���ر�Ҷ˹(Native Bayes)
��������,���DZ�Ҷ˹������,���Ҳ������ķ����㷨��
�����Ա�Ҷ˹����Ϊ����
ͨ��Ҫ������ô��������
**�������:**������������ͷ����õ��ĸ���,
P
(
Y
)
P(Y)
P(Y)
**�������:**�����ѷ������¼��������õ��ĸ���,
P
(
Y
�O
X
)
P(Y|X)
P(Y�OX)
**���ϸ���:**���ϸ������ڶ�Ԫ�ĸ��ʷֲ���,�����������ֱ�������������ĸ���,��ѧ����:
P
(
X
,
Y
)
��
P
(
X
Y
)
��
P
(
X
��
Y
)
P(X,Y)��P(XY)��P(X \cap Y)
P(X,Y)��P(XY)��P(X��Y)Ҳ�����¼�A��Bͬʱ�����ĸ���
�ٸ�����:

�Ҷ�һ��İ���������ж��Ƿ�Ϊ����
����˵:��֮���Ա���,��ô�Ҿ�����99%�Ǻ���,1%�ǻ���-�������
��һ��,��Ϊ��û��ȥ�Ͽ�,��������ο���ʦ���Ҿٱ���!
�滵!
�����Ҿ�����50%�Ǻ���,50%�ǻ��ˡ�-�������
����ʦ���Ĺ�ʽ:

���ر�Ҷ˹ԭ��
�б�ģ�ͺ�����ģ��
�ලѧϰ��Ϊ���ɷ���(Generative approach)���б�(discriminative approach)
��ѧ����ģ�ͷֱ���
�ලѧϰ��Ϊ����ģ��(Generative Model)���б�ģ��(discriminative Model)

���ر�Ҷ˹�ǵ��͵�����ѧϰ����
���ɷ�����ѵ������ѧϰ���ϸ��ʷֲ�
P
(
X
,
Y
)
P(X,Y)
P(X,Y),Ȼ����ú�����ʷֲ�
P
(
Y
�O
X
)
P(Y|X)
P(Y�OX),������
P
(
X
,
Y
)
=
P
(
Y
)
P
(
X
�O
Y
)
P(X,Y)=P(Y)P(X|Y)
P(X,Y)=P(Y)P(X�OY)
����Ҫ�ļ���:�����-���Խ�native
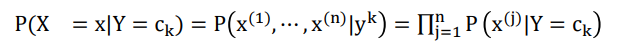
C
k
C_k
Ck?��ʾ���,k��ʾ������
�������Z�������,X��Y��������:
P
(
X
�O
Z
)
=
P
(
X
�O
Y
,
Z
)
P(X|Z)=P(X|Y,Z)
P(X�OZ)=P(X�OY,Z)
Ҳ���Ա�ʾΪ
P
(
X
,
Y
�O
Z
)
=
P
(
X
�O
Z
)
P
(
Y
�O
Z
)
P(X,Y|Z)=P(X|Z)P(Y|Z)
P(X,Y�OZ)=P(X�OZ)P(Y�OZ)
���ݼ�����Ȼ����
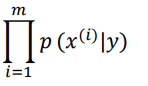
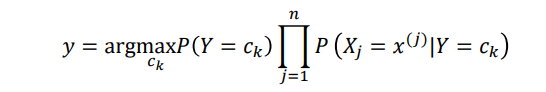
�������������ȼ���0-1��ʧ��������������С
�Ƶ�����:
���ݱ�Ҷ˹����
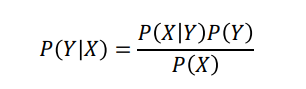
������������

��ʽ1����ʽ2
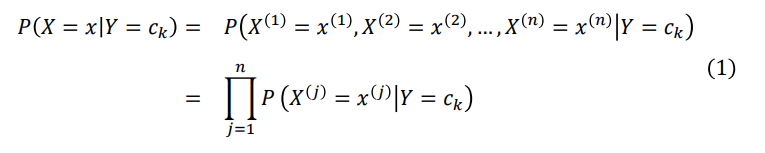

ʵ�ʰ���
���������������!
�Ƽ�һ��������ġ�������������
����ʵ��
��Ҷ˹������
GaussianNB��˹��Ҷ˹������,���,�����˹�ֲ�
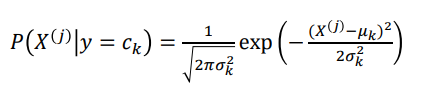

