��Һ�,�ҵ�СС����
ǰ�����ڡ�Python������ǿ����(TSec����ǽ+CSSͼƬ����ƫ�ƶ�λ)��һ���н�����ν���cssͼƬ����ƫ�Ƶ�����,��ͨ��ͼ��ʶ����ȡ���֡�
���Ľ��������������ʽ�Զ�������,���Ƶ���ͼ,��ͨ��ͼ��ʶ����ȡ����ϵ�б�,����У�Ժ���ȷ�Ķ�Ӧ��ϵ,���ջ�ȡ����ȷ�����ݡ�
��������,�����Ժ�����κ���ʽ�����巴�����ܼ��в��С�
����Ŀ¼
��������Զ����������
�Զ�������Ľ���
����,���DZ���Ҫ����Զ�����������ͨ���������,�Զ������嶨����һЩ�����Unicode�����Ӧ�ĵ���ͼ����,����ͨ����ֻ�Ƕ�����������ʾ��ʽ,������ͨ������Ⱦ�����ݿ���ֱ�Ӹ��Ƴ���ȷ���ı�,���Զ�������ֻ�ܸ��Ƶ���Ӧ��Unicode���롣
��ô�����������ʾ����Ӧ���ַ���?������Ϊ������������Զ�������Ķ�Ӧ��ϵ,��Ⱦ��Ӧ�ĵ���ͼ������ʾ��
����������ij�Ź���վΪ��������ʾ��
����ҷ�����ҳ����������������:
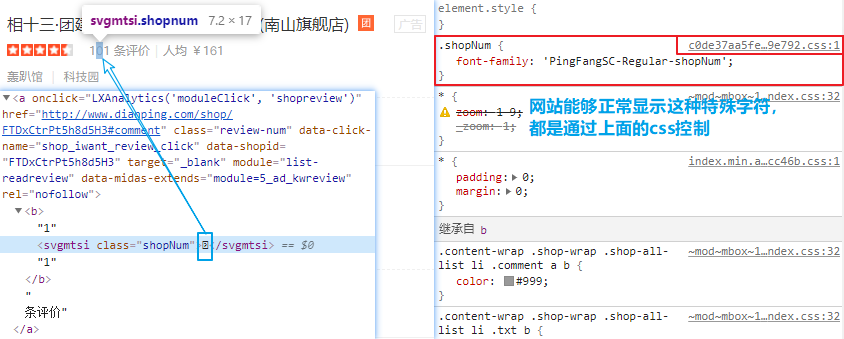

���Կ����Զ������嶼������svgmtsi��ǩ��,��ͬ��class����Ҳ��Ӧ�˲�ͬ�Զ��������ļ���
�������ȡ�����е��Զ�������ļ���,���Կ�����ҳ�϶�Ӧ��λ�ö����������:

����ͼҲ���Կ���,�����Զ��������λ����ȫ������ġ�
�����������,�������ʹ�ÿ�����HTML DOM���Ŀ���ά�ֽڵ�����˳��,��ѡ����BeautifulSoup�����,��ϧֻ֧��cssѡ������
����Ҳ��,������ѧ�����Java��С�����ʱ���ϲ��cssѡ����,���ÿ����һؾ�Υ�ĸо���
����������һ��������ҳ��,������python��ȡҳ������:
Python����ҳ��
import requests
headers = {
"Connection": "keep-alive",
"Cache-Control": "max-age=0",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Language": "zh-CN,zh;q=0.9"
}
session = requests.Session()
session.headers = headers
res = session.get("http://www.dianping.com/shenzhen/ch30")
��������ʹ��BeautifulSoup�������ص�ҳ��,����DOM��:
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text, 'html5lib')
����BeautifulSoup���Բ鿴�ٷ��ĵ�:
- https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
- https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
(����������������һ��,Ŀ¼��ʽ������)
������������������͵ص��б�
�������ڸ��Ź���վ���ڶ�ҳ��Ҫ���¼,����Ҳû�д������Ҫ������������ͨ�������ؼ�����������,��ģ���������ص�Ч����
������������������Щ��Ӧ�ı���:

ͨ��xpath��ѯ����ȡ��xpath��,�Ϳ���ת��Ϊcssѡ������
�����б�:
# //div[@id='classfy']/a/span
type_list = []
for a_tag in soup.select("div#classfy > a"):
type_list.append((a_tag.span.text, a_tag['href']))
type_list
[('��Ħ/����', 'http://www.dianping.com/shenzhen/ch30/g141'),
('KTV', 'http://www.dianping.com/shenzhen/ch30/g135'),
('ϴԡ/����', 'http://www.dianping.com/shenzhen/ch30/g140'),
('�ư�', 'http://www.dianping.com/shenzhen/ch30/g133'),
('�˶�����', 'http://www.dianping.com/shenzhen/ch30/g2636'),
('���', 'http://www.dianping.com/shenzhen/ch30/g134'),
('����', 'http://www.dianping.com/shenzhen/ch30/g2754'),
('�Ž���չ', 'http://www.dianping.com/shenzhen/ch30/g34089'),
('��ժ/ũ����', 'http://www.dianping.com/shenzhen/ch30/g20038'),
('�籾ɱ', 'http://www.dianping.com/shenzhen/ch30/g50035'),
('��Ϸ��', 'http://www.dianping.com/shenzhen/ch30/g137'),
('DIY�ֹ���', 'http://www.dianping.com/shenzhen/ch30/g144'),
