1. ��������
1.1 ����ѧϰ����
֮ǰ�����ܽ��������,�ع����Ļ������̺ͷ���������,�������Ի��ֵ�ԭ�����һ�����,�����������Զ���,���ǵ��ǻ���������ķ���:
��˼����ͨ����ֵ1��������1���л��ֳ������Ӽ�,�����Ӽ��ڷ���ԽСԽ��,���ջع�Ԥ����Ϊÿ������Ԥ�������ֵ��
����ѧϰ(Esemble Learning)��˼����ǹ�������϶��ѧϰ�����ѧϰ����:
{
ѧ
ϰ
��
1
:
f
1
(
X
)
ѧ
ϰ
��
2
:
f
2
(
X
)
.
.
.
ѧ
ϰ
��
n
:
f
n
(
X
)
}
��
��
��
��
ѧ
ϰ
��
\begin{Bmatrix} ѧϰ��1: & f_1(X) \\ ѧϰ��2: & f_2(X)\\ ...\\ ѧϰ��n: & f_n(X) \end{Bmatrix}��϶��ѧϰ��
????????ѧϰ��1:ѧϰ��2:...ѧϰ��n:?f1?(X)f2?(X)fn?(X)?????????��������ѧϰ��
�����ּ��ɵIJ�����һ���ܽ�,����ѧϰ(Esemble Learning)��Ϊ����:
- Bagging:bootstrap aggregating����д,bootstrapҲ��Ϊ������,����һ���зŻصij�������,��Bagging������,����bootstrap�������������ݼ��в�ȡ�зŻس����õ�N�����ݼ�,��ÿ�����ݼ���ѧϰ��һ��ģ��,����Ԥ��������N��ģ�͵�����õ�,�����:�����������N��ģ��Ԥ��ͶƱ�ķ�ʽ,�ع��������N��ģ��Ԥ��ƽ���ķ�ʽ���Ƚϵ��͵ľ������ɭ��;
- Boosting:��������(Boosting)��һ�ֿ���������С�ලѧϰ��ƫ��Ļ���ѧϰ�㷨����ҪҲ��ѧϰһϵ����������,���������Ϊһ��ǿ���������Ƚϵ��͵���Adaboost��GBDT��XGBoost;
- Stacking:Stacking������ָѵ��һ��ģ�����������������ģ�͡�����������ѵ�������ͬ��ģ��,Ȼ���֮ǰѵ���ĸ���ģ�͵����Ϊ������ѵ��һ��ģ��,�Եõ�һ�����յ������������,Stacking���Ա�ʾ�����ᵽ������Ensemble����,ֻҪ���Dz��ú��ʵ�ģ����ϲ��Լ��ɡ�����ʵ����,����ͨ��ʹ��logistic�ع���Ϊ��ϲ��ԡ�
1.2 Boosting����㷨
��һС�ھ���һ��Boosting���ģ��,�ܽ��λ,��ӭ����������ָ��,��ཻ����
Boosting�Ļ���˼��������һ��ѧϰ�������һ��ѧϰ���IJв�:
��ʼѧϰ������Ϊ���� X X X,Ԥ��Ŀ������ʵֵ Y Y Y,������һ��ѧϰ��,��Ԥ��Ŀ����Ϊ��һ��ѧϰ��ѧϰ�õ��IJв�: y ^ ? y \hat y-y y^??y��
1.2.2 BDT
BDT(Boosting Decision Tree)�ĺ���˼������:
- �ӷ�ģ��:��������M�����ĺ� f M ( x ) = �� m = 1 M T ( x , �� m ) f_M(x)=\sum_{m=1}^{M}T(x,\theta_m) fM?(x)=m=1��M?T(x,��m?)
- ǰ��ֲ��㷨: L ( y i , f M ( x ) ) = > L [ y i , f M ? 1 ( x ) + T ( x , �� M ) ] L(y_i,f_M(x))=>L[y_i,f_{M-1}(x)+T(x,\theta_M)] L(yi?,fM?(x))=>L[yi?,fM?1?(x)+T(x,��M?)]
- f m ( x ) = f m ? 1 ( x ) + T ( x , �� m ) , f 0 ( x ) = 0 f_m(x)=f_{m-1}(x)+T(x,\theta_m),f_0(x)=0 fm?(x)=fm?1?(x)+T(x,��m?),f0?(x)=0
1.2.3 AdaBoost
AdaBoost����˼��:
����ע�ĵ���ڱ��������������ϡ�
- ��ʼ��������Ȩ�طֲ����� D m D_m Dm?;
- ʹ�þ���Ȩ�طֲ� D m D_m Dm?�����ݼ�����ѧϰ,�õ��������� G m ( x ) G_m(x) Gm?(x);
- ���� G m ( x ) G_m(x) Gm?(x)��ѵ�����ݼ��ϵķ��������: e m = �� i = 1 N w m , i ( �� �� Ȩ �� ) I ( G m ( x i ) �� y i ) e_m=\sum_{i=1}^Nw_{m,i}(����Ȩ��)I(G_m(x_i)\neq y_i) em?=i=1��N?wm,i?(����Ȩ��)I(Gm?(xi?)��?=yi?)
- ���� G m ( x ) G_m(x) Gm?(x)��ǿ�������еı���: �� m = 1 2 l o g 1 ? e m e m \alpha_m=\frac {1}{2}log\frac {1-e_m}{e_m} ��m?=21?logem?1?em??
- ����ѵ������Ȩ�طֲ�: w m + 1 , i = w m , i z m e x p ( ? �� m y i G m ( x i ) ) , i = 1 , 2 , . . . , N w_{m+1,i}=\frac{w_{m,i}}{z_m}exp(-\alpha_my_iG_m(x_i)),i=1,2,...,N wm+1,i?=zm?wm,i??exp(?��m?yi?Gm?(xi?)),i=1,2,...,N z m = �� i = 1 N w m , i e x p ( ? �� m y i G m ( x i ) ) z_m=\sum_{i=1}^{N}w_{m,i}exp(-\alpha_my_iG_m(x_i)) zm?=i=1��N?wm,i?exp(?��m?yi?Gm?(xi?))
- �ظ�1-5�IJ��蹹����������;
- ���շ�����: F ( x ) = s i g n ( �� i = 1 N �� m G m ( x ) ) F(x)=sign(\sum_{i=1}^N\alpha_mG_m(x)) F(x)=sign(i=1��N?��m?Gm?(x))
��ʧ����: L o s s = �� i = 1 N e x p ( ? y i F m ( x i ) ) Loss=\sum_{i=1}^Nexp(-y_iF_m(x_i)) Loss=i=1��N?exp(?yi?Fm?(xi?)) = �� i = 1 N e x p ( ? y i F m ? 1 ( x i ) + �� m G m ( x i ) ) =\sum_{i=1}^Nexp(-y_iF_{m-1}(x_i)+ \alpha_mG_m(x_i)) =i=1��N?exp(?yi?Fm?1?(xi?)+��m?Gm?(xi?))
