开始写一写论文的总结,慢慢补

1.《BadNets Identifying Vulnerabilities in the Machine Learning Model Supply Chain》
概述:在一张图片上增加一个或者几个像素点来扰乱模型的准确性,导致在某些特定的训练集上精度异常低。
2.《Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images》
概述:利用遗传算法生成图像来扰乱模型,导致用户无法识别图像,电脑却可以识别图像。
3.《Explaining and Harnessing Adversarial Examples》
概述:利用 Fast Gradient Sign Method(快速梯度下降法)来对训练好的模型进行攻击,论文不对模型的参数造成攻击,而是在训练过程中依靠梯度反向生成对抗样本,举个例子,如果一个图片的某个像素点在一次训练的反向传播中为了让loss减少,应该是加上某个偏导数,而为了生成对抗样本,则反向的减去一些值,让这个loss反而增大。由于增加噪音无法指定让模型由正确的分类器转变为某个特定的错误分类,因此FGSM属于无目标攻击。
论文中给目标增加的噪音公式如下。其中sign为符号函数,即只判断正负,x为图片像素,y为真实标签值,前面那个希腊字母是学习率。学习率越大,噪音也越大,后面sign()的只影响正负。
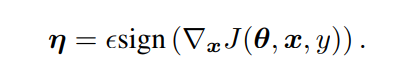
所以对抗样本的图片应该是 y_wrong=y_init+上述的噪音
ps:这里的噪音并非是一定要反向传播的梯度的相反值,可以自行设置,经过测试,少量噪音人对图片的分辨并不影响,但影响人工智能模型,但是过多的噪音不但影响人工智能模型,还影响人,这与论文2恰恰有点相反。
用python(pytorch)为图片增加噪音
def fgsm_attack(image, epsilon, data_grad):
sign_data_grad = data_grad.sign() # 获取梯度的符号,正为1,负为-1
perturbed_image = image + epsilon * sign_data_grad #epsilon 为增加噪音的度 本案例使用0 到 0.3 step=0.05
perturbed_image = torch.clamp(perturbed_image, 0, 1) # 将数值裁剪到0-1的范围内,超出1为1,小于0为0
return perturbed_image
下图为epsilon 0 到 0.3 step=0.05,生成的准确率,可以看到准确率下降的十分快

下图为从测试样例中抽取出来几个样本进行观察,可以发现,在epsilon=0.1时,图片与原图片差距不是十分明显,但是超过0.1后,就有点变样了,且识别的错误率也相当高。

后面还有个改良版的FGSM,也成为迭代式的FGSM,后期再补
4.《Practical Black-Box Attacks against Machine Learning》
概述:提出了一种基于黑盒攻击的方式,在不知道模型的参数、结构等情况下,训练一个跟想要攻击的目标模型完成同样任务的替代模型,基于当前的模型去生成对抗样本,这些对抗样本最终被用于攻击原目标模型。
5.《Privacy and Security Issues in Deep Learning: A Survey》
概述:对人工智能安全的一个总结,由于水平不够,这篇文章先放到一边,晚点再看。
两种攻击方式 1.模型提取攻击――>目标复制部署的模型参数
2.模型反演攻击――>利用可用信息进行推演
安全威胁:
1.敌对攻击――>黑盒 与 白盒
2.中毒攻击
解决隐私问题
1.差分隐私
2.同态加密
3.安全多方计算
4.可信执行环境
深度学习安全性
1.输入预处理
2.恶意软件检测
3.提高模型鲁棒性
4.对抗性训练(最有用)