('˽��ӰԺ', 'http://www.dianping.com/shenzhen/ch30/g20041'),
('��ſ��', 'http://www.dianping.com/shenzhen/ch30/g20040'),
('����/�羺', 'http://www.dianping.com/shenzhen/ch30/g20042'),
('VR', 'http://www.dianping.com/shenzhen/ch30/g33857'),
('������Ϸ', 'http://www.dianping.com/shenzhen/ch30/g6694'),
('������', 'http://www.dianping.com/shenzhen/ch30/g32732'),
('�Ļ�����', 'http://www.dianping.com/shenzhen/ch30/g142'),
('��������', 'http://www.dianping.com/shenzhen/ch30/g34090')]
�ص��б�:
# //div[@id='region-nav']/a/span
area_list = []
for a_tag in soup.select("div#region-nav > a"):
area_list.append((a_tag.span.text, a_tag['href']))
area_list
[('������', 'http://www.dianping.com/shenzhen/ch30/r29'),
('��ɽ��', 'http://www.dianping.com/shenzhen/ch30/r31'),
('����', 'http://www.dianping.com/shenzhen/ch30/r30'),
('������', 'http://www.dianping.com/shenzhen/ch30/r32'),
('������', 'http://www.dianping.com/shenzhen/ch30/r12033'),
('������', 'http://www.dianping.com/shenzhen/ch30/r34'),
('������', 'http://www.dianping.com/shenzhen/ch30/r33'),
('ƺɽ��', 'http://www.dianping.com/shenzhen/ch30/r12035'),
('������', 'http://www.dianping.com/shenzhen/ch30/r89951'),
('�ϰĴ�������', 'http://www.dianping.com/shenzhen/ch30/r12036')]
���������Ӧcss������URL
���۲���Է���,�����Զ��������css�ļ������Ӵ���svgtextcss�ؼ��ֵ�url��:
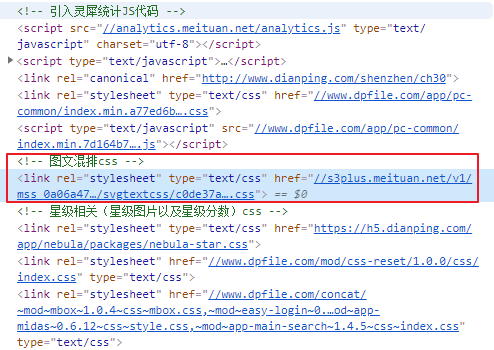
���ǿ��Դ����еĶ���css��ʽ���������ҵ�����svgtextcss�ؼ��ֵ�����:
from urllib import parse
def getUrlFromNode(nodes, tag):
for node in nodes:
url = node['href']
if url.find(tag) != -1:
return parse.urljoin(base_url, url)
def get_css_url(soup):
css_url = getUrlFromNode(soup.select(
"head > link[rel=stylesheet]"), "svgtextcss")
return css_url
css_url = get_css_url(soup)
css_url
'http://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/18379bbeb1f5bf54c52bb1d8b71d4fb1.css'
����css��ȡ�Զ��������URL
��ʽ�����������css�ļ�:

���Կ���,class������ʹ�õ���������,font-face������ÿ���������ƶ�Ӧ�������ļ���
��Ȼ�������ǿ��Կ�������ÿ��class���Ǽ���һ��PingFangSC-Regular-��ǰ��Ϊ��������,������������֤�Ժ����վ��Ȼ���������,Ϊ�˱�֤�Ժ�����������治��Ҫ�Ĵ���,������Ȼ���ǽ�����ÿ��class��Ӧ��font-family,�ٽ�����ÿ��font-family��Ӧ�Ķ������URL,���ն������URLȡ��Ϊ.woff��ʽ��URL,����class���Ե�woff�����ӳ���ϵ��
��������������:
import re
def get_url(urls, tag, only_First=True):
urls = [parse.urljoin(base_url, url)
for url in urls if tag is None or url.find(tag) != -1]
if urls and only_First:
return urls[0]
return urls
def parseCssFontUrl(css_url, tag=None, only_First=True):
res = session.get(css_url)
rule = {}
font_face = {}
for name, value in re.findall("([^{}]+){([^{}]+)}", res.text):
name = name.strip()
for row in value.split(";"):
if row.find(":") == -1:
continue
k, v = row.split(":")
k, v = k.strip(), v.strip(' "\'')
if name == "@font-face":
if k == "font-family":
