学习内容
本文以NLP为基础来介绍自注意力机制,而没有用图像为基础,但是其实两者都是相同的。
在图像中我们可以将图像切块(块的划分是自定义的),然后计算块与块之间的关系;
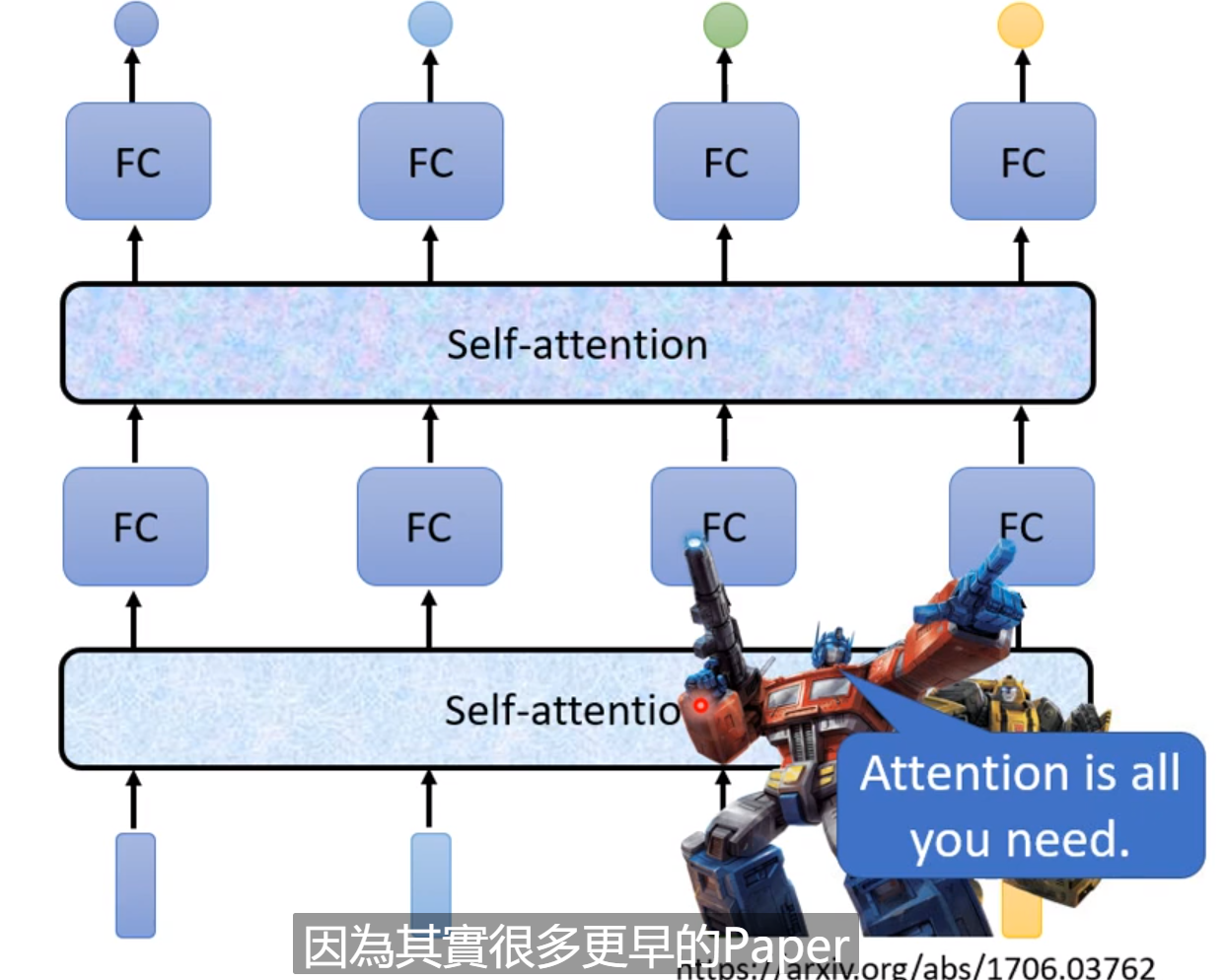
这里介绍了self-attention 的由来的应用
这里有几个问题需要说明:
- 常问的: 为什么是用dot-product来获取关系
我的理解是,如果两个特征高度相关,那么这两个特征之间的相似元素必然很多,那么点积之后的值就会很大,也就是关系型很强; 而且使用dot-product来计算关系是一个常用的方法。
1. 预备知识
1.1 Sophisticated Input(复杂输入)必须是 Vector set
在之前的一节中,我们的输入是一个向量,然后经过回归或者是分类来得到一个标量或者类别;
但是如果我们的输入长不只是有一个,而且多个呢? 而且是可以改变的呢?
一个句子: this is a cat
我们把每个单词作为一个向量;那么整个句子就是多个可变向量;
但是一个向量(单词)怎么表示呢?
- 第一种:我们可以以字母为单位,采用one-hot来表示一个单词;

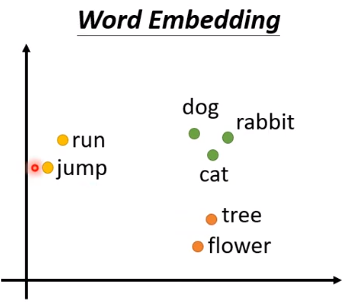
- 第二种是:Word Embedding
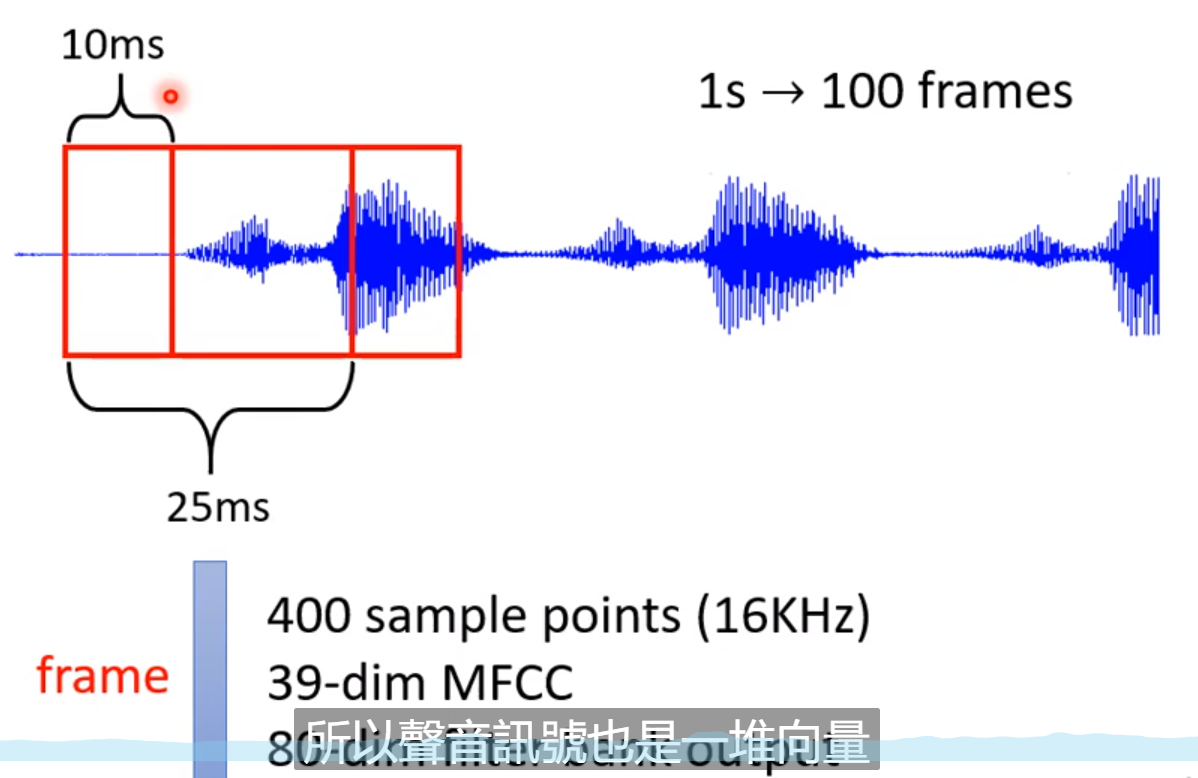
一段语音!
