- In book: Artificial Intelligence in Education (pp.252-256)
- 2020年6月
- 代码https://github.com/scott-pu-pennstate/dktt_light
- 论文地址(PDF) Deep Knowledge Tracing with Transformers (researchgate.net)
文章创新点:改进了transformer模型1)问题的结构和2)问题步骤之间经过的时间。问题结构的使用允许模型利用问题之间的关系。包含经过的时间为解决遗忘问题提供了机会。在公共数据集上,我们的方法在AUC方面比SAKT方法高出大约10%。
摘要
贝叶斯知识追踪(BKT)是智能教学系统中追踪学生技能获取的传统方法。近年来,深度学习方法的快速发展促使研究人员将递归神经网络(RNN)应用于智能教学和计算机支持的学习领域。因此,深度学习模型显示出优于BKT等传统模型的性能。然而,当应用于具有扩展模式的长序列时间序列数据时,神经网络的效率较低,而扩展模式是学习系统的典型模式。在这项工作中,我们提出了一个基于Transformer的模型来追踪学生的知识。我们修改了Transformer结构,以说明1)问题的结构和2)问题步骤之间经过的时间。问题结构的使用允许模型利用问题之间的关系。包含经过的时间为解决遗忘问题提供了机会。在频繁使用的公共数据集上,我们的方法在AUC方面比文献中最先进的方法高出大约10%。
模型
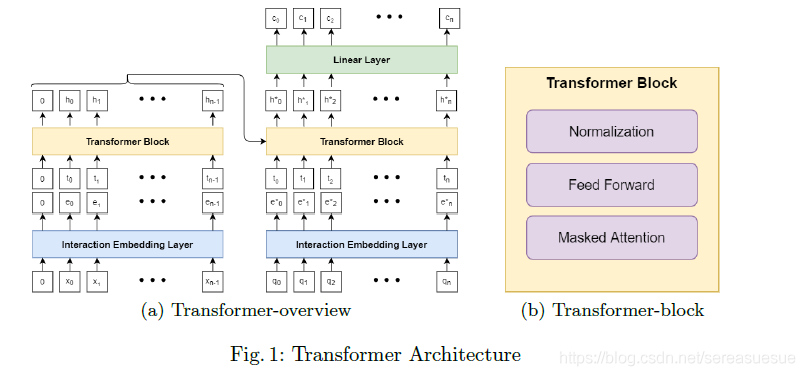
?DKT专注于学习学生互动的表现形式。在Transformer模型中,交互嵌入层负责学习每个交互xi的静态表示。Transformer块负责学习每个交互的上下文相关表示。互动的背景,xi有两个部分:1)所有以前的互动和2)它们各自的时间戳
图1(a)显示了带有1层transformers模块的transformers模型的简化版本。Transformer遵循编码器-解码器结构(左边部分是编码器,右边部分是解码器),学生的交互序列首先通过交互嵌入层嵌入为
,
序列和交互时间序列ti被一堆Transformers联合处理,以学习隐藏的呈现序列
在解码器侧,来自编码器的hi序列、嵌入的问题序列
和问题时间序列由另一堆栈
,生成解码器隐藏表示的变换块:? 。最终解码器输出通过线性层以生成预测的正确可能性序列,并与观察到的目标正确进行比较以计算损失值。
3.2 交互嵌入:将交互和问题映射到向量
?交互映射层将学生交互或问题
映射到其静态表示:高维向量
。该层首先创建交互技能映射矩阵W和技能嵌入矩阵S,然后计算交互xi的嵌入,如下所示:
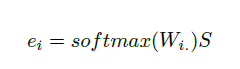
是W的第I行,代表与xi互动的所有潜在技能相关的权重。softmax函数标准化这些权重。S的每一列都是潜在技能的向量表示。因此,互动xi的静态表现是所有潜在技能的加权总和。
Transformer模型的体系结构将学习权重的责任分配给W矩阵,将学习技能表示的责任分配给S矩阵。这种设计有两个好处。首先,它允许我们利用智能教学系统中常见的专家标记的交互技能结构。为了利用专家标记的问题项-技能映射,我们使用专家标记初始化映射矩阵W。例如,如果qi在数据中被标记为sj,我们会将(qi,0)和(sj,0)之间的映射值初始化为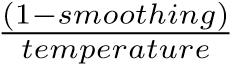 ,其他技能为