font_name = v
elif k == "src":
font_face.setdefault(font_name, []).extend(
re.findall("url\(\"([^()]+)\"\)", v))
else:
rule[name[1:]] = v
font_urls = {}
for class_name, tag_name in rule.items():
font_urls[class_name] = get_url(font_face[tag_name], tag)
return font_urls
font_urls = parseCssFontUrl(css_url, ".woff", only_First=False)
font_urls
{'shopNum': 'http://s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/89e46c52.woff',
'tagName': 'http://s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/f8536a55.woff',
'reviewTag': 'http://s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/0373a060.woff',
'address': 'http://s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/f8536a55.woff'}
��������
���ǿ��Խ������ĸ����嶼������������:
def download_file(url, out_name=None):
if out_name is None:
out_name = url[url.rfind("/")+1:]
with open(out_name, "wb") as f:
f.write(session.get(url).content)
for class_name, url in font_urls.items():
download_file(url, f"{class_name}.woff")
���غ�õ�4�������ļ�:
��Ҫ���ز鿴����,���ǿ���ͨ��FontCreator������ƹ���,�ٶ�һ�¿���ֱ���������������ӡ�
��:

�����Աȷ����ĸ��ļ��ĵ���ͼ˳����ȫһ��,��ͬ��ֻ�DZ��������ͼ�Ĺ�ϵ��
�����Զ�������ӳ���ϵ
����������Ҫ��������ָ������ÿ���������Unicode�ַ���Ӧ����ʵ�ַ������������ļ��д洢���ַ��ĵ���ͼ,������ͼƬ�������ı�,�������������Ƴ����������ǿ��Կ���ͨ��PIL�����Զ�������,Ȼ��ÿ���������Unicode�ַ�������Ӧ�ĵ���ͼ,�ٽ���ͼ��ʶ��,�Ϳ��Ի�ȡ��Ӧ���ı������ˡ�
������Ҫʹ��fontTools����,����ֱ��ʹ��pip��װ��
���:https://github.com/fonttools/fonttools
��class����tagName������Ϊ��,�Ȼ�ȡ�䱻�����Unicode�ַ��б�:
from fontTools.ttLib import TTFont
tfont = TTFont("tagName.woff")
# ȥ��ǰ2����չ�ַ�
uni_list = tfont.getGlyphOrder()[2:]
print(uni_list[:10], len(uni_list))
['uniec3e', 'unif3fc', 'uniea1f', 'unie7f7', 'unie258', 'unif5aa', 'unif48c', 'unif088', 'unif588', 'unif82e'] 601
�����ӡ��ǰ10��Unicode�����,����601���Զ����ַ���
��ӡ���Ҳ������Ľ�ͼ��FontCreator������ƹ��߲鿴�Ľ��һ�¡�
ʹ��PIL��ͼ����,�Ȼ���ǰ5����������һ��:
from PIL import ImageFont, Image, ImageDraw
font = ImageFont.truetype("tagName.woff", 20)
for uchar in uni_list[:5]:
unknown_char = f"\\u{uchar[3:]}".encode().decode("unicode_escape")
im = Image.new(mode='RGB', size=(22, 20), color="white")
draw = ImageDraw.Draw(im=im)
draw.text(xy=(5, -5), text=unknown_char, fill=0, font=font)
display(im)
���ƽ��:
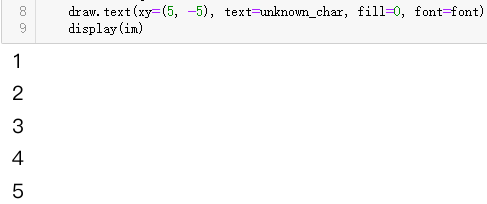
���Կ����ܹ���ȷ���Ƴ���Ӧ�ĵ���ͼ��
�����ٲ���ÿn�������Ϊһ��һ�����,���ٺ���ͼ��ʶ��Ĵ���(��������n=25,����5��):
n = 25
font = ImageFont.truetype("tagName.woff", 20)
for i in range(0, 5*n, n):
im = Image.new(mode='RGB', size=(20*n+10, 22), color="white")
draw = ImageDraw.Draw(im=im)
unknown_chars = "".join(uni_list[i:i + n]).replace("uni", "\\u")
unknown_chars = unknown_chars.encode().decode("unicode_escape")