这里就会把一段Sequence当作信号;比如我们选取25ms的作为一个frame;
同时我们如果想表达整个句子的话,需要 往前和往后调整10ms;
为什么设置25和10ms,这是前人证明过的,你只需要用就行了。
所以1s --》 100frames
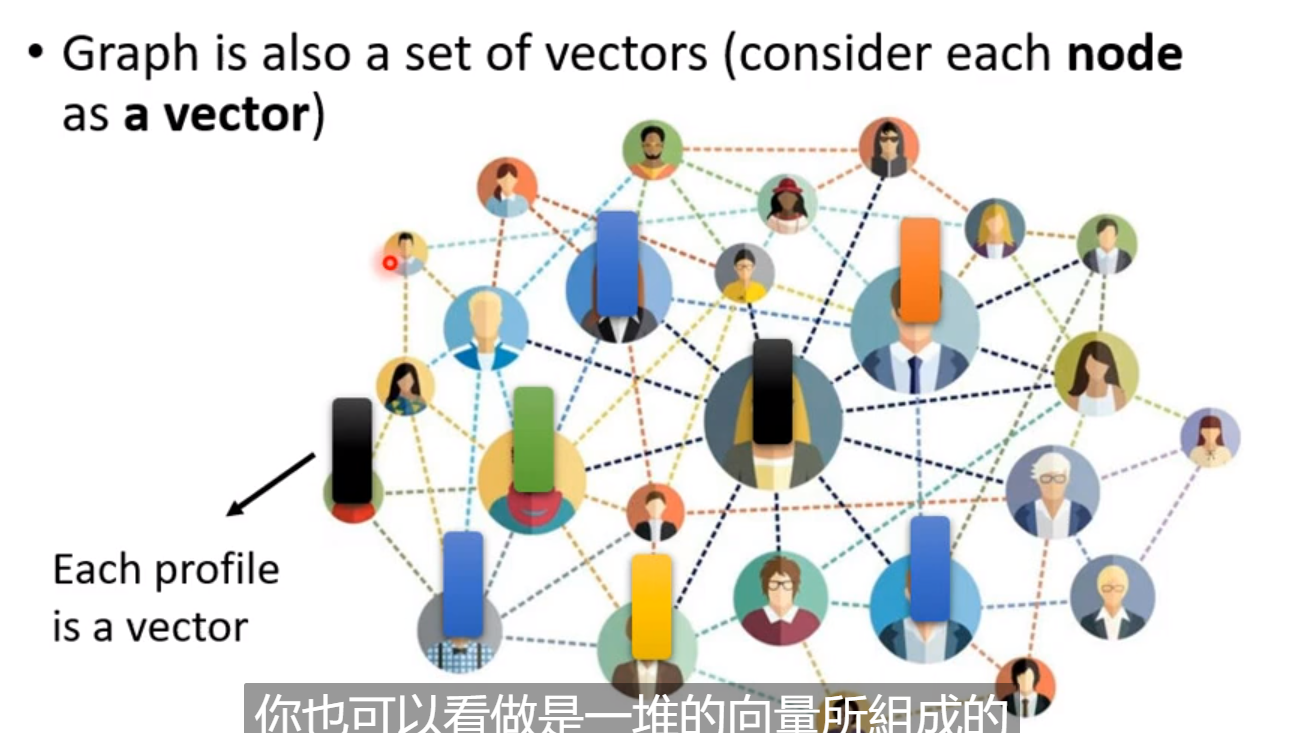
一个图
- 比如Social network中,每个人也就是每个节点就是一个向量,而每个人之间的edge就是关系,两个人可能是朋友关系或者是其它关系; 而每个人也就是每个向量就是这个人的资讯,比如它的性别、年龄和工作等等。
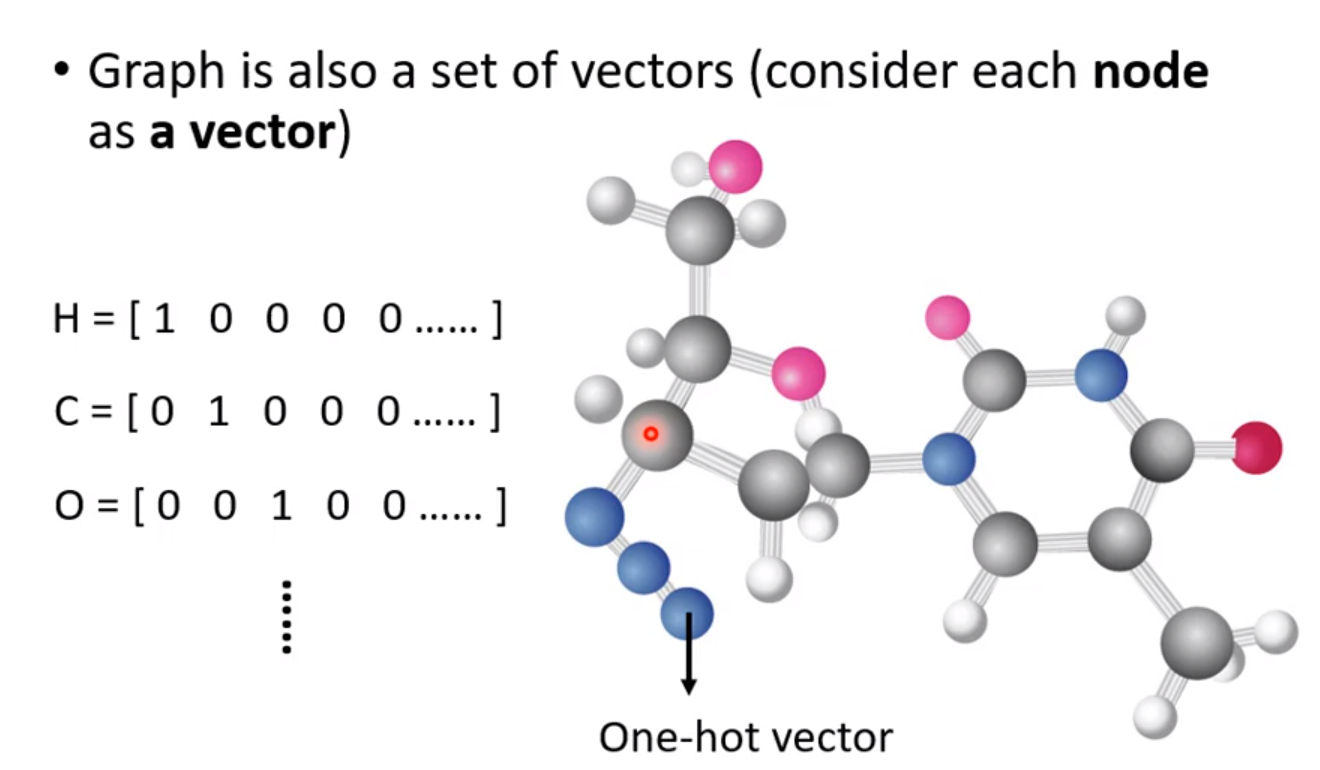
1.2 输出(以上面各个输入为基础)
三种输出可能性;
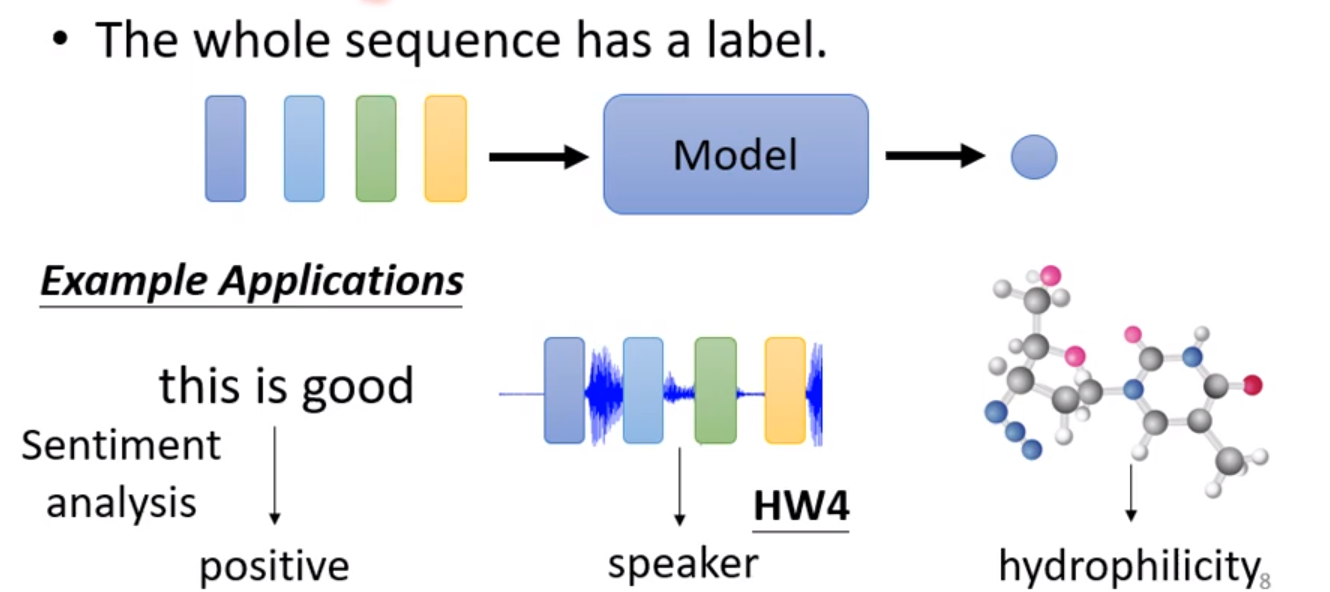
Each vector has a label

The whole sequence has a label
