Ŀ¼
ǰ��
ƽʱϲ���濪����,֮ǰ��jetson nano,RK3399pro,Ӣ�ض��������ʵ���˸������ѧϰ�㷨��Ǩ�Ʋ���,�Ƚ���Ϥtensorrt,rknn,openvino���ֻ�����ڵ���������
����ֽӴ��˻�ΪAtlas200DK������,������һ�Ѵ����ܹ��ĕN��310NPU,ʵ����ȷ����С��,�ڼ����ڵ�ѧϰ��Ŭ����������Ϥ����NPU����CANN������(�ұȽ�ϲ������������),��˷���һ��ʹ��CANN��pyACL�ӿڲ���YOLOX��YOLOv5��Nanodet�ķ�����
YOLOX��YOLOĿ����ϵ��������·���,�������Ѻ�,���Ҹ�������һƪ���͵Ľ��������ģ������Ч�ʺܸ�,��˱����ص���YOLOXΪ����
���ѧϰģ����AIоƬ�ϲ����һ������
���Ƚ���һ����AIоƬ�ϵIJ�������,������Ӣΰ���tensorrt,��о��rknn,����openvino��CANN����������,��Ȼ�������API��ͬ,���������̶����,����ͼ��ʾ:
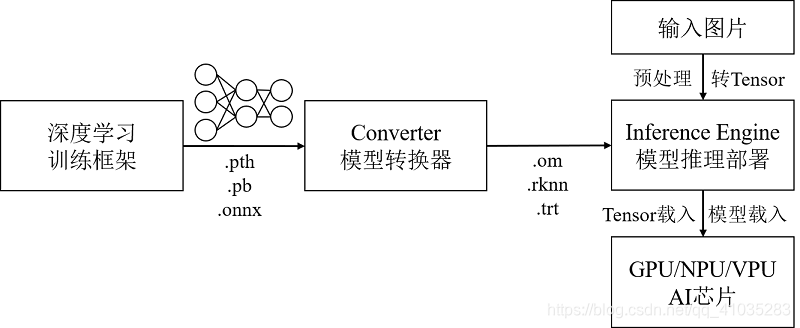
�����ѧϰѵ�����(��pytorch,tf,paddle��)ѵ���õ���ģ��,ͨ�����������渽����ģ��ת����(�е�������������APIת������RKNN,�е�������ר�ŵ�ת������tools����CANN��ATC),ת���ɶ�Ӧ����ĵ�����ģ�͡�������ʱ,ͨ������API��ģ�ͺ�Ԥ�������ͼƬ���ص��ڴ���,Ȼ������AIоƬ��ִ��������
������ͬ�������������������Ȼ����һЩϸ�ڲ��졣
CANNģ�Ͳ�������
����CANN����,ģ�Ͳ��������������Ը���һЩ����������һ�¹���������,���ڳ��õ�Ŀ����ģ��,ֻ��Ҫ���ұߵ�ģ��������OK��:
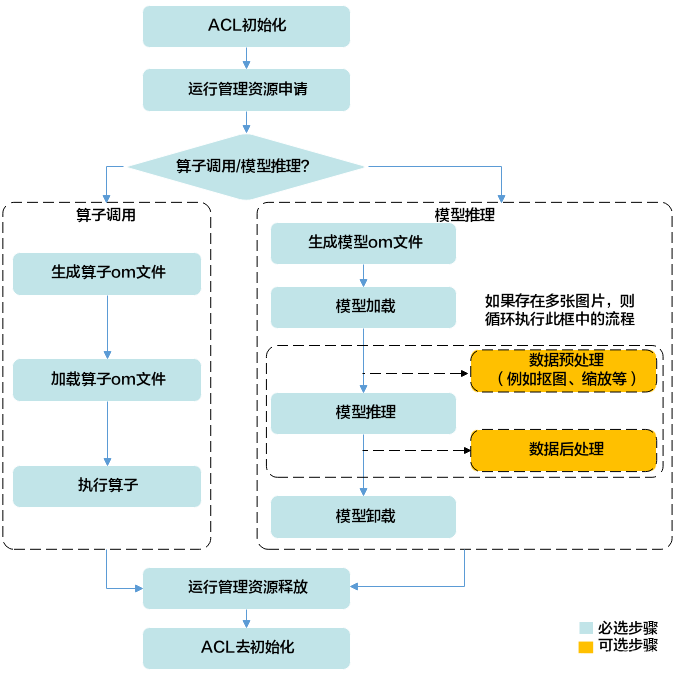
��Ҫ����ACL����(������Դ)����ʼ����ģ��ת���ͼ�����ͼ��Ԥ������ģ��������������ģ��ж����ACL������ȥ��ʼ����
էһ��,����ǰ���л�����ʼ����������ȥ��ʼ���IJ����ȽϷ���,�����ֹ淶�����������ʵ�Ǻ��б�Ҫ��:
�ٸ�����,openvinoû����Щ��ʼ��֮��IJ���,��������Ӣ�ض���NCS2 VPU�Ͼ�����������������Ҫ�ȴ��ܳ�ʱ����ܽ�����һ�����е�����,ԭ�����û�а���һ�μ��ص��ڴ�����ж�ص�:)
CANN ACL�ӿڵ�������(python)
ACL(Ascend Computing Language)�ṩ��CANN�������ӿ�,����C++(AscendCL)��python(pyACL)���п���,�ұȽ�ϲ����pyACL��
һ��Ľӿڵ�����������:
����1.ACL������ʼ������Դ����
import acl
# pyACL��ʼ��
ret = acl.init()
# ָ�������Device
self.device_id = 0
ret = acl.rt.set_device(self.device_id)
# ��ʽ����һ��Context,���ڹ���Stream����
self.context, ret = acl.rt.create_context(self.device_id)
����2.ģ�ͼ���
��pytorch�ȿ���µ�ģ�ͼ��ز�ͬ,CANN�ڼ���ģ��ʱ,����Ҫ��ģ���ļ����ص��ڴ���,��Ҫͨ��ģ���ļ���ģ�͵�����������͡��������ڴ�����ú�(openvinoҲ�����Ʋ���)��
'''
����ģ���ļ�
'''
self.model_path = './model/resnet50.om'
# ��������ģ���ļ�,���ر�ʶģ�͵�ID��
self.model_id, ret = acl.mdl.load_from_file(self.model_path)