draw.text(xy=(5, -4), text=unknown_chars, fill=0, font=font)
display(im)
���ƽ��:

��װһ��,������ȡһ�������ļ���ȫ��ͼƬ����:
from fontTools.ttLib import TTFont
from PIL import ImageFont, Image, ImageDraw
def getCustomFontGroupImgs(font_file, uni_list=None, group_num=25):
if uni_list is None:
tfont = TTFont(font_file)
uni_list = tfont.getGlyphOrder()[2:]
imgs = []
font = ImageFont.truetype(font_file, 20)
for i in range(0, len(uni_list), group_num):
im = Image.new(mode='RGB', size=(20*group_num+10, 22), color="white")
draw = ImageDraw.Draw(im=im)
unknown_chars = "".join(uni_list[i:i + group_num]).replace("uni", "\\u")
unknown_chars = unknown_chars.encode().decode("unicode_escape")
draw.text(xy=(5, -4), text=unknown_chars, fill=0, font=font)
imgs.append(im)
return imgs
pytesseractĬ�ϲ�֧�ֶ����ĵ�ʶ��,��Ҫ�϶�����á��������ֱ��ʹ��һ������Ƚ����еĿ�д����ܵ�orc������ͼ��ʶ��,һ������ɰ�װ:
pip install ddddocr
ʹ��ʾ���Ͳ������Բ鿴:https://pypi.org/project/ddddocr/
�����ÿ�ֻ֧�ִ�ͼƬ�ֽں�base64����,��֧��ֱ�Ӵ���ͼƬ����,��Ҫ����ת����
���Զ���һ����ͼƬת�ֽڵķ���:
from io import BytesIO
def get_img_bytes(img):
img_byte = BytesIO()
im.save(img_byte, format='JPEG') # format: PNG or JPEG
return img_byte.getvalue() # im����תΪ��������
Ȼ��Ϳ�����������ʽ��������ʶ��:
from ddddocr import DdddOcr
imgs = getCustomFontGroupImgs('shopNum.woff', group_num=50)
ocr = DdddOcr()
result = []
for im in imgs:
display(im)
text = ocr.classification(get_img_bytes(im))
print(text)
result.append(text)
������:

������˵ȷ�ʻ��Ƿdz��ߵġ�
�����ջ��Ǿ���ֱ�Ӽ̳�DdddOcr��,��дʶ���Ż��㷨(�Ժ��ٿ������п���ͼ��ʶ����):
from ddddocr import DdddOcr, np
class OCR(DdddOcr):
def __init__(self):
super().__init__()
def ocr(self, image):
image = image.resize(
(int(image.size[0] * (64 / image.size[1])), 64), Image.ANTIALIAS).convert('L')
image = np.array(image).astype(np.float32)
image = np.expand_dims(image, axis=0) / 255.
image = (image - 0.5) / 0.5
ort_inputs = {'input1': np.array([image])}
ort_outs = self._DdddOcr__ort_session.run(None, ort_inputs)
result = []
last_item = 0
for item in ort_outs[0][0]:
if item == 0 or item == last_item:
continue
result.append(self._DdddOcr__charset[item])
last_item = item
return ''.join(result)
Ȼ����������:
imgs = getCustomFontGroupImgs('shopNum.woff', group_num=42)
ocr = OCR()
result = []
for im in imgs:
display(im)
text = ocr.ocr(im)
print(text)
result.append(text)

���Կ��������̳е�����Ĵ���,ʶ��ȷ�ʸ�����Щ��
���������˹�У���ĺ�,�õ������ַ���:
words = '1234567890�������ҹ�С�����й����й�Ʒ�������ҵ��˾����װ��ʳ���������湤������ˮ���γ������㲿�������ջ�ר�����ѧ�����˰ٲͲ���ͨζ��ɽ����ҩ��ũ��ͣ�а�����һ�ݶ��Ͼ�Դ���ʼ�ʱ�����Ŀ��Ź�����������ض����ز���������ţ�ѻ������ް��������������ἦ�Һ�վ������������Ժ���ս�����ǻ��ʹ��Կƿ������Ӫ�ͻ�ͯ�������������ݾ���ׯʯ˳�ֶ����������úÿͻ���ʢ����֮Ь�����۰�¥У��ƽ���ϰɱ�������̳���ҽ����ὡ�������켼˹ϴ�����ľԵ����������̩ɫ����Ԣ�����������߳�������ƤȫŮ������άó�����˶��ڲ�����꾩��·��������������������ѵӰ������������ͷ�Ķ�ױ��Էɳ��¡���ɱ�������ܳ����ۼγ����Ӹ���ƻ�Ѷ̫Ѽ�Žֽ���渽�����Զ��ﶰ��ʡ�ź������ø����ڲ�Ԫ��ǰ�����������ͷ�ۿ��ؾ�Ȫ���Ų�����������������Ϫʮ�˹�˫ʤ����ͬ��ӭ��̨�������б�������ɽǼͳ���������ָ���þ��캺����Ū���������������굺��ԭ÷�����Ѻ�������½����������������Źȵ��Dz��˺ܻ���Ҳ���Ҿ����Կɵ���ûȥ���д�Ҫ�Ⱦ�����˵�����ǵ���ϲ��ô��λ�ܽϾ���Ϊ��Ȼ��ͦ�ż����������Ա��������ʵ�ּ�����������������ȵ����ټ�ֻ�������ֱ�����ڰ㶹��ѡ�̴�ÿ��������������Щ������ʲ��ʦ���������ܶ����㼶����Ϻ��̬�ҳ�����ǿ������֪������������ʽЦ��Ƭ������������۲Ÿ�����ش�������ֵ�������ĸ������'
�����ļ��е�Unicode��������������ַ����ַ�һһ��Ӧ��
���ڸ���վ���е��Զ�������ĵ���ͼ�������˳��,�������Dz�����Ҫ���������������ļ���ȡ����ַ��б�����Ȼ����Ź���վ�Ժ����̬��ÿ�������ļ��ĵ���ͼ˳��Ҳ���,����ֻ��˵,��ݡ��ǵ�ʱ�����ٿ��������Լ��Ĵ���,��Ϊ�Ҹ��˵�Ŀ�����û���ҽ������˵����ݡ�
���˵���ͼ��Ӧ���ַ���,���ǾͿ������ɽ��������ļ���ӳ���ϵ:
from fontTools.ttLib import TTFont
font_data = TTFont("tagName.woff")
uni_list = font_data.getGlyphOrder()[2:]
font_map = dict(zip(map(lambda x: x[3:], uni_list), words))
���建����
��Ը��Ź���վ,������������֤����ҳ������һ����ͬ��css�ļ�,����������Ҫ����һ��css��URL�������ļ�URL�������ļ�URL����Ӧ����ӳ���ϵ�Ķ�������:
from io import BytesIO
url2FontMapCache = {}
css2FontCache = {}
def getFontMapFromURL(font_url):
"��������URL��Ӧ����ӳ���ϵ"
if font_url not in url2FontMapCache:
font_bytes = BytesIO(session.get(font_url).content)
font_data = TTFont(font_bytes)
uni_list = font_data.getGlyphOrder()[2:]
url2FontMapCache[font_url] = dict(
zip(map(lambda x: x[3:], uni_list), words))
return url2FontMapCache[font_url]
def getFontMapFromClassName(class_name, css_url):
"����ָ��css�ļ���Ӧ����URL"
if css_url not in css2FontCache:
css2FontCache[css_url] = parseCssFontUrl(css_url, ".woff")
font_url = css2FontCache[css_url].get(class_name)
return getFontMapFromURL(font_url)
���Ի�ȡ��ǰҳ����,ÿ���Զ��������ӳ���ϵ:
for class_name in font_urls.keys():
font_map = getFontMapFromClassName(class_name, css_url)
print(list(font_map.items())[:12])
���:
[('e0a7', '1'), ('ebf3', '2'), ('ee9b', '3'), ('e7e4', '4'), ('f5f8', '5'), ('e7a1', '6'), ('ef49', '7'), ('eef7', '8'), ('f7e0', '9'), ('e633', '0'), ('e5de', '��'), ('e67f', '��')]
[('ec3e', '1'), ('f3fc', '2'), ('ea1f', '3'), ('e7f7', '4'), ('e258', '5'), ('f5aa', '6'), ('f48c', '7'), ('f088', '8'), ('f588', '9'), ('f82e', '0'), ('e7c5', '��'), ('e137', '��')]
[('e3e0', '1'), ('e85f', '2'), ('f3c8', '3'), ('f3d5', '4'), ('e771', '5'), ('f251', '6'), ('f6f6', '7'), ('e8da', '8'), ('ea58', '9'), ('f8fb', '0'), ('ef9b', '��'), ('f3dd', '��')]
[('ec3e', '1'), ('f3fc', '2'), ('ea1f', '3'), ('e7f7', '4'), ('e258', '5'), ('f5aa', '6'), ('f48c', '7'), ('f088', '8'), ('f588', '9'), ('f82e', '0'), ('e7c5', '��'), ('e137', '��')]
�������Զ�������ȫ���滻Ϊ��������
��������ӳ���ϵ,���ǾͿ��Զ�ҳ����Զ��������滻�����ǽ����õ��ı����ݡ�
���Ȼ�ȡ���滻�ĸ��ڵ��б�,����Ա�:
b_tags = [svgmtsi.parent for svgmtsi in soup.find_all('svgmtsi')]
b_tags

��Ȼ�������ڿ�������վÿ��svgmtsi��ǩֻ���һ���ַ�,����ȷ���Ժ�Ҳ��Ȼ���,�������ǵĴ������ھͿ���һ��svgmtsi��ǩ�ڲ����ڶ���ַ��������
ִ���滻:
for svgmtsi in soup.find_all('svgmtsi'):
class_name = svgmtsi['class'][0]
font_map = getFontMapFromClassName(class_name, css_url)
chars = []
for c in svgmtsi.text:
char = c.encode("unicode_escape").decode()[2:]
chars.append(font_map[char])
svgmtsi.replaceWith("".join(chars))
�滻��,�ٲ鿴֮ǰ����Ľڵ�:
b_tags
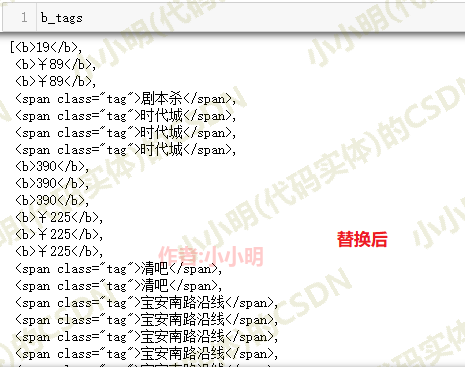
��ȡ����
���Զ��������滻֮��,���ǾͿ��Էdz�˿������ȡ��Ҫ��������:
num_rule = re.compile("\d+")
for li_tag in soup.select("div#shop-all-list div.txt"):
title = li_tag.select_one("div.tit>a>h4").text
url = li_tag.select_one("div.tit>a")["href"]
star_class = li_tag.select_one(
"div.comment>div.nebula_star>div.star_icon>span")["class"]
star = int(num_rule.findall(" ".join(star_class))[0])//10
comment_tag = li_tag.select_one("div.comment>a.review-num>b")
comment_num = comment_tag.text if comment_tag else None
mean_price_tag = li_tag.select_one("div.comment>a.mean-price>b")
mean_price = mean_price_tag.text if mean_price_tag else None
fun_type = li_tag.select_one("div.tag-addr>a:nth-of-type(1)>span.tag").text
area = li_tag.select_one("div.tag-addr>a:nth-of-type(2)>span.tag").text
print(title, url, star, comment_num, mean_price, fun_type, area)
��ſ��̨�����֮��(��ɽ��) http://www.dianping.com/shop/k1lqueFI6sIOfjnI 5 129 ¥196 ��ſ�� ���ȳ�
��¹�������ֲ�(��������) http://www.dianping.com/shop/k4tmabQaordrq6Tm 5 238 ¥246 ȭ�� ������
SWING CAGE ���������&���˻������ http://www.dianping.com/shop/l2lUP0rvcLPy4ebm 5 1088 ¥85 �������� �Ƽ�
���������ʽ�糡 http://www.dianping.com/shop/HaLzYuXfvUWmPLSz 0 8 None �籾ɱ �Ƽ�
����й�Chandelle http://www.dianping.com/shop/H2CSpvtn70y12wNh 5 138 ¥281 DIY�ֹ��� ������/��չ����
cozy cozy����DIY������(����ǵ�) http://www.dianping.com/shop/l3mCIs6dSrdL9jo7 5 1270 ¥321 DIY�ֹ��� �����
�����С�糡�������������(��ɽ������ص�) http://www.dianping.com/shop/H3S4zD55e1gmfb8E 3 18 None �籾ɱ �Ƽ�
FlowLife�ؼ�������˾��ֲ�(�߿��콢��) http://www.dianping.com/shop/G9sHgWISxYtBXz79 5 481 ¥217 �������� �߿�
Doors�ص���������������(�������ֵ�) http://www.dianping.com/shop/k4O3oDj6BwLtbgD4 5 878 ¥101 ���� ������
��¡��� http://www.dianping.com/shop/H6HEuBttJKlMkaAn 0 3 None ������ ��ͷ
��ʮ����ء��ִ��ռ� ����DIY http://www.dianping.com/shop/k5OURy1bNIs7ed7v 5 271 ¥152 DIY�ֹ��� ÷��
���ɣBATTING SOUND ��������� http://www.dianping.com/shop/k9yQRAmYoa3o8cLI 5 734 ¥114 �������� ������
�������� http://www.dianping.com/shop/l4JRIjqLWi2zeFQd 3 9 None ������ ��ó
ZUO STUDIO�決�γ̡� ��Ъ���ⶩ��(��ɽ�������ɹ㳡... http://www.dianping.com/shop/ER0EyDpjx36ekF0G 5 687 ¥224 DIY�ֹ��� ��ʯ��
cozy cozy����DIY������(��ɽ��) http://www.dianping.com/shop/G7MbwkosLSvS3X1I 5 431 ¥338 DIY�ֹ��� ��ͷ
��������
�������ϲ���,���ǿ��Խ�������ط�������װһ��,���������������ڻ��ϳǵ�����������ص��Ź���Ϣ:
import re
from bs4 import BeautifulSoup
import requests
import pandas as pd
import random
import time
from urllib import parse
from io import BytesIO
from fontTools.ttLib import TTFont
url2FontMapCache = {}
css2FontCache = {}
words = '1234567890�������ҹ�С�����й����й�Ʒ�������ҵ��˾����װ��ʳ���������湤������ˮ���γ������㲿�������ջ�ר�����ѧ�����˰ٲͲ���ͨζ��ɽ����ҩ��ũ��ͣ�а�����һ�ݶ��Ͼ�Դ���ʼ�ʱ�����Ŀ��Ź�����������ض����ز���������ţ�ѻ������ް��������������ἦ�Һ�վ������������Ժ���ս�����ǻ��ʹ��Կƿ������Ӫ�ͻ�ͯ�������������ݾ���ׯʯ˳�ֶ����������úÿͻ���ʢ����֮Ь�����۰�¥У��ƽ���ϰɱ�������̳���ҽ����ὡ�������켼˹ϴ�����ľԵ����������̩ɫ����Ԣ�����������߳�������ƤȫŮ������άó�����˶��ڲ�����꾩��·��������������������ѵӰ������������ͷ�Ķ�ױ��Էɳ��¡���ɱ�������ܳ����ۼγ����Ӹ���ƻ�Ѷ̫Ѽ�Žֽ���渽�����Զ��ﶰ��ʡ�ź������ø����ڲ�Ԫ��ǰ�����������ͷ�ۿ��ؾ�Ȫ���Ų�����������������Ϫʮ�˹�˫ʤ����ͬ��ӭ��̨�������б�������ɽǼͳ���������ָ���þ��캺����Ū���������������굺��ԭ÷�����Ѻ�������½����������������Źȵ��Dz��˺ܻ���Ҳ���Ҿ����Կɵ���ûȥ���д�Ҫ�Ⱦ�����˵�����ǵ���ϲ��ô��λ�ܽϾ���Ϊ��Ȼ��ͦ�ż����������Ա��������ʵ�ּ�����������������ȵ����ټ�ֻ�������ֱ�����ڰ㶹��ѡ�̴�ÿ��������������Щ������ʲ��ʦ���������ܶ����㼶����Ϻ��̬�ҳ�����ǿ������֪������������ʽЦ��Ƭ������������۲Ÿ�����ش�������ֵ�������ĸ������'
num_rule = re.compile("\d+")
def get_url(urls, tag, only_First=True):
urls = [parse.urljoin(base_url, url)
for url in urls if tag is None or url.find(tag) != -1]
if urls and only_First:
return urls[0]
return urls
def parseCssFontUrl(css_url, tag=None, only_First=True):
res = session.get(css_url)
rule = {}
font_face = {}
for name, value in re.findall("([^{}]+){([^{}]+)}", res.text):
name = name.strip()
for row in value.split(";"):
if row.find(":") == -1:
continue
k, v = row.split(":")
k, v = k.strip(), v.strip(' "\'')
if name == "@font-face":
if k == "font-family":
font_name = v
elif k == "src":
font_face.setdefault(font_name, []).extend(
re.findall("url\(\"([^()]+)\"\)", v))
else:
rule[name[1:]] = v
font_urls = {}
for class_name, tag_name in rule.items():
font_urls[class_name] = get_url(font_face[tag_name], tag)
return font_urls
def getFontMapFromURL(font_url):
"��������URL��Ӧ����ӳ���ϵ"
if font_url not in url2FontMapCache:
font_bytes = BytesIO(session.get(font_url).content)
font_data = TTFont(font_bytes)
uni_list = font_data.getGlyphOrder()[2:]
url2FontMapCache[font_url] = dict(
zip(map(lambda x: x[3:], uni_list), words))
return url2FontMapCache[font_url]
def getFontMapFromClassName(class_name, css_url):
"����ָ��css�ļ���Ӧ����URL"
if css_url not in css2FontCache:
css2FontCache[css_url] = parseCssFontUrl(css_url, ".woff")