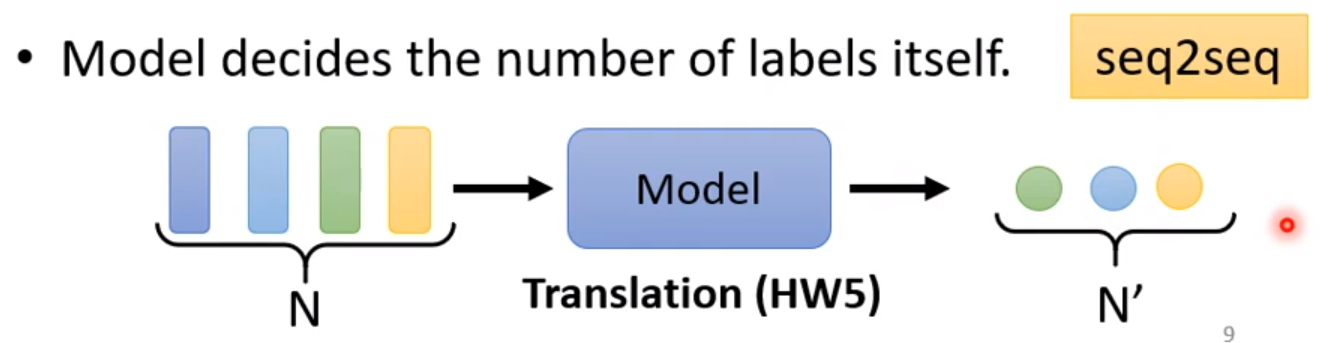
Model decides the number of labels itself(seq2seq)
2. self-attention
如果输入vector set的时候都可以使用self-attention
2.1 加入FC层
我们重点说第一种,一对一的,以Sequence Labeling为例,你要给每个向量一个label;
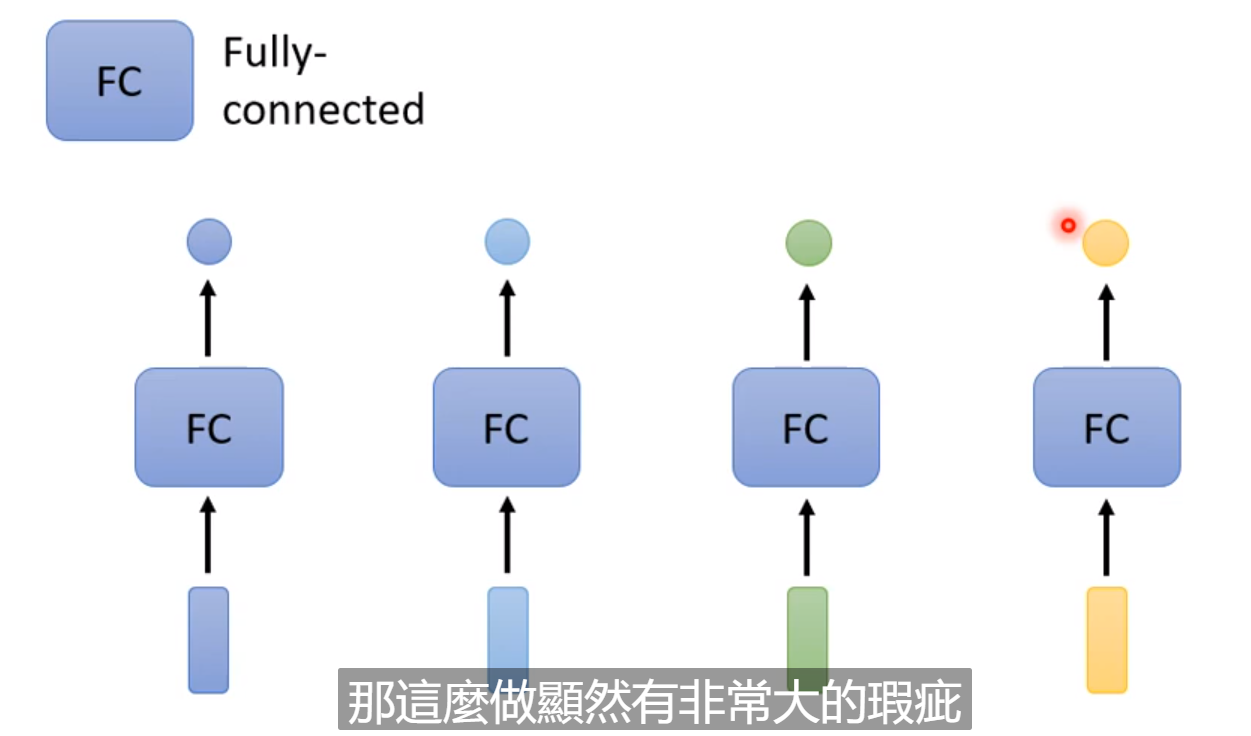
我们可以直接通过一个FC网络就可以实现了;
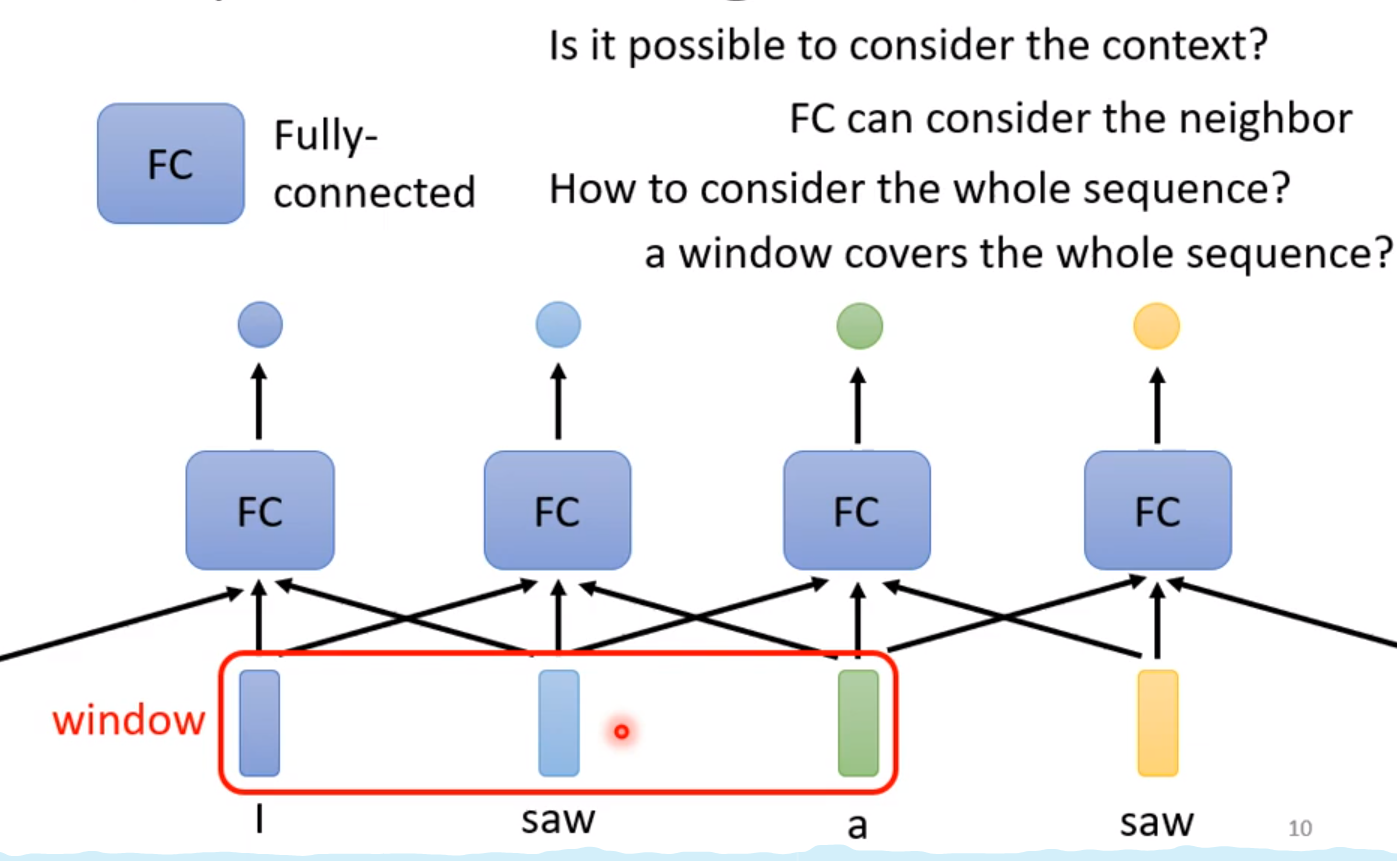
2.2 加入WIndow
但是这样就会有一个问题,你只关心一个单词的词性,如果两个单词一样的话,一个表示动词,一个表示名词,那么这样没有交集的处理会导致FC层无法处理。 所以需要让FC层考虑更多的上下文资讯。
所以我们可以扩大视野,简称window!
