本文来自ICME2021论文《Visual Analysis Motivated Rate-Distortion Model for Image Coding》

本文针对VVC帧内编码提出了一个面向视觉分析的RD模型,该模型包括码率控制策略和失真度量模型。首先提出了针对机器的ROI(ROIM)来度量不同CTU在视觉分析中的重要性。然后提出了基于ROIM和局部纹理特征的CTU级码率分配模型。提出多尺度特征失真(multi-scale feature distortion ?,MSFD)来度量CU的失真。实验显示在同样视觉分析(例如图像分类、目标检测和语义分割)质量下本文方法可节省28.17%的码率。
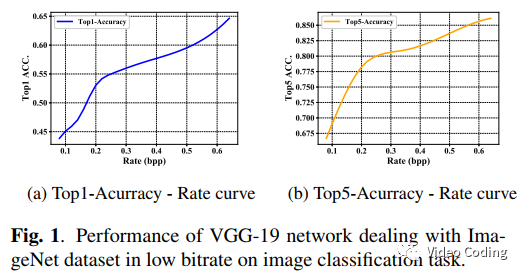
深度学习算法在处理机器视觉任务时能达到很好的效果,例如对于图像分类问题ResNet-50的top-5准确率能达到97%,但输入图像往往是未压缩或压缩质量很高的。实验显示当图像编码码率较低时视觉分析效果会急剧下降。如Fig.1,当bpp为0.1时top-5准确率仅为68%。这个现象揭示了现有的编码算法在处理机器视觉认为时不够高效,尤其是低码率情况下。
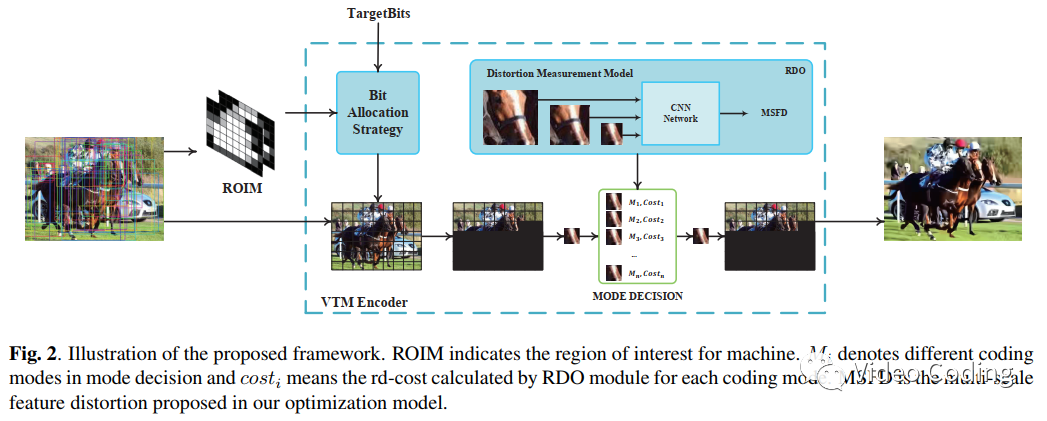
本文为VVC帧内预测提出了面向视觉分析的RDO模型,整个模型框架如Fig.2所示。
码率分配策略
ROIM生成
VTM中码率分配的基本单元是CTU,为了保持一致本文的ROIM基本单元也是CTU。ROIM会生成每个CTU在视觉处理任务中的重要性。ROIM模型包括两个部分:Mi和Mc。Mi揭示了每个CTU的重要性,Mc相邻CTU的连通性。ROIM模型是基于预训练的RPN的,RPN会生成一系列bounding box(非极大抑制之前,NMS)称为B。第k个CTU的重要性计算方式如下:
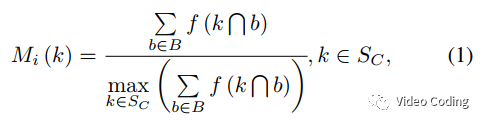
S_C表示CTU集,函数f(A)表示区域A的像素数。
相邻CTU的连通性计算如下:

L(i,j)表示CTUi和CTUj相邻边的长度,A(i,j)表示CTUi和CTUj相邻边在bounding box中的长度,如Fig.3所示。

码率分配
在VTM中,CTU级码率分配是基于纹理信息的,对于第i个CTU目标码率计算如下,
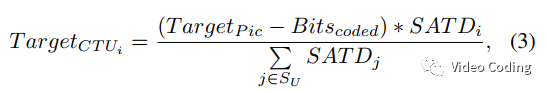
基于视觉分析任务和局部纹理信息,本文提出新的码率分配方法,
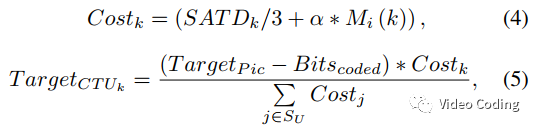
QP限制
在VTM中QP估计过程和RDO过程相互独立,因此为了保持重建图像的一致性需要对CTU的QP进行限制,QP估计过程需要满足公式(6)和(7),
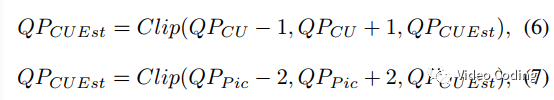
其中QP_pic是整帧图像的QP,QP_cu是已编码CTU的平均QP。但是QP估计带来的块效应会影响视觉分析任务,因此本文基于相邻CTU的连通性提出了新的QP限制策略,首先寻找CTUk来限制CTUi,
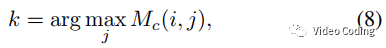
最终CTU的QP计算方式如公式(10),
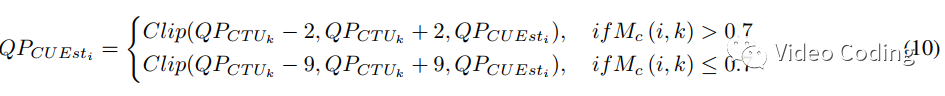
RDO
本文提出了基于CNN进行特征提取的RDO模型。其中特征相似性的计算方式如下,
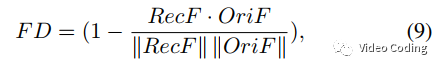
其中RecF和OriF分别代表从重建图像和原始图像中提取的特征。
失真度量
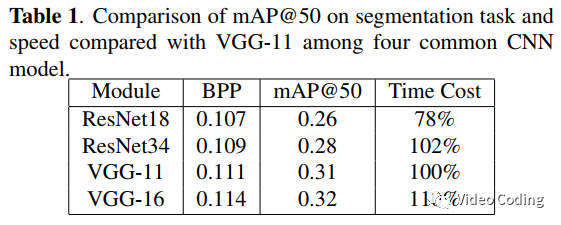
测试了4个CNN模型在语义分割任务上的特征失真,包括ResNet18、ResNet34、VGG-11和VGG-16(都不带最后的池化层和全连接层)。这些模型在ImageNet数据集上预训练,并从COCO-2014数据集上随机选择100幅图像验证模型速度和效果。效果用置信度为0.5时的mAP评价(mAP@50),速度以VGG-11为基准,结果如表1。最终选择VGG-11作为特征提取器。
多尺度特征失真
由于编码器进行块划分后会产生很多小块,这些小块很难提取出有效特征。为了解决在计算CU失真时缺少上下文信息的问题,本文利用多尺度窗口从已编码CU中提取一系列上下文信息。本方法利用左侧和上方重建像素作为参考。
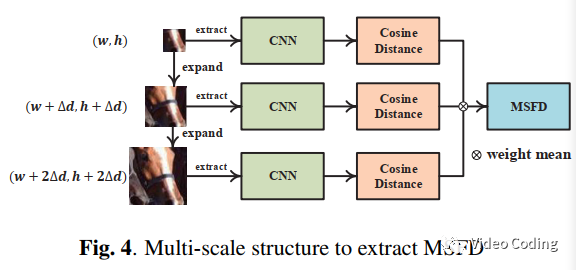
Fig.4是多尺度特征失真MSFD框架。公式(11)中FDi是重建CU和原始CU特征的余弦距离。
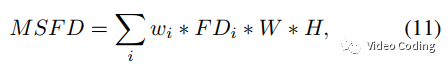
多尺度窗口可以增加小尺寸CU的上下文信息,但是对于极小的块(如4x4)还是难以提取有效特征,所以对于长或宽小于16的块使用余弦距离的最大值来估计FD。但是这种近似处理会引入像素级失真,为了平衡重建区域质量在失真度量时加入MSE,
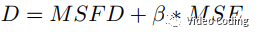
实验结果
视觉分析任务和数据集
为了验证本文方法的泛化性能,选择了3种视觉任务:图像分类、目标检测和语义分割。对于图像分类任务,从ImageNet数据集中选择1000个图像并使用VGG-19模型作为分类网络测试top-1和top-5准确率。对于目标检测,从VOC-2007中随机选择1000个图像,使用YOLOv3测试mAP@50。对于语义分割,从COCO-2014中随机选择1000个图像,使用mask RCNN并测试mAP@50。
配置和实验
实验平台为VTM10.1。QP={40,42,44,46}。配置为All intra。对于模型超参数,公式(5)中alpha=10000,Fig.4中?d ?=8,多尺度窗口设为3,权重wi分别为{4,2,1}。VTM10.1作为anchor。
实验分析
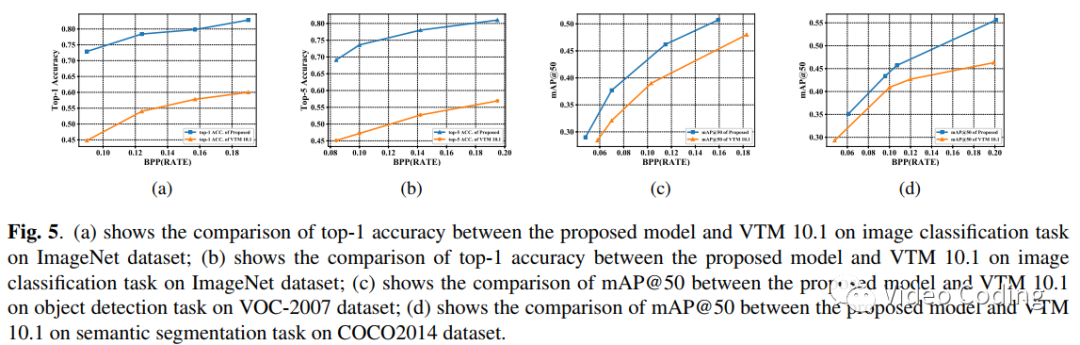
如Fig.5所示,本文方法在各种视觉处理任务中效果都更优。
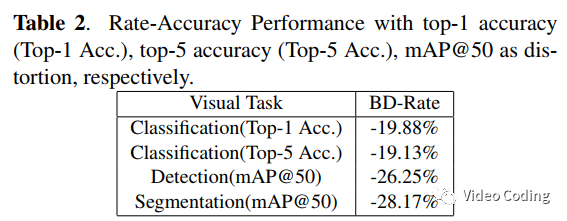
BD-Rate结果如表2所示,其中计算BD-Rate时失真计算采用的是分类准确率和mAP@50。
感兴趣的请关注微信公众号Video Coding