# ���ݼ��سɹ���ģ�͵�ID,��ȡ��ģ�͵�������Ϣ��
self.model_desc = acl.mdl.create_desc()
ret = acl.mdl.get_desc(self.model_desc, self.model_id)
'''
����ģ�͵�����
'''
ACL_MEM_MALLOC_HUGE_FIRST = 0
# ����aclmdlDataset���͵�����,����ģ������������
self.load_input_dataset = acl.mdl.create_dataset()
# ��ȡģ�����������
input_size = acl.mdl.get_num_inputs(self.model_desc)
self.input_data = []
# ѭ��Ϊÿ�����������ڴ�,����ÿ���������ӵ�aclmdlDataset���͵�������
for i in range(input_size):
buffer_size = acl.mdl.get_input_size_by_index(self.model_desc, i)
# ���������ڴ�
buffer, ret = acl.rt.malloc(buffer_size, ACL_MEM_MALLOC_HUGE_FIRST)
data = acl.create_data_buffer(buffer, buffer_size)
_, ret = acl.mdl.add_dataset_buffer(self.load_input_dataset, data)
self.input_data.append({"buffer": buffer, "size": buffer_size})
'''
����ģ�͵����
'''
# ����aclmdlDataset���͵�����,����ģ�����������
self.load_output_dataset = acl.mdl.create_dataset()
# ��ȡģ�����������
output_size = acl.mdl.get_num_outputs(self.model_desc)
self.output_data = []
# ѭ��Ϊÿ����������ڴ�,����ÿ��������ӵ�aclmdlDataset���͵�������
for i in range(output_size):
buffer_size = acl.mdl.get_input_size_by_index(self.model_desc, i)
# ��������ڴ�
buffer, ret = acl.rt.malloc(buffer_size, ACL_MEM_MALLOC_HUGE_FIRST)
data = acl.create_data_buffer(buffer, buffer_size)
_, ret = acl.mdl.add_dataset_buffer(self.load_output_dataset, data)
self.output_data.append({"buffer": buffer, "size": buffer_size})
��һ��������,��Ϊ��ȡģ���������������Ϣʱ����Ҫ��ʹ��API��ʼ�������������,Ȼ����ͨ����һ��API�����Ϣ,������C++�е���������ʹ�á�
����3.����������,Ԥ����,����,����
ACL_MEMCPY_DEVICE_TO_DEVICE = 3
NPY_BYTE = 1
images_list = ["./data/dog1_1024_683.jpg", "./data/dog2_1024_683.jpg"]
for image in images_list:
# 1.�Զ��庯��transfer_pic,��ͼƬ�������š����õ�Ԥ��������
img = transfer_pic(image)
# 2.��ģ����������������
np_ptr = acl.util.numpy_to_ptr(img)
# ��ͼƬ���ݿ��������������ڴ���
ret = acl.rt.memcpy(self.input_data[0]["buffer"], self.input_data[0]["size"], np_ptr,
self.input_data[0]["size"], ACL_MEMCPY_DEVICE_TO_DEVICE)