1.2.4 GBDT
GBDT(Gradient Boosting Decision Tree)�ݶ�����������˼��:
��ʧ����(��������)��Y��ƫ�������滻֮ǰBDT����ϲв��˼��:
- �ӷ�ģ��: h ( x ) = �� m = 1 M �� m f m ( x ) h(x)=\sum_{m=1}^M\beta_mf_m(x) h(x)=m=1��M?��m?fm?(x)
- ��ʧ����:
��
i
=
1
M
L
(
y
i
,
��
m
=
1
M
f
m
(
x
)
)
\sum_{i=1}^ML(y_i, \sum_{m=1}^Mf_m(x))
i=1��M?L(yi?,m=1��M?fm?(x))
��
m
=
1
M
L
(
y
i
,
h
m
?
1
+
f
m
(
x
)
)
\sum_{m=1}^ML(y_i,h_{m-1}+f_m(x))
m=1��M?L(yi?,hm?1?+fm?(x))
�����ʧ����ʱ����һ��̩��չ��,�Ӷ�ʹ�ú�һ��ѧϰ������ǰһ��ѧϰ�����ݶȽ���ѧϰ��
1.2.5 XGBoost
������������ݡ�
�����:
����ѧϰ(Esemble Learning)
2. XGboost���
������İ�װ�����������
xgbbost��İ�װ:
# windows
pip install xgboost
pip install --upgrade xgboost
# mac
brew install gcc@7
pip3 install xgboost
ʹ��xgboost��:
import xgboost as xgb
# ��ȡ����
xgb.DMatrix()
# ����
param = {}
# ѵ��ģ��
bst = xgb.train(param)
# Ԥ����
bst.predict()
xgboost�IJ���һ��:


sklearn�е�xgboost��API����һ��:

2.1 �ݶ�������
2.1.1 ��Ҫ����:n_estimators
�����ݶ�����������,����ͻع�Ľ��ͨ�����·�ʽ����:
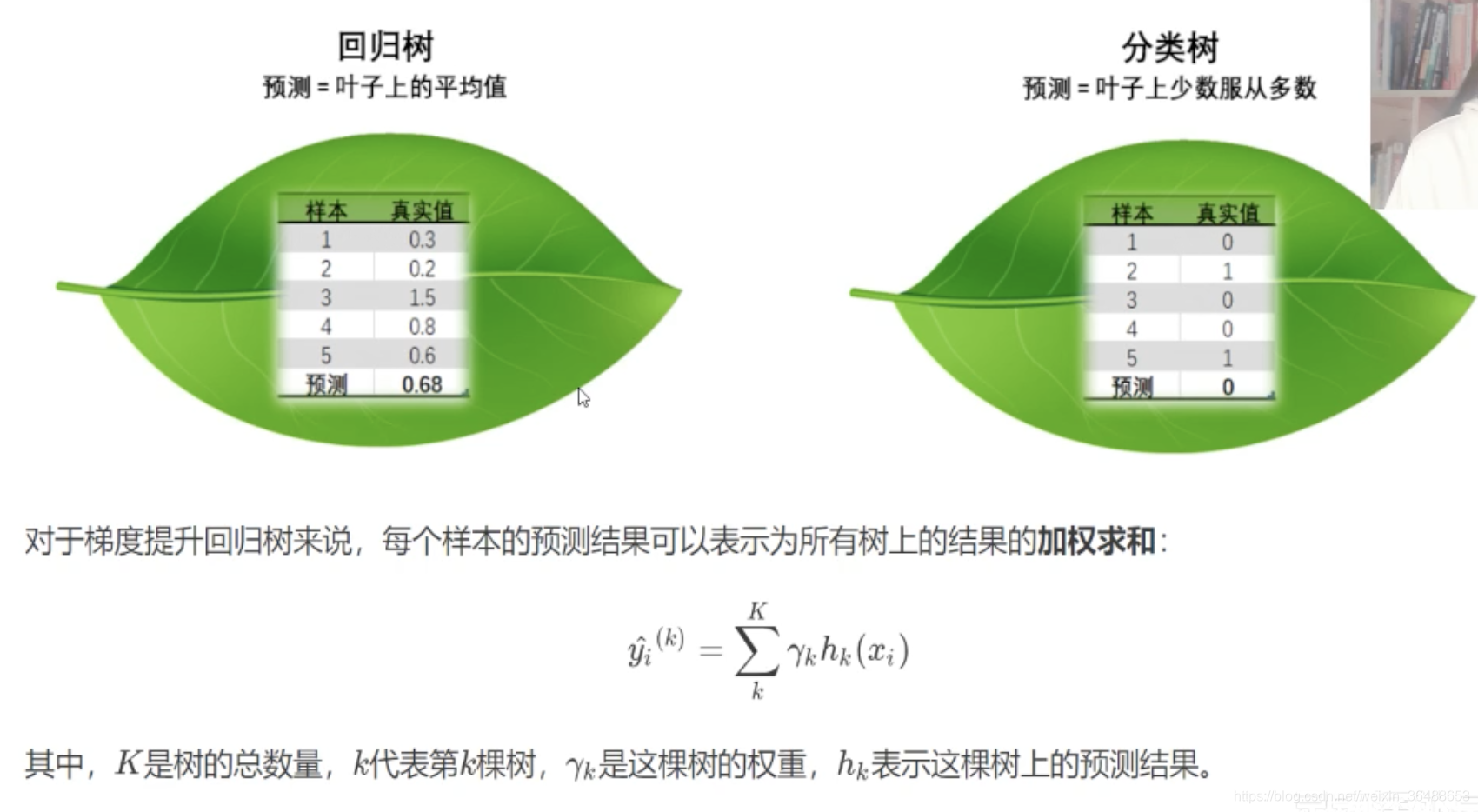
����XGBoost����,ÿ��Ҷ�ӽ���ϻ���һ��Ԥ�����,Ҳ����ΪҶ��Ȩ��,��
f
k
(
x
i
)
f_k(x_i)
fk?(xi?)����
��
\omega
������ʾ,����
f
k
f_k
fk?��ʾ��
k
k
k�þ�����,
x
i
x_i
xi?��ʾ����
i
i
i��Ӧ�����������������������ģ���й���
K
K
K�þ�����,������ģ�����������
i
i
i�ϵ�Ԥ����Ϊ:
y
^
i
k
=
��
k
K
f
k
(
x
i
)
\hat y_i^k=\sum_k^{K}f_k(x_i)
y^?ik?=k��K?fk?(xi?)