2.3 加入Self-attention
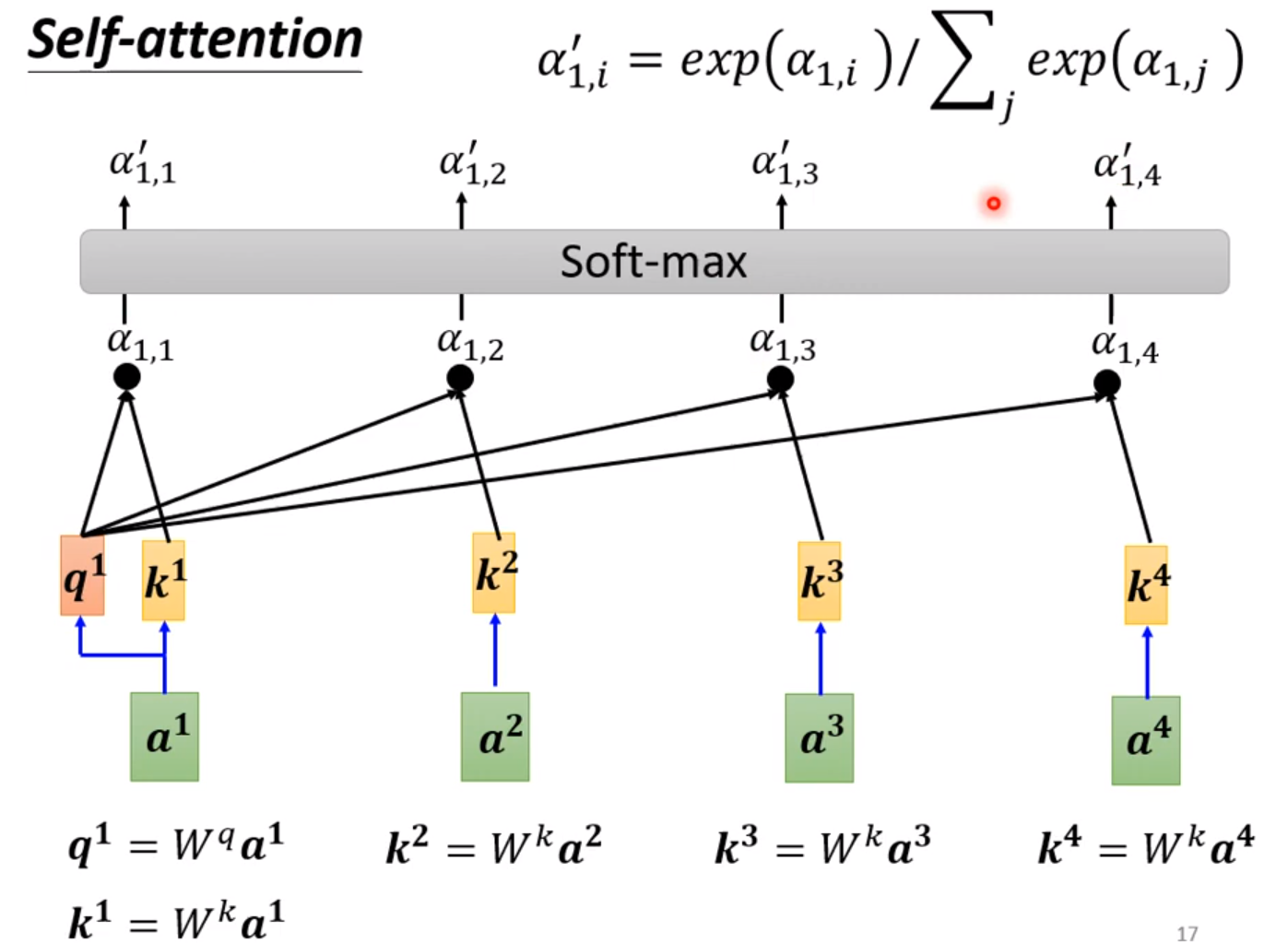
self-attention中一个标量的获得是由下面所有的一块决定的。

怎么产生 b 1 b^{1} b1; 也就需要计算KaTeX parse error: Undefined control sequence: \a at position 1: \?a?{1}和 a 2 a^{2} a2、 a 3 a^{3} a3的关系; 也就是 α 1 \alpha^{1} α1、 α 2 \alpha^{2} α2等。
而这个关系是怎么样找到的呢? 两种方法: dot-product和Additive


当然也可以进行softmax归一化! softmax不唯一,可以使用Relu、Norm等等。
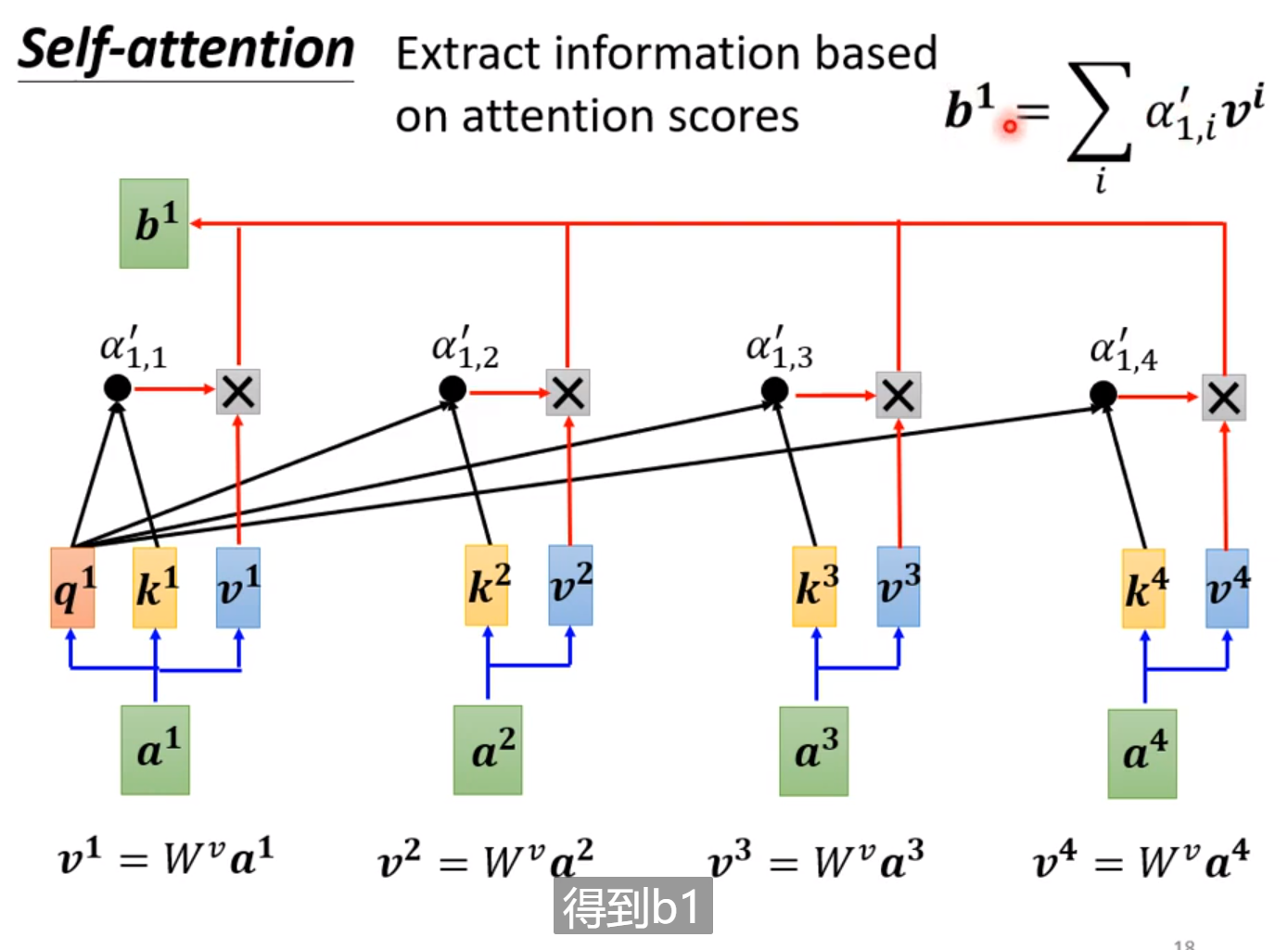
同理,我们就可以得到{ a 2 、 a 3 、 a 4 a_{2}、a_{3} 、a_{4} a2?、a3?、a4?} ―》 { b 2 、 b 3 、 b 4 b_{2}、b_{3} 、b_{4} b2?、b3?、b4?}
2.4 总结一下:
2.4.1 得到q、k、v

当然 W q 、 W k 、 W v W^{q}、W^{k}、W^{v} Wq、Wk、Wv都是矩阵!
2.4.2 得到attention score : α
下图中上方是推理第一向量得到的α的过程,下面则是将多个向量表达方式线性代数化了!
