
print('\n')
print(csvdata['stroke'].value_counts())
plt.figure(figsize=(12, 10))
ax = sns.heatmap(csvdata.corr())
fig = plt.figure(figsize=(20, 15))
ax = fig.gca()
csvdata.hist(ax=ax)
# plt.show()
# 选取特征,不选id作为特征,与预测无关
feature_data = csvdata.loc[:, ["age", "hypertension", "heart_disease", "ever_married", "avg_glucose_level", "bmi", "stroke"]]
text_data = csvdata.loc[:, ["gender", "work_type", "Residence_type", "smoking_status"]]
# print(text_data)
# 把ever_married的Yes和No替换成1和0
size_mapping = {'Yes': 1, 'No': 0}
feature_data['ever_married'] = feature_data['ever_married'].map(size_mapping)
pd.get_dummies(text_data, prefix=["gender", "work_type", "Residence_type", "smoking_status"])
feature_data = feature_data.join(pd.get_dummies(text_data, prefix=["gender", "work_type", "Residence_type", "smoking_status"]))
# 下采样:因为中风的数据量和未中风的数据量相差很大,中风的数据量太少了,要用下采样或者过采样的方法使得数据量均衡
# 采用索引取数据
data0_len = len(feature_data[feature_data['stroke'] == 0]) # 标签为0的总个数
data0_index = feature_data[feature_data['stroke'] == 0].index # 标签为0的索引
data1_len = len(feature_data[feature_data['stroke'] == 1]) # 标签为1的总个数
data1_index = feature_data[feature_data['stroke'] == 1].index # 标签为1的索引值
random_index = np.random.choice(data0_index, data1_len) # 随机抽取标签为0的数据
altogether_index = np.concatenate([data1_index, random_index]) # 合并索引值数据
altogether_data = feature_data.iloc[altogether_index, :] # 按索引在原数据中寻找相对应索引的数据
# 标准化数据
std = StandardScaler()
standard_data = std.fit_transform(altogether_data)
# print(standard_data)
standard_data = pd.DataFrame(standard_data, columns=feature_data.columns)
# 划分训练集和测试集
train_data = standard_data.iloc[:, standard_data.columns != 'stroke']
test_data = standard_data.iloc[:, standard_data.columns == 'stroke']
X_train, X_test, y_train, y_test = train_test_split(train_data, test_data, test_size=0.3)
print(y_train)
# 建模
lr_1 = LogisticRegression()
lr_1.fit(X_train, y_train)
prediction_lr_1 = lr_1.predict(X_test)
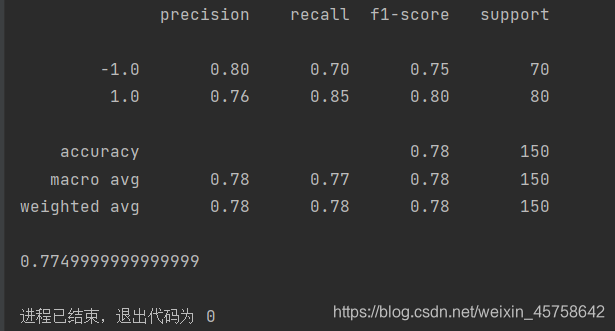
print(confusion_matrix(y_test, prediction_lr_1)) # 混淆矩阵
print(classification_report(y_test, prediction_lr_1)) # 每个类的精确度,召回率,F1值等信息
print(roc_auc_score(y_test, prediction_lr_1)) # 准确率
结果: