����Ŀ¼
��ҵ�ļ�
�����-ҽѧͼ��AI ר��γ�-��ҵ/��һ��/��һ�δ���ҵ/week3seg/C1M3_Assignmentlast.ipynb
��ӭ������ҽѧ�˹����ܡ��γ� 1 �����һ����!
����ѧϰ���ʹ�� MRI���ݹ������������Զ��ָ�����е���������
�㽫ѧϰ:
- MR ͼ������ʲô
- MRI ���ݼ��ı�����������
- �ָ�Ķ�������ʧ����
- ���ӻ��������ָ�ģ��
��ҵĿ¼
2.1 MRI data
�������ҵ��,���ǽ�����һ������ָ�ģ�������ǽ���ÿ��ͼ����ʶ�� 3 �ֲ�ͬ���쳣:ˮ�ס�����ǿ��������ǿ������
����ʹ��ITK-SNAP������һ��ͼ��ͱ�ǩ

ʹ�õ�MRI��������
Medical Segmentation Decathlon

����һ������ḻ�����ݼ�,�ṩ 3D ��ʾ��ÿ����(����)������ı�ǩ��
2.2 ̽������
���ǵ����ݼ���NifTI-1 ��ʽ�洢,���ǽ�ʹ�� NiBabel�����ļ����н�����ÿ��ѵ�������������������ļ����:
��һ���ļ���һ��ͼ���ļ�,������״Ϊ (240, 240, 155, 4) �� MR ͼ��� 4D ���С�
- ǰ 3 ��ά���� 3D �����ÿ����� X��Y �� Z ֵ,ͨ����Ϊ���ء�
- �� 4 ά�� 4 ����ͬ���е�ֵ
- 0:FLAIR����:������˥����ת�ָ���(FLAIR)
- 1:T1w:��T1 ��Ȩ��
- 2:t1gd:��T1 ��Ȩ�ŶԱȶ���ǿ��(T1-Gd)
- 3:T2w:��T2 ��Ȩ��
ÿ��ѵ��ʾ���еĵڶ����ļ���һ����ǩ�ļ�,���а���һ����״Ϊ (240, 240, 155) �� 3D ���顣
- �������е�����ֵ��ʾ��Ӧͼ���ļ���ÿ�����صġ���ǩ��:
- 0:����
- 1:ˮ��
- 2:��ǿ������
- 3:��ǿ����
���ǿ��Է����ܹ� 484 ��ѵ��ͼ��,���ǽ���Щͼ��ֳ�ѵ�� (80%) ����֤ (20%) ���ݼ���
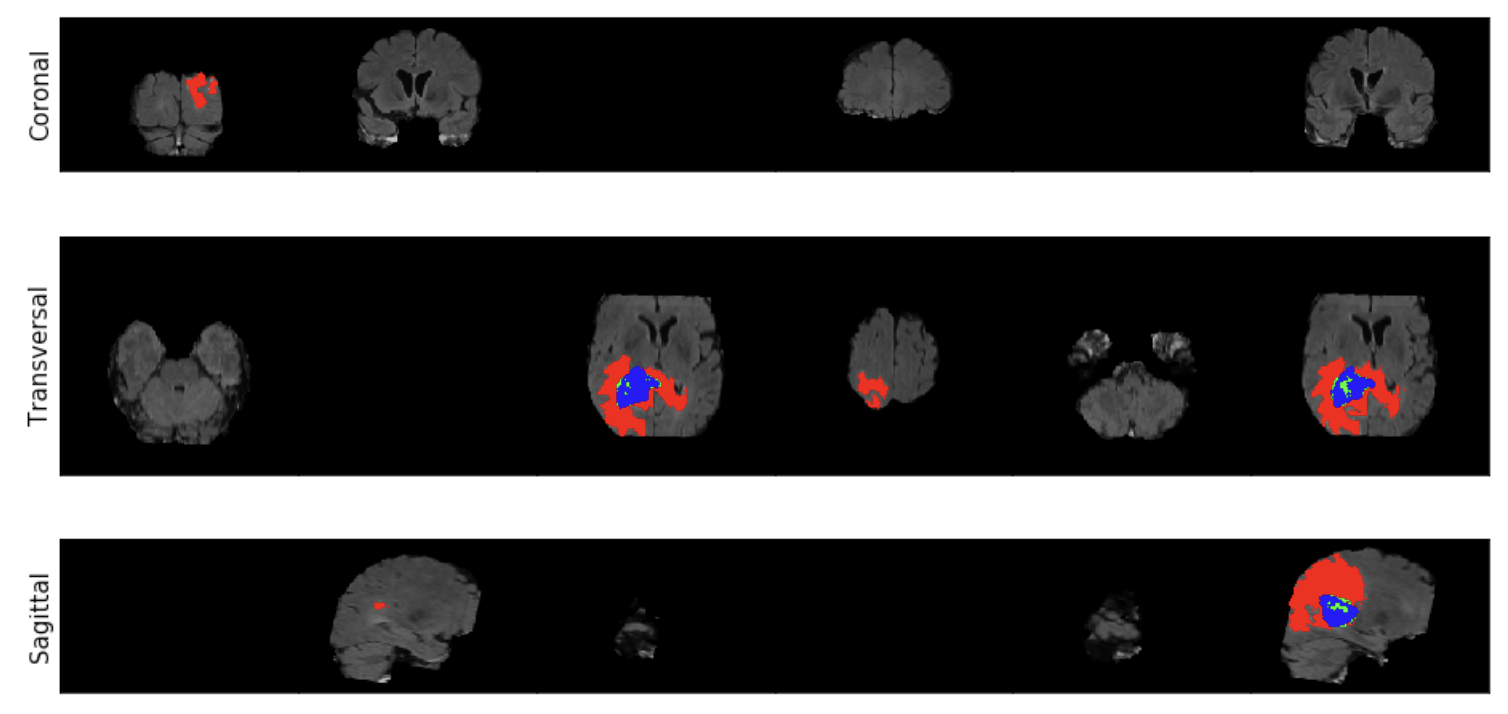
�����ǴӲ鿴һ�����������ӻ����ݿ�ʼ!������ͨ���˱ʼDZ����� 10 ����ͬ�İ���,����ǿ�ҽ��������н�һ��̽�����ݡ�
�ֱ𰴺��λ����״λ��ʸ״λ��ʾͼ��,���Ұѱ�ǩ��ʾ��ͼ����
image, label = load_case(DATA_DIR + "imagesTr/BRATS_003.nii.gz", DATA_DIR + "labelsTr/BRATS_003.nii.gz")
image = util.get_labeled_image(image, label)
util.plot_image_grid(image)
���ǻ���д��һ��ʵ�ú���,�ú�������һ��GIF,��ʾ��ÿ�����ϵ�����Ч��
image, label = load_case(DATA_DIR + "imagesTr/BRATS_003.nii.gz", DATA_DIR + "labelsTr/BRATS_003.nii.gz")
util.visualize_data_gif(util.get_labeled_image(image, label))