也就是K作为row, q作为了column。
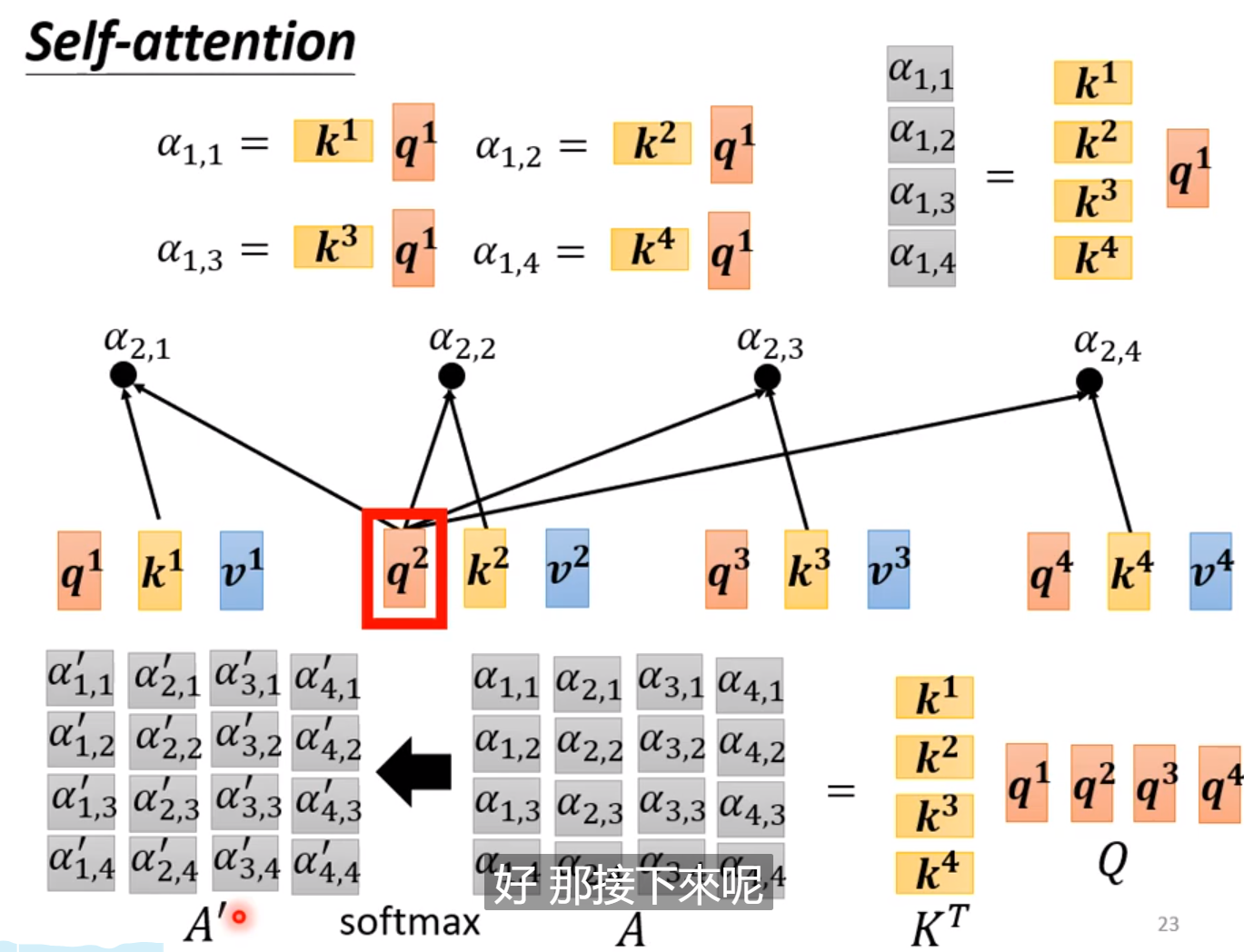
2.4.3 得到b
同样的道理
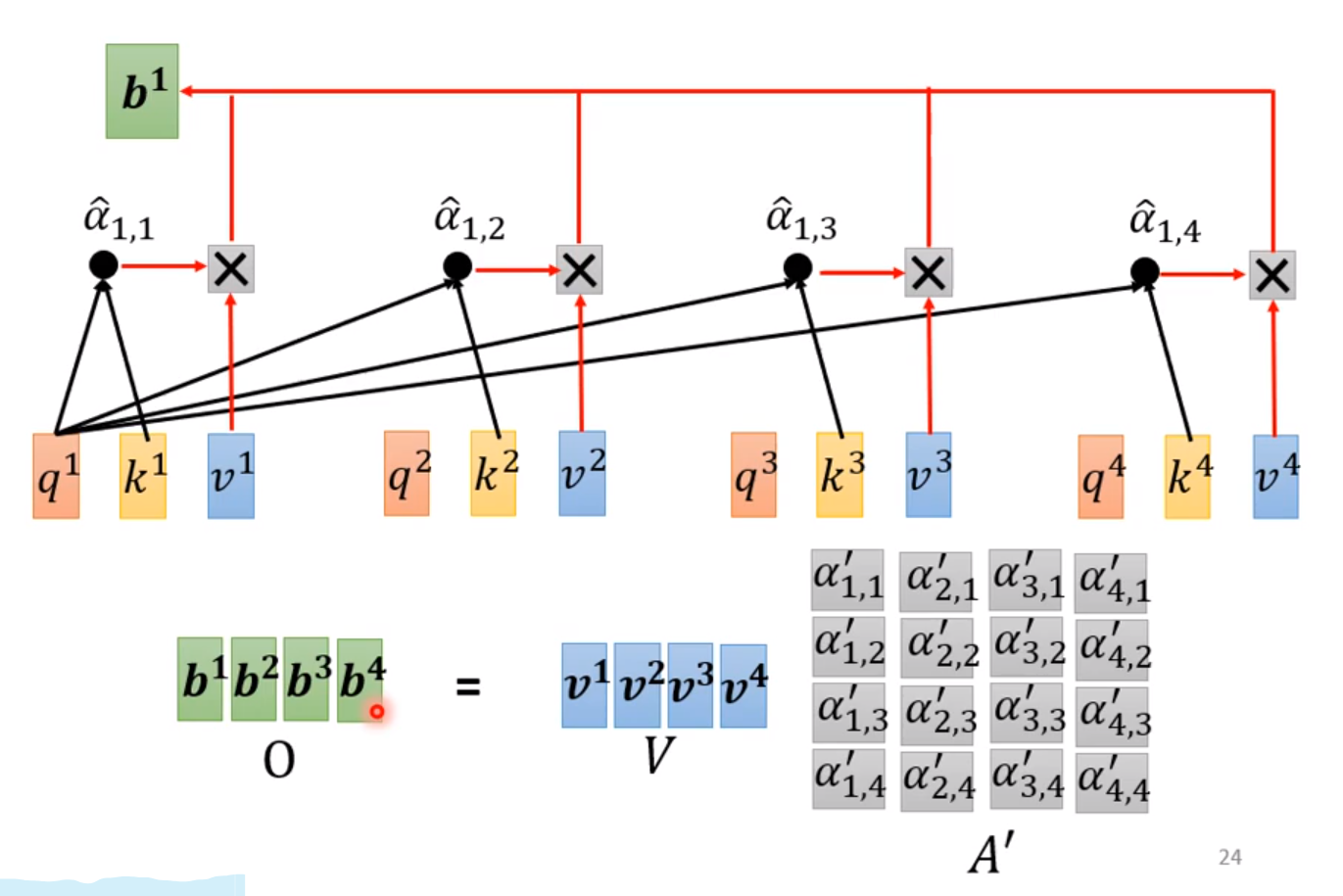
2.4.4 最后总结
输入I ―》 输出O;
中间Q是关系矩阵, A’是注意力矩阵。
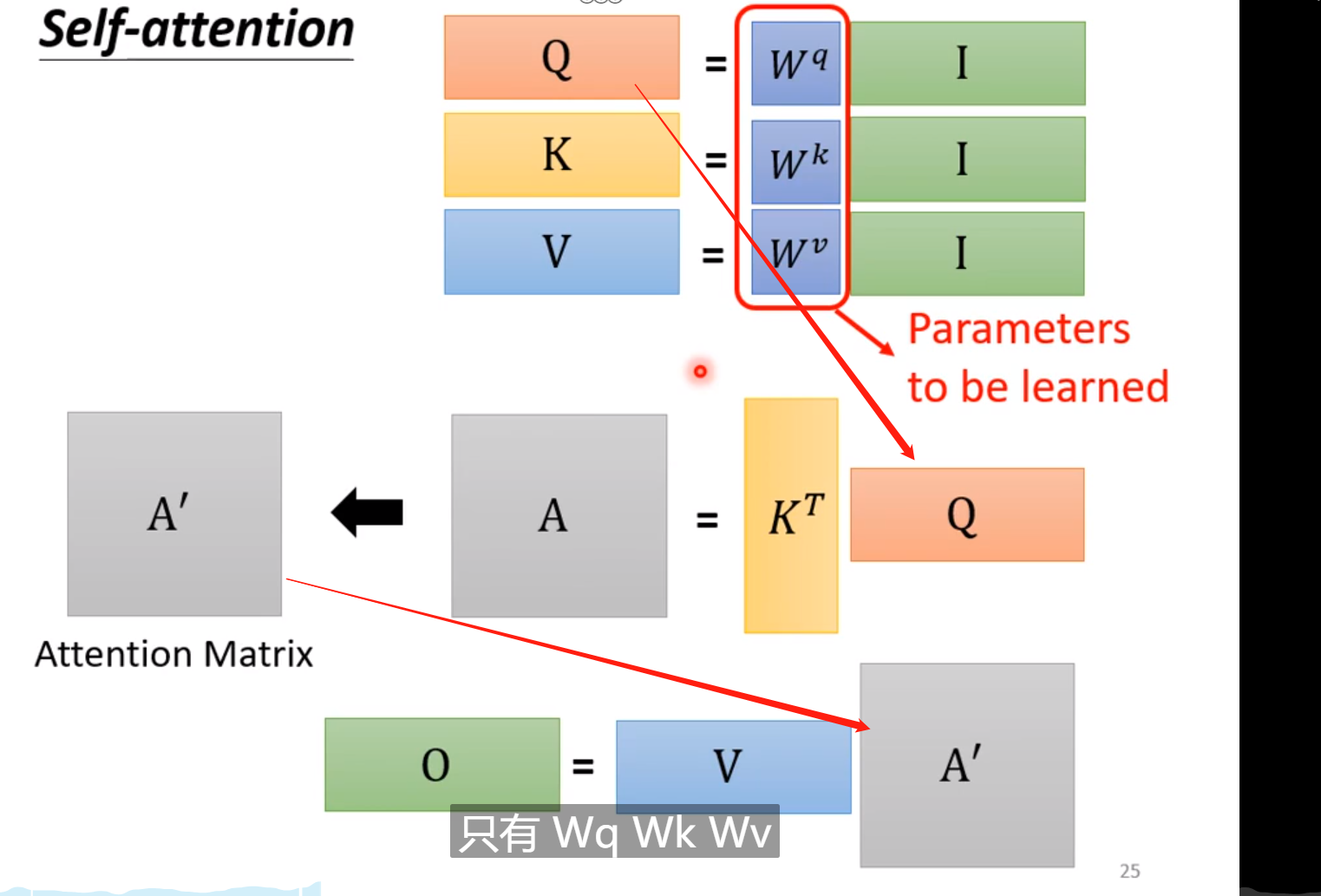
特别注意的是: 这里只有 W q 、 W k 、 W v W^{q}、W^{k}、W^{v} Wq、Wk、Wv是需要学习的,其它的都是已知的,不需要训练; 为什么呢? 自己去往上翻一翻就知道了。
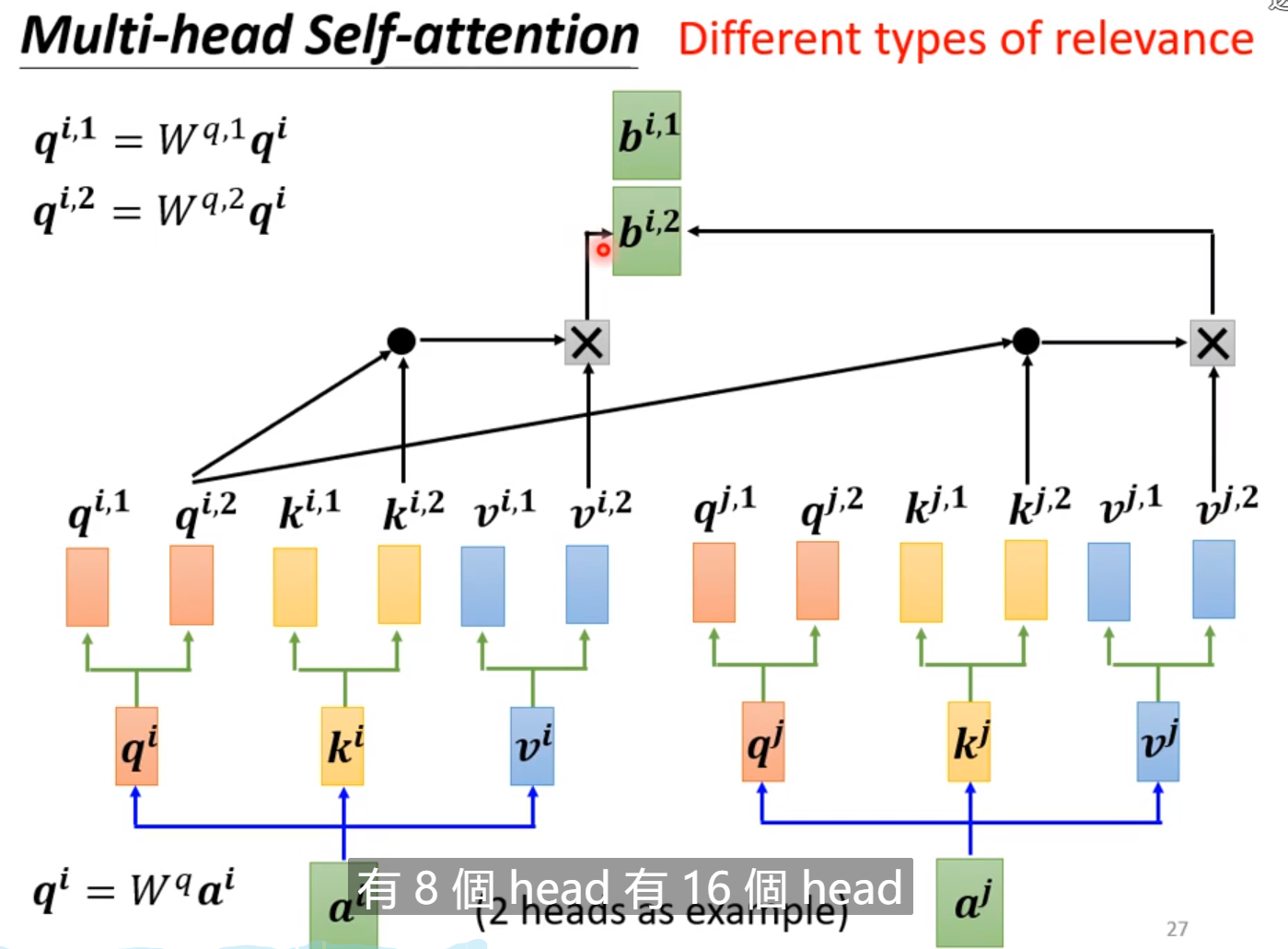
3. Multi-head self-attention
如果一件事有不同的形式,有很多不同的定义,需要多个head!不同的q 每个head是一种相关性,多个head就是多个相关性;
这个head也是一个超参数!!!

4. Position Encoding
可以看到自监督中是没有位置的定义的!
