1.背景:
Transformer是2017年的一篇论文《Attention is All You Need》提出的一种模型架构,这篇论文里只针对机器翻译这一种场景做了实验,并且由于encoder端是并行计算的,训练的时间被大大缩短了。全面击败了当时的SOTA,
现阶段,Transformer在cv领域也是全面开花,基于transformer的目标识别,语义分割等算法也是经常屠榜。
论文:?[1706.03762] Attention Is All You Need (arxiv.org)? ? ? ? ?
2.正文:

2.1 self-attention 是什么?
感性认识:
举例子:今天晚上打你
首先转换为词向量,转换为不同维数的矩阵。(维数是我随便写的,就是举个栗子)
?之后self-attention重构词向量,根据句子中每个词和自己的关系,通过权重表示关系的紧密程度。

?
?这就是自注意力机制,即:一句话当中每个词看其他词与自己的关系,这个词和其他句子中的词之间的关系叫做注意力机制。
2.2?self-attention 如何计算?
?
q1:当x1主动查别的词向量和自己的关系时需要用到的向量;
k1:当x1被别的词向量查询时需要出示的向量;
v1:当前词的特征向量
注意:每一个词向量都有q1,k1,v1这三个辅助向量;

?通过训练得到Q,K,V 三个矩阵。
?

?

?

divide by 8: 消除维数不同对相似程度的影响,理解为向量是64位,开根号之后为8。

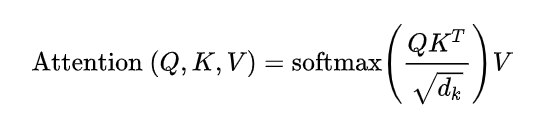
2.3 multi-headed 机制
 ?
?
?
2.4?Transformer 在CV方向的应用
视觉中的Attention 表现为关注图片前景,弱化背景。?以ViT为例说明:

?Token :每一个词或者每一个patch。
将输入的图片分成九份,每一份都以向量的的形式输入,通过一个全连接层,即:x1 = wx1 + b ,之后是self-attention 计算。每一份就是一个token。
?处理图片的时候需要patch position Embedding。位置向量和图片向量要绑定在一起。

?CNN层数的增多会提取更多的特征,能有更大的感受野,但是transformer 不需要堆叠,就可以或多全局的信息,但是transformer的训练能需要更好的资源,需要更多的训练数据。CNN不需要占用很大的资源。transformer 5 层相当于CNN30层
2.4.1位置编码
 ?
?
未完待续......
最后,如果这篇文章让你有多一点点了解编程这个世界,那就点个赞吧!
参考:
【经典精读】Transformer模型深度解读 - 知乎 (zhihu.com)
哔哩哔哩:https://www.bilibili.com/video/BV1M44y1q7oq
?