2.4 ʹ�� patch ��������Ԥ����
��Ȼ���ǵ����ݼ����������� NIfTI ��ʽ�ṩ�����ǵ�,���ڽ������ṩ�����ǵ�ģ��֮ǰ,������Ȼ��Ҫ��һЩС��Ԥ������
���������(sub-volumes)
���ǽ������������ݵġ�patch ������,�����Խ�����Ϊ���� MR ͼ����������
�������ɲ�����ԭ������Ϊԭʼͼ��̫��,���׳����ڴ档
���,���ǽ�ʹ������ͨ�ü��������ɿռ�һ�µ����������,��Щ������������뵽���ǵ������С�
������˵,���ǽ������ǵ�ͼ����������״Ϊ [160, 160, 16] ����������������
����,����������������,���ܻᵼ�´������ֻ������֯���ɫ����,û���κ�����,����ϣ�����ɵ�����������ٰ���һ�������������ء�
���,���ǽ�ֻѡ�������� 95% ����������(������ 5% ����)�IJ���(�������ɵ��������,�����ͷ��������ص�ռ��)
����ͨ�����ݱ�����ǩ�д��ڵ�ֵ������������һ�㡣
def get_sub_volume(image, label,
orig_x = 240, orig_y = 240, orig_z = 155,
output_x = 160, output_y = 160, output_z = 16,
num_classes = 4, max_tries = 1000,
background_threshold=0.95):
"""
Extract random sub-volume from original images.
Args:
image (np.array): original image,
of shape (orig_x, orig_y, orig_z, num_channels)
label (np.array): original label.
labels coded using discrete values rather than
a separate dimension,
so this is of shape (orig_x, orig_y, orig_z)
orig_x (int): x_dim of input image
orig_y (int): y_dim of input image
orig_z (int): z_dim of input image
output_x (int): desired x_dim of output
output_y (int): desired y_dim of output
output_z (int): desired z_dim of output
num_classes (int): number of class labels
max_tries (int): maximum trials to do when sampling
background_threshold (float): limit on the fraction
of the sample which can be the background
returns:
X (np.array): sample of original image of dimension
(num_channels, output_x, output_y, output_z)
y (np.array): labels which correspond to X, of dimension
(num_classes, output_x, output_y, output_z)
"""
# Initialize features and labels with `None`
X = None
y = None
### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###
tries = 0
while tries < max_tries:
# randomly sample sub-volume by sampling the corner voxel
# hint: make sure to leave enough room for the output dimensions!
start_x = np.random.randint(0,orig_x - output_x + 1)
start_y = np.random.randint(0,orig_y - output_y + 1)
start_z = np.random.randint(0,orig_z - output_z + 1)
# extract relevant area of label
y = label[start_x: start_x + output_x,
start_y: start_y + output_y,
start_z: start_z + output_z]
# One-hot encode the categories.
# This adds a 4th dimension, 'num_classes'
# (output_x, output_y, output_z, num_classes)
y = keras.utils.to_categorical(y,num_classes= num_classes)
# compute the background ratio
bgrd_ratio = np.sum(y[:, :, :, 0])/(output_x * output_y * output_z)
# increment tries counter
tries += 1
# if background ratio is below the desired threshold,
# use that sub-volume.
# otherwise continue the loop and try another random sub-volume
if bgrd_ratio < background_threshold:
# make copy of the sub-volume
X = np.copy(image[start_x: start_x + output_x,
start_y: start_y + output_y,
start_z: start_z + output_z, :])
# change dimension of X
# from (x_dim, y_dim, z_dim, num_channels)
# to (num_channels, x_dim, y_dim, z_dim)
X = np.moveaxis(X,3,0)
# change dimension of y
# from (x_dim, y_dim, z_dim, num_classes)
# to (num_classes, x_dim, y_dim, z_dim)
y = np.moveaxis(y,3,0)
### END CODE HERE ###
# take a subset of y that excludes the background class
# in the 'num_classes' dimension
y = y[1:, :, :, :]
return X, y
# if we've tried max_tries number of samples
# Give up in order to avoid looping forever.
print(f"Tried {tries} times to find a sub-volume. Giving up...")
����
���,���� MR ͼ���е�ֵ���ǵķ�Χ�dz��㷺,���ǽ���Щֵ����Ϊ��ֵΪ 0,����Ϊ 1��
�������ͼ�����еij��ü���,��Ϊ����ʹ���������ѧϰ��
# UNQ_C2 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)
def standardize(image):
"""
Standardize mean and standard deviation
of each channel and z_dimension.
Args:
image (np.array): input image,
shape (num_channels, dim_x, dim_y, dim_z)
Returns:
standardized_image (np.array): standardized version of input image
"""
### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###
# initialize to array of zeros, with same shape as the image
standardized_image = np.zeros(image.shape)
# iterate over channels
for c in range(image.shape[0]):
# iterate over the `z` dimension
for z in range(image.shape[3]):
# get a slice of the image
# at channel c and z-th dimension `z`
image_slice = image[c,:,:,z]
# subtract the mean from image_slice
mean=np.mean(image_slice)
centered = image_slice-mean
# divide by the standard deviation (only if it is different from zero)
std=np.std(centered)
if std != 0:
centered_scaled = centered/std
# update the slice of standardized image
# with the scaled centered and scaled image
standardized_image[c, :, :, z] = centered_scaled
### END CODE HERE ###
return standardized_image
3D U-Net
ģ��ʹ�õ���3D unet