比如动词不能作为句头,动词一般充当谓语。所以需要加入位置信息。但是位置信息不是单纯的位置,而是包含了位置的其它资讯,包含了重要性(我的理解是这样的)。

所以
e
i
e^{i}
ei长什么样子呢? 最早的transformer(attention is all your need)
方法一: hand-crafted
这是人设的! 但是sequence是改变的,所以很费劲
方法二: sinusoidal或者cos
最早的
方法三: 自己炼丹吧!!这是一个尚待研究的问题
比如左下角FloATER是自己创造的

5. Many Applications
Transformer 和 Bert
语音可以、图像也可以; 具体怎么做,自己看视频,因为我是做NLP的,直接省略!
比如图像中的一个pixel多个Channel; 或者是一行;
6. Self-attention v.s CNN
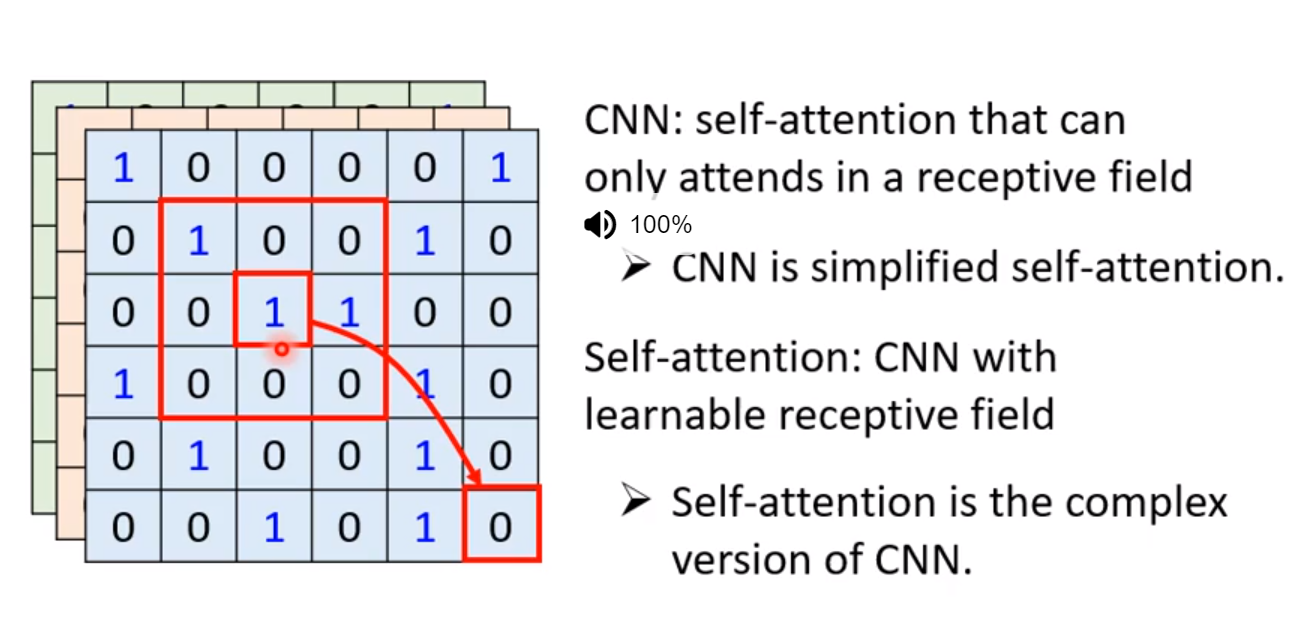
CNN是精简版的Self-attention! 因为Self-attention需要的感受野是全部的。 而在CNN中,感受野是确定的!