font_url = css2FontCache[css_url].get(class_name)
return getFontMapFromURL(font_url)
def parse_data(soup):
result = []
for li_tag in soup.select("div#shop-all-list div.txt"):
title = li_tag.select_one("div.tit>a>h4").text
url = li_tag.select_one("div.tit>a")["href"]
star_class = li_tag.select_one(
"div.comment>div.nebula_star>div.star_icon>span")["class"]
star = int(num_rule.findall(" ".join(star_class))[0])//10
comment_tag = li_tag.select_one("div.comment>a.review-num>b")
comment_num = comment_tag.text if comment_tag else None
mean_price_tag = li_tag.select_one("div.comment>a.mean-price>b")
mean_price = mean_price_tag.text if mean_price_tag else None
fun_type = li_tag.select_one(
"div.tag-addr>a:nth-of-type(1)>span.tag").text
area = li_tag.select_one("div.tag-addr>a:nth-of-type(2)>span.tag").text
result.append((title, star, comment_num,
mean_price, fun_type, area, url))
return result
def getUrlFromNode(nodes, tag):
for node in nodes:
url = node['href']
if url.find(tag) != -1:
return parse.urljoin(base_url, url)
def get_css_url(soup):
css_url = getUrlFromNode(soup.select(
"head > link[rel=stylesheet]"), "svgtextcss")
return css_url
def fix_text(soup):
css_url = get_css_url(soup)
for svgmtsi in soup.find_all('svgmtsi'):
class_name = svgmtsi['class'][0]
font_map = getFontMapFromClassName(class_name, css_url)
chars = []
for c in svgmtsi.text:
char = c.encode("unicode_escape").decode()[2:]
chars.append(font_map[char])
svgmtsi.replaceWith("".join(chars))
headers = {
"Connection": "keep-alive",
"Cache-Control": "max-age=0",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Language": "zh-CN,zh;q=0.9"
}
session = requests.Session()
session.headers = headers
base_url = "http://www.dianping.com/shenzhen/ch30"
res = session.get(base_url)
soup = BeautifulSoup(res.text, 'html5lib')
type_list = []
for a_tag in soup.select("div#classfy > a"):
type_list.append((a_tag.span.text, a_tag['href']+'r91172'))
result = []
for type_name, url in type_list:
print(type_name, url)
res = session.get(url)
soup = BeautifulSoup(res.text, 'html5lib')
fix_text(soup)
result.extend(parse_data(soup))
time.sleep(random.randint(2, 4))
df = pd.DataFrame(result, columns=["����", "�Ǽ�", "������", "����", "��������", "����", "����"])
df.������ = df.������.apply(lambda x: int(x) if x else pd.NA)
df.���� = df.����.str[1:].apply(lambda x: int(x) if x else pd.NA)
df.drop_duplicates(inplace=True)
df.to_excel("���ϳ�����.xlsx", index=False)
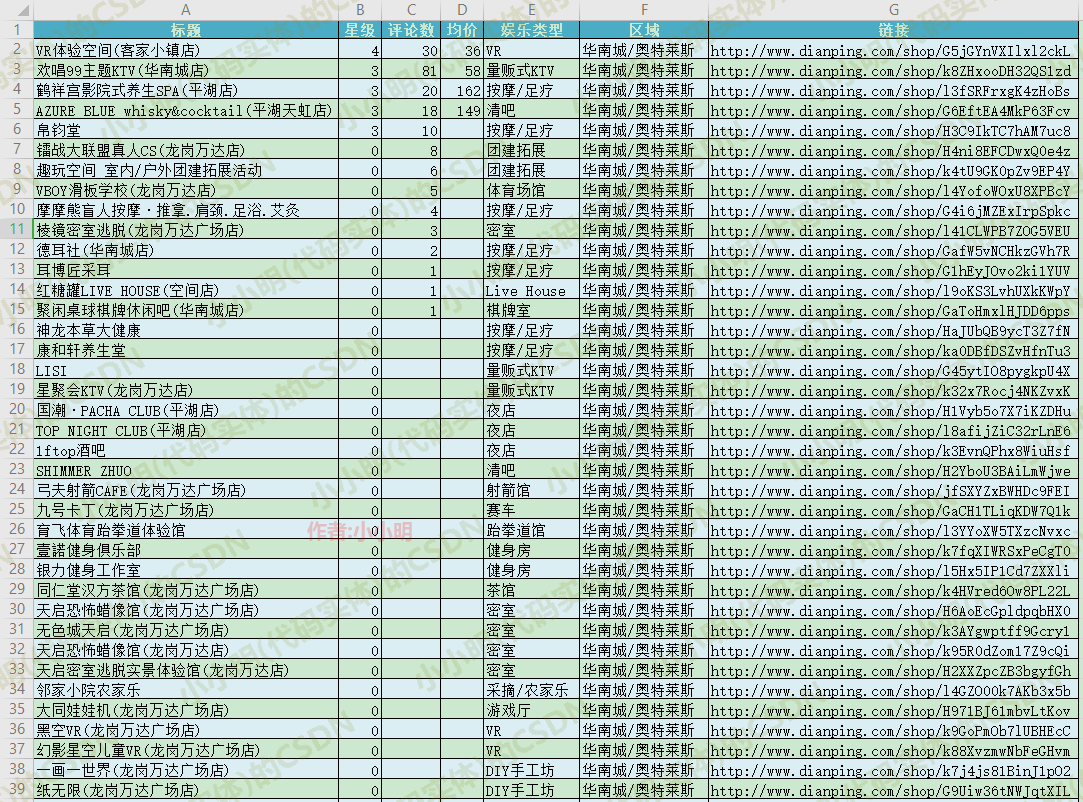
��ȡ���(��һ���Ķ��α༭):
�ܽ�
������˵,���Ź���վ�ķ������ƻ���ͦ�͵�,���˾�ţ����֮��Ҳ��ֻ��ÿ����Ŀ��һҳ����,��û�е�ַ,�Ƽ���λ��Ҫȥ���ˡ�
�������ĵ�Ŀ�ľ�����ʾ�����ѵ����巴���������,ϣ�������Ѿ��ﵽ���Ŀ��,������滹�и��ѵ����巴����վ����,�ټ������������,���в��С�
ϣ����λС���,���о��걾�ĺ�,�ܹ�Ӧ���κ����巴�����⡣