xgboost��sklearn��API�������������ij�����:
��ʹ��:
from xgboost import XGBRegressor as XGBR
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.linear_model import LinearRegression as LinearR
from sklearn.datasets import load_boston
from sklearn.model_selection import KFold, cross_val_score as CVS, train_test_split as TTS
from sklearn.metrics import mean_squared_error as MSE
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from time import time
import datetime
data = load_boston()
X = data.data
y = data.target
Xtrain, Xtest, Ytrain, Ytest = TTS(X, y, test_size=0.3, random_state=420)
# ��ͬģ�͵ĶԱ�
reg = XGBR(n_estimators=100).fit(Xtrain, Ytrain)
reg.predict(Xtest)
print(reg.score(Xtest, Ytest))
print(MSE(Ytest, reg.predict(Xtest)))
# �鿴ģ����Ҫ�Է���(��ģ�͵�����)
print(reg.feature_importances_)
reg = XGBR(n_estimators=100)
print(CVS(reg, Xtrain, Ytrain, cv=5).mean())
print(CVS(reg, Xtrain, Ytrain, cv=5, scoring="neg_mean_aquares_score").mean())
print(sorted(sklearn.metrics.SCORERS.keys()))
rfr = RFR(n_estimators=100)
print(CVS(rfr, Xtrain, Ytrain, cv=5).mean())
print(CVS(rfr, Xtrain, Ytrain, cv=5, scoring="neg_mean_aquares_score").mean())
lr = LinearR()
print(CVS(lr, Xtrain, Ytrain, cv=5).mean())
print(CVS(lr, Xtrain, Ytrain, cv=5, scoring="neg_mean_aquares_score").mean())
# �鿴�����Ĺ���,��ӡ����
reg = XGBR(n_estimators=100, silent=False).fit(Xtrain, Ytrain)
print(CVS(reg, Xtrain, Ytrain, cv=5, scoring="neg_mean_aquares_score").mean())
# ����ѧϰ���ߺ���
from sklearn.model_selection import learning_curve
import matplotlib.pyplot as plt
import numpy as np
def plot_learning_curve(estimator, title, X, y, ax=None, ylim=None, cv=None, n_jobs=None):
train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, shuffle=True, cv=cv,
random_state=420, n_jobs=n_jobs)
if ax == None:
ax = plt.gca()
else:
ax = plt.figure()
ax.set_title(title)
if ylim:
ax.set_ylim(*ylim)
ax.set_xlabel("Training examples")
ax.set_ylabel("Score")
ax.grid()
ax.plot(train_sizes, np.mean(train_scores, axis=1), "o-", color='r', label="Training score")
ax.plot(train_sizes, np.mean(test_scores, axis=1), "o-", color='g', label="Test score")
ax.legend(loc="best")
return ax
cv = KFold(n_splits=5, shuffle=True, random_state=42)
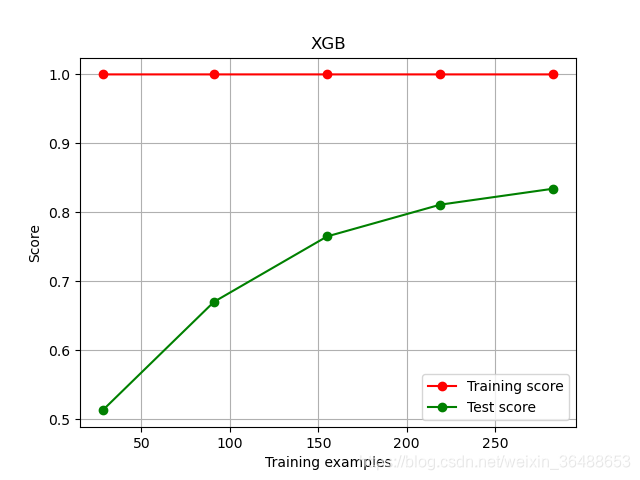
plot_learning_curve(XGBR(n_estimators=100, random_state=420), "XGB", Xtrain, Ytrain, ax=None, cv=cv)
plt.show()
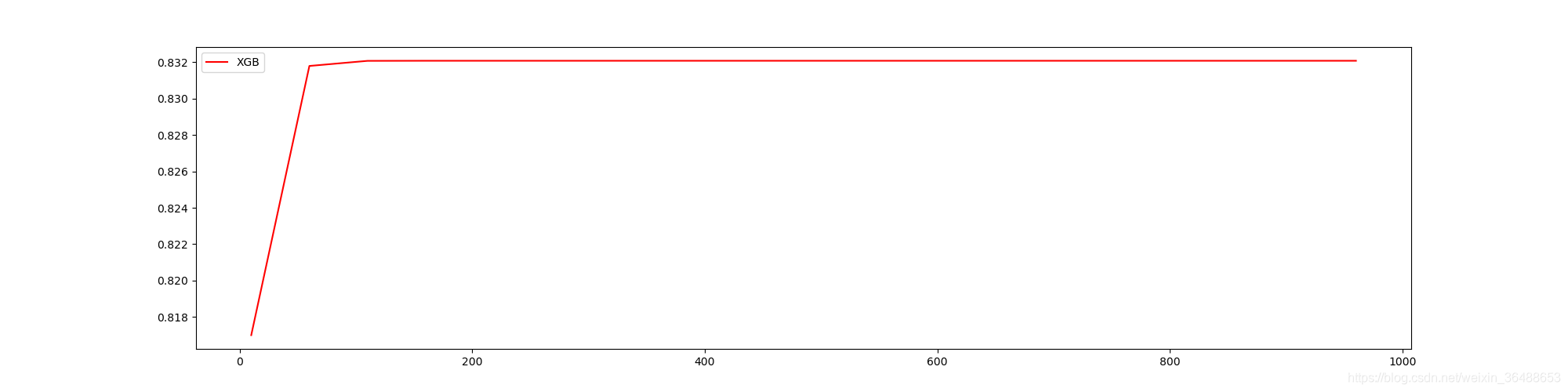
# ʹ��ѧϰ���߹۲�n_estimators��ģ�͵�Ӱ��
# ����ѧϰ����
cv = KFold(n_splits=5, shuffle=True, random_state=42)
axisx = range(10, 1010, 50)
rs = []
for i in axisx:
reg = XGBR(n_estimators=i, random_state=420)
rs.append(CVS(reg, Xtrain, Ytrain, cv=cv).mean())
print(axisx[rs.index(max(rs))], max(rs)) # 160 0.8320776498992342
plt.figure(figsize=(20, 5))
plt.plot(axisx, rs, c="red", label="XGB")
plt.legend()
plt.show()
# ������ѧϰ����:�����뷺�����
axisx = range(50, 1050, 50)
# ϸ����Χrange(100, 300, 10)
rs = []
var = []
ge = []
for i in axisx:
reg = XGBR(n_estimators=i, random_state=420)
cvresult = CVS(reg, Xtrain, Ytrain, cv=cv)
# ��¼ƫ��
rs.append(cvresult.mean())
# ��¼����
var.append(cvresult.var())
# ���㷺�����Ŀɿز���
ge.append(1 - cvresult.mean() ** 2 + cvresult.var())
# ��ӡR2�������Ӧ�IJ���ȡֵ, ����ӡ��������µķ�����
print(axisx[rs.index(max(rs))], max(rs), var[rs.index(max(rs))])
# ��ӡ�������ʱ��Ӧ�IJ���ȡֵ, ����ӡ��������µ�R2
print(axisx[var.index(min(var))], rs[var.index(min(var))], min(var))
# ��ӡ�������ɿز��ֵIJ���ȡֵ,����ӡ��������µ�R2,�����Լ��������Ŀɿز���
print(axisx[ge.index(min(ge))], rs[ge.index(min(ge))], var[ge.index(min(ge))], min(ge))
# ���ӷ����ߵĻ���
rs = np.array(rs)
var = np.array(var) * 0.01
plt.figure(figsize=(20, 5))
plt.plot(axisx, rs, c="black", label="XGB")
plt.plot(axisx, rs+var, c="red", linestyle="-.")