MultinomialNB���Ҷ˹������,�������ʷֲ��������ʽ�ֲ�
BernoulliNB��Ŭ����Ҷ˹������,���������������ֲ�
����scikit-learn��ʵ��
import numpy as np
X = np.array([[-1,-1],[-2,-1],[-3,-2],[1,1],[2,1],[3,2]])
y = np.array([1,1,1,2,2,2])
# �����˹���ر�Ҷ˹������
from sklearn.naive_bayes import GaussianNB
# ʵ����
clf = GaussianNB()
# ѵ������
clf.fit(X,y)
# ���뵥��Ԥ����
print('-----predict result by predict-----')
print(clf.predict([[-0.8,-1]]))
print('-----predict result by predict_proba-----')
print(clf.predict_proba([[-0.8,-1]]))
print('-----predict result by predict_log_proba-----')
print(clf.predict_log_proba([[-0.8,-1]]))
������:
-----predict result by predict-----
[1]
-----predict result by predict_proba-----
[[9.99999949e-01 5.05653254e-08]]
-----predict result by predict_log_proba-----
[[-5.05653266e-08 -1.67999998e+01]]
������дGaussianNB�ĸ�˹���ر�Ҷ˹numpyʵ��
import numpy as np
from sklearn import datasets
# ��������
iris = datasets.load_iris()
X = np.array([[-1,-1],[-2,-1],[-3,-2],[1,1],[2,1],[3,2]])
y = np.array([1,1,1,2,2,2])
# �����˹���ر�Ҷ˹������
from sklearn.naive_bayes import GaussianNB
# ʵ����
clf = GaussianNB()
# ѵ������
clf.fit(X,y)
# ���뵥��Ԥ����
print('-----predict result by predict-----')
print(clf.predict([[-0.8,-1]]))
print('-----predict result by predict_proba-----')
print(clf.predict_proba([[-0.8,-1]]))
print('-----predict result by predict_log_proba-----')
print(clf.predict_log_proba([[-0.8,-1]]))
# ����GaussianNB�����ر�Ҷ˹numpyʵ��
# �ȶ���һ����
class NaiveBayes:
def __init__(self):
print('Gaussian naive bayes model!')
def gaussian_pdf(self,x_test,x):
"""
�����˹��̬�ֲ��µ���������
params:
x_test(array):
x(array):ͬ����һ�����
"""
temp1 = (x_test-x.mean(0))*(x_test-x.mean(0))
temp2 = x.std(0) * x.std(0)
return np.exp(-temp1 / (2 * temp2)) / np.sqrt(2 * np.pi * temp2)
def fit(self,x_train,y_train):
self.x_train = x_train
self.y_train = y_train
def predict(self,x_test,y_test=None):
assert len(x_test.shape) == 2
# ����Ӧ����y_test
self.classes = np.unique(np.concatenate([x_test,y_test],0))
pred_probs = []
# ����ÿһ������,����������ÿ�����ĸ���
for i in self.classes:
idx_i = self.y_train == i
# ����P(y)
p_y= len(idx_i) / len(self.y_train)
# ���ø�˹�����ܶȺ�������P(x|y)
p_x_y = np.prod(self.gaussian_pdf(x_test,self.x_train[idx_i]),1)
# ����x,y�����ϸ���,P(x|y)P(y)
prob_i = p_y * p_x_y
pred_probs.append(prob_i)
pred_probs = np.vstack(pred_probs)
# ȥ������߸��ʵ����
label_idx = pred_probs.argmax(0)
y_pred = self.classes[label_idx]
if y_test is not None:
self._score(y_test,y_pred)
return y_pred
def _score(self,y_test,y_pred):
self.score = np.count_nonzero(y_test == y_pred)/len(y_test)
model = NaiveBayes()
model.fit(iris.data, iris.target)
print('GaussianNB train done!')
print(model.predict(np.array([4.4,3.2,1.3,0.2])))
#print(model.score(X,y))