# 3.ִ��ģ������
# self.model_id��ʾģ��ID,��ģ�ͼ��سɹ���,�᷵�ر�ʶģ�͵�ID
ret = acl.mdl.execute(self.model_id, self.load_input_dataset, self.load_output_dataset)
# 4.����ģ���������������,���top5���Ŷȵ������
inference_result = []
for i, item in enumerate(self.output_data):
buffer_d, ret = acl.rt.malloc(self.output_data[i]["size"], ACL_MEM_MALLOC_HUGE_FIRST)
ret = acl.rt.memcpy(buffer_d, self.output_data[i]["size"], self.output_data[i]["buffer"],
self.output_data[i]["size"], ACL_MEMCPY_DEVICE_TO_DEVICE)
data = acl.util.ptr_to_numpy(buffer_d, (self.output_data[i]["size"],), NPY_BYTE)
inference_result.append(data)
tuple_st = struct.unpack("1000f", bytearray(inference_result[0]))
vals = np.array(tuple_st).flatten()
top_k = vals.argsort()[-1:-6:-1]
print("======== top5 inference results: =============")
for j in top_k:
print("[%d]: %f" % (j, vals[j]))
����4.ж��ģ��
# �ͷ�������Դ,�������ݽṹ���ڴ�
while self.input_data:
item = self.input_data.pop()
ret = acl.rt.free(item["buffer"])
input_number = acl.mdl.get_dataset_num_buffers(self.load_input_dataset)
for i in range(input_number):
data_buf = acl.mdl.get_dataset_buffer(self.load_input_dataset, i)
if data_buf:
ret = acl.destroy_data_buffer(data_buf)
ret = acl.mdl.destroy_dataset(self.load_input_dataset)
# �ͷ������Դ,�������ݽṹ���ڴ�
while self.output_data:
item = self.output_data.pop()
ret = acl.rt.free(item["buffer"])
output_number = acl.mdl.get_dataset_num_buffers(self.load_output_dataset)
for i in range(output_number):
data_buf = acl.mdl.get_dataset_buffer(self.load_output_dataset, i)
if data_buf:
ret = acl.destroy_data_buffer(data_buf)
ret = acl.mdl.destroy_dataset(self.load_output_dataset)
# ж��ģ��
ret = acl.mdl.unload(self.model_id)
# �ͷ�ģ��������Ϣ
if self.model_desc:
ret = acl.mdl.destroy_desc(self.model_desc)
self.model_desc = None
����5.��Դ�ͷ�,aclȥ��ʼ��
# �ͷ�Context
if self.context:
ret = acl.rt.destroy_context(self.context)
self.context = None
# �ͷ�Device
ret = acl.rt.reset_device(self.device_id)
# pyACLȥ��ʼ��
ret = acl.finalize()
���Ͼ���pyACL�ӿڵĻ�����������
���ڼ����Atlas Utils
(����)