plt.plot(axisx, rs-var, c="red", linestyle="-.")
plt.legend()
plt.show()
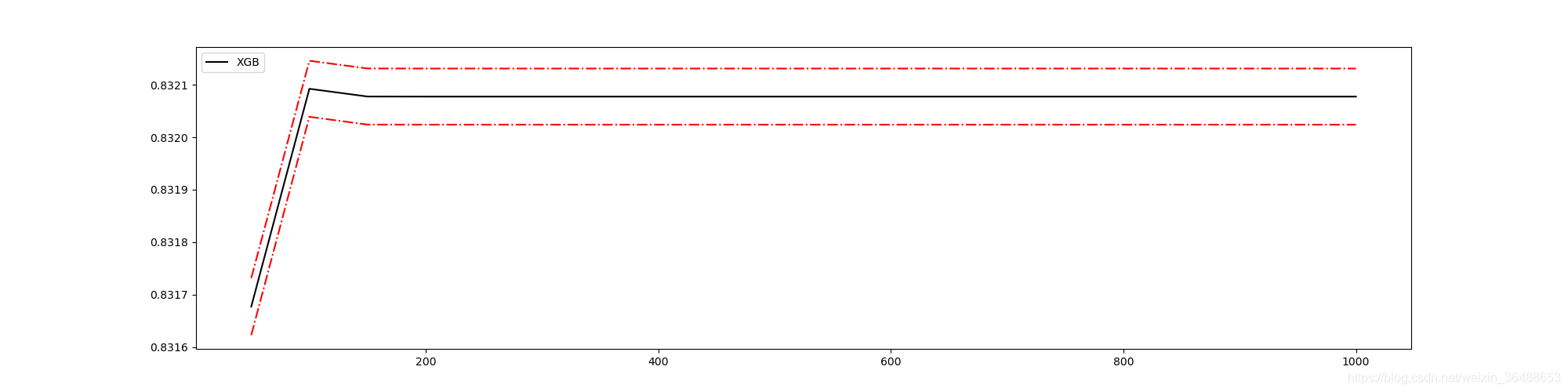
��֤ģ��Ч��:
time0 = time()
print(XGBR(n_estimators=100, random_state=420).fit(Xtrain, Ytrain).score(Xtest, Ytest))
print(time()-time0)
# 0.9050988968414799
# 0.13734769821166992
time0 = time()
print(XGBR(n_estimators=660, random_state=420).fit(Xtrain, Ytrain).score(Xtest, Ytest))
print(time()-time0)
# 0.9050526026617368
# 0.38094520568847656
time0 = time()
print(XGBR(n_estimators=180, random_state=420).fit(Xtrain, Ytrain).score(Xtest, Ytest))
print(time()-time0)
# 0.9050526026617368
# 0.18987488746643066
2.1.2 ��Ҫ����:subsample
���ڴ��������ݼ�(С�����Ͳ��������),���ÿ�ι���������ȫ���ݻᵼ������ʱ�����,��˲�ȡ�зŻس����ķ�ʽ����ȡ����������,ÿһ��������ѵ����ᷴ��Ԥ�������������,����ڹ�����һ����ʱ,�������һ������Ԥ�����������Ȩ��,�Դ�����ֱ�����
����һ��(��ȡ�����ı���):

# ���Ʋ���ѧϰ����
axisx = np.linspace(0, 1, 20)
# ϸ��:axisx = np.linspace(0.05, 1, 20)
rs = []
for i in axisx:
reg = XGBR(n_estimators=100, subsample=i, random_state=420)
rs.append(CVS(reg, Xtrain, Ytrain, cv=cv).mean())
print(axisx[rs.index(max(rs))], max(rs))
# 1.0 0.8320924293483107
plt.figure(figsize=(20, 5))
plt.plot(axisx, rs, c="green", label="SGB")
plt.legend()
plt.show()
# Ҳ���Կ��Ƿ���ƫ���һ��ϸ��,���ϾͲ�д��
reg = XGBR(n_estimators=180, subsample=0.770833333333334, random_state=420).fit(Xtrain, Ytrain)
print(reg.score(Xtest, Ytest))
print(MSE(Ytest, reg.predict(Xtest)))
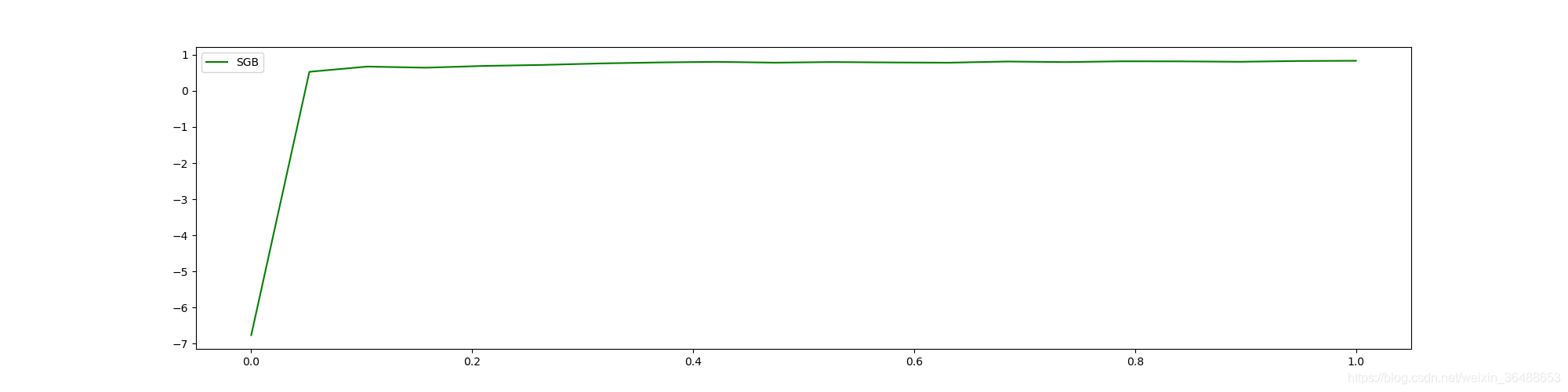
2.1.3 ��Ҫ����:eta
��XGBoost��,�����ĵ����������Ĺ�ʽ:
y
^
i
(
k
+
1
)
=
y
^
i
(
k
)
+
��
f
k
+
1
(
x
i
)
\hat y_i^{(k+1)}=\hat y_i^{(k)}+\eta f_{k+1}(x_i)
y^?i(k+1)?=y^?i(k)?+��fk+1?(xi?)
