MixMatch
�����ͽ����㷨�����赼,����ϸ����μ�ԭ��
ԭ��
Github����
���
MixMatchץס�˰�ල�㷨��������Ҫ�۵�:��һ������С��;�ڶ���һ��������������������۵���㷨���γ���MixMatch��
������
��ල�㷨��һ������������Ƿ���ľ��߽߱粻Ӧ��ͨ�����ݷֲ��ĸ��ܶ�������仰�������������һ������ģ��,����߽߱�һ�����ڴ����֮���ϡ��߽���,�����ܴ���һ���ص�����(���ܶ�����)����ʵ����һ���һ�ַ�������Ҫ���������δ��������������Ԥ�⡣MixMatch��ʹ��һ��"sharpening"��������ʽʵ������С������ν����С��������Ԥ��,����ָʹ������ʷֲ��Ƚ��С�ƫ���ԡ�,����ϣ�����һ����ƽ����Ԥ�⡱��������Ϣ�����Dz�ȷ���ȵĶ���,������ɢģ�͵��������,��֪�ھ��ȷֲ�ʱ��ȡ�����ֵ,���仰˵,����һ��ȷ���ķֲ�,��ijһ��ĸ�����1,������ĸ�����0ʱ,��Ϊ0��Ҳ����˵��Ҫ�õ�����С,�͵�ʹ������������ģ��Ԥ����ʼ��з����ijһ�ࡣ�����ٽ��ܡ�sharpening���������ʵ����һ�㡣
һ��������
һ��������Ҳ��һ�������İ�ල���衣VAT��MeanTeacher����ʵ��������ʹ�������ּ��衣���������,����ϣ��һ������������Ű汾(ͨ��ͼ���г�ΪAugment)ͨ����������,�õ����Ƶ��������ʵҲ����˵����߽粻Ӧ�ô������ݷֲ��ĸ��ܶ���������ͼ,��ɫ����ԭʼ����,��ɫ����ɫΪ���Ŷ��汾,��ɫͬ��Բ������Բ�������������ݲΧ,�������������Ķ�Ӧ����Ϊ�����������ݵ�Ϊͬһ�ࡣͨ���Ŷ����ݵ�ļ���,�����߽߱��Ƶ����ʵ�λ��,ʹ��������³���Ը�ǿ��
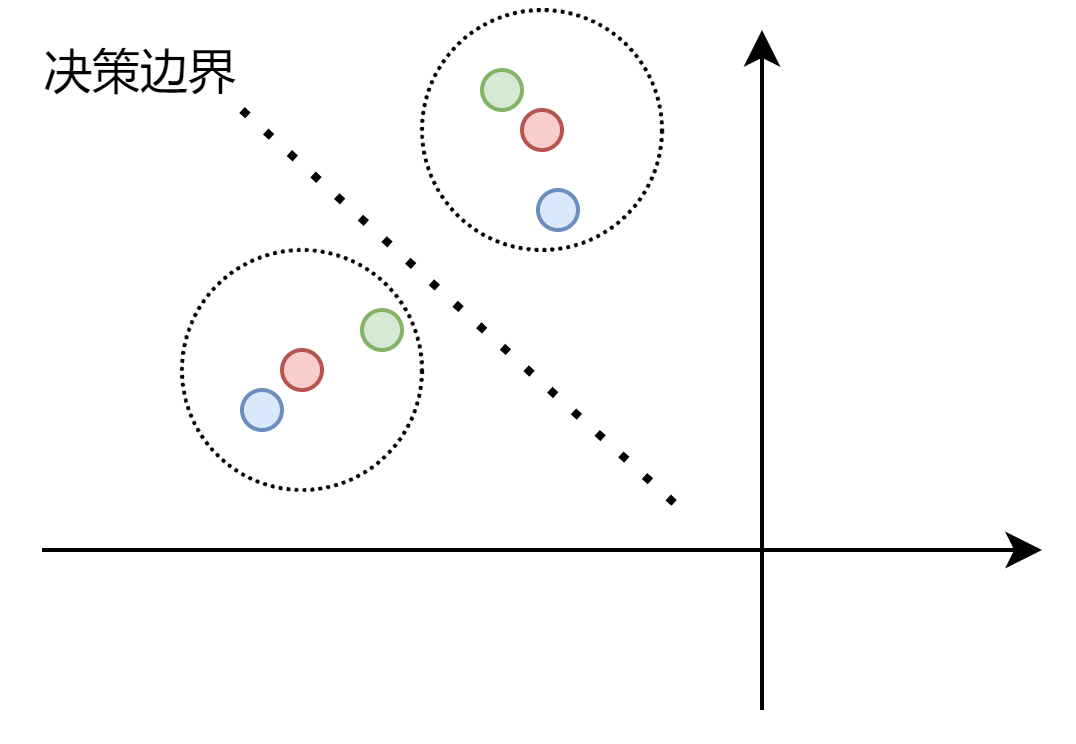
һ�����,ͨ����ԭʼ���������Ŷ��汾�ķ�����������к���,����ʵ��һ��������,�����ĺ�����ʽ��MSE��KLɢ�ȡ�JSɢ�ȵȡ���MixMatch��ͨ����ͼ��ı�������ǿ(ˮƽ��ת���ü�)ʵ���Ŷ�(Augment),����MSE��ʽ������
�ܵ���˵,�㷨�����²���:

���������������:
��һ��,�����ݽ�������(Augment)��������Ϊ���б�����ݼ� X X X?�������Ͷ��ޱ�����ݼ� U U U?������,�ֱ��Ϊ X ^ \hat{X} X^?�� U ^ \hat{U} U^?���� X X X?����һ��,�� U U U?���� K K K?��,������ȡ K = 2 K=2 K=2?����Ϊ��ȡbatchʱ, B a t c h S i z e U = B a t c h S i z e X Batch Size _U = BatchSize_X BatchSizeU?=BatchSizeX??,���������� B a t c h S i z e U ^ = K ? B a t c h S i z e X ^ Batch Size _{\hat{U}} = K\cdot BatchSize_{\hat{X}} BatchSizeU^?=K?BatchSizeX^?????��
�ڶ���,����ƽ��Ԥ��ֲ����˲���������ݼ� U ^ \hat{U} U^???���С���ͨ�����¹�ʽ����,���� ( u b , k ^ , y ) (\hat{u_{b,k}},y) (ub,k?^?,y)?�� U ^ \hat{U} U^?��һ�� B a t c h Batch Batch?:
q b �� = 1 K �� k P m o d e l ( y �O u b , k ^ ; �� ) \bar{q_b}=\frac{1}{K}\sum_kP_{model}(y|\hat{u_{b,k}};\theta) qb?��?=K1?k��?Pmodel?(y�Oub,k?^?;��)
ֵ��ע�����, P m o d e l ( y �O u b , k ^ ; �� ) P_{model}(y|\hat{u_{b,k}};\theta) Pmodel?(y�Oub,k?^?;��)�� S o f t m a x Softmax Softmax?֮���Ԥ����ʷֲ���
������,ͨ�� s h a r p e n i n g sharpening sharpening������ɷֲ�����,����㹫ʽ����:
S h a r p e n ( p , T ) i = p i 1 T �� j = 1 L p j 1 T Sharpen(p,T)_i=\frac{p_i^{\frac{1}{T}}}{\sum^L_{j=1}p_j^{\frac{1}{T}}} Sharpen(p,T)i?=��j=1L?pjT1??piT1????
�������� T �� 0 T\to 0 T��0?ʱ, S h a r p e n ( p , T ) Sharpen(p,T) Sharpen(p,T)?������ o n e ? h o t one-hot one?hot??�ֲ�,������һ�����ĸ���Ϊ1,�������Ϊ0;��ĸ��ʷֲ���Ϊ U ^ \hat{U} U^?�����ݱ�ǩ(pseudo label)��
���IJ�,ͨ��
M
i
x
U
p
MixUp
MixUp��������ݼ��Ĺ������Ƚ���һ���������
X
^
\hat{X}
X^��
U
^
\hat{U}
U^����ƴ���ٴ���˳��,�õ�
W
=
S
h
u
f
f
l
e
(
C
o
n
c
a
t
(
X
^
,
U
^
)
)
W=Shuffle(Concat(\hat{X},\hat{U}))
W=Shuffle(Concat(X^,U^)),Ȼ���ٽ�
W
W
W��Ϊ������,��һ���ִ�С��
X
^
\hat{X}
X^��ͬ(Ҳ��
X
X
X��ͬ),��Ϊ
W
x
W_x
Wx?;�ڶ����ִ�С��
U
^
\hat{U}
U^��ͬ(Ҳ��
U
U
U��ͬ),��Ϊ
W
u
W_u
Wu?��Ȼ��
W
x
W_x
Wx?��
X
^
\hat{X}
X^����
M
i
x
U
p
MixUp
MixUp,
W
u
W_u
Wu?��
U
^
\hat{U}
U^����
M
i
x
U
p
MixUp
MixUp,�õ�
X
��
X'
X����
U
��
U'
U��?��
M
i
x
U
p
MixUp
MixUp��������:
��
��
B
e
t
a
(
��
,
��
)
\lambda\sim Beta(\alpha,\alpha)
����Beta(��,��)
��
��
=
m
a
x
(
��
,
1
?
��
)
\lambda'=max(\lambda,1-\lambda)
����=max(��,1?��)
x
��
=
��
��
x
1
+
(
1
?
��
��
)
x
2
x'=\lambda'x_1+(1-\lambda')x_2
x��=����x1?+(1?����)x2?
p
��
=
��
��
p
1
+
(
1
?
