Ŀ¼
ǰ��
AlphaPose����
AlphaPose��һ����ȷ�Ķ�����̬������,�ǵ�һ����COCO���ݼ���ʵ��70+ mAP (75 mAP),��MPII���ݼ���ʵ��80+ mAP (82.1 mAP)�Ŀ�Դϵͳ��Ϊ��ƥ���֡��Ӧ��ͬһ���˵�����,���ǻ��ṩ��һ����Ϊ�����������ĸ�Ч�������Ƹ���������������PoseTrack Challenge���ݼ���ͬʱʵ��60+ mAP (66.5 mAP)��50+ MOTA (58.3 MOTA)�Ŀ�Դ�������Ƹ�������
����ǿ��һ��
��Alphapose�����¶������Alphapose��RMPE�������йء�����ʵ�Ϸ�չ������,Alphapose��ʵ���ӽ�һ������Ļ������϶��µĶ�����̬������Ŀ,�����ģ��Ҳ�Ǽ��ڼ�֮����,��RMPE�������ᵽ��SSTN���°����Ŀ����������ȥ���ˡ�
������ʲô
Ŀǰ��Alphaposeʵ������yolov3-spp���˼��+��̬�ؼ�����+������ʶ���㷨�����,��Ӧ��Ŀ������������̬������������ʶ����������,������Ҫ���ܵ�����Alphaposeԭ��Ŀ��������������̬����ģ���ķ�����
yoloĿ�����������
Alphapose��ʹ�õ�yolov3ʵ������yolov4��Ŀ�µ�һ���汾,�����˿ռ�������ػ�(Spatial Pyramid Pooling, SPP),Ŀ����Ч�����ԭ���yolov3��һ�㡣
�����д���ʹ��Yolov4�Ż���һ��Ŀ���ⲿ��:https://github.com/WildflowerSchools/pytorch-YOLOv4
csdn�����һ�����������ʹ������yolo�滻Alphapose��Ŀ�����������Ŀ:https://blog.csdn.net/qq_35975447/article/details/114940943
���˵������ǽ�����ģ��ת����torchscriptģ��,Ȼ���Լ���д�м���ν�(��Ҫ���м��ͼ�����Ͷ��߳���ˮ��),����Ȥ�Ŀ��Թ�עһ���ҵ���Ŀ,�������ҵ���Ӧ�Ĵ���:https://github.com/hongyaohongyao/smart_classroom_demo
- ������Ŀ���õ���yolov5sģ��,��������ʹ���˱Ƚ�������Ŀ����ģ�Ͱɡ�
������̬���������������
Alphapose�����϶��µĶ�����̬���ƵIJ���
- ��������Ŀ����
- ������Ŀ��ü�����,ͨ������任ת���ɴ�СΪ�̶���С��ͼ��
- ʹ�õ�����̬��������Ԥ������ͼ���еĹؼ���,�ؼ���ع��õ�����ͼ��
- �����Ĺؼ���ͨ������任����任��ԭ��ԭͼ���е����ꡣ
Alphapose�ĵ�����̬����������Ҫ�����������ʽ:coco 17�ؼ���,Halpe 26�ؼ����Halpe 136�ؼ��㡣
coco17�ؼ���Ƚϳ���,��ʵ����������������̬����ģ�����,��������Ͼ���ѧ����SimpleBaseline��������:https://github.com/zhang943/lpn-pytorch
Halpe��Alphapose�Լ������ݼ�,��Ҫ�Լ�����ѵ��ģ�͡�
ѵ���������ĵ�����̬����ģ��
�������ݼ�
��Alphapose���������ĿFang-Haoshu/Halpe-FullBody�������ݼ�
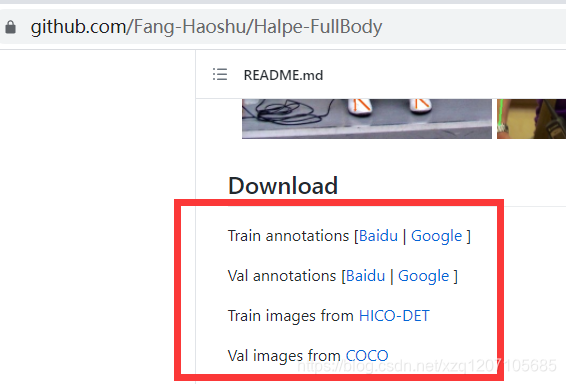
��data�ļ����°��������Ŀ¼�ṹ������֯,������Ӧ�øĹ�һЩ�ļ�����,��Ҫ�����洴����ѵ���ļ����ж�Ӧ
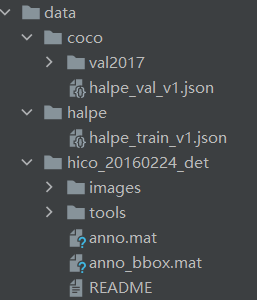
- ��ʵ������ģ��Ӧ��Ҫ��:300wLP(����)��Halpe���ݼ�(ȫ��)��frei(�ֲ�)�������ݼ�ѵ��,������ѵ��Halpe���ݼ��Ļ��ֲ���������Ч����Ƚϲ�,������Ϊ�豸��ʱ�������,��ֻѵ����Halpe���ݼ���136���ؼ���,��Ȼmap���½�,����ʵ��Ч��Ҳ������������Ŀ����
����FastPoseMobile
��alphapose/modelsĿ¼�´����Լ���������ģ�͡���������FastPoseMobile
����ʹ��torchvision��mobilenetv3��������fastpose�ĹǸ�����
- ������һ��,ò��Alphapose���Alphapose��fastpose������ûɶ��ϵ,���ܾ��Ǹ�ģ�ͽṹ�ɡ�
- �����õ�ģ����Ҫ����`@SPPE.registe���������ͼƬ����
r_module`ע��
- ��
alphapose/models/__init__.py�ļ���__all__�ֵ�������FastPoseMobile - mobilenet_v3���Ҵ�torchvision����ĵ�,���ݱȽ϶�,����Ͳ��ų�����
# -----------------------------------------------------
# Copyright (c) Shanghai Jiao Tong University. All rights reserved.
# Written by Jiefeng Li (jeff.lee.sjtu@gmail.com)
# -----------------------------------------------------
import torch.nn as nn
from .builder import SPPE
from .layers.DUC import DUC
from .layers.mobilenet_v3 import mobilenet_v3
@SPPE.register_module
class FastPoseMobile(nn.Module):
def __init__(self, norm_layer=nn.BatchNorm2d, **cfg):
super(FastPoseMobile, self).__init__()
self._preset_cfg = cfg['PRESET']
if 'CONV_DIM' in cfg.keys():
self.conv_dim = cfg['CONV_DIM']
else:
self.conv_dim = 128
assert cfg['MODEL_SIZE'] in ['large', 'small']
self.preact = mobilenet_v3(cfg['MODEL_SIZE'])
output_num = 960 // 4 if cfg['MODEL_SIZE'] == 'large' else 576 // 4
self.suffle1 = nn.PixelShuffle(2)
self.duc1 = DUC(output_num, 1024, upscale_factor=2, norm_layer=norm_layer)
if self.conv_dim == 256:
self.duc2 = DUC(256, 1024, upscale_factor=2, norm_layer=norm_layer)
else:
self.duc2 = DUC(256, self.conv_dim * 4, upscale_factor=2, norm_layer=norm_layer)
self.conv_out = nn.Conv2d(
self.conv_dim, self._preset_cfg['NUM_JOINTS'], kernel_size=3, stride=1, padding=1)
def forward(self, x):
out = self.preact(x)
out = self.suffle1(out)
out = self.duc1(out)
out = self.duc2(out)
out = self.conv_out(out)
return out
def _initialize(self):