����
��
\eta
������eta,�ǵ����������IJ���,�ֽ�ѧϰ�ʡ�

# ����һ�����ֺ���,ֱ�Ӵ�ӡXtrain�Ͻ�����֤�Ľ��
def regassess(reg, Xtrain, Ytrain, cv, scoring=["r2"], show=True):
score = []
for i in range(len(scoring)):
if show:
print("{}:{:.2f}".format(scoring[i], CVS(reg, Xtrain, Ytrain, cv=cv, scoring=scoring[i]).mean()))
score.append(CVS(reg, Xtrain, Ytrain, cv=cv, scoring=scoring[i]).mean())
return score
# �鿴learning_rate��Ӱ��
for i in [0, 0.2, 0.5, 1]:
time0 = time()
reg = XGBR(n_estimators=180, random_state=420, learning_rate=i)
print("learning_rate = {}".format(i))
regassess(reg, Xtrain, Ytrain, cv, scoring=["r2", "neg_mean_squared_error"])
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
print("\t")
"""
learning_rate = 0
r2:-6.76
neg_mean_squared_error:-567.55
00:03:225483
learning_rate = 0.2
r2:0.83
neg_mean_squared_error:-12.30
00:04:164096
learning_rate = 0.5
r2:0.82
neg_mean_squared_error:-12.48
00:02:290789
learning_rate = 1
r2:0.71
neg_mean_squared_error:-20.06
00:01:632761
"""
# ���Ը�������������Ʒ���ȸ��ӵ�ѧϰ����
2.2 XGBoost����
2.2.1 ѡ����������:��Ҫ����booster

for booster in ["gbtree", "gblinear", "dart"]:
reg = XGBR(n_estimators=180, learning_rate=0.1, random_state=420, booster=booster).fit(Xtrain, Ytrain)
print(booster)
print(reg.score(Xtest, Ytest))
"""
gbtree
0.9260984369386971
gblinear
0.6521127945547635
dart
0.9260984459922119
"""
2.2.2 Ŀ�꺯��:��Ҫ����objective
XGBoost������ģ���Ӷ��������㷨������Ч��,Ŀ�꺯����д��:
O
b
j
=
��
i
=
1
m
l
(
y
i
,
y
^
i
)
+
��
k
=
1
K
��
(
f
k
)
Obj=\sum_{i=1}^{m}l(y_i,\hat y_i)+\sum_{k=1}^{K}\Omega(f_k)
Obj=i=1��m?l(yi?,y^?i?)+k=1��K?��(fk?)
����
i
i
i�������ݼ��еĵ�
i
i
i������,
m
m
m��ʾ�����
k
k
k��������������,
K
K
K����������������,��ֻ������
t
t
t����ʱ,ʽ��Ӧ��Ϊ
��
k
=
1
t
��
(
f
k
)
\sum_{k=1}^{t}\Omega(f_k)
��k=1t?��(fk?)����һ���dz��õ���ʧ����RMSE���ڶ������ģ���Ӷȡ�

����xgboost�����Ŀ�(��������,Ч���������ٶȸ���):
import xgboost as xgb
# ʹ��Dmatrix��ȡ����
dtrain = xgb.DMatrix(Xtrain, Ytrain)
dtest = xgb.DMatrix(Xtest, Ytest)
# �����
param = {"silent":False, "objective": "reg:linear", "eta": 0.1}
num_round = 180
# ��train
bst = xgb.train(param, dtrain, num_round)
preds = bst.predict(dtest)
r2_score(Ytest, preds)
MSE(Ytest, preds)
2.2.3 ���XGBĿ�꺯��
�����XGBĿ�꺯���Ĺ�����,���Խ�Ŀ�꺯��ת��Ϊ��Ϊ����ʽ����֪:
y
^
i
(
t
)
=
��
k
t
f
k
(
x
i
)
=
��
k
t
?
1
f
k
(
x
i
)
+
f
t
(
x
i
)
=
y
^
i
t
?
1
+
f
t
(
x
i
)
\hat y_i^{(t)}=\sum_k^{t}f_k(x_i) =\sum_k^{t-1}f_k(x_i) + f_t(x_i)=\hat y_i^{t-1}+ f_t(x_i)
y^?i(t)?=k��t?fk?(xi?)=k��t?1?fk?(xi?)+ft?(xi?)=y^?it?1?+ft?(xi?)
Ŀ�꺯�����Կ���������:
O
b
j
=
��
i
=
1
m
l
(
y
i
,
y
^
i
)
+
��
k
=
1
K
��
(
f
k
)
Obj=\sum_{i=1}^{m}l(y_i,\hat y_i)+\sum_{k=1}^{K}\Omega(f_k)
Obj=i=1��m?l(yi?,y^?i?)+k=1��K?��(fk?)
���м�
���ȵ�һ������:
�ڵ�t�ε�����,��������֪ʽ�ӿɵ�:
��
i
=
1
m
l
(
y
i
,
y
^
i
)
\sum_{i=1}^{m}l(y_i,\hat y_i)
i=1��m?l(yi?,y^?i?)
=
��
i
=
1
m
l
(
y
i
t
,
y
^
i
t
?
1
+
f
t
(
x
i
)
)
=\sum_{i=1}^ml(y_i^t,\hat y_i^{t-1}+ f_t(x_i))
=i=1��m?l(yit?,y^?it?1?+ft?(xi?))
����
y
i
t
y_i^t
yit?��һ����֪��,����Ա�ʾ��:
=
F
(
y
^
i
(
t
?
1
)
+
f
t
(
x
i
)
)
=F(\hat y_i^{(t-1)}+f_t(x_i))
=F(y^?i(t?1)?+ft?(xi?))
��̩�չ�ʽ����չ��,�ñ���ʽ���Լ�:
f
(
x
1
+
x
2
)
��
f
(
x
1
)
+
x
2
?
f
��
(
x
1
)
+
1
2
(
x
2
)
2
?
f
��
��
(
x
1
)
f(x_1+x_2)\approx f(x_1)+x_2*f'(x_1)+\frac {1}{2}(x_2)^2*f''(x_1)
f(x1?+x2?)��f(x1?)+x2??f��(x1?)+21?(x2?)2?f����(x1?)
F
(
y
^
i
(
t
?
1
)
+
f
t
(
x
i
)
)
��
F
(
y
^
i
(
t
?
1
)
)
+
f
t
(
x
i
)
?
?
F
(
y
^
i
(
t
?
1
)
)
?
y
^
i
(
t
?
1
)
+
1
2
(
(
f
t
(
x
i
)
)
2
)
?
?
2
F
(
y
^
i
(
t
?
1
)
)
?
y
^
i
(
t
?
1
)
F(\hat y_i^{(t-1)}+f_t(x_i))\approx F(\hat y_i(t-1))+f_t(x_i)*\frac {\partial F(\hat y_i^{(t-1)})}{\partial \hat y_i^{(t-1)}}+\frac {1}{2}((f_t(x_i))^2)*\frac {\partial ^2F(\hat y_i^{(t-1)})}{\partial \hat y_i^{(t-1)}}
F(y^?i(t?1)?+ft?(xi?))��F(y^?i?(t?1))+ft?(xi?)??y^?i(t?1)??F(y^?i(t?1)?)?+21?((ft?(xi?))2)??y^?i(t?1)??2F(y^?i(t?1)?)?
��
l
(
y
i
t
,
y
^
i
(
t
?
1
)
)
+
f
t
(
x
i
)
?
g
i
+
1
2
(
f
t
(
x
i
)
)
2
?
h
i
\approx l(y_i^t,\hat y_i^(t-1))+f_t(x_i)*g_i+\frac {1}{2}(f_t(x_i))^2*h_i
��l(yit?,y^?i(?t?1))+ft?(xi?)?gi?+21?(ft?(xi?))2?hi?