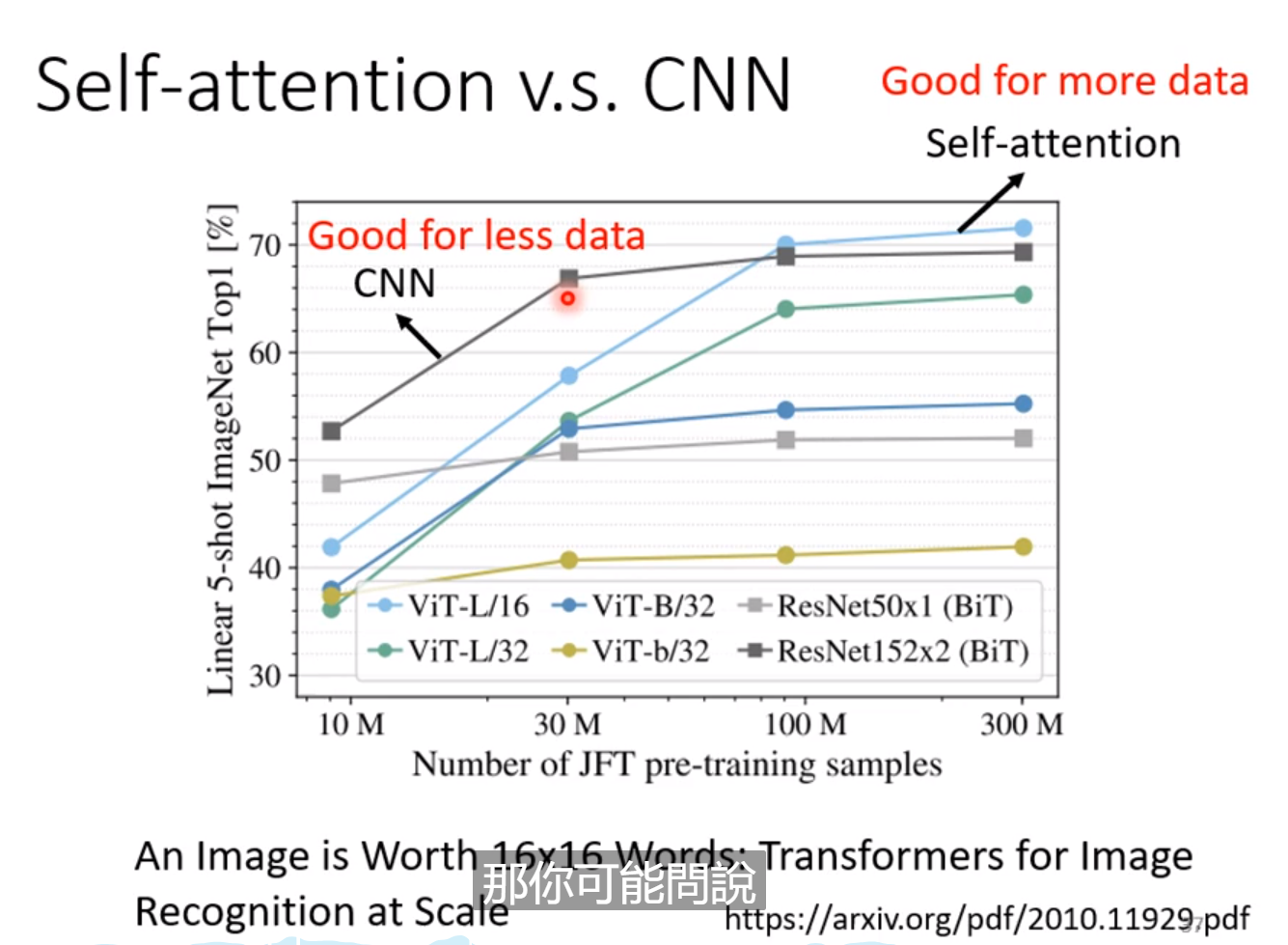
self-attention是一个flexible的model, 而且越是flexible的model越是需要更多的data,data不够,更容易overfitting;比如下面的图中, 我们比较了六个模型的分别使用CNN 和 Transformer的随着数据集量的增大后准确率的结果。 可以看出,数据集在少的时候,CNN是好的,但是随着数据集的增加,self-attention逐渐的更好。 这是因为感受野的不同的!
6. Self-attention v.s RNN
因为RNN可以被Self-attention取代,就不讲RNN了。
初始是一个memory 是预定义的!,处理的是一个sequence!
第一个RNN的block吃memory和第一个vector,然后输出新的memory和经过一个FC层来做我们需要的预测;
第二个RNN的block吃上一个吐出来的东西好第二个vector!
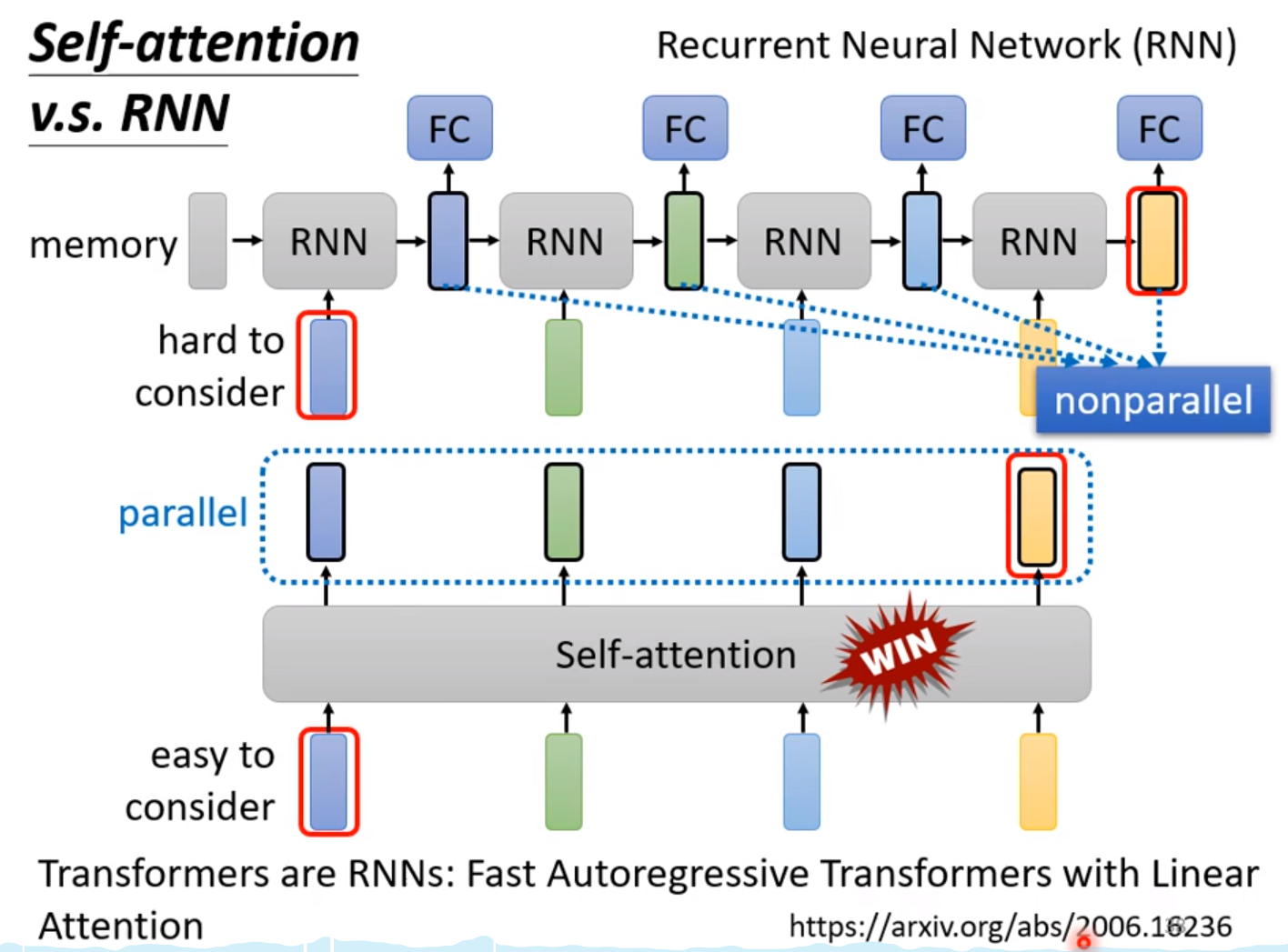
两者之间有很大的不同:
我们直观上可能感觉,RNN只考虑前几个的关系,而没有考虑全部;其实RNN也可以是双循环的,也可以认为是全部的关系; 所以这不是主要的区别。
-
天涯若比邻, self-attention中即使很远离,但是只需要计算就可以了; 而RNN中第一个和最后一个还需要经历漫长的关系,不能够忘掉。
-
不够并行处理 ; RNN是一个接着一个的;而self-attention的每个向量都是同时计算出来的。
最下面的链接将的是 ALL Transformers are RNN;
7.self-attention for graph
图的优点是有关联已经确定了,不需要再次计算了; 只需要计算强弱就行了!不需要决定有还是没有!