for m in self.conv_out.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
# logger.info('=> init {}.weight as normal(0, 0.001)'.format(name))
# logger.info('=> init {}.bias as 0'.format(name))
nn.init.normal_(m.weight, std=0.001)
nn.init.constant_(m.bias, 0)
����ѵ���ļ�
����ѵ���ļ�configs/halpe_136/mobilenet/256x192_mobilenet_lr1e-3_2x-regression.yaml
- Ҫѵ���������ݼ����Բο������ʽ��дһ������ѵ���ļ�,��Ҫ�Ǹ�һ��DATASET������ļ���ַ��
DATASET:
TRAIN:
TYPE: 'Halpe_136'
ROOT: './data/halpe/'
IMG_PREFIX: 'train2017'
ANN: 'halpe_train_v1.json'
AUG:
FLIP: true
ROT_FACTOR: 45
SCALE_FACTOR: 0.35
NUM_JOINTS_HALF_BODY: 8
PROB_HALF_BODY: 0.3
VAL:
TYPE: 'Halpe_136'
ROOT: './data/coco/'
IMG_PREFIX: 'val2017'
ANN: 'halpe_val_v1.json'
TEST:
TYPE: 'Halpe_136_det'
ROOT: './data/coco/'
IMG_PREFIX: 'val2017'
DET_FILE: './exp/json/test_det_yolo.json'
ANN: 'halpe_val_v1.json'
DATA_PRESET:
TYPE: 'simple'
LOSS_TYPE: 'L1JointRegression'
SIGMA: 2
NUM_JOINTS: 136
IMAGE_SIZE:
- 256
- 192
HEATMAP_SIZE:
- 64
- 48
MODEL:
TYPE: 'FastPoseMobile'
PRETRAINED: ''
TRY_LOAD: ''
NUM_DECONV_FILTERS:
- 256
- 256
- 256
MODEL_SIZE: 'large'
CONV_DIM: 256
LOSS:
TYPE: 'L1JointRegression'
NORM_TYPE: 'sigmoid'
OUTPUT_3D: False
DETECTOR:
NAME: 'yolo'
CONFIG: 'detector/yolo/cfg/yolov3-spp.cfg'
WEIGHTS: 'detector/yolo/data/yolov3-spp.weights'
NMS_THRES: 0.6
CONFIDENCE: 0.05
TRAIN:
WORLD_SIZE: 4
BATCH_SIZE: 48
BEGIN_EPOCH: 0
END_EPOCH: 270
OPTIMIZER: 'adam'
LR: 0.001
LR_FACTOR: 0.1
LR_STEP:
- 170
- 200
DPG_MILESTONE: 210
DPG_STEP:
- 230
- 250
��ʼѵ��
��train.py�ļ�������,���Ccfg��Ĭ��ֵ�ijɸղŵ�ѵ���ļ���
parser.add_argument('--cfg', default="configs/halpe_136/mobilenet/256x192_mobilenet_lr1e-3_2x-regression.yaml",
help='experiment configure file name',
type=str)
Ȼ��Ϳ�����Ŀ����gpu��������ѵ���ˡ�
ѵ�����
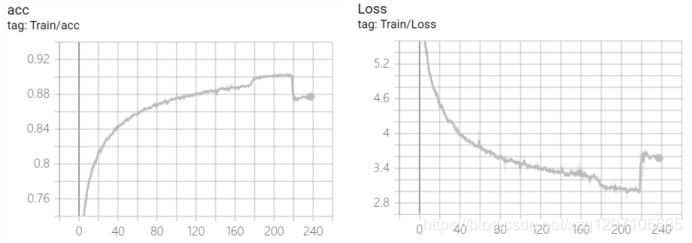
�ð��ſ���rtx3090ѵ���˴��6��,ģ����209�ִﵽ����õ�Ч��,ȷ�ʴ��90%��,֮�������ˡ�
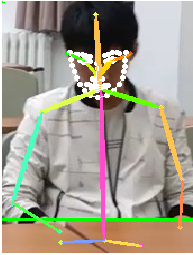
ʶ��Ч����ʵ���Dz�����,�沿�Ĺؼ���ع�����е�Ť��,��ǿ����ʹ��,�ֲ��Ļ���û����,��Ҫ�������������ݼ���һ��ѵ��,�������Ҳ�ò��ϡ