,其他技能为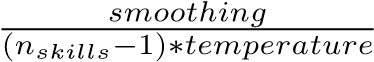 。平滑和温度是控制传递到softmax层的logits的平滑度的两个超参数。其次,它足够灵活,如果有一个以上的潜在技能与交互相关联,该层可以从数据中学习这种关联。
。平滑和温度是控制传递到softmax层的logits的平滑度的两个超参数。其次,它足够灵活,如果有一个以上的潜在技能与交互相关联,该层可以从数据中学习这种关联。
3.3 masked attention:学习情境化的交互嵌入
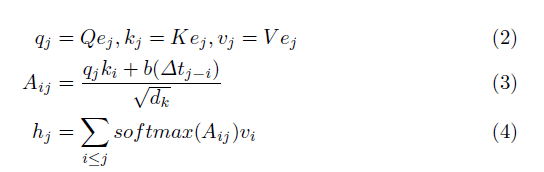
在等式(2)中,masked attention注意力层通过将静态表示ej与三个可训练矩阵:Q、K和V相乘来提取查询qj、键kj和值vj。键和查询可以被解释为与交互ej相关联的潜在技能,值是与ej相关联的潜在技能(或知识状态)的状态。
等式(3)计算分配给过去交互ei的注意力Aij。它有两个组成部分:1) qjki,即ej和ei之间的键值协议,可以解释为交互ej和ei之间潜在技能重叠的程度;2)调节注意力的时间间隙偏差。交互ej和ei之间的时间间隔权重。分母dk用于归一化注意力大小。详见附录。理论上,如果两个问题项在潜在技能上有很大的重叠,一个紧接着另一个,这两个交互之间的注意力就会很高。同时,当两种互动在潜在技能上几乎没有重叠或相距太远时,注意力权重值就会很低。
等式(4)将上下文化表示hj计算为过去值表示的加权和。权重与注意力权重成正比,由softmax函数归一化。请注意,由于任务是预测下一个问题cj+1的正确性,因此注意力值上强制有一个掩码,以便只有i ≤ j的Aij用于计算hj。换句话说,softmax(Akj) = 0,?k > j。
4 实验
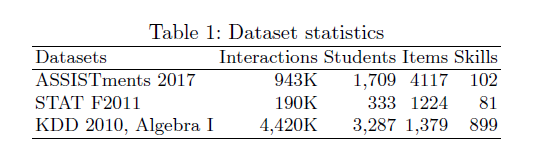
为了评估我们的Transformer方法的性能,我们在文献中经常使用的三个数据集上进行了5倍的学生验证交叉验证。表1列出了数据集的描述性统计数据。
、
?
ASSISTments 2017。该数据追踪了中学生和高中生对在线辅导系统的使用情况。它包括1,709名学生、942,816次互动、4,117个问题和102项标记技能。
STAT F2011。该数据跟踪学生在大学水平的工程静力学课程中的成绩。数据包含333名学生、189,620次互动、1,224个问题和81个标记的知识成分。我们遵循[16]使用的预处理策略,1)将问题名称和步骤名称连接成一个问题,2)只保留每个问题的最终尝试。
KDD。该数据是来自KDD 2010年教育数据挖掘挑战的挑战集A-代数I 2008-2009数据集。它最初包含3310名学生和942666个步骤。我们只保留有知识成分的步骤。
要批量运行学生序列,所有序列必须具有相同的长度maxlen。我们遵循了Pandey和Karypis[6]的策略: 于比maxlen短的序列,我们在左边添加了一个特殊的填充标记,2)对于比maxlen长的序列,我们将序列折叠成长度为maxlen的片段,并用左边的填充标记填充剩余部分。像其他深度学习模型一样,Transformer的性能取决于最优超参数的选择。表2展示了我们实验中调整的所有超参数。