��
��
)
p
2
p'=\lambda'p_1+(1-\lambda')p_2
p��=����p1?+(1?����)p2?
���岽,�����ල��ʧ����,��Ϊ�ڱ�����ݼ� X �� X' X��?�ϵ���ʧ���� L x L_x Lx?�����ޱ�����ݼ� U �� U' U���ϵ���ʧ���� L u L_u Lu?,��ʽ����:
L x = 1 �O X �� �O �� x , p �� X �� H ( p , P m o d e l ( y �O x ; �� ) ) L_x=\frac{1}{|X'|}\sum_{x,p\in X'}H(p,P_{model}(y|x;\theta)) Lx?=�OX���O1?x,p��X����?H(p,Pmodel?(y�Ox;��))
L u = 1 L �O U �� �O �� u , q �� U �� �O �O q ? P m o d e l ( y �O u ; �� ) �O �O 2 2 L_u=\frac{1}{L|U'|}\sum_{u,q\in U'}||q-P_{model}(y|u;\theta)||^2_2 Lu?=L�OU���O1?u,q��U����?�O�Oq?Pmodel?(y�Ou;��)�O�O22?
L = L x + �� U L u L=L_x+\lambda_UL_u L=Lx?+��U?Lu?
���� H ( ? ) H(\cdot) H(?)?�� C o r s s E n t r o p y L o s s CorssEntropyLoss CorssEntropyLoss?; L u L_u Lu?��ʵ���� M S E MSE MSE���µ�����?
�����ݶȴ��������������MixMatch�㷨
���Ĵ������
ͼ���ˮƽ��ת���ü�ʵ�� A u g m e n t Augment Augment:
transform_train = transforms.Compose([
dataset.RandomPadandCrop(32),
dataset.RandomFlip(),
dataset.ToTensor(),
])
transform_val = transforms.Compose([
dataset.ToTensor(),
])
�������ڵ���������,�ֶ�ȡ�������е�batch,������ֱ��ʹ��Dataloader����������������ļ�ƪ���´��븴���ж�������,����ҪĿ����Ϊ����һ��epoch�п��Ե���ָ������,��ֱ��ʹ��Dataloaderֻ�ܵ������ c e i l ( �� �� �� �� B a t c h S i z e ) ceil(\frac{��������}{BatchSize}) ceil(BatchSize��������?)��,���� c e i l ( ? ) ceil(\cdot) ceil(?)����ȡ������,��� d r o p l a s t drop_last dropl?ast,��ֻ�ܵ��� �� �� �� �� B a t c h S i z e \frac{��������}{BatchSize} BatchSize��������?�Ρ������е�����try except��Ϊ�˱�֤��������ȫ����һ�κ�,���¼��ص�����,��������,ֱ���ﵽָ����������ת��һ��epoch��
for batch_idx in range(args.train_iteration):
try:
inputs_x, targets_x = labeled_train_iter.next()
except:
labeled_train_iter = iter(labeled_trainloader)
inputs_x, targets_x = labeled_train_iter.next()
try:
(inputs_u, inputs_u2), _ = unlabeled_train_iter.next()
except:
unlabeled_train_iter = iter(unlabeled_trainloader)
(inputs_u, inputs_u2), _ = unlabeled_train_iter.next()
��Ϊ������ȡ K = 2 K=2 K=2,���Խ�����������,��������ʵľ�ֵ,����output_u��output_u2�ֱ�Ϊ�����������ģ��������:
outputs_u = model(inputs_u)
outputs_u2 = model(inputs_u2)
p = (torch.softmax(outputs_u, dim=1) + torch.softmax(outputs_u2, dim=1)) / 2 # �����ε�ƽ��ֵ
��Sharpening���:
pt = p**(1/args.T)
targets_u = pt / pt.sum(dim=1, keepdim=True)
targets_u = targets_u.detach()
��� M i x U p MixUp MixUp:
all_inputs = torch.cat([inputs_x, inputs_u, inputs_u2], dim=0)
all_targets = torch.cat([targets_x, targets_u, targets_u], dim=0)
l = np.random.beta(args.alpha, args.alpha)
l = max(l, 1-l)
idx = torch.randperm(all_inputs.size(0))
input_a, input_b = all_inputs, all_inputs[idx]
target_a, target_b = all_targets, all_targets[idx]
mixed_input = l * input_a + (1 - l) * input_b
mixed_target = l * target_a + (1 - l) * target_b
Ȼ�������ʧ����:
logits = [model(mixed_input[0])]
for input in mixed_input[1:]:
logits.append(model(input))
# put interleaved samples back
logits = interleave(logits, batch_size)
logits_x = logits[0]
logits_u = torch.cat(logits[1:], dim=0)
Lx, Lu, w = criterion(logits_x, mixed_target[:batch_size], logits_u, mixed_target[batch_size:], epoch+batch_idx/args.train_iteration)
loss = Lx + w * Lu
�����ݶȴ���,������