没有必要再学习了!
其实GNN是另一种self-attention
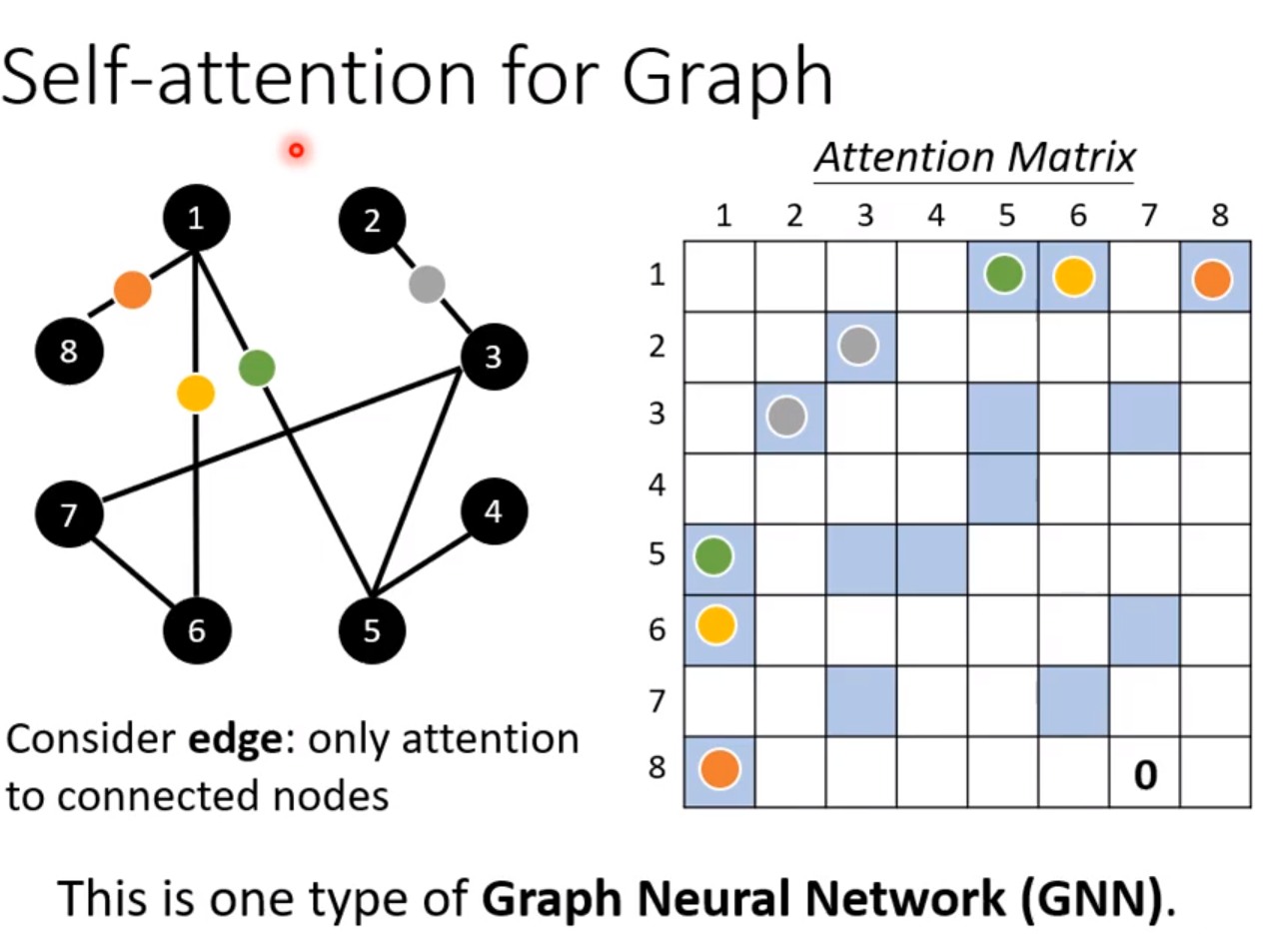
GNN水也是很深的!!
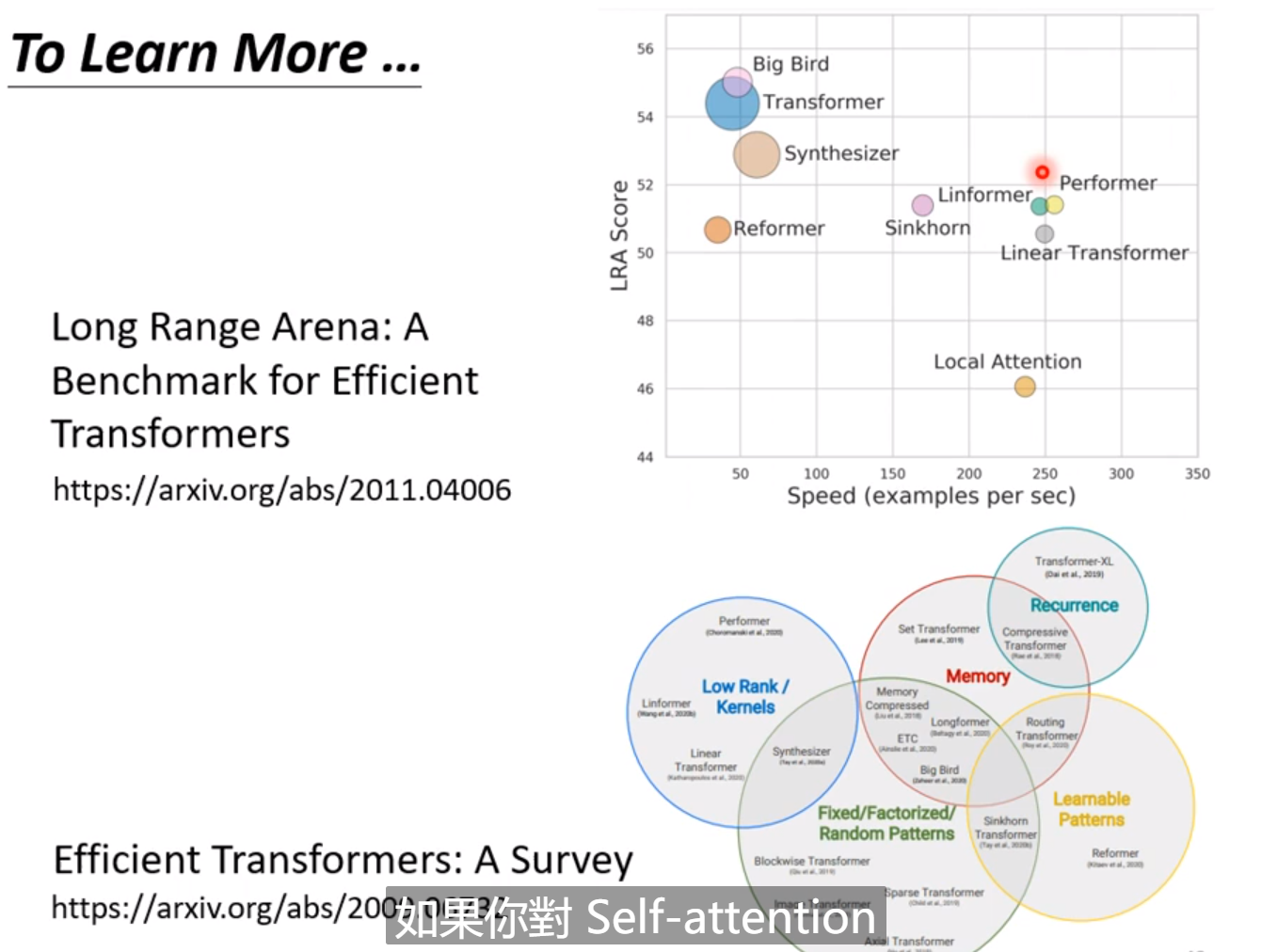
8. To learn more。。。
横轴是速度,纵轴是准确率!
self-attention 首先用在Transformer中,但是它很慢,所以才有了下面的各种变形!!
但是准确率和速度兼顾的方法还需要进一步的深究!