 ?结果
?结果
表3总结了我们的发现,并将其与文献中最先进的Transformer结果以及贝叶斯知识追踪(BKT)模型进行了比较。我们报告的主要指标是AUC,因为它是文献中经常使用的标准,但我们也报告了Transformer模型和BKT模型的均方根误差(RMSE)和精度。
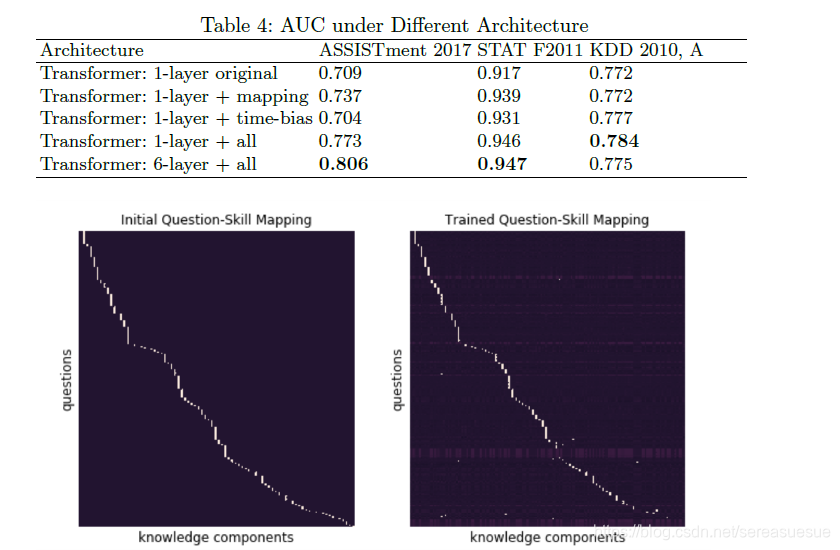
修改后的Transformer模型在所有指标上都优于BKT,而且有很大的优势。最值得注意的是,在ASSISTments 2017和STAT F2011数据集上,它的性能分别比文献中最先进的Transformer模型高出9.81%和11.02%。显著的增益不是由于原始transformers模型的结构。Pandey和Karypis [6]的自我关注模型大致相当于一个具有学习位置编码的1层Transformer。尽管他们的工作在多个基准数据集上产生了最先进的性能,但他们在ASSISTments 2017和STAT F2011上报告的AUC分数比我们改进的Transformer差了约10%。为了进一步说明这一点,我们在有/没有修改组件的原始transformers上重复实验,如表4所示.最初的transformers未能在2017年达到国家或最先进的援助结果.然而,通过在其结构中加入交互技能映射和时间偏差,该模型获得了明显的性能提升。
图2比较了初始专家标记的交互技能映射和学习项目技能映射。在这里,我们展示了STAT F2011数据集的交互-技能映射,其中我们只包括用技能标记的行。大约85.5 %的交互在训练后保持其初始映射为主导映射,而剩余的14.5%发生了变化。这表明专家标记和灵活的映射对于模型的性能都很重要。
图3显示了在STAT F2011数据上训练的模型中的注意力权重。我们从两个专家标记的技能中采样了64个交互作用的伪序列:a)用力和力偶代替一般载荷,b)找到线性分布的净力位置。查询交互,x63,属于前潜伏技能(a)。
?在图中,每一列代表一对交互之间的注意力。最左边的一列代表x0和x63之间的交互关注。最右边的一栏代表x62和x63之间的交互关注。第一行表示综合注意力。第二行关注时间偏差。第三行可视化了查询键协议。正如我们预期的那样,时间偏差(一般来说)给较近的交互(最右边的列)分配的值高于给较远的交互(最左边的列)分配的值。此外,对于类似的技能交互,查询键协议将具有更高的值(标有A的列)。此外,时间偏差会调整注意力,因此距离较远的相同技能事件(左侧的A)被分配的注意力低于距离较近的相同技能事件(右侧的A)
结论
在本文中,我们提出了一种基于Transformer的学生学习建模方法。我们修改了最初的Transformer架构,以便它知道交互的结构以及它们之间的时间。我们通过使用真实数据集将其与已知替代方案进行比较来验证该模型。结果表明,改进的transformers优于文献中发现的最先进的transformers模型的结果约10%。
对于未来的工作,我们打算探索如何有效地将更多的特性信息合并到Transformer架构中。例如,张和他的同事[16]表明,增加工程特性可以提高车型的性能。此外,我们的交互技能映射不能利用关于潜在技能的复杂结构信息,例如,当潜在技能来自诸如技能分类的层次结构时。我们打算继续探索如何将这种结构灵活地表示为Transformer体系结构的一部分。

?
?