
?
paper:https://arxiv.org/pdf/2006.15102.pdf?
code:https://github.com/Nandan91/ULSAM
摘要
注意机制建模长期依赖关系的能力使其在视觉模型中的部署迅速发展。与卷积算子不同,自注意提供了无限的接受域,并支持全局依赖关系的高效建模。然而,现有的最先进的注意机制产生了较高的计算和参数开销,因此不适合紧凑的卷积神经网络(CNNs)。在这项工作中,提出了一个简单而有效的“超轻量级子空间注意机制”(ULSAM),它为每个特征图子空间推断出不同的注意图。为每个特征子空间单独的实现注意图,从而实现多尺度和多频的特征表示,这对于细粒度的图像分类更为理想。子空间注意方法是正交的,并补充了现有的现有注意机制。ULSAM是端到端可训练的,可以作为一个即插即用模块部署在现有的紧凑型cnn中。值得注意的是,该工作是第一次尝试使用子空间注意机制来提高紧凑型cnn的效率。在MomileNet-V2的FLOPs和参数计数上分别降低了≈13%和≈25%,在ImageNet-1K和细粒度图像分类数据集上,Top-1的准确率分别提高了0.27%和1%以上。
论文背景
自注意力有效地捕捉了特征空间中特征的全局依赖性,规避了CNN中卷积算子的固有限制。然而,这些注意力机制的较高参数和计算开销对于在紧凑型CNN中是不可取的。由于紧凑型CNN的参数空间冗余度较低,与现有的注意力机制相比,紧凑型CNN的理想注意力机制应该具有更有效、更高效地捕捉全局相关性(融合语义和空间信息)的能力。
论文主要思想
论文提出了一种新的用于紧凑型cnn的注意块ULSAM,它可以学习每个特征子空间的个体注意映射,并在多尺度、多频率特征学习的同时实现跨信道信息的高效学习。具体地,将提取的特征分成g组,对每组的子特征进行空间上的重新校准,最后,把g组特征concatenate到一起。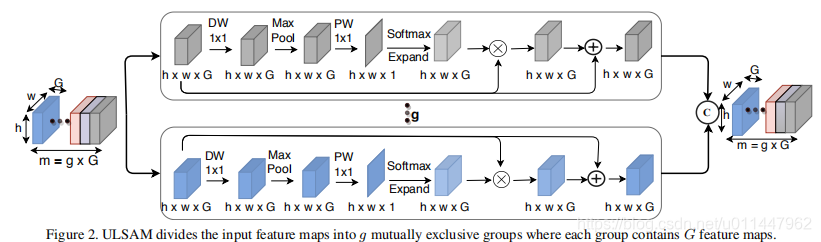
Keras实现?
以下是根据论文和pytorch源码实现的keras版本(支持Tensorflow1.x)。
def _ULSAM(inputs, num_splits=4):
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
sub_feat = Lambda(lambda x: tf.split(x, num_splits, axis=channel_axis))(inputs)
features = []
for i in range(num_splits):
x = sub_feat[i]
out = DepthwiseConv2D(kernel_size=1, strides=1, padding='same')(x)
out = BatchNormalization(momentum=0.9)(out)
out = Activation(activation='relu')(out)
out = MaxPool2D(pool_size=3, strides=1, padding='same')(out)
out = Conv2D(1, kernel_size=1, strides=1, padding='same')(out)
out = BatchNormalization(momentum=0.9)(out)
out = Activation(activation='relu')(out)
m, n, p, q = K.int_shape(out)
out = Reshape((n, -1))(out)
out = Activation(activation='softmax')(out)
out = Reshape((n, p, q))(out)
out = Multiply()([out, x])
features.append(Add()([out, x]))
return Concatenate(axis=channel_axis)(features)声明:本内容来源网络,版权属于原作者,图片来源原论文。如有侵权,联系删除。
创作不易,欢迎大家点赞评论!