=
��
i
=
1
m
[
l
(
y
i
t
,
y
^
i
(
t
?
1
)
)
+
f
t
(
x
i
)
g
i
+
1
2
(
f
t
(
x
i
)
)
2
h
i
]
=\sum_{i=1}^{m}[l(y_i^t,\hat y_i^{(t-1)})+f_t(x_i)g_i+\frac {1}{2}(f_t(x_i))^2h_i]
=i=1��m?[l(yit?,y^?i(t?1)?)+ft?(xi?)gi?+21?(ft?(xi?))2hi?]
�ڶ�������:
��
k
=
1
K
��
(
f
k
)
\sum_{k=1}^{K}\Omega (f_k)
k=1��K?��(fk?)
=
��
k
=
1
t
?
1
��
(
f
k
)
+
��
(
f
t
)
=\sum_{k=1}^{t-1}\Omega (f_k)+\Omega (f_t)
=k=1��t?1?��(fk?)+��(ft?)
��Ŀ�꺯�����տ��Ա���:
��
i
=
1
m
[
f
t
(
x
i
)
g
i
+
1
2
(
f
t
(
x
i
)
)
2
h
i
)
]
+
��
(
f
t
)
\sum_{i=1}^{m}[f_t(x_i)g_i+\frac {1}{2}(f_t(x_i))^2h_i)]+\Omega (f_t)
i=1��m?[ft?(xi?)gi?+21?(ft?(xi?))2hi?)]+��(ft?)
��GBDT�����һ������Ϊ����⼫ֵ,XGBoost���ö�������Ϊ�˼�ʽ,���������Dz�����ȵ�,������XGBoost����⼫ֵҲ�����һ������
2.2.4 ������������:����alpha��lambda
��ʹ��
q
(
x
i
)
q(x_i)
q(xi?)��ʾ����
x
i
x_i
xi?���ڵ�Ҷ�ӽڵ�,����ʹ��
w
q
(
x
i
)
w_{q(x_i)}
wq(xi?)?����ʾ��������䵽��
k
k
k�����ϵĵ�
q
(
x
i
)
q(x_i)
q(xi?)��Ҷ�ӽڵ�������õķ���,������:
f
k
(
x
i
)
=
w
q
(
x
i
)
f_k(x_i)=w_{q(x_i)}
fk?(xi?)=wq(xi?)?
���ĸ��Ӷȿ��Ա�ʾΪ(Ҷ�������Է��Ƴ����):
��
(
f
)
=
��
T
+
��
��
��
(
L
1
��
L
2
��
��
��
һ
��
)
\Omega(f)=\gamma T+������(L1��L2������һ��)
��(f)=��T+������(L1��L2������һ��)
XGBoost��GBDT��һ���������������XGBoost�����������������ƹ���ϡ�

�����͵�ģ��һ�㲻���������
from sklearn.model_selection import GridSearchCV
# ʹ������������Ѱ�Ҳ���������
param = {"reg_alpha": np.arange(0, 5, 0.05), "reg_lambda":np.arange(0, 2, 0.05)}
reg = XGBR(n_estimators=180, learning_rate=0.1, random_state=420)
gscv = GridSearchCV(reg, param_grid=param, scoring="neg_mean_aquared_error", cv=cv)
time0 = time()
gscv.fit(Xtrain, Ytrain)
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%s:%f"))
print(gscv.best_params_)
print(gscv.best_score_)
preds = gscv.predict(Xtest)
print(r2_score(Ytest, preds))
print(MSE(Ytest, preds))
2.2.5 Ѱ��������ṹ:��� �� \omega ���� T T T
������һ�ڵĻ���,Ŀ�꺯�����Խ�һ��������,���нṹ��ת����ͬҶ�ӽڵ������:
��
i
=
1
m
[
f
t
(
x
i
)
g
i
+
1
2
(
f
t
(
x
i
)
)
2
h
i
)
]
+
��
(
f
t
)
\sum_{i=1}^{m}[f_t(x_i)g_i+\frac {1}{2}(f_t(x_i))^2h_i)]+\Omega (f_t)
i=1��m?[ft?(xi?)gi?+21?(ft?(xi?))2hi?)]+��(ft?)
=
��
i
=
1
m
[
w
q
(
x
i
)
+
1
2
w
q
(
x
i
)
2
h
i
]
+
��
T
+
1
2
��
j
=
1
T
w
j
2
=\sum_{i=1}^m[w_{q(x_i)}+\frac {1}{2}w_{q(x_i)}^2h_i]+\gamma T+\frac {1}{2}\sum_{j=1}^Tw_j^2
=i=1��m?[wq(xi?)?+21?wq(xi?)2?hi?]+��T+21?j=1��T?wj2?
����ÿ��Ҷ��ֻ��һ��Ȩ��ֵ,�в�����ÿ��������Ӧ��һ��
g
i
g_i
gi?,����Խ�һ��ת��:
��
j
=
1
T
(
w
j
?
��
i
��
I
j
+
1
2
��
j
=
1
T
(
w
j
2
?
��
i
��
I
j
h
i
)
)
+
��
T
+
1
2
��
j
=
1
T
w
j
2
\sum_{j=1}^T(w_j*\sum_{i\in I_j}+\frac{1}{2}\sum_{j=1}^T(w_j^2*\sum_{i\in I_j}h_i))+\gamma T+\frac {1}{2}\sum_{j=1}^Tw_j^2
j=1��T?(wj??i��Ij?��?+21?j=1��T?(wj2??i��Ij?��?hi?))+��T+21?j=1��T?wj2?
=
��
j
=
1
T
[
w
j
��
i
��
I
j
g
i
+
1
2
w
j
2
(
��
i
��
I
j
h
i
+
��
)
]
+
��
T
=\sum_{j=1}^T[w_j\sum_{i\in I_j}g_i+\frac {1}{2}w_j^2(\sum_{i\in I_j}h_i+\lambda)]+\gamma T
=j=1��T?[wj?i��Ij?��?gi?+21?wj2?(i��Ij?��?hi?+��)]+��T
��
G
i
G_i
Gi?��
H
j
H_j
Hj?�ֱ��ʾһ���Ͷ����ļӺ�,����:
o
b
j
(
t
)
=
��
j
=
1
T
[
w
j
G
j
+
1
2
w
j
2
(
H
j
+
��
)
]
obj^{(t)}=\sum_{j=1}^T[w_jG_j+\frac{1}{2}w_j^2(H_j+\lambda)]
obj(t)=j=1��T?[wj?Gj?+21?wj2?(Hj?+��)]
F
?
(
w
j
)
=
w
j
G
j
+
1
2
w
j
2
=
(
H
j
+
��
)
F^*(w_j)=w_jG_j+\frac{1}{2}w_j^2=(H_j+\lambda)
F?(wj?)=wj?Gj?+21?wj2?=(Hj?+��)
Ϊ��ʹ��Ŀ�꺯����С,����Ի���
F
?
(
w
j
)
F^*(w_j)
F?(wj?)��
w
j
w_j
wj?���һ����,����:
w
j
=
?
G
j
H
j
+
��
w_j=-\frac {G_j}{H_j+\lambda}
wj?=?Hj?+��Gj??
����ʽ�Ӵ���ԭʽ�пɵ�:
O
b
j
(
t
)
=
?
1
2
��
j
=
1
T
G
j
2
H
j
+
��
+
��
T
Obj^{(t)}=-\frac{1}{2}\sum_{j=1}^T\frac {G_j^2}{H_j+\lambda}+\gamma T
Obj(t)=?21?j=1��T?Hj?+��Gj2??+��T
��ʱĿ�꺯�����ɡ��ṹ������,ֻ��Ҷ�ӽڵ�����йء�
���ݾ�����ѡȡҶ�ӽڵ�ʱ������Ϣ�����ԭ��,�ڹ���XGBoost��ʱҲ���Բ��������IJ���,����Ŀ�꺯����С�����ķ������������ǵ���,���з�֧,�ﵽ�ֲ����š�
2.2.5 ����ֹͣ����:��Ҫ����gamma

����gamma���Ե���ģ�͵ķ�������,ͨ����Ĺ�ʽ���Կ���gamma���Ե����������:
# gammaѧϰ����
axisx = np.arange(0, 5, 0.05)
rs = []
var = []
ge = []
for i in axisx:
reg = XGBR(n_estimators=180, random_state=420, gamma=i)
result = CVS(reg, Xtrain, Ytrain, cv=cv)
rs.append(result.mean())
var.append(result.var())
ge.append((1 - result.mean()) ** 2 + result.var())
rs = np.array(rs)
var = np.array(var) * 0.1
plt.figure(figsize=(20, 5))
plt.plot(axisx, rs, c="black", label="XGB")
plt.plot(axisx, rs + var, c="red", linestyle="-.")
plt.plot(axisx, rs - var, c="red", linestyle="-.")
plt.legend()
plt.show()
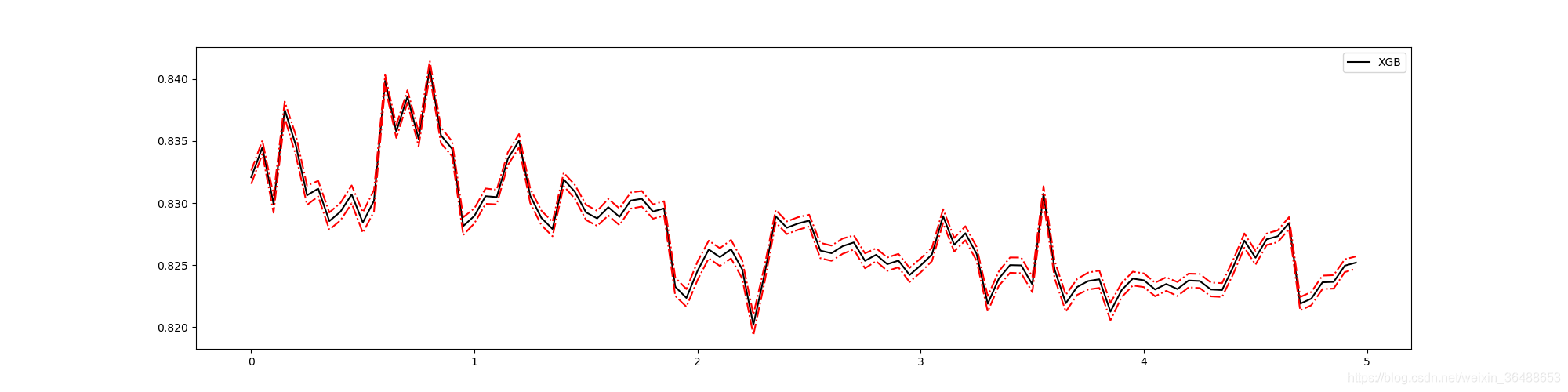
xgboost.cv��ʹ��(���õز鿴������ģ�͵�Ӱ��):
import xgboost as xgb
#xgb.cv��ʹ��
dfull = xgboost.DMatrix(X, y)
# "eval_metric":[rmse, mae, logloss, mlogloss, error, auc]
param1 = {"silent": True, "objective": "reg:linear", "gamma": 0}
num_round = 180
n_fold = 5
time0 = time()
cvresult1 = xgb.cv(param1, dfull, num_round, n_fold)
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%s:%f"))
print(cvresult1)
plt.figure(figsize=(20, 5))
plt.grid()
plt.plot(range(1, 181), cvresult1.iloc[:, 0], c="red", label="train, gamma=0")
plt.plot(range(1, 181), cvresult1.iloc[:, 2], c="orange", label="test, gamma=0")
plt.legend()
plt.show()
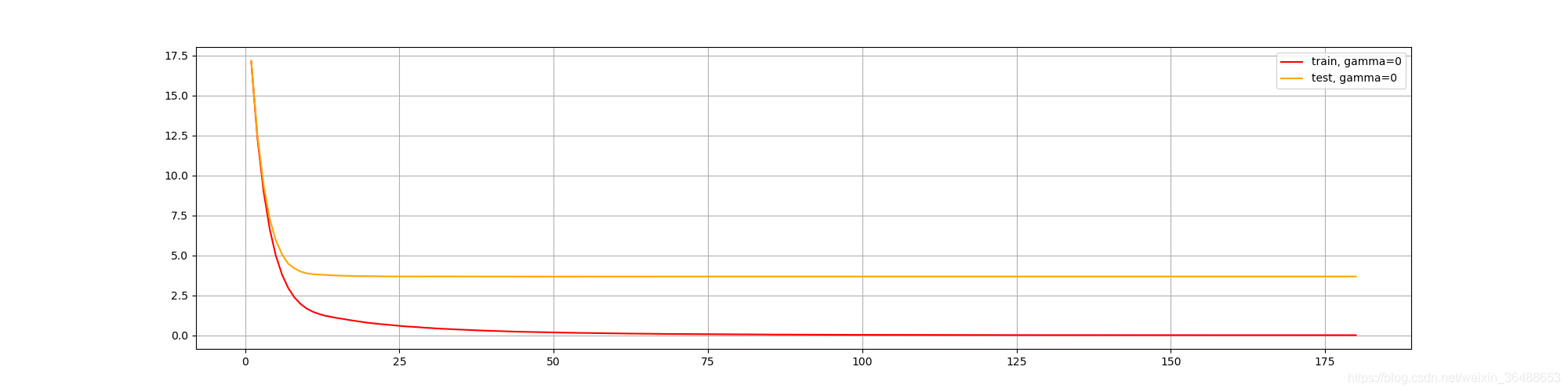
2.3 XGBoostӦ����չ
2.3.1 �����:��֦����
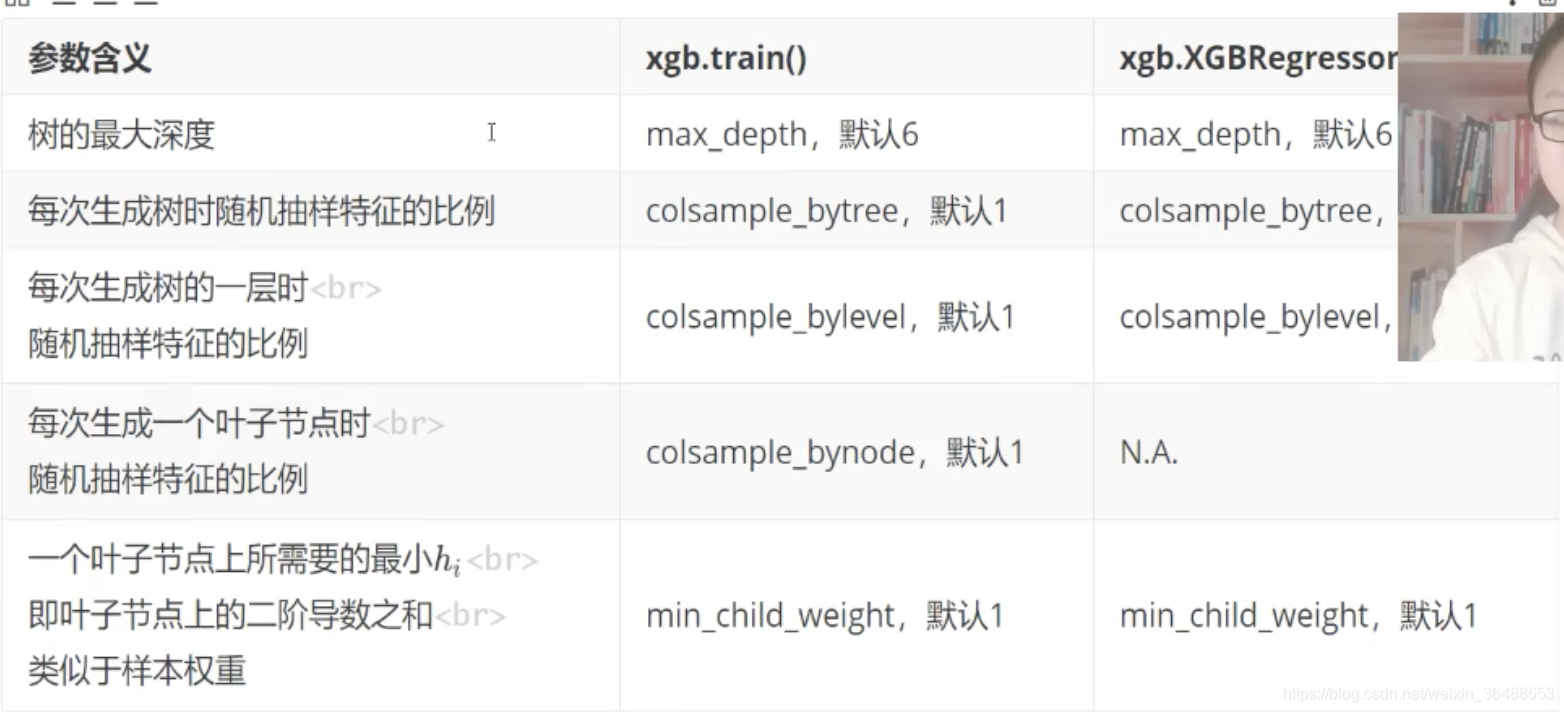
�۲�Ĭ�ϲ�������:
dfull = xgb.Dmatrix(X,y)
param1 = {"silent": True
, "obj": "reg:linear"
, "subsample": 1
, "max_depth": 6
, "eta": 0.3
, "gamma": 0
, "lambda": 1
, "alpha": 0
, "colsample_bytree": 1
, "colsapmle_bylevel": 1
, "colsample_bynode": 1
, "nfold": 5}
num_round = 200
# �۲�Ĭ�ϲ�������
time0 = time()
cvresult1 = xgb.cv(param1, dfull, num_round)
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%F"))
fig, ax = plt.subplots(1, figsize=(15, 10))
ax.grid()
ax.plot(range(1, 201), cvresult1.iloc[:, 0], c="red", label="train,original")
ax.plot(range(1, 201), cvresult1.iloc[:, 2], c="orange", label="test,original")
ax.legend(fontsize="xx-large")
plt.show()
# ֱ��ͨ����param����������
# ����ͼ���ģ��
from joblib import dump
bst = xgb.train(param1, dfull, num_round)
dump(bst, "ģ������")
bst = joblib.load("ģ������")
# or
import pickle
pickle.dump(bst, open("xgboost.dat", "wb"))
bst = pickle.load(open("xgboost.dat", "rb"))
2.3.2 XGBoost��������������

������:��������/����������
�鿴�ò���������:
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split as TTS
from xgboost import XGBClassifier as XGBC
from sklearn.metrics import confusion_matrix as cm, recall_score as recall, roc_auc_score as auc
# ��Ϊ���첻��������
class_1 = 500
class_2 = 50
# �趨������������
centers = [[0.0, 0.0], [2.0, 2.0]]
# �趨�������ķ���
clusters_std = [1.5, 0.5]
X, y = make_blobs(n_samples=[class_1, class_2],
centers=centers,
clusters_std=clusters_std,
random_state=0,
shuffle=False)
Xtrain, Xtest, Ytrain, Ytest = TTS(X, y, test_size=0.3, random_state=420)
clf_ = XGBC(scale_pos_weight=10).fit(Xtrain)
ypred = clf_.predict(Xtest)
clf_.score(Xtest, Ytest)
cm(Ytest, ypred, labels=[1, 0])
recall(Ytest, ypred)
auc(Ytest, clf_.predict_proba(Xtest)[:, 1])
for i in [1, 5, 10, 20, 30]:
clf_ = XGBC(scale_pos_weight=i).fit(Xtrain, Ytrain)
ypred_ = clf_.predict(Xtest)
print(i)
print("\tAccuracy:{}".format(clf_.score(Xtest, Ytest)))
print("\tRecall:{}".format(recall(Xtest, ypred_)))
print("\tAccuracy:{}".format(Ytest, clf_.predict_proba(Xtest)[:, 1]))
ʹ��XGBoost����:
dtrain = xgb.Dmatrix(Xtrain, Ytrain)
dtest = xgb.Dmatrix(Xtest, Ytest)
param = {"silent":True, "objective": "binary:logistic", "eta": 0.1, "scale_pos_weight":1}
num_round = 100
bst = xgb.trian(param, dtrain, num_round)
preds = bst.predict(dtest)
ypred = preds.copy()
# �����Լ��趨��ֵ
ypreds[preds > 0.5] = 1
ypreds[preds != 1] = 0
# �����
scale_pos_weight = [1, 5, 10]
names = ["negative vs positive: 1", "negative vs positive: 5", "negative vs positive: 10"]
for name, i in zip(names, scale_pos_weight):
param = {"silent":True, "objective": "binary:logistic", "eta": 0.1, "scale_pos_weight":i}
clf = xgb.train(param, dtrain, num_round)
preds = clf.predict(dtest)
ypred = preds.copy()
ypred[preds > 0.5] = 1
ypred[ypred != 1] = 0
print(name)
print("\tAccuracy:{}".format(clf_.score(Xtest, Ytest)))
print("\tRecall:{}".format(recall(Xtest, ypred_)))
print("\tAccuracy:{}".format(Ytest, clf_.predict_proba(Xtest)[:, 1]))