4.1 ��������ϵ��
���˼ܹ�֮��,�κ����ѧϰ����������Ҫ��Ԫ��֮һ������ʧ������ѡ��
��������Ϥ��һ����Ȼѡ���ǽ�������ʧ������
Ȼ��,�������ص����ƽ��(ͨ��û�кܶ�������),������ʧ�������ڷָ��������롣
�ָ������һ������������ʧ�� Dice ����ϵ��,���Ǻ������������ص��̶ȵ�ָ�ꡣ
Dice = 0 ��ʾ��ȫ��ƥ, Dice =1 ��ʾ����ƥ�� ��
DSC
(
A
,
B
)
=
2
��
�O
A
��
B
�O
�O
A
�O
+
�O
B
�O
.
\text{DSC}(A, B) = \frac{2 \times |A \cap B|}{|A| + |B|}.
DSC(A,B)=�OA�O+�OB�O2���OA��B�O?.
�������ǿ��Խ�� 𝐴 �� 𝐵 ��Ϊ���ؼ�,𝐴 ��ΪԤ������������ 𝐵 �� ground truth��
���ǵ�ģ�ͻὫÿ������ӳ�䵽 0 �� 1
- 0 ��ʾ���DZ�������
- 1 ��ʾ���Ƿָ������һ���֡�
DSC ( f , x , y ) = 2 �� �� i , j f ( x ) i j �� y i j + ? �� i , j f ( x ) i j + �� i , j y i j + ? \text{DSC}(f, x, y) = \frac{2 \times \sum_{i, j} f(x)_{ij} \times y_{ij} + \epsilon}{\sum_{i,j} f(x)_{ij} + \sum_{i, j} y_{ij} + \epsilon} DSC(f,x,y)=��i,j?f(x)ij?+��i,j?yij?+?2����i,j?f(x)ij?��yij?+??
- x x x : the input image
- f ( x ) f(x) f(x) : the model output (prediction)
- y y y : the label (actual ground truth)
-
?
\epsilon
? : ��Ϊ�˱��ⱻ��������ӵ�С��

def single_class_dice_coefficient(y_true, y_pred, axis=(0, 1, 2),
epsilon=0.00001):
### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###
dice_numerator = 2 * K.sum(y_true * y_pred) + epsilon
dice_denominator = K.sum(y_true) + K.sum(y_pred) + epsilon
dice_coefficient = dice_numerator / dice_denominator
return dice_coefficient
4.2 soft dice loss
L D i c e ( p , q ) = 1 ? 2 �� �� i , j p i j q i j + ? ( �� i , j p i j 2 ) + ( �� i , j q i j 2 ) + ? \mathcal{L}_{Dice}(p, q) = 1 - \frac{2\times\sum_{i, j} p_{ij}q_{ij} + \epsilon}{\left(\sum_{i, j} p_{ij}^2 \right) + \left(\sum_{i, j} q_{ij}^2 \right) + \epsilon} LDice?(p,q)=1?(��i,j?pij2?)+(��i,j?qij2?)+?2����i,j?pij?qij?+??
- p p p is our predictions
- q q q is the ground truth
- q i q_i qi? �� 0 or 1.
soft dice loss ���� 1-DSC
����Ƕ����,�Ͱ�ÿ������ DSC �ۼ�����:
L
D
i
c
e
(
p
,
q
)
=
1
?
1
N
��
c
=
1
C
2
��
��
i
,
j
p
c
i
j
q
c
i
j
+
?
(
��
i
,
j
p
c
i
j
2
)
+
(
��
i
,
j
q
c
i
j
2
)
+
?
\mathcal{L}_{Dice}(p, q) = 1 - \frac{1}{N} \sum_{c=1}^{C} \frac{2\times\sum_{i, j} p_{cij}q_{cij} + \epsilon}{\left(\sum_{i, j} p_{cij}^2 \right) + \left(\sum_{i, j} q_{cij}^2 \right) + \epsilon}
LDice?(p,q)=1?N1?c=1��C?(��i,j?pcij2?)+(��i,j?qcij2?)+?2����i,j?pcij?qcij?+??
def soft_dice_loss(y_true, y_pred, axis=(1, 2, 3),
epsilon=0.00001):
dice_numerator = 2. * K.sum(y_true * y_pred, axis = axis) + epsilon
dice_denominator = K.sum(y_true**2, axis = axis) + K.sum(y_pred**2, axis = axis) + epsilon
dice_loss = 1 - K.mean(dice_numerator / dice_denominator)
return dice_loss
5 ����ģ��
model = util.unet_model_3d(loss_function=soft_dice_loss, metrics=[dice_coefficient])
ģ���� utils.py �ļ����ṩ
5.1 ѵ��
�������ѵ��ģ��,��5.1 �Ĵ�������һ��
6 ����
ѵ���õ�ģ��,û�и������,������Լ�ѵ��һ��ģ��,������������ֱ���Ķ�������������,����ʵ����
���ڷָ�ģ��,����ͬ�����Լ��� ���ж�,������

�����Կ��ӻ�Ԥ����

���³�������,���Թ�ע�Ź��ںš�ҽѧͼ���˹�����ʵսӪ����ȡ���¶�̬,һ����ע��ҽѧͼ��������ǰ�ؿƼ��Ĺ��ںš������ʵ��Ϊ��,�ְ��ִ�������Ŀ,�����,д���ġ���ԭ�����½��ṩ���۽���,ʵ�����,ʵ�����ݡ�ֻ��ʵ�����ܳɳ��ĸ���,��ע����,һ��ѧϰ����~
����Tina, ������ƪ���ͼ�~
���칤������д��,Ż����Ѫ
����д�IJ����Ļ����,�����,����,�ղء�����һ������
